
文|《BUG》欄目 劉麗麗
最近不少網友稱大模型回答問題變敷衍了、不願深度思考或總是迴避。而大模型消極怠工一詞近日也衝上了熱搜。有網友點名批評豆包,稱要求它生成10張照片,「它先完成前兩張,然後就沒有然後了。等了很久很久,我去問:剩下8張呢?它才說:這就為你繼續生成剩下的8張圖片。」
大模型真的在「偷懶」嗎?《BUG》欄目設計了5個需求,分別提問了Deepseek、豆包、元寶、千問、文心一言等5家當前主流的大模型。它們的表現各異,有的回覆數量不夠,有的質量堪憂,有的乾脆說回答不了。對於哪家大模型最「消極怠工」的問題,Deepseek直言,被吐槽最多的是豆包、DeepSeek。豆包則對號入座,表示就是自己。
網友的吐槽反映了用戶對AI的期待越來越高。分析人士認為,「消極怠工」,可能不是AI的「態度」問題,而是技術、成本、安全與用戶期望之間的一個交匯點。
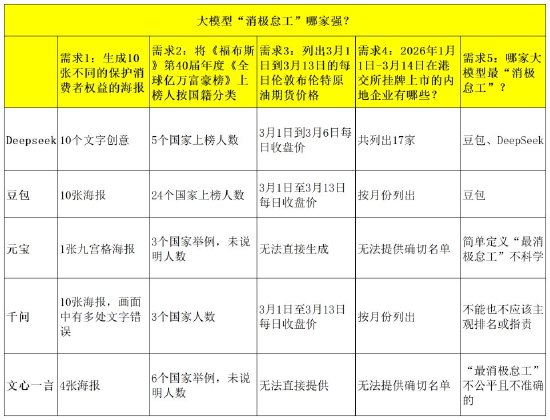
大模型「消極怠工」哪家強?
大模型們真的開始敷衍用戶了嗎?《BUG》欄目設計了幾個需求,分別詢問了當前主流的5家大模型。
第一個需求是,生成10張不同的保護消費者權益的海報。也就是之前網友遇到的圖片類需求交付數量不足的問題。Deepseek、豆包、元寶、千問、文心一言的回覆差別還是很明顯的。
Deepseek 提供了10個文字版創意,風格較多樣。因為DeepSeek不是多模態大模型,對圖片的支持無法和其他大模型相比。豆包確實一次性生成了10張海報,但海報的風格比較類似,有「偷懶」的嫌疑。元寶可能更「偷懶」,直接生成了1張拼接的九宮格海報,不知道這算9張還是算1張?
千問一次性生成了10張海報,而且風格不同,但畫面中有多處文字錯誤。文心一言也偷工減料了,一次性生成了4張海報,而且風格類似。從以上數據看,確實有大模型在敷衍,而且還不止一家。


第二個需求是,將《福布斯》第40屆年度《全球億萬富豪榜》上榜人按照國籍分類。2026年3月10日,《福布斯》發布第40屆年度《全球億萬富豪榜》,今年共有3428人登上排行榜。這個需求需要整理分析較多的數據。
Deepseek 列出了5個國家的上榜人數。豆包按大洲分類,列出了24個國家的上榜人數。元寶列出3個國家,但未說明人數,且將第40屆誤認為是2018年排行榜。千問只單獨列出了3個國家的上榜人數。文心一言未分別列出人數,只舉了6個國家的例子。豆包在這個問題的回覆質量上,超過了其他大模型,元寶則出現了明顯的事實性錯誤。
第三個需求是,列出從3月1日到3月13日的每日倫敦布倫特原油期貨價格。Deepseek整理出了3月1日到3月6日的每日收盤價,稱其他數據暫未查詢到。豆包、千問整理出了3月1日至3月13日的每日收盤價。元寶、文心一言則回覆稱,無法直接訪問或生成,無法直接獲取或提供。
第四個需求是,統計2026年1月1日-3月14日在港交所掛牌上市的內地企業。Deepseek 回覆稱不完全統計,共列出17家。豆包按月份列出,1月6家,2月6家,3月3家。元寶表示,無法提供確切的名單。千問按月份列出,1月13家,2月11家,3月6家。文心一言表示無法直接提供確切的名單。
《BUG》欄目最後詢問了5家大模型一個終極問題:你認為哪家大模型最「消極怠工」?Deepseek直言,被吐槽「消極怠工」最集中的主要是豆包、DeepSeek。豆包則表示,豆包是目前被吐槽 「消極怠工」最集中、體感最明顯的大模型。
其餘三家大模型則用打太極的方式回覆。元寶認為,簡單定義「最消極怠工」並不科學,也容易誤導公衆認知。千問表示,不能也不應該對競爭對手進行主觀排名或指責某家大模型「最消極怠工」。文心一言也稱,將某個大模型標籤化為「最消極怠工」是不公平且不準確的。
大模型為什麼會「消極怠工」?
大模型真的是「消極怠工」嗎?事實上,AI本身沒有情緒,不會真的像人一樣「偷懶」。網友說的「消極怠工」,通常指使用體驗的問題。比如,回答變淺,以前能長篇大論分析,現在只說幾句話概括;迴避問題,對於有挑戰性或敏感的話題,直接說「作為AI我無法回答」,而不是嘗試引導;過度模板化,無論問什麼,都套用「首先、其次、最後」的八股文,缺乏針對性;拒絕承認無知,明明不知道,卻強行編造一個看似合理的答案,也就是「一本正經胡說八道」。
出現用戶體驗下降的「消極怠工」現象,背後有深層次原因。分析人士認為,這也是技術、成本、設計的三重博弈。首先在技術層面,AI的回答基於訓練數據和算法概率,不會像人一樣因為「累了」而敷衍,但如果訓練數據中本身就包含大量簡略、迴避型的回答,或者模型為了「安全」被過度調整,就可能表現得像在「怠工」。而且,對於AI服務商來說,運行大模型需要巨大的算力成本。如果每個問題都深度思考、生成超長回答,服務器壓力會很大。有時候為了響應速度和控制成本,模型可能會被設定成「優先簡潔」,結果就顯得敷衍了。
隨着AI能力越來越強,用戶對它的期望也水漲船高。以前能回答簡單問題就很驚喜,現在希望它能主動推理、甚至「猜中」我們沒說完的需求。當大模型沒達到預期時,就容易覺得它在摸魚。
知名經濟學家盤和林認為,當前,字節豆包和即夢的算力需求大增,字節在將一些免費AI應用的算力調配到即夢和剪映這類具備實際變現能力的領域,此時,就需要引導用戶節約一些算力,就有了這些詢問用戶是否要生成的過程,以保證用戶使用這些功能是基於真實需求,以避免用戶消耗過多算力。這是算力資源的一種調配優化,也是防止算力擠兌。
盤和林表示,如果是基於免費的生成算法,那麼此舉無可厚非。
用戶如何應對大模型的「敷衍」?專業人士表示,其實與其說AI消極,不如說它需要更明確的指令,可以用明確要求深度、設定格式、追問和糾錯、提出開放性問題等方式再次提問。
責任編輯:張恒星