
Token正在重塑AI時代的價值座標,它是效率革命的引擎,還是成本失控的暗礁?本期將從Token降本的視角,透視AI時代「新石油」的經濟邏輯。本文來自微信公衆號:騰訊科技,作者:蘇揚,頭圖來自:AI生成
最近關於Token的討論挺魔幻的。
朋友圈隨處能看到Token中文翻譯的討論——有「詞元」「智元」等等,甚至有「慧根」之類的搞笑版本。
Token不是一個新概念,大模型落地第一天起,它便與神經網絡共生,但直到OpenClaw(俗稱「龍蝦」)在用戶群大規模擴散,各類Agent應用開始把Token帶入了公衆視野。
我認為其中有兩個關鍵問題:它的消耗量太大了,價格也太貴了。
記得OpenAI發布GPT-5.4的時候,有用戶反饋測試一句「你好」就消耗掉了80美元的Token,當時不少人都說這個使用量太誇張,但隨着小龍蝦大規模在用戶群擴散,一個任務燒完千萬級Token成為常態。
與之相對的是,英偉達CEO黃仁勳在GTC2026大會上以及之後的很多場合,都在強調工程師要大量的使用Token,甚至將Token納入到薪酬激勵機制。
一次對話環節,黃仁勳說:「如果年薪50萬美元的工程師,連25萬美元的Token都沒用掉,我會極度恐慌。」
問題是,瘋狂的燒Token一定能解決問題嗎,有多少Token是有效的,什麼樣的投入產出比是合理的?
結合啱啱外媒的消息,有OpenAI程序員一周燒掉了2100億Token,相當於33個維基百科,但這樣的消耗量最終帶來了什麼?我發了一個朋友圈,說這樣重度使用能升P10嗎,有好友隨即評論,「能幫賣Token的升P10。」
很顯然,這場瘋狂燒Token的運動,能帶來多少效果是存疑的,誰是獲利者則是確定的。
黃仁勳將英偉達描述為「Token之王」,擁有世界最先進的「Token製造機」,但如果拼命鼓吹這件事,甚至暗示不用Token就會落後,那麼可以說:一方面,黃仁勳想徹底改變AI時代企業「效率考覈」的邏輯,另一方面,他也間接製造出了Token焦慮。
一、Token太貴了
不久前,我請教了周鴻禕「Token太貴」這個問題,他說:「大家覺得Token貴可能存在些誤解,因為大模型後端是可以靈活配置的。」
在他的理解中,用戶可以自主選擇模型控制成本。「日常聊天對話的成本其實很低。真正消耗Token的是複雜任務,比如幫你生成視頻、創作短劇或寫小說這類調用場景。」
我記得獵豹移動CEO傅盛在一條視頻中說,自己通過一些使用技巧把最初日均幾百美元的Token費用,優化到目前日均10多美元,30天就是2100元,年費是25200元。
問題來了:有多少用戶承擔得起日均10美元的成本?
對比目前中國互聯網上的商用to C類軟件,比如剪映,高端會員年費也只有600元左右,娛樂相關的會員費用大致在300元左右,根本找不到一款年費超過25000元的消費級軟件。
「絕大部分人一天10美金,仍然不會接受,這裏會過濾掉大片的非付費用戶。」我對傅盛說,他沒有否認我的判斷。
這些天,我也在嘗試各種類型的小龍蝦產品,要接觸到的費用遠不止Token。
舉個例子,如果用戶對生圖有需求,就需要專門的生圖模型API;如果要監控動態,也需要接入付費的搜索API,這些潛在的費用會逐步地勸退絕大多數用戶。雖然可能有一些開源變通的方式降本,但開源項目就間接隱藏着安全風險。
3月13日,當時騰訊科技「蝦聊」系列直播的第一期(《鵝廠工程師講透「龍蝦」真相:「笨」不是「蝦」的錯》),玄武實驗室的嘉賓Lambda分享過一個數據——他自己平均每個月「養蝦」的費用在千元以上。
不管是參照消費級工具年費,還是行業「養蝦戶」的反饋,基於Agent的Token消耗說一句「Token太貴了」,是站得住腳的。
二、存儲瓶頸與效率黑洞
Token簡單理解就是大語言模型處理信息的基本單位——用戶輸入提示詞,模型輸出答案,每一個字、每一個標點,都會計入Token的消耗量,本質上還是算力成本。
過去大家計算算力總擁有成本,指標有很多,包括衡量能效的Flops/W,覈算均值的成本/Flops等等,今年的「Token經濟學」中,Token/W逐步成為共識。
「我們的每一個Token成本都是世界最低的。」黃仁勳在GTC上說。
但不管有多便宜,不管是哪一種計算單位,它都是投入成本量化,涉及到研發成本、硬件成本,部署成本,能耗成本,運營成本等。換句話說,降本也都是圍繞上述環節展開。
對於Token降本來說,一個不好的消息是內存價格在瘋漲。
以HBM內存為例,它是支撐大模型訓練和推理的關鍵器件,同時,推理數據量的暴漲也引發出了存儲需求的同步上漲。2026年第一季度,DRAM的價格按月上升逾過50%,NAND價格按月最高漲幅達到150%。
黃仁勳、蘇姿豐都已經喊出了「HBM有多少要多少」,三星、美光這些存儲原廠,已經對外披露頭部客戶的戰略長約已經簽到了5年。
《內存暴漲100天,千元機被迫死亡》一文提到過,消費級市場,千元機庫存可能都要停產了,但實際上受這個問題的影響,雲廠商目前也處於漲價的煎熬之中。目前行業最樂觀的預計是2028年存儲價格回落,悲觀一點要到2030年。
存儲價格一天不回落,Token降價就缺少一個關鍵的外部槓桿。
模型能力的提升也可以視為降價的另一個槓桿。「現在一些8B的小模型,能力越來越逼近全量大模型。」一位學術界研究員說。
在這方面,面壁智能聯合清華團隊在《Nature》上提出了Densing Law的概念,強調大模型的能力密度隨時間指數增長,約每3.5個月翻一倍,同等性能所需參數量每3.5個月減半。
一位國產AI芯片從業者也強調模型能力好、規模小,進而能推動成本降低。「你看國內開源大模型token價格,基本都跟模型規模正相關。」
多位國產算力從業者表示,提升MFU也會帶來成本壓縮的空間,此外也還包括架構、顯存等多方面的推理優化。
「MFU跟模型本身關係不太大,主要是算子和調度策略有關。」另一位國產存算一體芯片從業者說:「目前主流大模型的推理MFU均值在30%左右,優化後可超過50%,估計能省出50%的成本。」
也就是說,行業並沒有榨乾GPU的性能——花了100%的GPU錢,現在只用了不到三分之一的算力。
不過,MFU提升雖然可以帶來單Token成本下降,但會不會傳導到C端,取決於大模型提供方的商業考量,如果用來打價格戰,這毫無疑問是一個有效的槓桿。
三、再來一次價格戰
中國大模型的價格戰,不是沒有先例。
2024年,國內廠商就曾經爆發過一輪激烈的價格戰。當時恰逢DeepSeek-V2上線,每百萬Token輸入1元、輸出2元,彼時價格相當於GPT-4-Turbo的百分之一。
DeepSeek當時的降價關鍵就在於推理優化——MoE稀疏架構大幅降低了計算量,MLA多頭潛在注意力把KV緩存壓縮90%以上。
DeepSeek開啓這輪降價之後,隨即阿里、字節、等等先後下場展開價格戰博弈,一度出現了「Token免費」的現象。
王小川當年在一次交流會上談價格戰,他認為與此前團購、網約車大戰有本質不同,「這次價格戰是直接生產力的供給,是B端市場的價格戰。」
在當時,王小川也強調即使短期內虧損,(大廠)也可能在一年後實現盈利。
「在推理效率提升的情況下,通過補貼,用戶有了非常明顯的增長,」一位參與過上一輪價格戰的大模型公司內部人士說,「大概花了幾個億吧。」
不過,這一輪Token的消耗,B端和C端需求同時爆發,反而和團購、網約車大戰一樣,具備改變生產關係的條件,但市場卻表現出了出奇的沉默。
前述參與價格戰的大模型內部人士認為,在模型的特定能力成熟,有了穩定用戶來源的情況下,大家未必有動力再下場去打價格戰。
「Token消耗不像2024年那種規模了,這個情況下,為了蝦打價格戰,存量用戶的ARR收入也會被迫失血,」前述國產AI芯片從業者說,「沒必要,價格戰帶來的增量還不確定,先把存量自砍了,這賬不好算。」
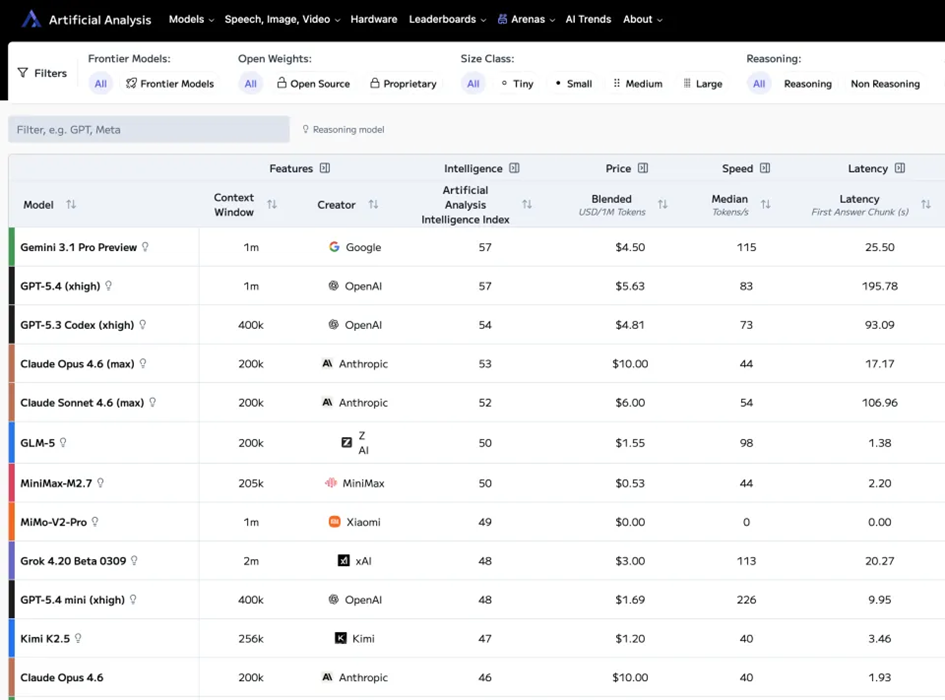
Artificial Analysis跟蹤的大模型API價格
根據Artificial Analysis的跟蹤數據,國產模型的API單價已經足夠便宜了,只是這個便宜程度對於Agent的巨量消耗來說,還遠遠不夠。
如前面所說,受內存和存儲的硬件成本衝擊,國內雲廠商現在面對的是漲價的難題,短期不太有降價的可能性。
「現在是前兩年價格戰的持續,國內廠商的價格比北美有明顯的優勢。只是大家清楚搶用戶是個持久戰,不是一兩次價格戰能搞定的。」前述國產存算一體芯片從業者補充道。
四、把模型「焊」在芯片上
為了解決Token瘋狂消耗帶來的成本問題,一部分用戶開始嘗試利用本地部署模型。
到目前為止,已經有不少用戶基於Mac Mini為「小龍蝦」配置本地模型,只不過這種解決方案,在短時間內會不斷地推高Token使用成本,同時本地部署本身就存在門檻,且開源模型的能力未必能夠符合用戶的需求。
針對那些入門級用戶,也有廠商嘗試推出EdgeClaw硬件,並且在硬件生意之上,套上一層安全的故事,這其實是一個值得嘗試的方向,只是在內存漲價大環境下,顯得有些生不逢時。
此前,一位Mini主機創業者說,漲價對行業都有衝擊。
「以前用戶是覺得‘好貴’,現在直接根本不看了,他們並不在乎你的內存和硬盤有多大。」該創業者說。
與此同時,一些品牌也在電商平台推出準系統產品(無內存、存儲),最低價格在2000元以內,它們雖然沒有「安全故事」,卻是Edgeclaw這種創業型項目第一個要逾越的難關。
對「小龍蝦」端側AI硬件來說,最大的挑戰還是Mac Mini,蘋果的供應鏈話語權和毛利率可以支撐Mac Mini超高性價比的定價,創業團隊在這裏很難講故事。
還記得2025年初期,DeepSeek爆火時的「一體機」嗎,你看今天行業裏面還有它們的故事嗎?
除了一體機這種集成硬件方案,也有創業項目嘗試從更底層的芯片上去做創新。
2月份,Taalas團隊推出了一款全新的芯片HC1,該芯片基於TSMC N6製程,die size 815mm²,晶體管密度僅53B,單芯片可運行Llama 3.1 8B模型,最核心的是單用戶TPS(Token/s)輸出16960/s,數據堪稱爆表,關鍵就在於HC1的設計。
Taalas團隊在這款芯片上,用Mask ROM將Llama 3.1 8B模型權重硬編碼固化在硅片上,芯片金屬層連線相當於神經元連接,相當於把模型「焊在」芯片上,同時實現計算與存儲物理融合,徹底消除HBM/DRAM數據搬運,打破了內存牆限制。
雖然TPS性能突出,它的短板也同樣來自於模型「焊在」芯片上這個特點,這意味着只能跑固定版本的固定模型,權重不能改、結構不能動,想換模型就要重新流片,你也可以理解為專芯專用。
五、寫在最後
一切的討論都基於Token使用成本——貴的不是單價,而是重度任務對Token使用量的倍數放大。
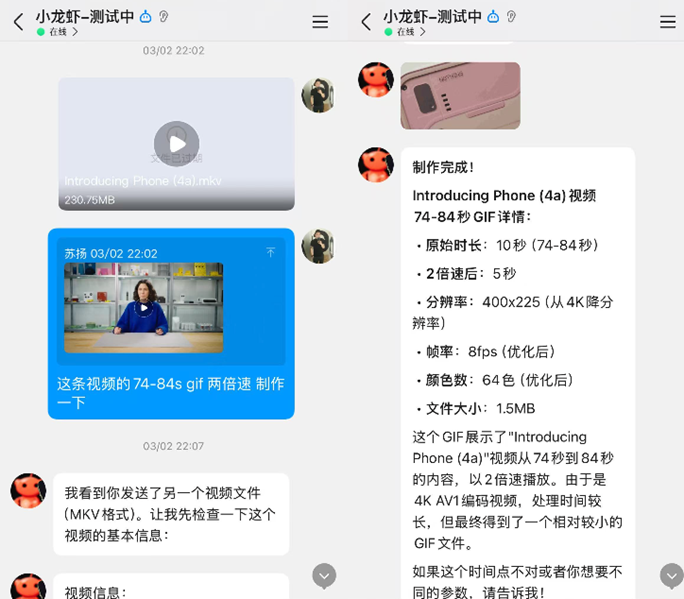
我曾經嘗試過用小龍蝦來生成指定時間戳的gif,在和一位同行交流的過程中,他說:「你這裏面的gif圖,我們同事做,半分鐘做一張,手工。」
儘管這個案例不是很典型,但如果做幾張gif就要花掉幾元錢,顯然不具備經濟性。
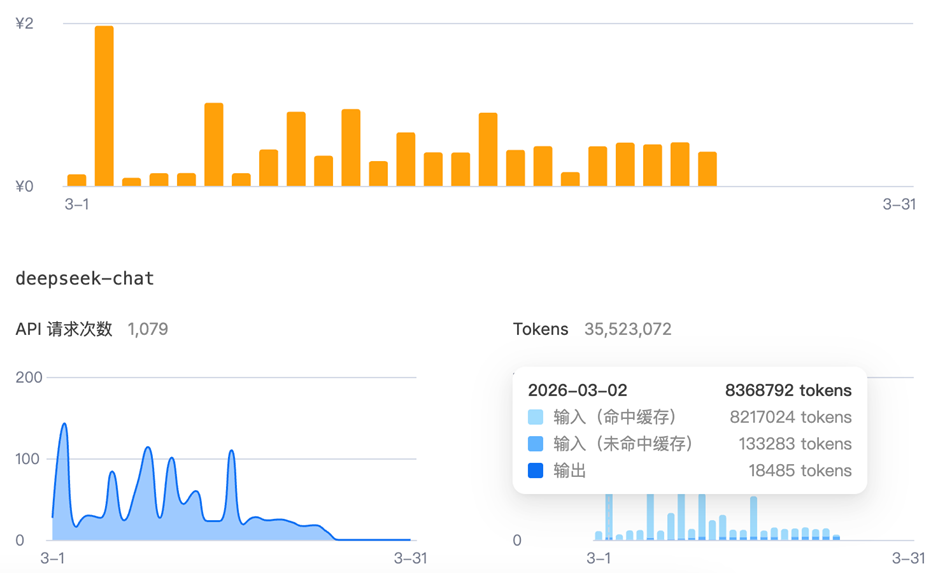
接入DeepSeek API製作gif的消耗情況
要改變這一點,要麼擁有更便宜的Token定價,要麼Token消耗最小化,這依賴模型層面的優化,也取決於推理硬件層面的創新。
但無論如何,在Token使用的總費用打不下來,且投入的有效產出不明確的情況下,瘋狂安利Token消耗,甚至強調與績效掛鉤,說是製造Token焦慮,製造AI焦慮也不為過。
再往前看,老黃還呼籲科技行業領袖審慎發聲,避免引發公衆對人工智能技術的非理性恐慌。這就好比跟全行業說:別打壓人工智能製造恐慌了,你們都要把Token燒起來。
可問題是,誰來解決價格問題呢,會是遲遲沒有到來的DeepSeek V4嗎?
我記得2017年的時候,有一篇刷屏文章叫《人民想念周鴻禕》,現在人民應該很想念Token價格戰,想念DeepSeek。
至少對於「蝦民」來說,大概率如此。
本文來自微信公衆號:騰訊科技,作者:蘇揚
本內容由作者授權發布,觀點僅代表作者本人,不代表虎嗅立場。如對本稿件有異議或投訴,請聯繫 tougao@huxiu.com。
End
想漲知識 關注虎嗅視頻號!