
4月4日,忍耐了許久的Anthropic,終於宣佈切斷了第三方客戶端掛在Claude Pro/Max訂閱賬號的通路。
這一舉動瞬間在開發者社區激起了軒然大波。不少習慣了通過OpenClaw和OpenCode等代理工具薅官方訂閱羊毛的用戶對此表示極為不滿,畢竟,為數不多的幾條通往國際頂級大模型的「低價高速」又少了一條。
兩天之後,小米AI團隊的羅福莉發布了一篇關於Mimo Token Plan的推文,批判了當前智能體行業中算力分配的亂象。
兩家AI公司的彼此獨立的商業動作,異口同聲地揭示了一個不易發現的行業真相:
大模型正在從互聯網免費午餐的幻覺中退場,迴歸作為稀缺能源的物理本質。
01
訂閱制的崩塌
一個擺在眼前的事實是:算力的「大鍋飯」,已經供不起爆發兩個多月的智能體了。
在傳統的SaaS時代,訂閱制就是互聯網公司商業文明的基石。
無論是著名的Netflix,還是以前幾乎每個人電腦中都必須安裝的Office 365,商業邏輯都是一樣的:「用大多數人的閒置來補貼極少數的重度用戶」。
但在如今的智能體時代,這個邏輯已經失效。
羅福莉在推文中隱含了一個深刻的洞察:在當前的算力成本下,低廉的token價格、高強度的使用頻率和第三方代理的完全開放,構成了一個不可能三角。
對於幾個月前的大語言模型,傳統的對話式使用(Chatbot)受到人類輸入和閱讀的速度限制,單次會話的Token消耗基本存在一個明確的上限。
但Agent毫無徵兆地徹底打破了這個博弈規則。
一個像OpenClaw這樣的編程代理,想要執行任務就必須進行高頻的環境感知和工具調用。
越複雜的任務,模型需要記住的內容就越多,在真實應用場景下,隱藏在每一次微小修改背後的,可能是超過上百萬的token消耗。
如果把訂閱制比作健身房的會員卡,過去的用戶只是偶爾去運動一個小時打個卡。
但現在的智能體用戶,就是帶着一群大胃王去喫自助餐,而且每個人的胃都是無底洞。
按照目前Claude Opus 4.6的API價格,輸入端5美元/百萬token,輸出端25美元/百萬token,一個深度開發者通過第三方代理進行短短几個小時的重度編程,實際消耗的token價值可能輕而易舉地消耗上百美元。
結論顯而易見,Anthropic賣出一份幾十或是上百美元的訂閱,不僅不賺錢,甚至要虧損不少算力成本。
Anthropic在正式切斷第三方接入之前,已經不止一次封禁各種渠道的外部訂閱,而Google的Antigravity和OpenAI的Codex也同樣有類似的操作。
本質上,這就是AI企業不約而同的一次商業化止損,防止訂閱制被智能體帶來的算力黑洞徹底吞噬。
國內的AI企業當然也不能倖免。
今年3月起,智譜、阿里、騰訊等企業推出的Coding Plan訂閱服務陸續宣佈大幅度漲價。
短短一周之內,和此前的外賣大戰如出一轍的低價獲客活動就草草落幕。
02
計費模式的演進
模型越變越強,用戶越來越多,AI行業的計費邏輯也正在經歷着從模糊到精確的演進,而這背後則是用戶付費認知與廠商成本壓力之間的博弈。
①明碼標價的API
原生的API就是最初的工業級「電錶」。
API從AI行業走入人們視野至今,一直都是最透明的計費方式,也是讓普通用戶最焦慮的方式。
它和每家每戶的電錶一樣實時跳動,每一句「你是誰」都在扣費。
極其公平的計費方式,實際價格卻觸目驚心:
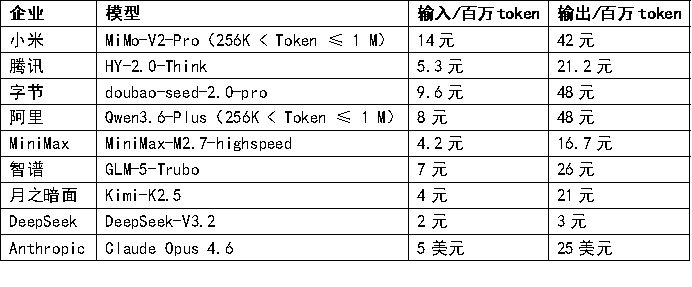
Anthropic被全球用戶詬病的超高定價自然不必多說,但國內的AI巨頭們發布的旗艦模型API價格也絕對說不上便宜。
價格門檻不僅阻礙了大規模的C端普及,B端用戶也不得不仔細考量本地部署的經濟效益。
但在AI企業相繼推出訂閱服務之前,這就是用戶唯一能選擇的付費方式。
也因此,開發者的每一次調用都伴隨着極大的「算力焦慮」,這種焦慮也扼殺了AI本該帶來的探索性嘗試。而更多的用戶,選擇繼續在網頁中與AI免費交流。
②隨處可見的Coding Plan
面對這種付費慾望極低的困境,Coding Plan成為了變現的良機。
雖然名稱各有不同,但目前國內外主流大模型幾乎全部推出了訂閱制的Coding Plan,這也是付費認知和成本壓力彼此妥協的最終產物。
它通過「每5小時1200次請求」這樣的模糊規則,將算力包裝成了一種類似寬帶包月的服務。
隨着Coding Agent的誕生,其價值逐步得以體現:它成功建立了一部分開發者用戶的付費習慣。
這些程序員們成為了第一批喫螃蟹的人,他們開始在電腦上讓AI幫着編寫代碼、運行、調試、修復bug,而不是通過複製粘貼的方式頻繁切換窗口和網頁中的AI進行交互。
不過,僅僅兩個月之後,這種計費方式的侷限性也暴露出來:不透明。
這1200次請求,可不是用戶給AI發送消息的次數,而是調用模型的次數。
用戶的1次提問,就會觸發幾次甚至幾十次的模型調用。完成一個任務需要幾次提問、幾次模型調用?沒人能說得清。
除此之外,廠商為了控制成本,往往要在後端進行精細的流量控制,甚至在壓力過大時通過模型降級等方式來維持服務。
這種計費模式,最終直接導致了用戶使用體驗的斷裂。對於專業開發者來說,一旦進入高強度的編程狀態,要麼是發現AI突然降智,要麼是因為多次對話達到頻率限制而不得不中斷。
③小米發布的Token Plan
這是4天前小米啱啱推行的一套新的計費邏輯,也是羅福莉在推文中極力倡導的方案。
值得注意的是,發布當天晚上,騰訊也推出了同樣的計費方式。
與Coding Plan不同的是,它不再使用以次數為限制的虛無縹緲的承諾,而是像手機流量包的配額制一樣,明確告知用戶一個周期內套餐中能夠使用的token數量。
當然,羅福莉作為小米AI團隊的代表,一篇推文的發布必然優先立足於小米的商業化利益。
與此同時,如果只看旗艦模型,小米的MiMo-V2-Pro能力和國內第一梯隊的智譜、MiniMax、Kimi也拉不開太大的差距,但價格卻並不「親民」。定價表中「一杯咖啡」的價格,怕是給星巴克用戶專門定製的。

但必須承認的是,這種計費方式是目前能夠兼顧算力緊缺現狀和商業利益的唯一解法,也是最符合貨幣經濟運行規律的方式。
人們花錢購買生產資料,而產出的價值則取決於生產力。
AI服務被量化為可預測的成本,「提效」的壓力也交還給了開發者。
一個月前被賣到脫銷的Coding Plan已經告訴我們,在底層大語言模型的性能拉不開差距的情況下,一價定律在訂閱服務上是成立的。
因此,可以預見,在4月接下來的幾周內,Token Plan即將接管新的token計費戰場。
至於小米的模型能力到底對不對得起定價,市場競爭最終會給出公平的答案。
03
技術層面的反思
高昂的API調用成本、限流限售的Coding Plan、再加上讓token進一步漲價的Token Plan,算力緊缺的問題從來沒有被根本解決,反而進一步籠罩了全球AI市場。
以前AI巨頭們抱怨算力不夠,是因為規模化定律(Scaling Law)始終在發揮作用。
在那個大語言模型跑分決定一切的年代(儘管就是幾個月以前),想要推出具有競爭力的新一代旗艦模型,算法、算力和數據就必須有所突破
顯然,相比起算法,算力和數據的堆砌在工程上與投入呈明顯的正相關關係,只要有更好的數據和更多的芯片,模型就必然會更強大。
但Agent時代,規模化定律雖然仍在生效,但效果已經不如先前顯著。
如今的算力缺口,從訓練階段轉移到了推理階段,而Vibe Coding技術和以OpenClaw為代表的代理程序可謂是罪魁禍首。
就像我之前的觀點一樣,OpenClaw等一衆桌面代理的出現創造了前所未有的僞需求。
而推理階段中出現很大一部分算力缺口,就是因為其Agent框架設計粗糙,人為製造出了大量毫無必要且效能低下的交互。
SGLang的核心貢獻者趙晨陽在4月6日發布的一篇文章中,把這種現象成為「用消防水龍頭澆花」。
而起因是因為他在觀測現有的Agent框架實際產生的請求模式時,發現緩存命中率(Cache Hit Rate)慘不忍睹。
這與羅福莉推文中提到的問題完全一致:目前的第三方Agent框架在上下文管理上表現得極其「懶惰」。
為了在複雜任務中不會因為遺忘信息而脫離應用場景,Agent往往會在每一輪對話中都重新發送一次全量且未經優化的上下文。
而在接近上下文窗口的上限時,大約每3步就會「破壞性」地壓縮一次工具響應信息。
這種行為在工程角度來看最為直觀和簡便,但幾乎讓為推理引擎設計的提示詞緩存機制變得無效。
趙晨陽的描述很符合目前AI行業軟硬件發展的現狀:
硬件工程師拼命把HBM做大,推理引擎工程師拼命優化KV Cache內存佈局,然後上層Agent框架以一種愚蠢的請求方式將資源揮霍殆盡。
這就是各種Claw爆火的匪夷所思之處和商業邏輯:
模型能力不足→靠Agent框架增加token消耗來彌補→token銷量增加→廠商漲價
自工業革命以來,這套運行邏輯不符合任何技術演進的過程。
這就好比有人設計了一輛極度費油、甚至一邊開一邊漏油的破車,駕駛者不僅沒能跑的更遠,反而因為浪費了大量燃油而推高油價。
而現實已經證明,這種依靠低效堆砌換來的繁榮必然是虛假的:
3月上旬安裝龍蝦成為淨賺幾百元的生意;
3月中旬AI企業開始免費給用戶安裝龍蝦;
3月下旬上門卸載龍蝦再次成為淨賺幾百元的生意;
4月龍蝦在普通用戶中無人問津。
羅福莉推文中說的一句話值得所有開發者牢記:
痛苦最終會轉化為工程紀律。
只有Token變貴到人們不能揮霍的程度,開發者纔會有動力去思考:
如何用更少的Token完成更多的任務。
04
算力不再是「免費午餐」
人們總是在說,AI,或者說token,未來將會成為水和電一樣的生活基本資源。
於是,AI行業內也普遍形成了一個共識,未來token的成本將會被打到一個極低的水平。
但現實也如此嗎?
至少目前的趨勢,是token在越來越貴。
國內受限於芯片出口限制,算力必須作為「省着花」的存量資源;國外受限於電力基建和電網功能,算力變成了有上限的增量資源。
在這種既需要算力加強基礎模型性能,又需要算力滿足爆發的推理需求的環境下,算力的供不應求已經不僅是AI企業需要考慮的問題,全球的AI用戶也必須承擔一部分經濟成本的壓力。
也因此,Coding Plan幾周前的價格戰無需任何叫停的聲音就已經銷聲匿跡。
按照火山引擎總裁譚待所說,國內智能體用戶的體量只有百萬級,而這已經能讓各大AI企業在短短一周之內接連漲價訂閱服務,核心原因仍然是:
其中存在大量快速消耗token但產出價值極低的僞需求。當算力以大鍋飯的形式供給大衆時,這些僞需求就會快速擠佔公共資源。
於是,「精準配給制」理所應當地出現了。
Google的Gemini API增加了付費優先級,小米和騰訊推出了價格更高的token訂閱服務,本質上都是在通過價格手段進行資源的最優配置。
按token使用量計費,正是要讓更具價值的token分配給能創造出更多價值的人。
而這場算力經濟的變局,遲早要深刻影響每一個AI用戶的日常。
在過去的二十年裏,軟件工程的主旋律一直是「用空間換時間」和「用硬件換開發效率」。
但在Agent時代,算力被抽象為token,顛覆了這套邏輯併成為了最昂貴的變量。
未來的AI用戶,可能不會再有0門檻使用AI完成生產任務的機會,還必須做出一個艱難的二選一:
要麼有錢購買高價值token,要麼懂得算力預算管理。
也就是說,對於絕大部分人們,在使用AI時都必須有清醒的認知,並準確判斷一項任務值得調用什麼水平的模型,甚至是一段上下文如何進行更有效地摘要和每一次工具調用是否是冗餘的操作。
或許不容易意識到,但我們已經被迫進入了一個算力精算的時代。
不僅是開發者,每一個AI用戶都必須站在推理引擎、模型能力和業務價值的十字路口做出權衡。
低效的用戶依靠暴力堆砌token,在頻繁的改錯和吵架中耗盡額度,最終和拒絕使用AI的人並無兩樣。
而高效的用戶學會設計出更好的提示詞架構,用更聰明的調度方式讓模型在更短的上下文中給出答案。
這場由Anthropic切斷第三方渠道引發的討論,已經給所有人敲響了警鐘:
算力紅利接近枯竭,算力紀律已經降臨。
我們必須接受高價值token正在變得昂貴而稀缺的現實,而且只能在這個現實中尋找新的工程最優解。
羅福莉在推文的最後給出了一句結論:
Agent時代不屬於燒算力最兇猛的人,而屬於利用算力最聰明的人。
提高生產力的關鍵,絕不是規定每個員工一個月必須要用掉多少token這種滑稽的做法,而是如何把單位算力的智商產出比提升一個數量級,這纔是Agent時代的入場券。
至於通用人工智能(AGI),在現有的底層模型能力和Agent算法框架水平下,還只是春秋大夢。