
聖何塞SAP中心,凌晨2點。黃仁勳再次穿着那件似乎永遠不會舊的黑皮衣走上台。這場長達2小時的演講中,老黃扔出了狂扔「核彈」。
第一顆炸彈:Vera Rubin平台。七款全新芯片全面投產,Vera Rubin平台由七款突破性芯片、五個機架和一個巨型超級計算機組成。同時發布Vera CPU,效率是傳統機架式CPU的兩倍,速度提升50%。
第二顆炸彈:1萬億美元。 黃仁勳在台上宣佈,英偉達目前看到了至少1萬億美元的需求訂單,覆蓋到2027年。
第三顆炸彈:Token成為商品。「Token是新的商品。」黃仁勳公開詳細闡述了AI工廠的商業模式——Token的分層定價體系,從免費層到premium層。
第四顆炸彈:為OpenClaw社區發布 NemoClaw。這款開源項目「在幾周內就做到了linux 30年才做到的事」,黃仁勳斷言:「每一家公司都需要OpenClaw戰略。」
這場發布會留下了太多需要消化的信息。芯片、工廠、機器人、AI Agent......每一個詞都可能是下一個萬億市場的入口。如果你今晚錯過了這場直播,這篇文章會告訴你黃仁勳到底說了什麼。
01
芯片核武器庫
Vera Rubin來了。
Vera Rubin是英偉達為「代理式AI」(Agentic AI)專門設計的新一代計算平台。
與上一代Blackwell 平台相比,Vera Rubin展現了驚人的效能躍進。該系統僅需1/4的GPU 即可完成混合專家大模型(MoE)的訓練,且每瓦推論吞吐量飆升高達10 倍,成功將單Token的生成成本降至十分之一。在基礎設施配置上,新一代的NVL72機架通過第六代NVLink連接了72塊Rubin GPU與36塊Vera CPU。黃仁勳特別指出,第六代NVLink交換系統是極度難以實現的技術,但英偉達成功達成了這項創舉。

此外,Vera Rubin系統採用100%液冷設計,使用45°C的溫水進行冷卻,徹底移除了傳統繁雜的纜線。這不僅大幅減輕了數據中心的冷卻壓力與能源成本,更將過去需要花費兩天才能完成的安裝時間,驚人地縮短至僅需兩小時。
該平台整合了Vera CPU、Rubin GPU、NVLink 6 交換機、ConnectX - 9 超級網卡、BlueField - 4 DPU和Spectrum-6 以太網交換機,以及新集成的Groq 3 LPU。這些芯片協同工作,構成一台強大的AI 超級計算機,為 AI 的各個階段提供支持——從大規模預訓練、後訓練和測試時擴展,到實時智能推理。
黃仁勳表示:「Vera Rubin 是一次代際飛躍——它由七款突破性芯片、五個機架和一個巨型超級計算機組成,旨在為人工智能的各個階段提供強大支持。」
Vera CPU強勢登場
本次大會的一大亮點,是英偉達首度展現其在中央處理器(CPU)領域的強大野心。英偉達最初於2022年GTC大會上發布了第一代Grace CPU,今晚老黃正式發布了Vera CPU和Vera CPU機架,標誌着英偉達正式進軍CPU直銷領域,成為傳統CPU市場中英特爾和AMD的有力競爭對手。
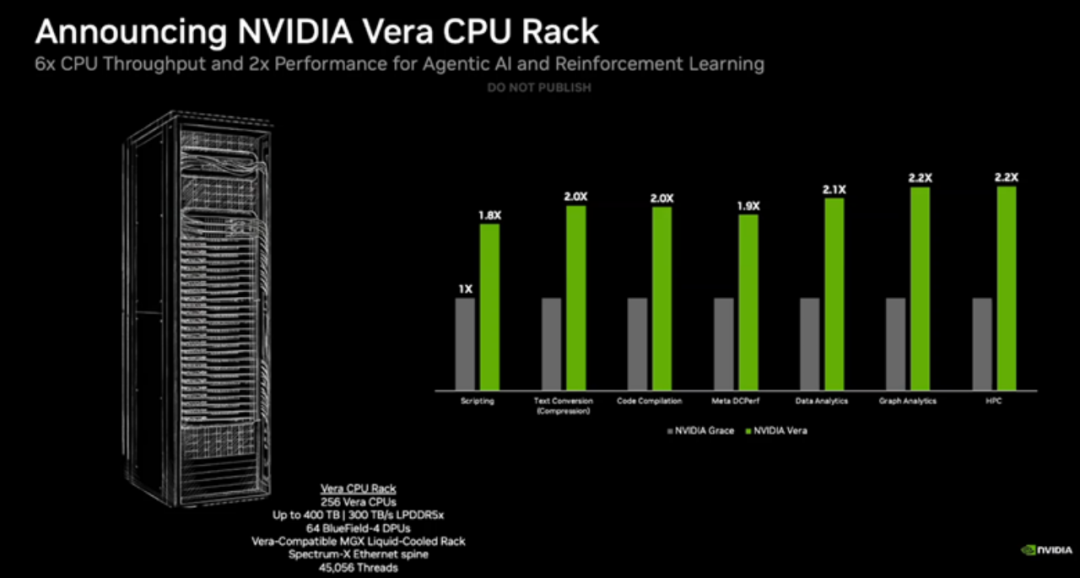
Vera CPU的定位是大規模數據處理、AI 訓練和智能體推理場景,其效率是傳統機架式CPU 的兩倍,速度提升50%。
為了應對AI使用工具時所需的極速反應,Vera CPU專為極高的單線程效能、強大的資料處理能力與極致的能源效率而設計。單顆Vera芯片配備了88個核心與144個線程,採用英偉達深度定製化的Arm v9.2-A Olympus核心,其指令級平行度(IPC)實現了1.5倍的代際提升。
更具革命性的是,該架構首發引入了"空間多線程(Spatial Multithreading)"黑科技,通過實體隔離流水線組件,讓多個線程能真正在單核上同時運行,徹底消除了傳統多線程技術因資源排隊而造成的算力損耗。Vera CPU也是全球首款採用LPDDR5的數據中心CPU,提供無與倫比的單線程效能與每瓦效能。
作為NVIDIA Vera Rubin NVL72平台的一部分,Vera CPU通過NVLink-C2C互連技術與GPU配對,提供1.8 TB/s的相干帶寬(是PCIe Gen 6帶寬的7倍),實現CPU和GPU之間的高速數據共享。
英偉達表示,阿里巴巴、CoreWeave、Meta和Oracle雲基礎設施,以及戴爾科技、HPE、聯想、超微等全球系統製造商都與NVIDIA合作部署Vera。同時,英偉達發布了Vera CPU機架,提供基於NVIDIA MGX的密集型液冷基礎設施,集成256個Vera CPU,可提供可擴展、節能的容量以及世界一流的單線程性能,從而大規模釋放智能AI的潛力。
Vera CPU目前已全面投產,預計將於今年下半年開始交付。
收購Groq後,LPU登場
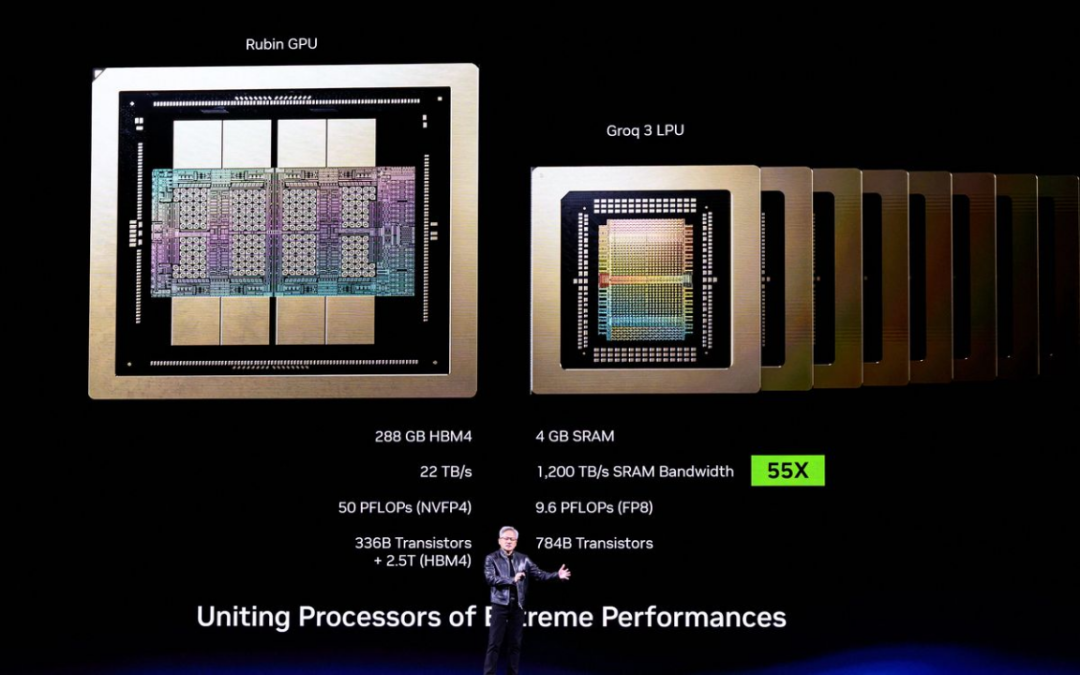
英偉達收購了開發Groq芯片的團隊,並將其技術與Vera Rubin深度整合。
為什麼需要LPU?
與大多數依賴HBM作為工作內存層的AI加速器不同,Groq 3 LPU每個芯片都集成了500MB的SRAM。這種內存也用於CPU和GPU的超高速緩存。雖然與每個Rubin GPU上容量高達288GB的HBM4相比,這顯得微不足道,但這塊SRAM可提供150 TB/s的帶寬,遠高於HBM的22 TB/s。對於帶寬敏感型AI解碼操作而言,Groq 3芯片帶寬的大幅提升為推理應用帶來了誘人的優勢。
兩種處理器的統一:LPU + Vera Rubin。「我們想出了一個絕妙的主意,」黃仁勳解釋道,「我們將推理過程完全重新架構。我們把適合Vera Rubin的工作放在Vera Rubin上,然後把解碼生成、低延遲、帶寬受限的部分卸載到LPU上。」
這兩種極端處理器的統一:一個為高吞吐量,一個為低延遲,產生了令人震驚的效果:每兆瓦功耗的推理吞吐量最高可提升35倍,萬億參數模型的收益機會最高可提升10倍。
「35倍,」黃仁勳重複了一遍,「這是世界從未見過的。」
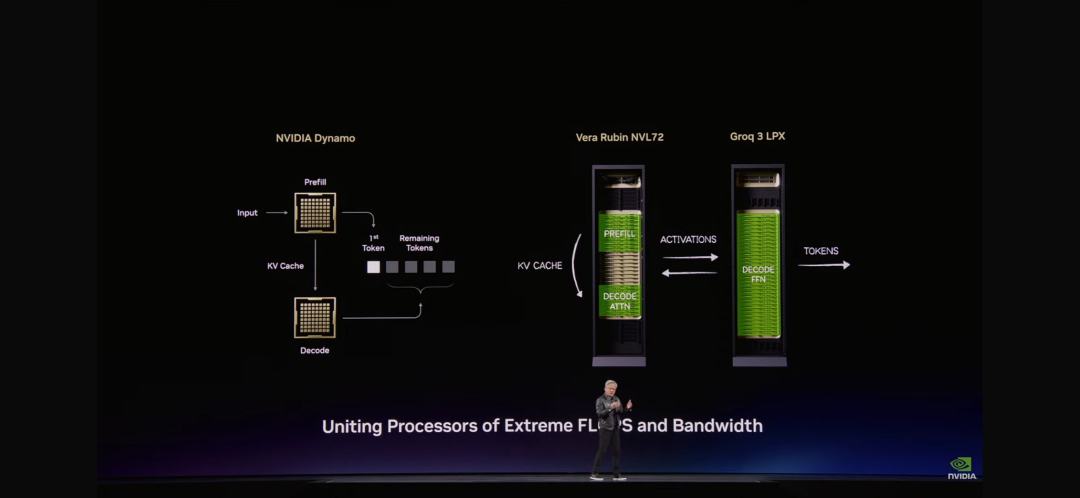

英偉達構建了包含256個Groq 3 LPU的Groq 3 LPX機架。該機架提供128GB的SRAM和40 PB/s的推理加速帶寬,並通過每個機架640 TB/s的專用擴展接口將這些芯片連接起來。
大規模部署時,LPU 集群可作為一個巨型單處理器,實現快速、確定性的推理加速。與Vera Rubin NVL72 集成,Rubin GPU 和 LPU 通過聯合計算每個輸出標記的 AI 模型每一層,顯著提升解碼速度。
LPX採用全液冷設計,基於MGX基礎設施構建,可無縫集成到將於今年下半年推出的下一代Vera Rubin AI工廠中。
重塑網絡與AI 原生存儲架構
在網絡連接與集群擴展方面,英偉達展示了全新一代的Kyber機架,這是一款專為Rubin Ultra 運算節點設計的系統。有別於傳統的水平插拔,Kyber 採用垂直插入設計,通過背板的中板(Midplane)連接,成功在單一NVLink 網域內連接多達144 個GPU,突破了傳統銅纜連接的距離限制。
同時,英偉達也與台積電合作,獨家量產名為COUPE的革命性共同封裝光學(CPO)技術,並應用於全球首款CPO Spectrum-X 交換器中,讓光學信號直接與芯片對接。
英偉達重新設計了整個存儲系統:BlueField - 4 STX 存儲機架。可將 GPU 內存無縫擴展到整個 POD(物理數據中心)。STX 由 BlueField-4 提供支持,BlueField-4 結合了Vera CPU和ConnectX-9 SuperNIC,可提供高帶寬共享層,該層針對存儲和檢索大型語言模型和智能 AI 工作流生成的海量鍵值緩存數據進行了優化。
太空計算也來了

在GTC大會上,老黃還發布了NVIDIA Space-1 Vera Rubin模塊,標誌着英偉達正式推出太空計算服務。與NVIDIA H100 GPU相比,該模塊上的Rubin GPU可為基於太空的推理提供高達25倍的AI計算能力,從而為ODC(分佈式計算中心)、高級地理空間智能處理和自主太空操作提供下一代計算能力。
根據英偉達官方新聞稿,Vera Rubin 空間模塊專為在太空直接運行 LLM 和高級基礎模型的軌道數據中心而設計,它採用緊密集成的CPU-GPU 架構和高帶寬互連,旨在實時處理來自太空儀器的大量數據流。
黃仁勳說到:「太空計算,這片最後的疆域,已經到來。隨着我們部署衛星星座並深入探索太空,智能必須存在於數據產生的任何地方。」

這場發布會還展示了完整的芯片路線圖。「每年一個全新架構,」黃仁勳總結道,「這就是英偉達的速度。」
02
1萬億美元:英偉達看到的需求
「5000億美元。」這是去年GTC大會上,黃仁勳公布的英偉達看到的高置信度需求和採購訂單。
當時他認為這個數字已經非常驚人。「但現在,一年過去了,就在我現在站的位置,我看到了至少1萬億美元的需求,覆蓋到2027年。」
為什麼需求會這麼大?「因為推理的轉折點已經到來。」黃仁勳在演講中詳細解釋了原因。
過去兩年發生了什麼?「三件事情。」黃仁勳回顧道。第一,ChatGPT開啓了生成AI時代。「它不只是理解和感知,還能翻譯和生成獨特的內容。」第二,推理AI(o1/o3)出現了。 「它能反思,能思考,能規劃,能把一個無法理解的問題分解成能理解的步驟。這讓ChatGPT真正起飛了。」第三,claude code出現了:第一個代理式模型。「它能讀文件、寫代碼、編譯、測試、評估、迭代。claude code徹底改變了軟件工程。」
黃仁勳說了一個關鍵數據:"過去兩年,AI的計算需求增加了大約1萬倍。AI現在必須思考。為了思考、為了執行、為了閱讀,它都必須推理。每一次交互,它都在推理。過去的訓練時代已經過去了。現在是推理的時代。」這就是1萬億美元需求的來源。每一個公司都在建設AI工廠,每一個工廠都需要Token生產。
Token是新的商品
「Token是新的商品。」當黃仁勳在GTC 2026上說出這句話時,整個AI行業的商業模式正在被重新定義。在黃仁勳展示的那張「最重要的圖表」上,橫軸是Token速率,縱軸是吞吐量。這張圖表將決定未來每一個CEO的決策——因為它直接關係到AI工廠的營收。
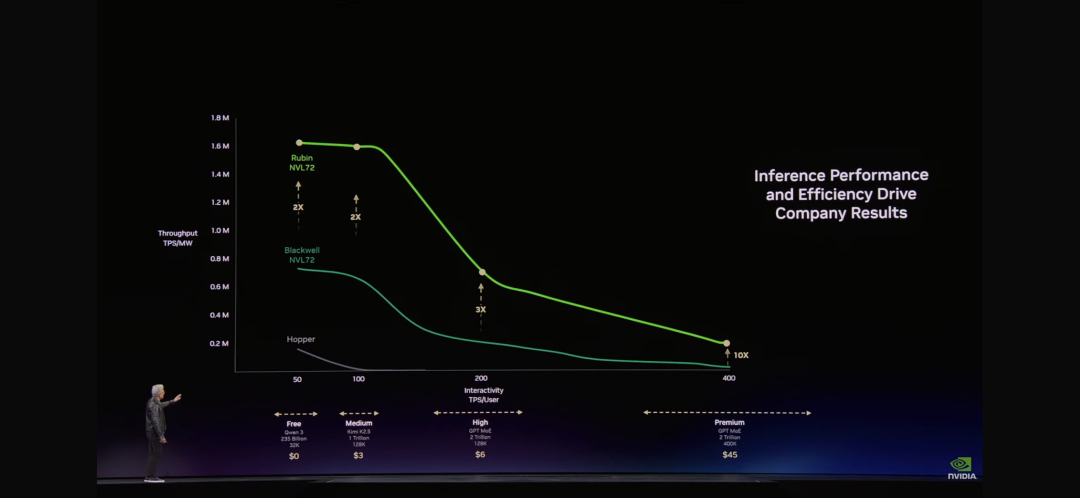
黃仁勳詳細解釋了AI工廠的商業模式,其中提到了Token的分層定價:
免費層:高吞吐量、低速度——用於吸引用戶
第一層:中等速度——$3/百萬Token
第二層:高速度、長上下文——$45/百萬Token
premium層:超高速度——$150/百萬Token
「就像任何行業一樣,"黃仁勳解釋道,"更高的質量,更高的性能,更低的容量。Grace Blackwell在你的免費層提升了巨大吞吐量,但在你最能變現的層級,它提升了35倍。Vera Rubin又在這個基礎上提升了10倍。
「假設你用25%的電力在免費層,25%在中等層,25%在高層層,25%在premium層。你的數據中心只有1吉瓦。你需要決定如何分配。」黃仁勳算了一筆賬:免費層吸引用戶,premium層服務最有價值的客戶。這種組合,按照這張圖表計算——Blackwell可以產生5倍的營收,Vera Rubin又是5倍。
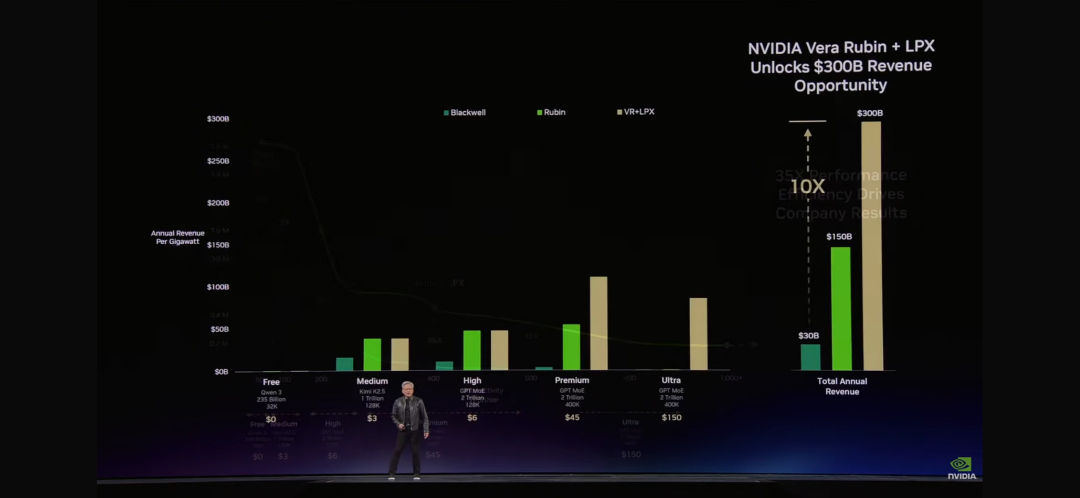
"你應該在Vera Rubin上儘快行動,"黃仁勳建議道,"因為你的Token成本會下降,吞吐量會上升。"
"在兩年時間內,在一個1吉瓦的工廠中,使用我之前展示的數學,摩爾定律只能給我們帶來幾個步驟的提升。但有了這個架構,我們的Token生成速率將從2200萬提升到7億——提升350倍。"這就是「極致協同設計」的力量。黃仁勳稱之為「垂直整合然後水平開放」的策略。
03
黃仁勳誇讚龍蝦
"OpenClaw是人類歷史上最受歡迎的開源項目。它在幾周內就做到了Linux 30年才做到的事。"
當黃仁勳宣佈英偉達支持OpenClaw時,全場再次沸騰。OpenClaw是一個Agentic系統(代理式系統)的操作系統。它連接大型語言模型,管理資源,訪問工具和文件系統,執行調度,創建子代理,這些能力讓它幾乎就是一個完整的操作系統。
「在OpenClaw出現之前,個人電腦因為Windows而成為可能,「黃仁勳說道,」現在,OpenClaw讓創建個人Agent成為可能。其含義是深遠的。」
Agentic系統可以訪問敏感信息、執行代碼、與外部通信,這帶來了巨大的安全挑戰。英偉達推出了NemoClaw,使用NVIDIA Agent Toolkit軟件,只需一條命令即可優化 OpenClaw。它安裝OpenShell,提供開放模型和隔離的沙箱,為自主代理增加數據隱私和安全保障。
04
結語
從一塊GPU到一座AI工廠,黃仁勳用十年時間完成了英偉達的進化。GTC 2026的大幕已經拉開。看完這場發布會,你最關心的問題是什麼?
你覺得英偉達的下一個十年會被"神化"還是"拉下神壇"?
評論區聊聊。