IT之家 3 月 17 日消息,今日,理想汽車基座模型負責人詹錕出席 NVIDIA GTC 2026,發表主題演講《MindVLA-o1:開啓全能範式 —— 下一代統一視覺-語言-動作自動駕駛大模型探索》,發布了理想汽車的下一代自動駕駛基礎模型 MindVLA-o1。
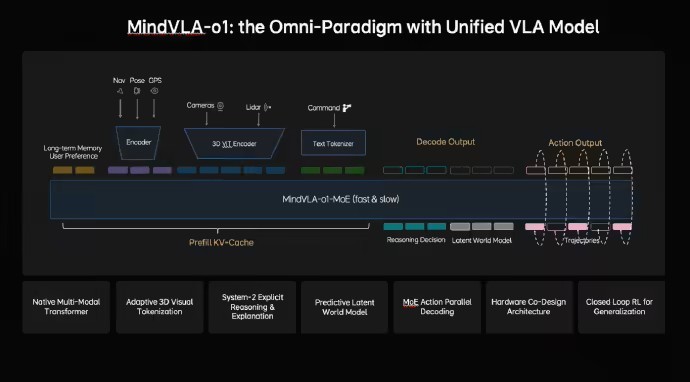
據介紹,MindVLA-o1 通過五大技術創新 ——3D 空間理解、多模態思考、統一行為生成、閉環強化學習和軟硬件協同設計,構建面向物理世界智能的自動駕駛基礎模型。
據IT之家了解,該模型的核心突破可以概括為以下五個維度:
看得更準(3D 空間理解):以前的系統更多是在處理平面圖像,而 MindVLA-o1 結合了攝像頭和激光雷達,通過 3D 編碼器讓車能夠像人類一樣感知物體的深淺、距離和運動狀態,真正理解三維物理空間。
想得更深(多模態思考):它是首個能「腦補」未來的模型。通過隱世界模型,它不僅看現在,還能在隱形空間裏提前「預演」未來幾秒可能發生的場景,從而做出更有預見性的決策。
行得更穩(統一行為生成):系統採用 VLA-MoE 架構,專門配備了「動作專家」。它能同時生成所有行駛軌跡點,並通過類似「去噪」的優化過程,確保車開得既絲滑又符合物理規律。
進化更快(閉環強化學習):理想構建了一個強大的世界模擬器。模型不僅在馬路上學,還能在虛擬世界裏進行大規模、高效率的自我練習和策略優化,大大降低了訓練成本。
部署更高效(軟硬件協同):通過研究模型精度與硬件延遲的平衡,理想將架構設計的時間從幾個月縮短到幾天,讓複雜的大模型能更流暢地跑在車端芯片上。