
編譯 | 陳駿達
編輯 | 李水青
智東西3月23日報道,在上周六發布的播客中,OpenAI聯合創始人、AI大牛Andrej Karpathy(安德烈·卡帕西)系統梳理了自己在AI編程和OpenClaw浪潮中的一線體感與方法論,他笑稱由於AI領域的飛速發展,自己彷彿出現某種「精神錯亂」,在不同新事物之間疲於奔命。他還發現,當下AI編程智能體的瓶頸已不只是模型能力:「Agent做不好,多半是Skill問題。」
「我現在幾乎一行代碼都沒再親自寫過。」在Karpathy看來,軟件工程的工作流已經在短短幾個月內被Agent徹底改寫。現在不是人寫代碼,而是人用自然語言調度一群智能體完成系統級任務。過去他80%代碼靠自己,如今變成80%交給Agent完成,甚至更高。
除了將Agent用於編程之外,OpenClaw的爆發也改變了Karpathy的生活。他打造了一個名為「多比」的OpenClaw,直接「接管」家庭,自動掃描並接入音箱、燈光、安防等設備,自主尋找API、建立控制面板,還能在陌生人接近時發預警。
這一經歷讓Karpathy得出判斷:許多App都應該是Agent可調用的API,Agent就是粘合劑。OpenClaw之所以特別,不是因為某個功能最強,而是它更接近人們心目中的AI形態。
值得一提的是,在預告這期播客的推文下,Karpathy在OpenAI的前同事、OpenAI o1模型作者之一Noam Brown發了一條頗有「火藥味」的推文,質疑Karpathy在這一關鍵時刻,為什麼不在AI前沿實驗室好好做研究。
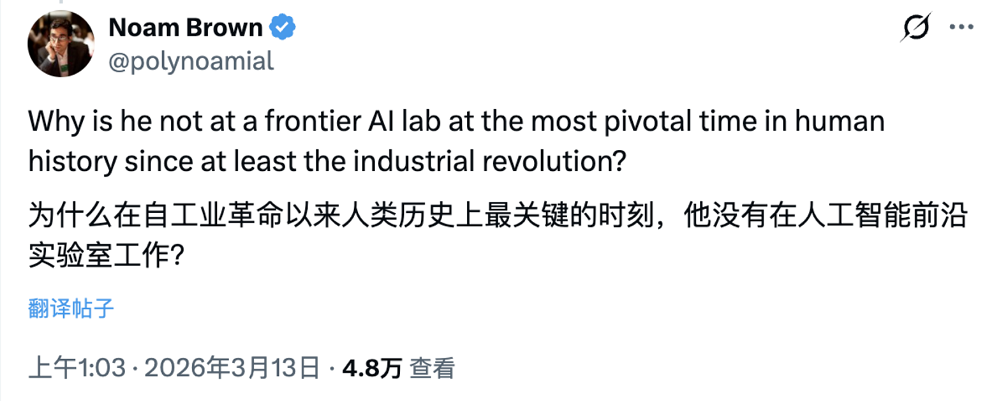
對此,Karpathy也在播客中做出正面回應,如果深度綁定一家前沿AI實驗室,就很難保持完全獨立的立場,離開後反而與人類整體的立場更為對齊。財務激勵與社會責任之間存在「利益衝突」,這也是OpenAI創立時就存在的問題,至今未能解決。
Karpathy認為,在前沿AI Lab幹一段時間,做一些高質量工作,然後再離開,是個不錯的方式——既能跟上真實進展,又不至於完全被某個實體控制,還給生態做了貢獻。這番表態,頗有點「普羅米修斯盜火」的意味,或許真是他從OpenAI急流勇退的原因。
在這期播客中,Karpathy還就自動化研究、大模型能力「鋸齒化」、開源與閉源競爭格局,以及AI對就業與軟件形態的重構分享了自己的思考,以下是這期播客的核心內容:
1、AI編程:去年12月以來,AI編程的範式已經徹底改變,如今人其實不是在編程,而是在向Agent表達自己的想法。
2、生產力焦慮:行業目前最焦慮的已經不是能不能跑滿GPU了,而是能不能用完token,「訂閱沒用完我就焦慮,說明我的token吞吐量沒拉滿。」
3、自動研究:AI已經能高度自動化地完成複雜研究任務,人類要做就是把人從所有流程中撤走,儘可能自動化,追求極高的Token吞吐量。
4、模型能力呈鋸齒狀分佈:模型在不同領域的能力仍然參差不齊,如今與AI對話的感覺,就像是同時在和一個天才程序員和一個10歲小孩對話。
5、泛化問題:智能並沒有全面溢出,可驗證能力的提升並不會帶動模型軟性能力的提升。比如,模型在代碼上變強了,但講笑話還是五年前的爛梗。
6、職業選擇:在前沿實驗室工作並不自由,有太多利益糾葛和立場約束,在這些機構之外,反而更接近「人類整體」的立場。
7、開源v.s.閉源:完全封閉的智能還是有系統性風險的。開源模型如果並非最強,最好也只是稍微落後,扮演行業的「共同工作空間」角色,確保權力平衡。
8、單一大模型v.s.專用小模型:大模型會出現更多「物種分化」,但是持續學習、微調和權重修改等相關技術仍未成熟。
9、機器人:操作原子(物理世界)要比操作比特(數字世界)難上100萬倍,但物理世界的總潛在市場(TAM)可能比純數字世界還大。
10、AI與教育:人類互相教授知識的時代要結束了,未來教育的模式可能是先讓agent搞懂,然後讓它來教人。
以下是播客內容的完整編譯:
01.
AI「龍蝦」編程效果不佳?
多半還是Skill問題!
主持人:我記得有段時間走進你的辦公室,看到你非常專注,我問你在做什麼,你說「我必須每天‘編程’16小時」。編程甚至都不是正確的動詞了,你其實是在向Agent表達自己的想法。跟我說說你的體驗。
Karpathy:我感覺自己一直處在一種「AI精神錯亂」(AI psychosis)的狀態,現在也經常如此。因為作為個體,你能實現的事情變得更多了。過去你會受限於打字速度之類的因素,但現在有了這些Agent,情況完全不同了。
從去年12月開始,我的工作方式迎來真正的轉折點:原本我手寫80%的代碼,剩餘20%交給Agent,現在變成了20%自己寫、80%交給Agent,甚至可能還不止80%。從那時起,我幾乎一行代碼都沒再親自寫過。
隨便找一個軟件工程師,去看看他們在做什麼,你會發現他們構建軟件的默認工作流,從去年12月開始已經徹底改變了。
這是一個極其巨大的變化。我也跟我父母聊過這件事,其實普通人並沒有意識到改變正在發生,或者沒有意識到它有多戲劇性。
所以我現在的狀態就像是「精神錯亂」了一樣,試圖搞清楚到底哪些事是可行的,並把這些可能性推向極限。我會想:怎麼能不侷限於單次會話的Claude Code或Codex?怎麼能擁有更多?怎麼才能更合理地利用這些能力?這些OpenClaw到底能用在什麼場景?新東西實在太多了。
我覺得自己必須站在最前沿。我在Twitter上看到很多人在做各種嘗試,聽起來都頭頭是道。如果我不處在前沿,就會感到非常焦慮。這種「精神錯亂」狀態,本質上是因為我們還在探索「什麼是可能的」,而這個領域從根本上說仍是未知的.
主持人:如果你都感到焦慮,那我們其他人就更不用說了。我們有個合作團隊,他們的工程師完全不手寫代碼,所有人都戴着麥克風,一直對Agent低語。這是有史以來最奇怪的工作場景。我以前覺得他們瘋了,現在我完全接受了,「哦,這纔是正道」。你只是領先了一步。你覺得現在自己探索或做項目的能力受限於什麼?
Karpathy:Agent做不好,多半是人沒掌握好Skill。不是它不行,是你還沒摸清楚怎麼把現成的東西組合起來。比如agents.md文件裏的指令寫得不夠好,或者沒配個好用的記憶工具,歸根結底都是Skill問題。
最好的辦法是讓Agent並行幹活,就像Peter Steinberg(OpenClaw作者)那樣。Peter有張特別逗的照片——他坐在顯示器前,螢幕上鋪滿了一堆Codex Agent。如果提示詞寫得對,再開個高強度推理模式,每個任務差不多要跑20分鐘。他手上大概有10個repo要檢查,就來回切換着給Agent分配工作。
這樣你就能用更大的顆粒度去操作了,不是「這兒改一行代碼,那兒加個新函數」這種小打小鬧,而是「這個新功能交給Agent 1,那個新功能不衝突,給Agent 2」,然後根據你對代碼的重視程度去審查它們的產出。
這些就是操作代碼倉庫的「宏觀動作」。一個Agent在做研究,一個在寫代碼,另一個在規劃新的實現方案,所有事都在這些宏觀動作裏推進。你得努力精通這套玩法,練出肌肉記憶。這事兒特別有回報,一來是真的有用,二來是你在學新東西。所以纔會「精神錯亂」。
02.
「訂閱沒用完我就焦慮,
說明我的token吞吐量沒拉滿」
主持人:我的直覺是,每次等Agent幹完活兒,都覺得自己應該多幹點別的,對吧?如果token還富餘,就該並行塞更多任務進去。這挺有壓力的,因為要是你不覺得token花費是瓶頸,那系統裏真正的瓶頸就是你自己了。
Karpathy:起碼說明你訂閱的額度沒用滿。理想情況下,Codex跑滿了就該切到Claude或者別的。我最近一直在試這個模式,訂閱沒用完我就焦慮,說明我的token吞吐量沒拉滿。
我讀博的時候其實也經歷過這種事,GPU沒跑起來就焦慮——明明有GPU算力,FLOPS卻沒榨乾。但現在不是FLOPS了,是token。你的token吞吐量是多少?你指揮着多少token在跑?
主持人:我覺得挺有意思的,過去至少十年,很多工程任務裏大家都不覺得受計算限制,而目前整個行業突然變得受資源限制了。現在能力突然躍升了,你就會發現「哦,原來不是我搞不到算力,瓶頸是我自己」。
Karpathy:是Skill問題。研究這事兒能讓你變得更好。我覺得挺上頭的,因為你變強了就會解鎖新東西。
主持人:你覺得會往哪兒發展?比如Karpathy每天迭代16小時,其他人也在用編程Agent變強,一年後你達到的精通水平,會是什麼樣?
Karpathy:精通是什麼樣?年底,還是兩年、三年、五年、十年後?我覺得大家都想往技術棧的上層走。不是單次和Agent聊天,而是多個Agent怎麼協作、團隊怎麼配合,大家都在摸索那會是什麼樣。
然後我覺得OpenClaw也是個有意思的方向,因為我說的OpenClaw是指那種把持久性提升到新層次的東西。它是那種持續循環運行的,不是你交互式參與的,它有自己的小沙盒,自己幹事兒,哪怕你不盯着,還有更復雜的記憶系統之類的,這些Agent裏還沒實現。
OpenClaw的記憶系統就比默認的大模型複雜多了,默認只是上下文滿了就壓縮記憶。
主持人:你覺得OpenClaw是不是憑藉這一點打動了用戶,還是更廣泛的工具訪問?
Karpathy:我覺得OpenClaw有很多非常好的想法。Peter做得特別棒。我最近見到他聊過,他挺謙虛的,但我覺得他同時在五個不同維度創新,然後整合到一起。比如那個「靈魂文檔(soul.md)」,他真的精心打造了一種有吸引力、有意思的人格。我覺得現在很多Agent都沒做對這點。
Claude的人格就不錯,感覺像隊友,跟你一起興奮。有意思的是ChatGPT裏的Codex很活潑、很有活力,但Codex這個編程Agent就很枯燥,好像不在乎你在創造什麼,雖然完成了,但是它好像不理解我們在構建什麼。
主持人:確實。
Karpathy:還有一點,比如Claude,我覺得他們把模型的「人格」調得挺好。Claude誇我的時候,我確實覺得配得上。因為當我給它的想法不太成熟的時候,它反應就不強烈。但按我自己的標準,真是好想法的時候,它好像會多獎勵一點。我有點想贏得它的誇獎,這真挺奇怪的。
人格很重要,很多其他工具可能沒那麼重視。Peter真的很在乎這個,所以做對了。然後是記憶系統,還有通過單一WhatsApp入口,訪問所有功能,這個設計很不錯。
03.
「一切都應該是API端點,
Agent是粘合劑」
主持人:你個人用OpenClaw做過什麼編程之外的有意思的事嗎?
Karpathy:1月份的時候,我經歷了一段「OpenClaw精神錯亂」時期。我搭了個照顧家的OpenClaw,叫它「家養小精靈多比」。我用Agent找家裏局域網上所有智能家居子系統,還挺驚訝居然開箱即用。
我只是跟它說「家裏有Sonos,你能找找嗎?」它就做了IP掃描,找到Sonos音箱,結果沒密碼保護,直接登進去了。然後它開始逆向工程,看看這些系統是怎麼工作的,也做了些網絡搜索,直接找到API端點,問我想試試嗎,然後音樂就出來了。
燈光也一樣。它基本上是黑進了系統,搞清楚了整個系統,創建了API,創建了儀表盤,我能看到家裏所有燈的指揮中心,然後開關燈。我可以跟它說:「多比,要睡覺了」。這條指令就可以把所有燈關掉,它還控制着我所有的燈、空調、窗簾、泳池、水療吧,以及安保系統。
我有攝像頭對着房子外面,每次有人進來,首先會進行變化檢測,然後基於變化檢測去調Qwen,最後給我發WhatsApp消息,顯示外面的圖像,比如:「嘿,FedEx卡車剛到了,你可能想檢查一下,你收到郵件了。」這是多比剛給我發的,真的很不可思議。
多比管着房子,我通過WhatsApp跟它發消息,這些宏觀動作真的很有意思。我還沒真正推得更遠,我覺得有人在做更瘋狂的事。但就算只是家庭自動化設定,我以前要用六個完全不同的App,現在不用了,多比用自然語言控制一切,很神奇。我覺得我還沒完全推到這個範式的極限,但已經很有幫助、很有啓發了。
主持人:你覺得這從用戶體驗角度說明了人們想要什麼嗎?因為學習新軟件、新UI是需要人類努力的,這在過去被忽視了。
Karpathy:某種程度上是對的。OpenClaw實現的東西,本質上是從「人們覺得AI應該是什麼樣」這個角度倒推出來的。人們心目中的AI其實不是原始意義上的大模型——大模型就是個token生成器,但人們想象中的AI是那種有人格、有身份的存在,你可以跟它分享事情,它也會記得,就像WhatsApp背後的某個實體,更好理解。
所以某種程度上說,OpenClaw匹配了人類對AI行為的既有期望,但底層有很多技術細節。比如大模型作為原始原語對大多數人來說太「原始」了,對很多人來說不能真正被當成AI來看待。
主持人:我覺得這就是我們理解AI的方式,把它描述成多比或某種人格顯然能引起共鳴。我覺得你把六個不同的軟件系統統一起來做家庭自動化,也指向另一個問題:人們真的想要我們今天擁有的所有這些軟件嗎?你所做的就是把這些硬件的軟件層或UX層扔掉了。你覺得這是人們想要的嗎?
Karpathy:我覺得有種感覺是,應用商店裏那些配套智能家居設備的App,某種意義上根本不應該存在——不應該就是個API嗎,Agent不應該直接調用嗎?我能做各種家庭自動化,任何單個App都做不到。大模型能驅動工具、調用所有正確的工具、做相當複雜的事。
這說明業界可能生產了太多定製App,它們不應該存在,因為Agent把它們都統一起來了,一切都應該更像是暴露出來的API端點,Agent是粘合劑,是實際調用所有部分的智能。
另一個例子是我的跑步機,有個跑步機App,我想記錄做有氧的頻率,但我不想登入網頁UI、走流程什麼的。這些都應該只是開放的API,這是走向Agent化網絡或Agent優先工具的方向。所以行業必須在很多方面重新配置,客戶不再是人類,而是代表人類行事的Agent,這種重構可能會相當徹底。
有人反駁說,我們期望人們vibe code這些工具嗎?普通人要做我剛纔描述的這些嗎?但某種程度上這只是今天的技術現狀,現在有vibe coding,我在觀察、在跟系統合作。
但我覺得我剛纔說的這些,一兩年或三年後應該是免費的,沒有vibe coding參與,這是微不足道的,是基本要求,任何AI甚至開源模型都能做這個。
主持人:大模型應該能很容易地把不熟悉技術的人的意圖,翻譯回去。
Karpathy:今天還是需要vibe coding,但沒多少人會做。
主持人:而且你還得做些設計決策,對吧?比如取幀。
Karpathy:但我覺得門檻會降下來,只是為你服務的臨時軟件,某個OpenClaw處理所有細節,你不參與。它有台機器,會搞清楚,只給你呈現UI,你說話就行。
主持人:你為什麼沒把個人用OpenClaw的邊界推得更遠?是因為你專注更重要的項目,比如自動研究,還是在研究如何精通Vibe Coding,或者其他原因?
Karpathy:我覺得我分心了。我花了一周在OpenClaw的東西上,但還有更多嘗試可以做。我沒給它郵件、日曆和其他東西的訪問權限,因為我還有點懷疑。它還很新、很粗糙。我不想給它我數字生活的完全訪問權。部分原因是安全、隱私,也許這是主導因素。但部分也確實是因為我被分心了。
04.
AI已能「自動研究」
人類別拖後腿
主持人:你探索「自動研究」的動機是什麼?你一直在說,想讓Agent做訓練或至少優化模型的任務。
Karpathy:我早先有條推文,大意是為了充分利用現在可用的工具,你必須把自己從瓶頸中移除,你不能在那裏寫提示詞,指揮模型做下一件事,需要把自己抽離出來,安排好任務讓它們完全自主。怎麼在不參與循環的情況下,最大化你的token吞吐量,這纔是目標。
現在要做的就是增加你的槓桿,我只輸入很少的token,偶爾一次,但是有大量事情正在發生。
人們喜歡這個概念,但可能沒完全想通含義。對我來說,自動研究員就是上述觀點的案例之一——我不想做研究者,看結果什麼的,我在拖系統後腿,所以問題是怎麼重構所有抽象層。
我們要做的就是讓Agent能運行更長時間、不用你參與、代表你做事。所謂的自動研究員就是,你告訴Agent,這是目標,這是指標,這是能做和不能做的事情,放手去做吧。
主持人:你對它的有效性感到驚訝。
Karpathy:對,我沒想到會有效。我有nanoGPT這個項目,很多人不理解我對訓練GPT-2模型的着迷,但對我來說,訓練GPT模型只是個小工具、小遊樂場。我真正更感興趣的是遞歸自我改進這個想法,以及大模型能在多大程度上改進大模型。所有前沿實驗室都在做這件事,他們都在大致嘗試遞歸自我改進。
這個項目對我來說就是一個小遊樂場。我已經用經典的手工方式調過nanoGPT了——我是研究者,做了大概二十年。我做了很多實驗,做了超參數調優,做了所有事,非常熟練,達到了某個點,我覺得調得相當好了。
然後我讓自動研究跑了一晚上,它給我帶來了我忽略的調優空間,比如我確實忘了值嵌入的權重衰減,我的Adam beta沒充分調好,這些東西是聯合交互的,一旦調一個,其他的也可能要變。
我不應該是瓶頸,我不應該跑這些超參數搜索優化,我不應該看結果,這種情況有客觀標準。所以你只需安排好Agent,讓它能一直跑下去。我很驚訝它找到了這些調優空間,代碼庫已經高度優化了。
而這還只是單循環,前沿AI實驗室有數以萬計GPU的集群。不難想象,可以在較小模型上進行大量這種研究。所有前沿AI模型都是關於外推和Scaling損失的,可以在較小模型上做大量探索,然後嘗試外推出去。
主持人:你的意思是,如果能更好地進行這種實驗,那研發效率會大幅提升,在擴大模型規模時,也會有更明確的方向。
Karpathy:是的。我覺得目前最有趣、可能也是頂尖實驗室正在攻克的項目,就是在小模型上做實驗。你會試圖讓實驗過程儘可能自動化,把研究員從環節中踢出去。研究員們往往有種「過度自信」,其實他們不該插手這些過程。你得重寫整個流程,雖然現在研究員還能提供點想法,但不該由他們去執行。
想象一下,有一個點子隊列,可能還有一個「自動化研究員」,它根據所有的arXiv論文和GitHub倉庫產生靈感並輸入隊列;人類研究員也可以貢獻點子,但它們都進入同一個隊列。然後由自動化Agent去抓取任務並嘗試。行得通的代碼就進入功能分支,人工只需偶爾監控一下並合併到主分支。
總之,就是把人從所有流程中撤走,儘可能自動化,追求極高的Token吞吐量。這需要重新思考所有的抽象層,一切都要推倒重來。這非常令人興奮。
05.
AI能力呈「鋸齒狀」分佈:
有時像天才,有時像10歲小孩
主持人:如果我們再往深處推演一級,模型什麼時候能寫出比你更好的「program.md」?
Karpathy:「program.md」是我嘗試描述自動化研究員如何工作的一個簡陋草案——比如「先做這個,再做那個,嘗試這些架構或優化器的點子」。我只是用Markdown隨手寫出來的。你肯定想要一種自動化研究循環,去尋找更優的方案。你可以想象,不同的「program.md」會帶來不同的進展。
每一個研究機構其實都可以由一個「program.md」來描述。一個研究機構就是一組描述角色和連接方式的Markdown文件。你可以想象一個更高效的機構:也許他們早上的會更少,因為那純屬浪費時間。既然這一切都是代碼,你就可以微調它:有的開會少,有的偏好高風險。
你可以打造多個不同的研究機構,每個機構都以代碼表示,有了代碼就可以對其進行優化。你可以分析進步是從哪兒來的,然後調整「program.md」,讓它多做有效的事,少做沒用的事。
主持人:這就是元優化(Meta Optimization)。
Karpathy:這主意很棒,但得一步步來。這就像剝洋蔥:現在大模型部分已經是常態了,智能體部分也是常態了,像OpenClaw也是常態了。現在你可以擁有多個實體,給它們指令,甚至對指令進行優化。這信息量確實有點大,甚至讓人感覺有點「精神錯亂」,因為它是無限嵌套的,而且一切都還處於早期階段。
主持人:如果我們要判斷當下,什麼樣的技術纔是核心?我們是否應該在各個領域都嘗試實現這種「去人化」的自動化循環?核心是建立指標,還是創造讓Agent在沒有你的情況下持續工作的能力。那「性能工程」(Performance Engineering)還有地位嗎?
Karpathy:關於AI生態我有幾點想提醒。第一,這種模式極其適合那些有客觀指標、易於評估的領域。比如編寫更高效的CUDA算子。有一段低效代碼,想要一段行為完全一致但速度更快的高效代碼,這是自動化研究的完美場景。但如果你無法評估,你就沒法對其進行自動化研究。
第二,雖然我們能看到下一步,但模型的基本功層面其實還有很多不足,沒完全跑通。如果你步子跨得太大,最後可能反而沒用。現在的模型雖然進步很大,但在某些方面還是比較粗糙。我感覺自己同時在和一個天才級的系統程序員以及一個10歲小孩對話。
這種「鋸齒狀」(Jaggedness)的能力分佈很奇怪,人類的能力通常更均衡。有時候我要求一個功能,結果Agent給我的完全是錯的,然後陷入完全錯誤的循環,我就特別崩潰。明明能感覺到它的強大,但它偶爾還是會幹出完全沒道理的事情。
06.
模型能力「泛化」仍然存疑,
一切都卷在不透明的神經網絡裏
主持人:當我發現Agent在一些顯而易見的問題上浪費了大量算力時,我會非常惱火。
Karpathy:我猜這背後的深層原因是:這些模型是通過強化學習(RL)訓練的。它們也面臨我們剛纔聊到的問題:實驗室只能在可驗證、有獎勵反饋的領域提升模型。代碼寫對了嗎?單元測試過了嗎?這些好辦。
但它們在比較「軟」的東西上就掙扎了,比如:我到底想要什麼細微差別?我意圖是什麼?什麼時候該反問我求澄清?凡是感覺比較模糊、不明確的領域,它們就明顯差很多。
所以你要麼就在軌道上,屬於超級智能的一部分,要麼就偏離軌道,進入了不可驗證的領域,然後一切就開始漫無目的地遊蕩。
換個說法:你今天去用最強的ChatGPT,說「給我講個笑話」,你大概率知道會得到哪個笑話。
主持人:我猜ChatGPT大概翻來覆去就那三個笑話。
Karpathy:沒錯。所有大模型最愛講的笑話永遠是:「為什麼科學家不信任原子(Atoms)?因為它們構成了(Make up,也有編造之意)一切。」
這是三四年前模型講的笑話,現在依然是。儘管模型在Agent任務上已經能移山填海,可你一讓它講笑話,它還是五年前的爛梗。
因為這不在強化學習的優化範圍內,它是「鋸齒狀能力」中的窪地。模型能力提升的同時,講笑話的能力並沒有提升。它沒有優化,而是停留在了原地。
主持人:這是否說明我們在「泛化」意義上並沒有看到更廣的智能——比如講笑話的聰明度並沒有跟寫代碼的聰明度綁定在一起?
Karpathy:對,我覺得確實存在一定程度的解耦。有些東西可驗證、被重點優化;有些東西沒有被優化。有些領域實驗室根據訓練數據隨意優化,有些根本沒動。
主持人:有一些研究組的前提是:如果你在代碼生成等可驗證領域變得更聰明,就應該在所有領域都更聰明。但笑話這個例子說明,至少目前並沒有發生全面的溢出。
Karpathy:我也不覺得發生了。我覺得有一點點,但遠沒有達到讓人滿意的程度。
主持人:人類也有這種特質。你可以數學極其厲害,但講笑話巨爛。
Karpathy:但這也說明,我們並沒有得到那種「模型越強,所有領域的智能都自然而然跟着變強」的故事。並不是這樣。存在盲區,有些東西根本沒被優化。這一切都卷在不透明的神經網絡裏。
如果是獲得針對性訓練的能力,就會光速前進,如果不在這一範圍內,表現就不佳。這就是能力的參差不齊。
即使方向很明顯,也還不能完全放手讓它跑,因為它還沒完全跑通——要麼是技術還沒成熟,要麼是我們還沒搞明白怎麼用。
07.
大模型會出現更多「物種分化」
但相關技術仍不成熟
主持人:我能問一個有點大逆不道的問題嗎?我們現在還是把模型打包成一個單體模型,但如果這種參差不齊的能力分佈會一直存在,那是否應該把模型拆開,拆成可以在不同智能領域分別優化、分別改進的東西?比如拆成多個專家模型(Mixture of Experts),每個專注不同領域。
而不是現在這樣:一個大模型什麼都行,但為什麼在這件事上表現很好、在另一件事上表現極差,讓人非常困惑。
Karpathy:我現在的感覺是:前沿實驗室還是想做一個單一的「單文化」模型,在所有領域都儘可能聰明,然後把一切都塞進參數裏。但我認為未來應該會出現更多的「物種分化」(speciation)。
就像動物界,大腦形態極其多樣,有各種生態位。有些動物視覺皮層超級發達,有些其他部分超發達。我們應該也會看到更多這種分化。
不需要一個無所不知的神諭(oracle)。你可以讓它分化,然後針對特定任務部署。而且這樣可以出現更小的模型,但仍然保留認知核心,仍然很能幹,只是在特定任務上做了特化。
這樣在延遲、吞吐量上都會更高效。比如專門為Lean定理證明做優化的模型,已經有幾家在發布了。應該會出現越來越多這種解耦的場景。
主持人:我有一個問題是:當前計算基礎設施的容量限制,會不會反過來推動這種分化?因為效率變得更重要了。因為如果算力完全不限,你什麼都能跑,哪怕是一個超大單模型。但如果你真切感受到:我不可能為每一個用例都開一個巨型模型。你覺得這會不會推動分化?
Karpathy:這個問題很有道理。但我現在的困惑是:我們其實還沒看到太多分化。目前還是單一模型佔主導。
主持人:業界明顯有壓力,要做一個好的編程模型,然後再合併回主幹。
Karpathy:儘管模型本身已經有很大壓力了。
主持人:也許現在是短期供給極度緊張,反而會造成更多分化。
Karpathy:對。我覺得本質上,實驗室在對外提供模型時,他們並不知道終端用戶會問什麼。所以他們必須在所有可能的問題上進行多任務規劃。
如果你是跟某個企業深度合作、針對特定問題,那可能會出現更多特化。或者某些極高價值的細分應用。但目前他們還是在追求「包羅萬象」。
另外,操控這些「腦」的科學本身還沒完全成熟。比如在不損失通用能力的情況下做微調,同時,我們也還沒有很好的原語(primitives)。現在基本上靠上下文窗口來操控,它確實很好用、很便宜,所以我們用它做各種定製化。
但如果想更深層地調整模型,比如持續學習(continual learning)、在特定領域微調、真正動權重而不是只動上下文窗口,這要複雜得多。動權重實際上是在改變整個模型的智能,很容易出問題。所以「物種分化」的科學本身還不成熟。
主持人:而且成本也要足夠低,才值得去做。
08.
AI研究「並行化」展現潛力
「散戶」也能貢獻算力
主持人:我能再問一個關於你之前提到的「自動研究」(auto research)的問題嗎?你談到過「開放地帶」(open ground),說我們需要圍繞它建立更多的協作表面,讓大家都能參與到整體研究中。你能再講講這部分嗎?
Karpathy:好的。我們之前聊到,研究本質上是一條單線程:我不斷嘗試、循環迭代。但真正有趣的部分其實是它的並行化。我嘗試過一些想法,但目前還沒有找到特別簡單、讓我特別滿意的方案,所以這只是我業餘時間、在不做OpenClaw時順手搗鼓的一個方向。
一個很直接的思路是:如果你有很多並行節點,很容易就能讓多個自動研究員(auto researchers)通過一個共享系統互相討論。但我更感興趣的是,如何讓互聯網上大量不被信任的工人(untrusted pool of workers)參與進來。
舉個例子,在自動研究裏,我們的目標是找到一段能把模型訓練到非常低驗證損失的代碼。如果有人從互聯網上提交一個候選commit,你很容易驗證它到底好不好——直接跑一下就知道。
但驗證本身雖然簡單,卻可能要消耗大量算力。而且對方完全可能撒謊。所以這裏其實有點像我之前設計的一些系統,引入了不信任的工人池,結構上有點像區塊鏈。
這些commit可以互相建立在前面,包含代碼的改進。所謂的「工作量證明」其實就是大量實驗,找到真正有效的commit。現在的獎勵只是上排行榜,沒有任何金錢激勵。
我不想把這個類比推得太遠,但核心問題是:搜索的成本非常高,但驗證一個候選方案是否優秀卻非常便宜——你只需要訓練一次模型,看看它到底行不行。前面可能試了1萬個想法失敗了,但你只要驗證那個成功的就夠了。
簡單來說,你需要設計一套系統,讓不被信任的工人池和可信任的驗證工人協同工作,整個流程是異步的、安全的。從安全角度看,如果有人隨便發一段代碼給你,你直接跑它是非常危險的。但理論上這是完全可行的。
你應該很熟悉SETI@home(在家搜尋地外文明)、Folding@home(在家研究蛋白質摺疊)這些項目,它們都有非常相似的性質:找到一個低能量蛋白質構象非常難,但一旦有人找到了,你很容易驗證它就是低的。
所以凡是符合「生成極貴、驗證極便宜」這個特性的問題,都很適合用「@home」模式,比如Folding@home、SETI@home,或者未來的「Auto Research @ home」。
一句話總結:互聯網上的一大群智能體有可能合作來改進大語言模型,甚至有可能跑贏前沿實驗室,誰知道呢?前沿實驗室擁有大量可信算力,但地球上不被信任的閒散算力總量要大得多。
如果能把機制設計好,讓安全驗證到位,也許真的有可能讓這群「散戶」貢獻算力,共同推動某些他們關心的方向。
再延伸一點,很多公司、機構、甚至個人研究方向都可以有自己的自動研究賽道。比如你特別關心某種癌症,你不只是捐錢給機構,你還可以買一些算力,然後加入那個癌症方向的自動研究「池子」。這樣算力就變成了一種你可以貢獻的東西,所有研究者最終都在共享、競爭、迭代這些算力成果。
主持人:這真的很振奮人心。而且很有意思的一點是,現在至少有一部分人——不管是硅谷排隊買顯卡的,還是中國商場裏搶設備的——突然又覺得擁有個人算力變得有意思了。
Karpathy:對。
主持人:他們可能為了自己的OpenClaw去買算力,然後順便貢獻給自動研究。
Karpathy:現在大家都在乎美元,但未來會不會變成大家都在乎FLOP(浮點運算次數)?會不會出現一種「翻轉」——算力變成真正稀缺和主導的東西?當然我不認為會完全這樣,但這個想法挺有意思的。
09.
AI是數字世界的「幽靈」
進入物理世界仍會滯後
主持人:你最近發布的好像是對一些就業數據的分析,對吧?好像還稍微觸動了一些人的神經,雖然你只是可視化了公開數據。你當時主要是好奇什麼?
Karpathy:對。我就是很好奇AI對就業市場的真實影響到底會怎樣。每個人都在討論這個話題。所以我就想看看現在的職業分佈是什麼樣子、各個職業有多少人,然後逐個去想:以AI目前和未來可能的演化路徑,這些職業是會被AI當作工具來增強,還是會被取代?它們是會增長、萎縮,還是會發生很大變形?會不會出現全新的職業?
所以這其實主要是餵養我自己對整個行業的思考鏈條。我看的是美國勞工統計局(BLS)的數據,他們對每個職業未來十年(大概是基於2024年的預測)都有一個預期增長百分比。
主持人:我們需要很多醫療工作者。
Karpathy:對,他們已經做了這些預測。我不清楚他們的具體方法論是什麼。我當時主要按「數字vs物理」來給這些職業分類。
因為我覺得目前主流發展的AI更多是數字世界的「幽靈」——它們能非常高效地操縱數字信息,但還沒有真正的物理具身。操控原子永遠比操縱比特慢很多個數量級。
所以我預期數字空間會發生爆炸式的活動、重寫、沸騰,而物理世界會相對滯後一段時間。數字領域的「神經系統」會被AI大幅升級,帶來大量原本由人和傳統計算機完成的數字信息處理工作被重構(refactoring)。而物理世界會慢半拍。
所以我特別把那些本質上就是在家裏操縱數字信息的職業標出來——因為這些領域會發生劇烈變化。不是說崗位數量一定減少或增加(那取決於需求彈性等很多因素),而是說這些職業的工作內容、技能要求會發生巨大改變。這就像給人類超級有機體升級了一套新的神經系統。
主持人:從你看數據的感受來說,對於現在面臨就業市場、或者在考慮學什麼、發展什麼技能的人,你有什麼觀察或者建議嗎?
Karpathy:這個真的很難一概而論,因為職業太多樣了,情況千差萬別。但總體來說,這些工具出現得太新、太強大了,所以第一件事就是儘量跟上它們的發展。
很多人會選擇忽視它,或者因為害怕而回避——這完全可以理解。但我覺得最重要的是保持好奇、主動去接觸和使用它們。因為它們確實是極其強大的新生產力工具。
現在AI其實就是一個非常強大的工具。很多工作本質上是一堆任務的集合,其中一部分任務可以用AI讓速度變得非常快。所以大家現在應該主要把它看成一個工具。至於長遠未來會怎樣,其實挺難預測的,我也不是專業做這方面預測的人,這應該交給經濟學家去認真研究。
10.
OpenAI的研究員
正「光榮地」把自己自動化掉
主持人:你是工程師啊。我覺得有意思的一點是,現在對工程崗位的需求其實還在持續上升。我不確定這是不是暫時的現象。你怎麼看?
Karpathy:對,我覺得現在軟件其實是稀缺的。正因為稀缺、太貴,所以需求纔沒有爆發。如果門檻大幅降低,就會出現「傑文斯悖論」——東西變得更便宜,人員需求反而增加了。
經典例子就是ATM機和銀行櫃員。很多人一度擔心ATM和電腦會把櫃員徹底取代,但實際上因為銀行開支店的運營成本大幅下降,反而開了更多分行,最後櫃員數量反而增加了。這是大家常引用的例子。本質就是:某樣東西變便宜了,很多之前被壓抑的需求就被釋放出來了。
所以我在軟件工程這個領域其實是謹慎樂觀的。我覺得軟件的需求會變得極大,因為它變得便宜太多了。
而且軟件本身太強大了——它是數字信息處理,你不再被迫使用那些不完美的、別人給你的工具,你也不用只能接受現成的東西。代碼現在是臨時的、可變的、可修改的。所以我認為未來會在數字世界裏出現大量「重構一切」的活動,這會創造非常多的需求。
長遠來看呢,像OpenAI、Anthropic這些前沿實驗室,現在也就僱一千來個研究員吧。這些研究員某種意義上是在「光榮地」把自己自動化掉,他們其實就是在主動做這件事。
我有時候去OpenAI轉轉,就會跟他們說:你們有沒有意識到,如果我們真的成功了,我們全都要失業啊?我們就是在給Sam(OpenAI聯合創始人兼CEO Sam Altman)或者董事會造一個能取代我們的東西啊。
有些研究員自己也開始有那種「精神錯亂」的感覺,因為它真的在發生。他們會想:完了,連我也完了。
11.
在前沿AI Lab之外
跟「人類整體」立場對齊度更高
主持人:你為什麼不乾脆去前沿實驗室,用海量算力跟一大群同事一起做自動研究(auto research)?就像前幾天Noam Brown所問的那樣?
Karpathy:其實我之前在那裏待過一段時間,也算是重新出來過。我覺得這個問題可以從很多角度看,有點複雜。
我現在感覺,在前沿實驗室之外,人們其實也能產生非常大的影響,不管是行業外還是生態層面的角色。比如你現在做的就是生態層面的工作,我目前也更多是在生態層面,我覺得這類角色能帶來的影響其實挺好的。
反過來,如果太深度綁定到某一家前沿實驗室,其實也有問題。因為你會有巨大的財務激勵,而你自己也承認AI會極大地改變人類和社會,卻在裏面一邊建技術一邊從中獲利。這個難題其實從OpenAI剛創立時就存在,一直沒完全解決。
你在公司裏面就不是完全自由的個體。有些話你不能說,有些話組織希望你說。雖然不會強迫你,但那種壓力是存在的——說錯話會很尷尬,會被側目,會被問「你在幹嘛」。所以你在裏面其實很難保持完全獨立的立場。
我在實驗室外面,反而覺得自己跟「人類整體」的立場對齊度更高,因為我幾乎不受那些壓力影響,想說什麼就說什麼。當然,前沿實驗室裏你也能做出很大貢獻,尤其是如果你想法很強、能參與核心決策。現在整體風險還不算特別高,大家都還挺友善。
可一旦真正到高風險、利害攸關的時候,作為一個員工,你對公司最終決策到底有多大影響力,其實我是不太確定的。你可以在會議室裏提想法,但你並不是真正掌舵的那個人。的確存在一些錯位。
另一方面,我也同意一個觀點:如果你完全在實驗室外面,判斷力確實會慢慢漂移。因為你接觸不到最前沿的東西,看不到模型到底是怎麼工作的,未來會怎麼發展。
所以從這個角度,我確實有點擔心。我覺得保持跟前沿的接觸是重要的。如果有機會去前沿實驗室幹一段時間,做一些高質量工作,然後再出來,也許是個不錯的方式——既能跟上真實進展,又不至於完全被某個實體控制。
所以我覺得Noam如果在OpenAI應該也能做出非常好的工作,但他的最高影響力也許恰恰是在OpenAI外面。
理想狀態可能就是來回切換、在裏面和外面都待一待。這是一個複雜的問題,我自己就是先進去,又出來,未來可能還會再進去。我大概就是這麼看待這件事的。
12.
開閉源模型差距明顯收斂
AI生態需維持健康的權力平衡
主持人:開源模型到底離前沿模型有多近,這個差距會持續嗎?我覺得整個事情的發展其實挺讓人意外的。從一開始只有少數幾個中國模型和全球模型,到現在大家都在持續發布,而且能力上比很多人預想的要更接近前沿。
你長期做開源,對此怎麼看?會不會覺得驚訝?
Karpathy:我大概的觀察是:閉源模型仍然領先,但大家都在盯着「開源模型落後幾個月」這個差距。一開始是完全沒得比,後來拉到18個月左右,現在已經明顯在收斂,可能現在落後6–8個月的樣子吧。
我當然是非常支持開源的。拿操作系統舉例:有封閉的Windows和macOS這樣的大型軟件項目,就像未來的大模型一樣;但同時也有Linux,它其實極其成功,跑在全球絕大多數計算機上(我記得上次看是60%還是更多)。因為行業需要一個大家覺得安全、可信的共同開放平台。
現在大模型也是同樣的邏輯,行業其實有強烈的需求,希望有這樣一個東西存在。唯一的區別是,現在做這件事需要巨量的資本投入,這讓競爭變得更難。
但我認為現在的開源模型已經非常好用了。對於絕大多數消費級場景,甚至終端開源模型都足夠強。往前再走幾年,很多簡單用例都會被很好地覆蓋,甚至可以本地跑。
當然,永遠都會有一部分對「最前沿智能」的需求,而且這個需求可能佔很大一塊市場。但也許未來的「前沿」會變成那種諾貝爾獎級別的工作,或者像把Linux從C重寫成Rust這樣的大工程。封閉的最強模型可能會主要服務這類高難度任務,而開源則會喫掉大量基礎和日常用例。
而且現在封閉實驗室的「前沿」模型,過幾個月可能就開源了,然後繼續幹很多活。所以我預計這個動態會持續:前沿實驗室保持封閉的最強模型當「神諭」,開源模型落後幾個月,但差距可控。我覺得這其實是個挺不錯的整體格局。
因為我對完全封閉的智能還是有系統性風險的。歷史上看,極度中心化的東西(不管是政治、經濟還是其他系統)表現都不太好。
我希望開源就算不是最強的,但最好也只是稍微落後一點,作為整個行業都能用的共同工作空間。這樣權力平衡會比較健康。
主持人:另一方面,我也覺得有很多大問題要靠持續推進最前沿的智能才能解決。人類面臨的一些超級難題,沒法只靠今天的能力搞定,所以我們還是得支持那些願意花大錢往前推的實驗室。
但正如你說的,今天的「前沿」如果過一陣子就開源,那本身就已經是非常大的能力釋放了。這種智能的普惠化,我覺得既實用又有益。
Karpathy:所以某種意義上,我們現在這個局面其實挺意外地還不錯,甚至可以說是個相對健康的生態。
主持人:而且只要這種動態能持續得久一點,整個生態的「面積」(累積的能力)就會越來越大。
Karpathy:不過最近閉源模型好像反而更集中了,因為很多原本跑在前面的玩家現在掉隊了,所以頭部更集中。我其實不太喜歡這個趨勢。我希望有更多前沿實驗室,越多越好。我對集中這件事就很警惕。
機器學習裏ensemble(集成)總是比單個模型強,所以我也希望最難的問題是有多組人在思考、最難的決策是有多組知情的人在房間裏討論,而不是關起門來兩三個人說了算。我覺得那不是好的未來。
所以長話短說:我希望會有更多的AI實驗室,開源模型能一直存在,目前稍微落後一點其實是好事。
13.
與操作「比特」相比
操作原子「難上100萬倍」
主持人:你之前做過通用機器人的前期工作,也就是自動駕駛相關的研究。最近幾個月機器人公司也加速了,很多公司在泛化能力、長時序任務上進步很大,還有很多錢湧進來。你覺得機器人真的要起來了?最近有沒有什麼變化讓你改觀?
Karpathy:我的看法還是受當年自動駕駛的影響比較大。自動駕駛其實就是第一個真正落地的機器人應用。十年前那波,有一大堆初創公司,最後能活下來的其實沒幾個。
我看到的是:機器人這東西太難了,很多髒活累活,需要巨量的資本、時間和信念。「原子世界」就是要比「比特世界」難很多。所以我認為物理世界的機器人會明顯落後於數字世界。
數字世界現在就出現了巨大的「解鎖效應」——很多原本低效的東西,效率可以提升100倍。因為比特就是比原子好搞太多了。
目前最活躍、最會發生鉅變的還是數字空間。然後纔會慢慢到數字-物理的接口部分。
為什麼會有接口?因為一旦你有了更多Agents代表人類做事、互相協作、參與「Agent經濟」,純數字的任務總有一天會做完。到那時你必須去問宇宙問題,必須做實驗,讓物理世界給你反饋,才能學到新東西。
現在數字世界還有大量「過剩工作」——人類以前根本沒足夠腦力把所有已數字化的信息都思考一遍。現在AI來了,我們會先把這些過剩的部分榨乾。
但遲早會榨完。然後就開始需要跟物理世界交互的接口:傳感器(讀世界)、執行器(改世界)。所以我覺得真正有趣的公司會出現在這個接口地帶——能不能給超級智能喂數據,能不能按它的指令去操控物理世界。
而純物理世界的機會其實更大,總潛在市場(TAM)可能比純數字世界還大。但因為原子難搞太多,所以會滯後。我認為要難上100萬倍。時間線大概是先數字大爆發,然後是數字-物理接口,最後纔是純物理的大規模起飛。
主持人:當然,有些物理任務其實沒那麼難。比如只是在物理世界及逆行「讀寫」——讀可以用現成攝像頭、傳感器;寫可以用現成機械臂。如果你足夠聰明,不用投太多錢也能搞出很有價值的東西。
Karpathy:比如我最近去拜訪的朋友Liam,他是Periodic的CEO,他們在用AI做材料科學的自動研究。那裏傳感器的成本就很高,是實驗室設備。生物學也一樣,很多人在搞生物工程,傳感器遠不止攝像頭。
還有些公司在做「付費採集訓練數據」的生意,直接把人類當傳感器給AI喂數據。
主持人:所以我覺得未來我會很期待能直接給Agent一個物理世界任務、標個價格,說「你自己想辦法搞定,去拿數據」。
Karpathy:現在居然還沒有足夠發達的「信息市場」,我覺得挺意外的。
比如Polymarket、股票市場這些,如果未來Agent參與度越來越高,為什麼不能出現「我出10美元,讓人在德黑蘭某個地方拍張照或視頻」這樣的機制?拍完直接餵給Agent,讓它們去猜賭局或炒股。
我覺得「Agent化的web」還很早期,還缺很多這樣的基礎設施。但這種方向我覺得是會發生的。
有一本書可能挺有啓發,叫《惡魔》(Demon),裏面智能最後有點像在操縱人類——人類既是它的傳感器,也是它的執行器。未來整個社會可能會集體重塑,去服務於機器的某種需求,而不是單純服務於彼此。
主持人:我們之前聊到訓練數據缺口、自動研究(auto research)的問題。要把人類從訓練閉環裏拿掉,讓模型自己提需求、自己收集數據、自己優化,得把SFT(監督微調)這一環也高度自動化纔行。
Karpathy:對,100%同意。但對於大語言模型訓練,其實這個範式特別合適。因為它有清晰的優化目標、損失函數,代碼跑得快,還有可量化的指標。
當然,如果完全閉環優化某個指標,可能會出現大量「對指標的作弊」,或者說過擬合。但可以用系統自己再發明新指標,做到更好的覆蓋。所以整體來說,語言模型訓練其實是目前最容易實現自主閉環的領域之一。
14.
人類互相教授知識的時代要結束了:
先讓agent搞懂,然後讓它來教人
主持人:最後聊個你的小項目吧——micro GPT。
Karpathy:對,micro GPT是我這十幾年一直在乾的一件事:把LLM儘可能地簡化、提純到最本質。
我之前做過nano GPT等等項目,現在micro GPT是我目前能做到的最極致版本——整個從頭訓練一個小型語言模型的代碼,只有200行Python(包括註釋)。
大家看到那麼多複雜的訓練代碼,其實絕大部分複雜度都來自「要跑得快」。如果不在乎速度,只關心算法本身,那真的就200行,非常好讀:數據集、50行網絡結構、前向傳播、100行autograd引擎算梯度、10行Adam優化器,再加個訓練循環,就結束了。
以前我會想錄個視頻一行行講,或者寫個教程。但現在我覺得沒太大必要了。因為代碼已經簡單到隨便丟給一個agent,它就能給你各種角度解釋。
我現在更多是在跟agent解釋東西,而不是直接跟人解釋。如果agent能懂,那它就能按用戶的語言水平、無限耐心、反覆講解各種方式。人類反而從agent那裏能學得更好。
我甚至可以寫一個「skill」,就是告訴agent應該按什麼順序、用什麼方式把micro GPT講給不同水平的人。這樣我只負責設計課程的骨架,剩下的執行交給agent。
所以我覺得教育的形式正在被重塑。以前是講義、講座、文檔;現在更像是:先讓agent搞懂,然後讓它來教人。
當然現在agent還不是完全取代我——我還是能比它們講得稍微好一點。但模型進步太快了,我覺得這是一場必輸的戰鬥。
所以教育可能會大幅重構,那種人類互相教授知識的時代可能快要結束了。打個比方,如果我有一個代碼庫或者其他什麼項目,以前你會為使用這個庫的人寫文檔,但現在你不應該這麼做了。
你不應該再寫給人看的HTML文檔,而應該寫給智能體看的markdown文檔。因為如果智能體理解了,它們就能解釋其中的各個部分。這是一種通過智能體的間接傳遞,我覺得我們會看到越來越多這樣的情況發生。
我嘗試過讓智能體來寫micro GPT。我讓它試着把神經網絡提煉成最簡單的東西,但它做不到。micro GPT是我癡迷一生研究出的結晶,就200行代碼。我思考了很久,這就是解決方案。相信我,不可能更簡單了。
這就是我的價值所在。其他所有東西,智能體都能搞定。它可能想不出來,但它完全能理解,也明白為什麼要用某種方式實現。
我的貢獻大概就是這幾個關鍵部分,但之後所有的教育工作就不再是我的領域了。也許教育的模式確實會改變——你只需要注入那些你特別在意、你覺得是課程核心的少數幾個點,或是補充更好的講解方式。
那些智能體做不到的事,現在成了你的工作;而那些智能體能做的事,它們可能比你做得更好,或者很快就會比你做得更好。你應該戰略性地思考,到底把時間花在什麼事情上。