IT之家 3 月 17 日消息,科技媒體 9to5Mac 昨日(3 月 16 日)發布博文,報道稱蘋果 AI 研究團隊發布研究報告,攻克了 3D 重建領域的一項核心難題:僅通過單張平面圖像,就能重建出完整的 3D 對象。
該專利描述名為 LiTo(表面光場標記化)的最新模型,打破了傳統方法需要多角度圖像輸入的限制,在重建 3D 對象之後,用戶切換不同觀察視角後,該模型生成的反光、高光等光影效果依然能保持高度的物理真實與一致性。
這項突破的核心在於對創新應用「潛在空間」(Latent Space)。在機器學習中,潛在空間能將複雜信息壓縮成多維數學向量,從而大幅降低計算成本。
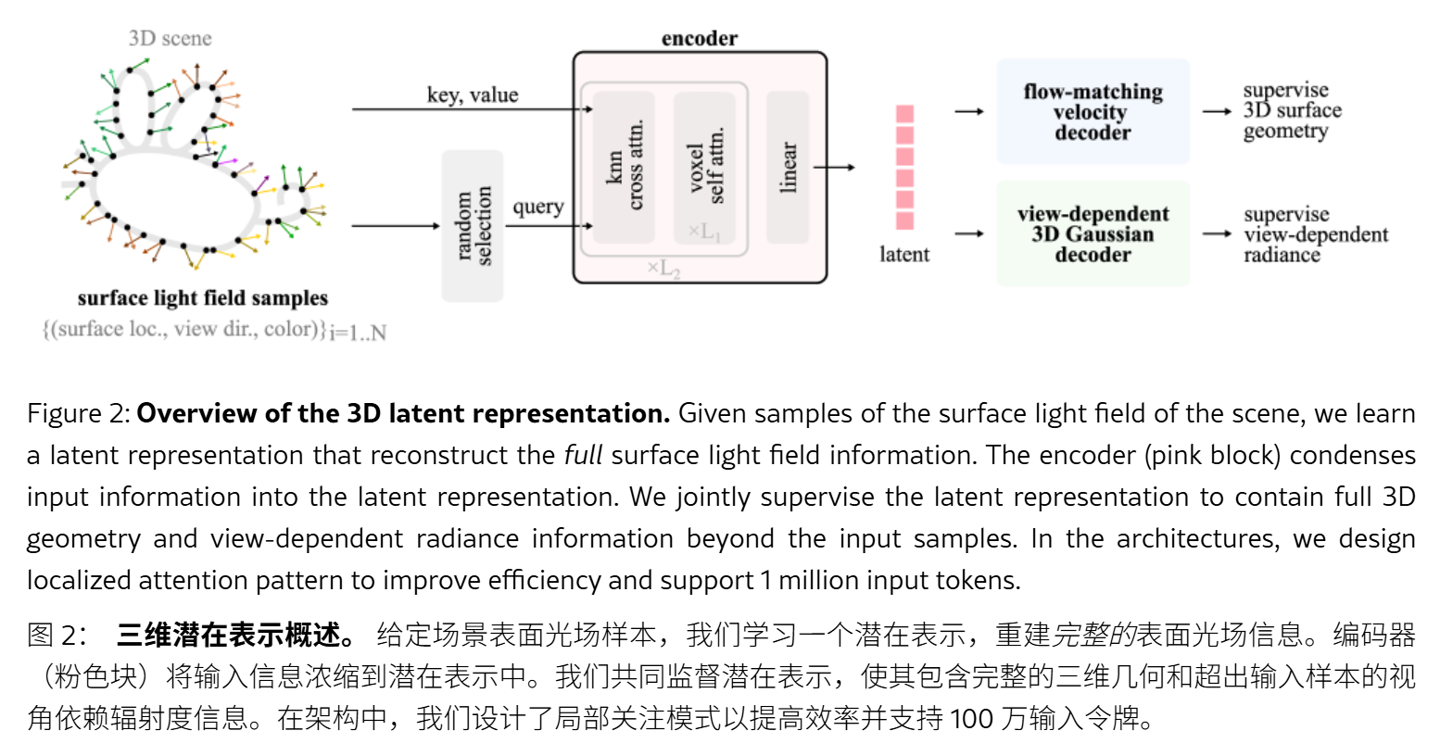
LiTo 模型首創了一種統一的 3D 潛在表示法,將隨機採樣的表面光場數據編碼為緊湊的向量集。這意味着模型無需死記硬背每一個視覺細節,而是通過數學描述,同時掌握了對象的物理形狀以及光線與其表面交互的底層規律。
在具體運行機制上,LiTo 編碼器負責「壓縮信息」,將輸入圖像中的幾何結構和視角相關的外觀特徵,轉化為潛在空間中的精簡代碼。
隨後,解碼器執行「逆向解壓」,利用這些底層代碼完整還原出 3D 對象。這種雙向機制讓模型能夠精準復現複雜光照條件下的鏡面高光和菲涅爾反射等高級光影效果。
為打造該模型,蘋果研究人員使用了數千個在 150 個不同視角和 3 種光照條件下渲染的 3D 對象進行高強度訓練。系統通過不斷抽取小部分數據樣本,訓練解碼器在不同光照和視角下還原完整對象。
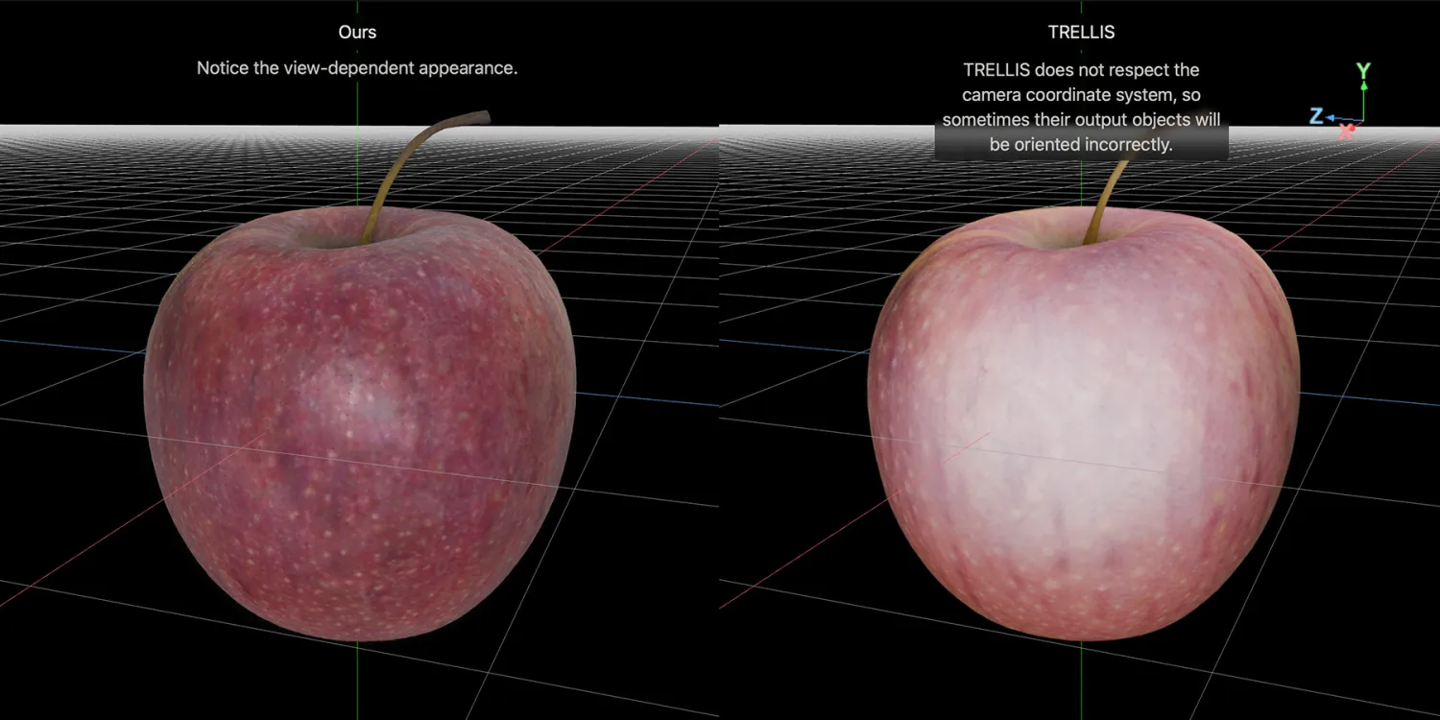
最終,模型具備了僅憑單張圖片就能預測其三維潛在表示的能力。在蘋果公布的官方對比測試中,LiTo 在多視角光影還原度上顯著超越了現有的 TRELLIS 模型。