英偉達正在自主智能體基礎設施競爭中發力,標誌着這家芯片巨頭在人工智能(AI)競賽中從硬件供應商向模型層深度延伸的戰略轉變。
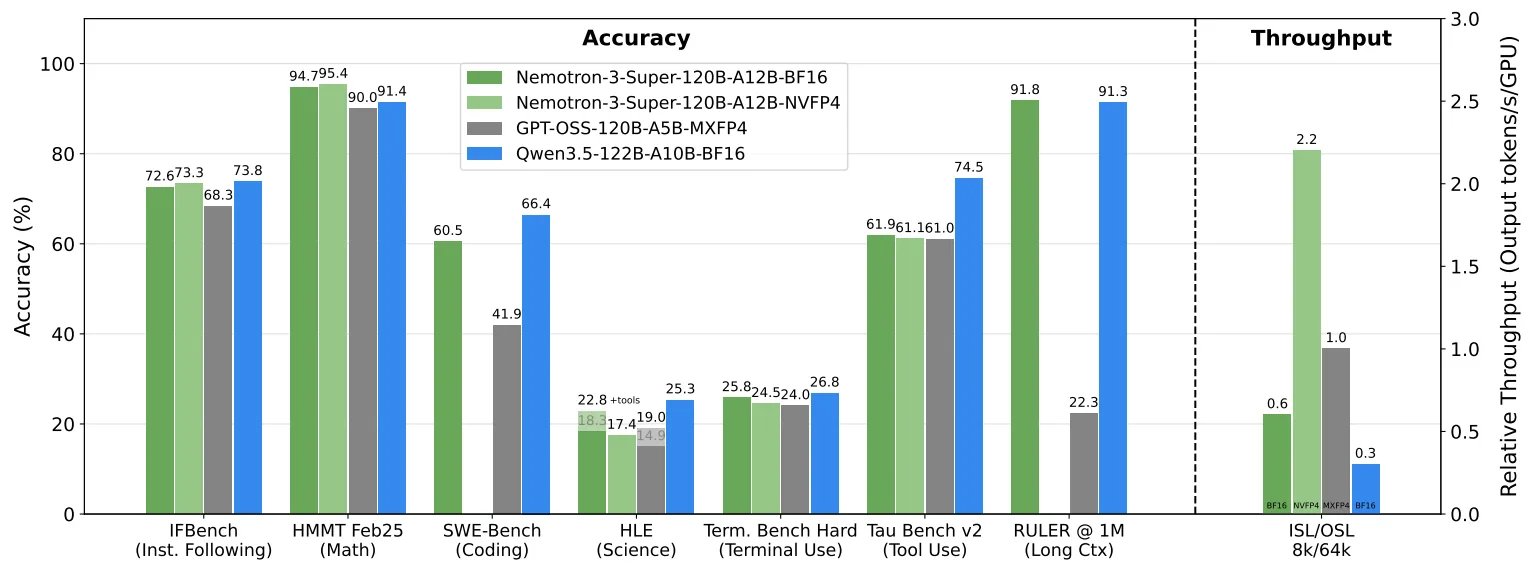
美東時間11日周三,英偉達宣佈推出新一代開源大語言模型Nemotron 3 Super,專為企業級多智能體系統設計,憑藉全新的混合專家(MoE)架構,將推理吞吐量提升至上一代模型的五倍以上。該模型的總參數量達1200億,推理時僅激活120億參數,原生支持100萬token上下文窗口。
英偉達表示,Nemotron 3 Super在效率與開放性方面已登頂Artificial Analysis榜首,同等規模模型中準確率領先,並驅動英偉達AI-Q研究智能體在DeepResearch Bench及DeepResearch Bench II兩大排行榜中位列第一。
英偉達披露了Nemotron 3 Super的首批合作伙伴。AI搜索公司Perplexity成為首家接入該模型執行智能體任務的合作方,為用戶提供搜索及Computer產品中的多智能體編排服務。Palantir、西門子、Cadence、達索系統及Amdocs等企業軟件巨頭也已宣佈將部署該模型,用於電信、網絡安全、半導體設計及製造等領域的工作流自動化。
Nemotron 3 Super模型現已通過英偉達旗下build.nvidia.com、Hugging Face及OpenRouter等渠道向開發者開放。
兩大瓶頸催生新架構
英偉達在博客中指出,企業從聊天機器人邁向多智能體應用時,面臨兩項核心約束。
其一為"上下文爆炸":多智能體工作流每次交互均需重新傳輸完整歷史記錄(含工具輸出和中間推理步驟),生成的token數量最高可達標準對話的15倍。隨着任務延伸,這一海量上下文不僅推高成本,還會導致"目標漂移"——智能體逐漸偏離原始目標。
其二為"思考稅":複雜智能體須在每一步驟進行推理,若每個子任務均調用大型模型,多智能體應用將因成本高昂、響應遲緩而難以落地。
Nemotron 3 Super通過100萬token原生上下文窗口直接回應上下文爆炸問題,確保智能體在超長任務中保持狀態連貫,防止目標漂移。而混合架構設計則針對性化解思考稅。
三重架構創新支撐五倍提速
英偉達博客披露,Nemotron 3 Super的性能躍升來自三項架構層面的核心創新。
混合Mamba-Transformer骨幹網絡:模型交錯部署Mamba-2層與Transformer注意力層。Mamba層處理大部分序列任務,以線性時間複雜度提供4倍內存與計算效率提升,使百萬token上下文窗口具備實際可行性;Transformer層則在關鍵深度插入,保障精確的關聯召回能力。
潛在專家混合模型(latent MoE):在路由決策前,將token嵌入壓縮至低秩潛空間,專家計算在該較小維度內完成後再投影回全維度。英偉達表示,這一設計使模型以相同推理成本激活4倍數量的專家,實現更細粒度的專業化路由——例如針對Python語法與SQL邏輯分別激活不同專家。
多token預測(MTP):模型在單次前向傳播中同步預測多個未來token,而非逐token生成。英偉達稱,這一設計在訓練階段強化了模型對長程邏輯依賴的內化,在推理階段則內置推測解碼能力,對代碼和工具調用等結構化生成任務實現最高3倍的速度提升,且無需額外草稿模型。
在英偉達Blackwell平台上,該模型以NVFP4精度運行,相比英偉達Hopper平台的FP8,推理速度最高提升至4倍,且據英偉達稱精度無損失。
開放權重疊加多層生態佈局
與當前主流前沿模型普遍採用API-only訪問方式不同,英偉達選擇以寬鬆許可協議開放Nemotron 3 Super的權重、數據集與訓練方案,開發者可在工作站、數據中心或雲端自由部署與定製。
英偉達同步公開了完整的訓練與評估方案,涵蓋預訓練至對齊的全流程,並發布超過10萬億token的預訓練及後訓練數據集、21個強化學習訓練環境以及評估方案。預訓練階段,模型在25萬億token上以NVFP4原生精度訓練,從首次梯度更新起即在4位浮點運算約束下學習準確性,而非事後量化。
在生態層面,英偉達已與谷歌雲Vertex AI、甲骨文雲基礎設施、戴爾技術、HPE等主流雲服務商及硬件廠商達成合作,亞馬遜AWS Bedrock及微軟Azure的接入亦在籌備中。CodeRabbit、Factory、Greptile等軟件開發智能體公司,以及生命科學機構Edison Scientific和Lila Sciences,也已宣佈將該模型整合至其智能體工作流。
"Super+Nano"組合部署
英偉達在博客中還闡述了Nemotron 3系列的協同部署邏輯。去年12月推出的Nemotron 3模型Nano版本適合處理智能體工作流中針對性的單步任務,Nemotron 3 Super則專為需要深度規劃與推理的複雜多步驟任務而設計。
以軟件開發場景為例,英偉達建議:簡單的合併請求可由Nano處理,涉及對代碼庫深度理解的複雜編碼任務交由Super承擔,而專家級任務則可進一步調用第三方專有模型。這一分層架構旨在幫助企業在成本與能力之間尋求最優平衡。
在具體應用場景上,英偉達博客舉例稱,軟件開發智能體可將整個代碼庫一次性加載至上下文,實現端到端代碼生成與調試;金融分析場景下可將數千頁報告載入內存,省去跨長對話的重複推理;網絡安全中的自主安全編排場景則可受益於高精度工具調用,避免在高風險環境中出現執行錯誤。
硬件護城河的模型層延伸
英偉達此次開放模型策略背後是一套清晰的商業邏輯。此前,英偉達主要通過向OpenAI、谷歌等模型提供商出售GPU積累AI領域主導地位。如今,若Nemotron成為企業智能體AI的主流基礎模型,大規模運行該模型所需的GPU基礎設施仍將倚重英偉達——在模型層推進開放的同時,鞏固硬件層的需求鎖定。
目前,Nemotron 3 Super已通過英偉達NIM微服務打包交付,支持從本地到雲端的靈活部署。性能數據能否在生產級工作負載下得到驗證,以及企業客戶如何在開放靈活性與競爭對手專有模型能力之間做出取捨,將是檢驗這一戰略成效的關鍵變量。