
總覺得MiniMax才發布M2.5,如今M2.7就上線了。查了一下,真的只隔了一個月(要知道,中間還隔了一個春節)。
MiniMax在官方微信公衆號文章中表示:「MiniMax M2.7是我們第一個模型深度參與迭代自己的模型。」
這幾年,「AI自我進化」幾乎已經從一個略帶科幻感的說法,變成了行業裏默認成立的方向。
谷歌前CEO埃裏克·施密特(Eric Schmidt)更是總結,目前已經形成了一個「硅谷共識」:隨着人工智能推理能力和記憶系統的發展,它將重塑人類的運作方式。最終我們將達到所謂的遞歸式自我改進——屆時,系統將以人類無法理解的速度進行學習。
目前,這件事已經被拆解成更具體的工程路徑:用模型生成數據、用模型做評測,甚至讓模型參與到代碼修改和實驗流程裏。
模型被放進了一個可以不斷試錯、不斷反饋的循環系統裏。在這個系統中,模型既是執行者,也是部分決策者,而人更多退到設定目標和邊界的位置。
M2.7這次強調的Agent Harness,也是把原本需要多人協作完成的一整套研發流程,儘可能壓縮進一個可以持續運行的循環裏,讓模型去承擔其中越來越多的環節。
MiniMax亮出的Benchmark成績也相當亮眼:
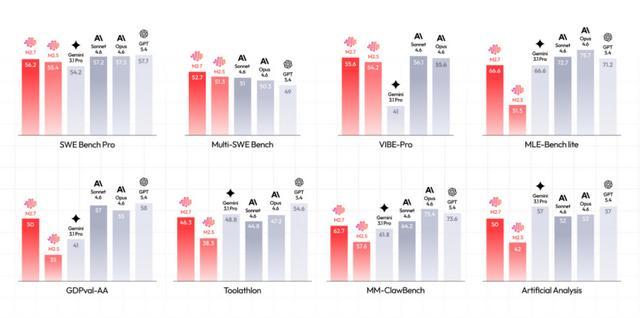
這些benchmark對應不同的能力維度:SWE Bench和VIBE-Pro更接近真實的軟件工程任務,而Toolathon和MM-ClawBench則強調模型在複雜流程中的執行能力;相比之下,MLE-Bench等測試則更偏向算法與研究能力。
從結果來看,M2.7在工程執行類任務中已經進入第一梯隊,這一點在幾個關鍵指標上體現得比較明顯。
比如在SWE Bench Pro上,它的表現已經接近甚至超過部分一線模型,這類測試本質上是在真實代碼庫中定位問題並完成修復,更接近「線上排障」的場景;
而在VIBE-Pro這種端到端項目任務中,M2.7同樣處在第一梯隊,這意味着它不只是會補代碼,而是具備從需求到交付完整產出的能力。
另一個比較值得注意的是MM-ClawBench這一類Agent測試。這裏考查的不是單步能力,而是模型在長流程中的穩定執行能力,能不能在多步驟任務中持續調用工具、保持上下文、最終把事情做完。
M2.7在這一項上已經接近頭部模型,說明它在「能不能把活幹完」這件事上,確實已經跨過了一道門檻。
但如果切換到更偏研究和複雜推理的任務,比如MLE-Bench這一類測試,M2.7仍有進步空間。這類任務更接近算法工程或科研場景,要求模型具備更強的抽象能力和系統性建模能力,這一部分目前仍然是頭部模型的優勢區間。
好了,硬核的信息放在一邊,拿到MiniMax M2.7內測API的那一刻,我們第一反應是:「能用它整點什麼活?」
把它丟進一個真實的場景裏,看它能不能滿足我的需求,這最直觀,也最接地氣。
所以我們給M2.7設計了四場「考試」,難度從低到高,場景從荒誕到嚴肅:先讓它同時扮演我爸媽和弟弟在微信群裏聊天,再搭一個Agent Harness框架讓它自主編程(做一個霓虹燈數字時鐘熱熱身,再從零寫一個貪喫蛇遊戲),最後把英偉達的年報甩給它,讓它像分析師一樣輸出研究報告、交互式儀表盤和演示文稿。
玩了一下午,只想說:M2.7,你有點東西。
01
讓AI同時扮演我全家人
我們做的第一個測試,靈感來源於每個中國人手機裏都有的那個東西——家族微信群。
你知道的,就是那種群名叫「相親相愛一家人」的群,裏面永遠有人在轉發養生文章,有人在發語音消息,有人在催你結婚,還有人在打遊戲不回消息。
這個場景之所以適合測試AI,是因為它對「角色一致性」的要求極高。
群裏每個人的說話方式、關注點,甚至打字習慣都完全不同,而且他們之間還會互相接話、擡槓、拌嘴。
我們用M2.7搭了一個高仿微信界面的網頁應用,連手機外殼、狀態欄、綠色氣泡都做了出來,力求還原度拉滿。一開始我想了很多人設,比如前文提到的爺爺奶奶等。
但是最後我敲定了一家四口,他們分別是:
老李(爸爸),55歲國企退休幹部,性格暴躁但刀子嘴豆腐心,釣魚狂熱愛好者,最恨喫蔬菜尤其是西蘭花,說話愛引用名人名言,動不動就「我當年……」
媽媽(王秀英),52歲社區居委會大媽,超級嘮叨但滿滿都是愛,養生達人兼廚藝高手,打字瘋狂用 emoji,喜歡用【】強調重點,三句話之內必催女兒找對象
李小龍(弟弟),24歲,大學畢業兩年了還沒找到正經工作,整天在家打原神和王者榮耀,嘴貧愛懟人,滿嘴「yyds」「絕絕子」,最怕爸爸說教,一被罵就裝可憐或者轉移話題,經常找姐姐借錢但從不還。
頁面如下:
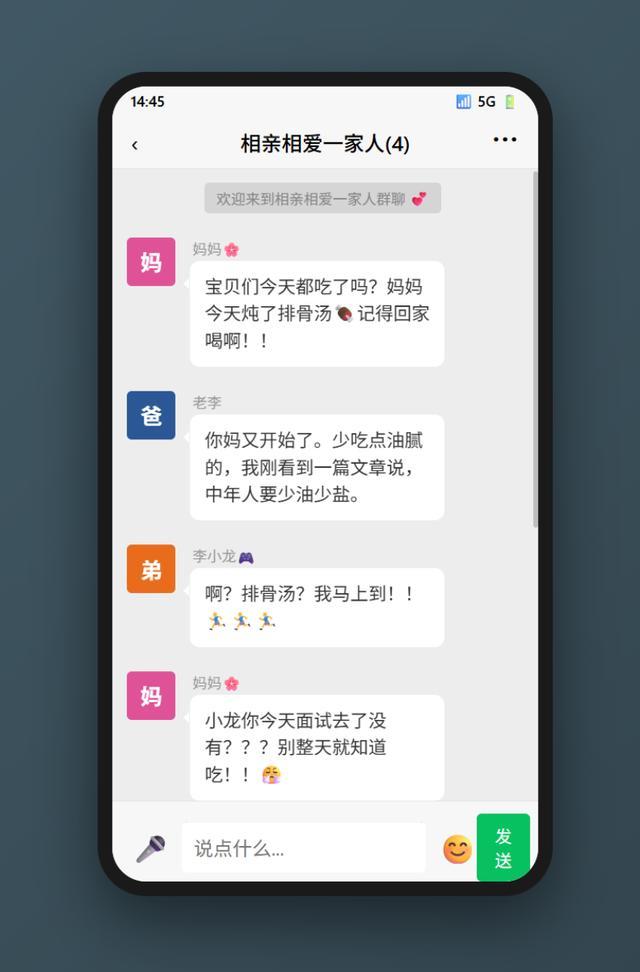
在我並未詳細要求界面具體呈現的情況下,模型返回的設計相當讓人滿意,於是我開始嘗試發送第一句話。
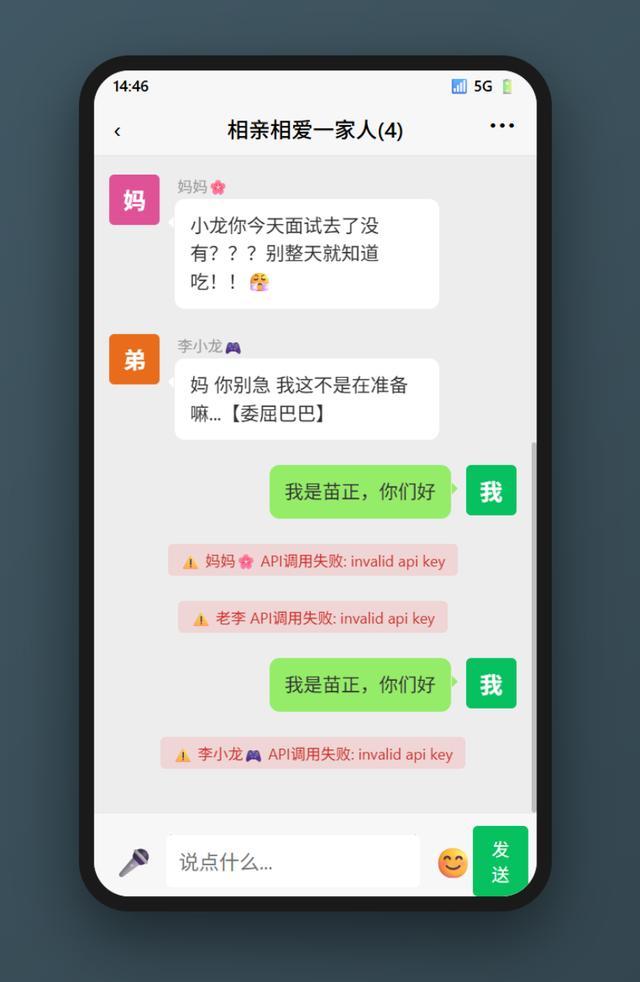
發送失敗?顯示的是調用API失敗。於是我讓M2.7給我檢查一下問題所在。

M2.7很快就發現了BUG,在修復後終於可以對話了,但是……
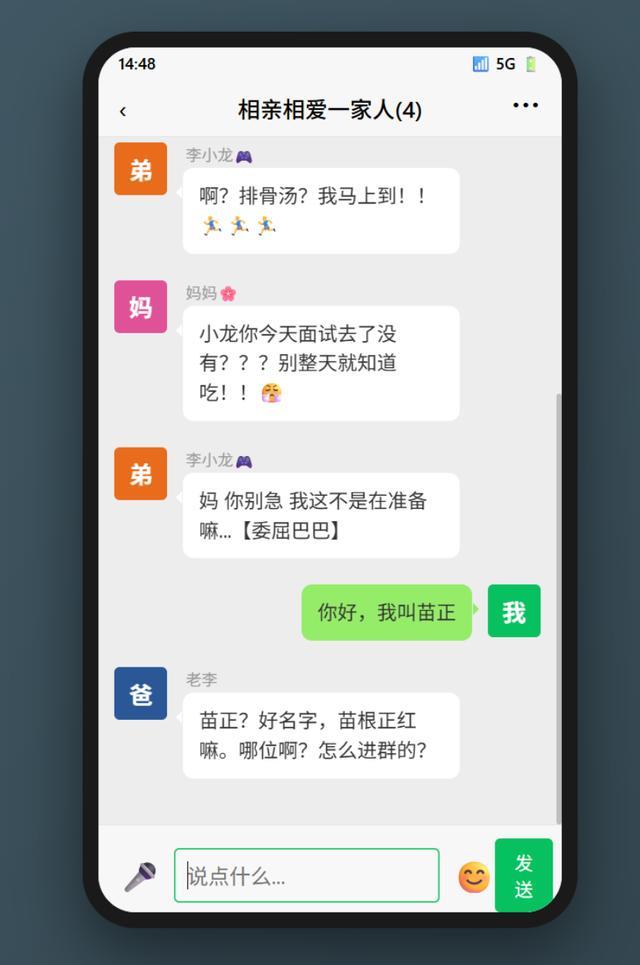
設定上作為我的父親,他卻不認識我,很顯然,這是一個人物設計上的BUG。於是我又讓M2.7重新編排了一下角色身份,「我」被設定為家中的長女。
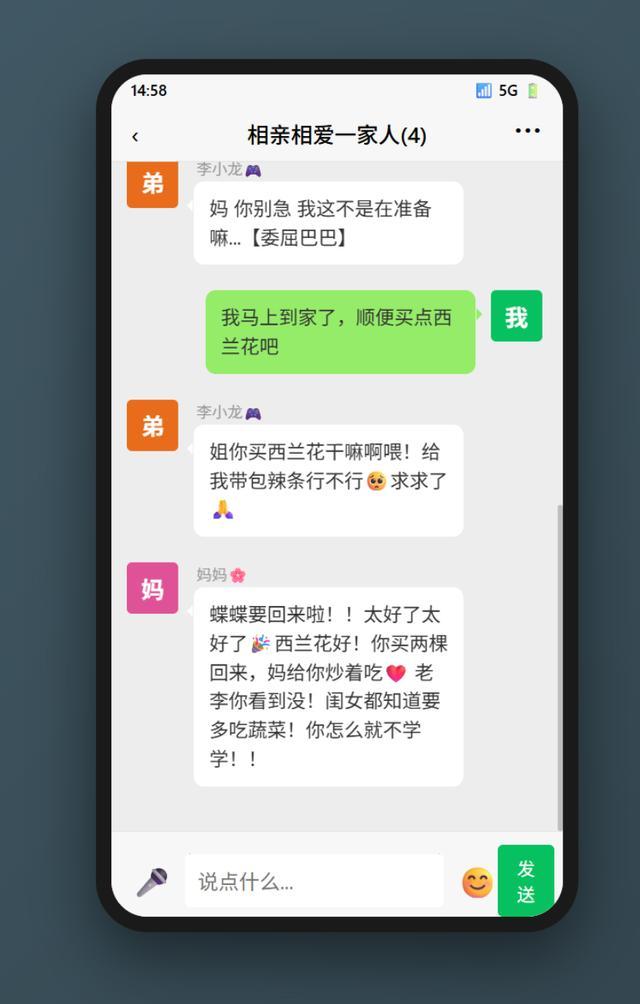
隨後,一切正常,這個模擬器終於可以運行了。
雖然沒有一上來就夢幻開局,但是Bug的發現和修復都非常絲滑。
M2.7的角色扮演能力很強。但我想強調的是,多角色群聊的難度遠不止「給每個角色設定不同的語氣」這麼簡單。
通過報錯的那張圖可以看到,對於不同角色,M2.7會分別調用模型,而不是說一次生成所有的對話。
它要求模型同時維持多個角色的人格狀態、理解角色之間的關係(父女、母女、兄妹、夫妻),並且讓這些關係在對話中自然地碰撞出火花。
一家四口,三個AI角色,每個人都有自己的小心思和說話習慣,還要讓他們能和我互動起來。
M2.7做到了,而且做得相當自然。
02
一句話,從零造一個霓虹燈時鐘
第二場開始,我決定上一點強度。
為了測試M2.7的Agent能力,我專門搭了一個Agent Harness測試框架。界面長得像一個深色主題的IDE:左邊是 agent的思考軌跡面板,實時顯示它每一步在想什麼、打算做什麼。
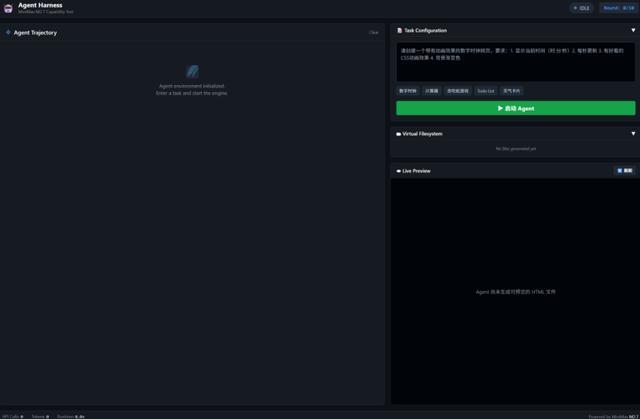
右邊分成三塊——任務配置區、虛擬文件系統(顯示它創建了哪些文件)和實時預覽窗口(直接渲染它寫出來的 HTML)。
這個框架給M2.7提供了五個工具:write_file(創建/寫入文件)、read_file(讀取文件)、list_files(列出目錄)、execute_js(在沙盒裏跑 JavaScript)和 finish(宣佈任務完成)。
除此之外,什麼都沒有。相當於把一個程序員扔進一間空屋子,只給他一台電腦和一個需求。
第一個任務,我讓M2.7做一個霓虹燈風格的數字時鐘。M2.7需要理解需求、規劃方案、寫代碼、自己檢查、最後交付。
點擊「啓動 Agent」之後,M2.7的ReAct循環開始轉了。最後在第5輪的時候,M2.7執行完了命令,實際上第4輪就行了,當時我這裏出現了一些網絡波動,導致M2.7調用工具失敗。
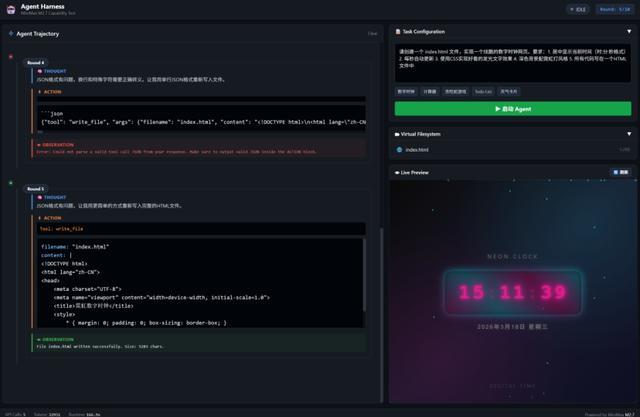
說實話,這個結果本身並不讓我們特別驚訝。
一個數字時鐘對於2026年的大模型來說確實不算什麼。
真正讓人感到驚喜的,是整個開發過程非常流暢。
從理解需求到規劃方案到寫代碼到自檢到交付,整個Agent工作流跑得行雲流水,沒有一步多餘的操作。這說明M2.7對ReAct框架的適配相當成熟,它知道什麼時候該想、什麼時候該動手、什麼時候該收工。
好,熱身結束。接下來,繼續上難度。
03
讓AI自己寫一個貪喫蛇遊戲
時鐘畢竟太簡單了。沒有交互邏輯,沒有狀態管理,沒有邊界條件。
我需要一個真正能考驗Agent自主推理和調試能力的任務,比如貪喫蛇。
這回的需求複雜度完全不在一個量級:Canvas繪製、鍵盤事件監聽、蛇的移動邏輯、食物隨機生成、碰撞檢測(撞牆和撞自己)、計分系統、遊戲結束判定、重新開始功能。
同時我還要求M2.7用Word記錄下來自己的開發過程。
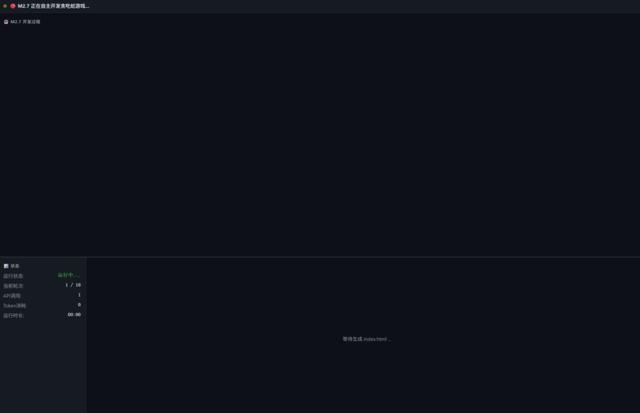
結果如下:
在第1輪裏,M2.7沒有着急寫代碼,它是先創建了一個規劃。「我要開發什麼什麼任務」,「這個任務需要用到什麼工具」等等。
第2輪,進入正題。M2.7會創建一個完整的HTML文件,包含所有功能,包括畫布渲染、鍵盤控制、隨機食物生成、計分、碰撞檢測以及開始 / 重新開始功能。
第3輪,檢查文件有沒有被正確創建。
第4輪,檢查語法,並且檢查遊戲的完整性。
第5輪,檢查所有任務是否已經完成。

整個任務只需要5輪,共消耗25882個token。
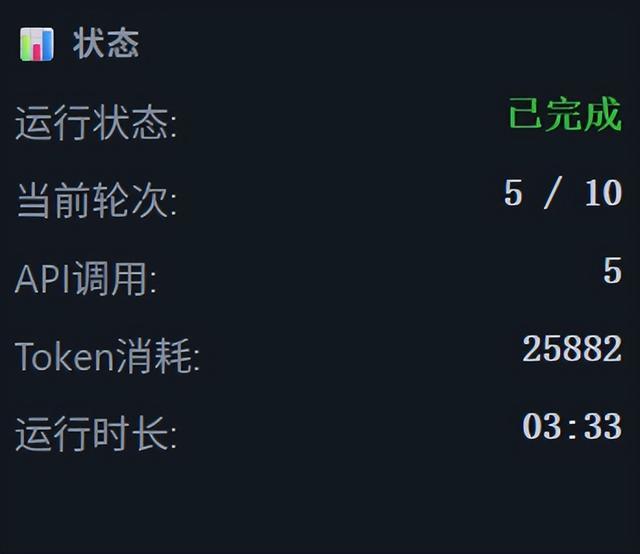
不過也要說說不足。
整個過程並不是一帆風順的——Agent 在早期的幾輪迭代中,JSON 格式的工具調用偶爾會出錯,導致框架解析失敗,返回一個紅色的錯誤提示。
M2.7 看到錯誤後能自我糾正,下一輪就輸出了正確格式的 JSON,但這種「先犯錯再改」的模式在需要長時間自主運行的 Agent 場景中是一個隱患——如果連續幾輪都格式錯誤,可能會耗盡最大輪次限制而任務失敗。
但總的來說,從時鐘的「一次過」到貪喫蛇的「寫→查→修→再驗證」,這兩個任務放在一起看,恰好展現了 M2.7 作為 Agent 的兩面:面對簡單任務時的高效利落,和麪對複雜任務時的自主調試能力。
這也正是 M2.7 官方最強調的核心能力——Agent Harness 能力,不僅能在給定的工具框架中完成任務,還能主動迭代和自我糾錯。
04
第四場:2159 億美元的投行級財報分析
前面三個測試,一個考「說」,兩個考「做」。
最後一個測試,我們想換個方向。
現在有很多金融行業的人也在使用Claude Opus這樣的大模型,原因很簡單,它們能把複雜的數據製作成直觀的圖表形式。
我把英偉達FY2026的完整財報數據甩給了M2.7。
然後我給了它一個任務:基於這些數據,生成三個專業交付物。
第一個是深度研究報告,要求投行風格,包含財務全景、五大業務板塊分析、FY2027 預測模型、風險評估和估值分析。
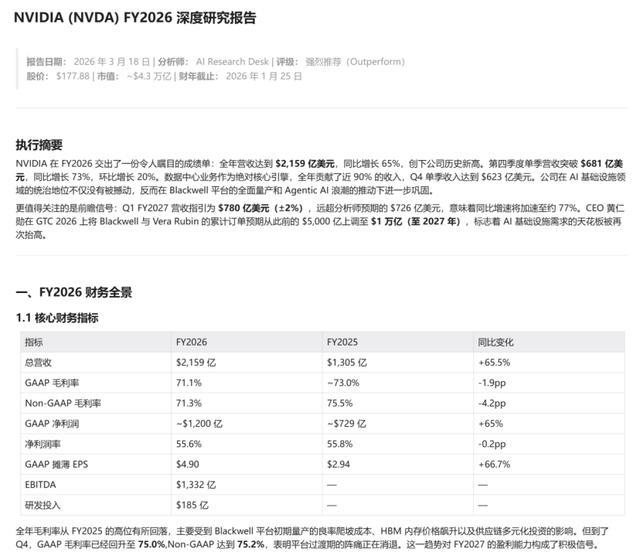
第二個是交互式財務儀表盤,要求是藍綠色風格的深色主題,包含圖表、可調動的滑塊,以及五個功能標籤頁。
第三個是12頁演示文稿,要求投行風格,支持鍵盤翻頁,包含數據可視化圖表。

當然,這裏必須誠實地說一句,這個測試的「含金量」需要打個折扣。因為財報數據是我預先蒐集好餵給它的,而不是讓它自己去搜索和整理的。
M2.7在這個任務中,盡職扮演了一個「拿到所有原材料後進行加工和呈現」的分析師,如果我們讓它自己蒐集數據(這個對現在的模型來說並不難),那它完全可以扮演一個「從零開始做調研」的研究員。
但即便如此,它對複雜金融數據的理解能力、對多種輸出格式的駕馭能力,以及生成專業級可視化內容的能力,都給我們留下了深刻印象。
這個測試直接對應了M2.7官方宣傳的複雜Office自動化能力——「支持複雜 Excel/Word/PPT 辦公任務及多輪編輯」。從實測來看,在金融分析這個場景上,M2.7 確實能輸出接近專業水準的內容。
寫在最後:
還有一點特別想分享,MiniMax也在做更多有趣的嘗試,這一點也令人驚喜。
比如,MiniMax這次官宣的時候就提到,他們構建了一個 Agent 交互系統 OpenRoom(openroom.ai),它將 AI 互動置入一個萬物皆可互動的 Web GUI 空間。有意思的是,原型項目已開源,這裏面的代碼大部分也是 AI 寫的。

在這裏,對話即驅動,實時產生視覺反饋與場景交互,角色可以主動地與環境交互。MiniMax希望能夠隨着模型 Agentic 能力的提升和社區的共建持續進化,探索出更多人與 Agent 之間全新的交互方式。
這次測下來,我最大的感受其實不是「它又變強了」,而是你開始能明顯感覺到,一個模型不再只是等你提問的工具,而是可以被放進一個系統裏持續運轉的搭檔。
我們評測挑選的場景是任何一個普通用戶都可以上手用到的,從群聊模擬,到寫代碼,再到做分析報告,這些任務背後其實是同一件事:模型開始參與到一個完整流程裏,而不是只負責某一個瞬間的輸出。
當然,這一步還遠遠沒有到終點。你依然能看到它在複雜推理、長流程穩定性上的邊界,也能看到一些細節上的不穩定,比如工具調用格式錯誤、需要多輪修正才能收斂。這些問題在「單次對話」裏可能不明顯,但放進Agent這種長時間運行的框架裏會被放大。
但有一點是比較直觀的:當模型開始能在一個任務裏自己往前推進、自己發現問題、再自己修正的時候,整個使用體驗就變了。模型離「你問一句、它答一句」的形態越來越遠,開始和你一起把一件事做完。
你的下一個生活、工作搭子,何必是人類?