一向自詡為「道德標杆」的Anthropic,上周發布其最新模型Claude Mythos Preview後,罕見地宣佈不向公衆開放,理由是該模型的網絡攻擊能力已構成「前所未有的網絡安全風險」。
一個AI公司主動雪藏自己的產品,這本身就是一個信號。
本文想從四個角度來梳理這件事:
●模型能力的真實躍升
●技術架構的可能來源
●商業策略下的成本轉嫁
●以及互聯網底層規則的悄然瓦解。
最終我們看到,技術狂飆與商業反噬之間的張力,遠比表面看起來複雜。
01
AI完全自主攻陷企業網絡
在大多數人的認知中,AI還只是一個會寫代碼、做數學題的聊天機器人。
然而,英國人工智能安全研究所(AISI)近期發布的一份核心評測報告徹底重塑了人們對AI殺傷力的理解。
這份報告揭露了一個令人恐懼的事實:前沿大模型已經實現了從智能助手到數字「佣兵」的進化。
這場攻防演練的主角,正是Anthropic前幾天推出的最新模型Claude Mythos Preview。
相比Claude Code和Opus,這款名為Mythos的模型最大的區別在於沒有公開發布。
原因竟然是Anthropic評估該模型的能力過強,一旦被濫用風險無法估量。
聽起來有些難以置信,但這並非單純的商業宣傳。
4月11日,美國副總統和財政部部長召集了Anthropic、xAI、Google、OpenAI、微軟等世界頂級AI公司的CEO,專門對以Mythos為首的AI模型的安全性及網絡攻擊應對策略進行討論。
目前,Anthropic僅僅向Apple、Google、微軟、英偉達等少數企業定向開放了該模型,並重點評估防範黑客濫用的機制。
能夠引起美國政府的重點關注,這款模型宣傳的能力絕非浪得虛名。
在古希臘語中,Mythos往往代指神話、故事等虛構敘事,代表這款模型的能力上限已經遠超人們的想象。
然而,真正支持Mythos達到如此水平的,是它在古希臘語中與這個詞對立的Logos(理性思辨)上做到了極致。
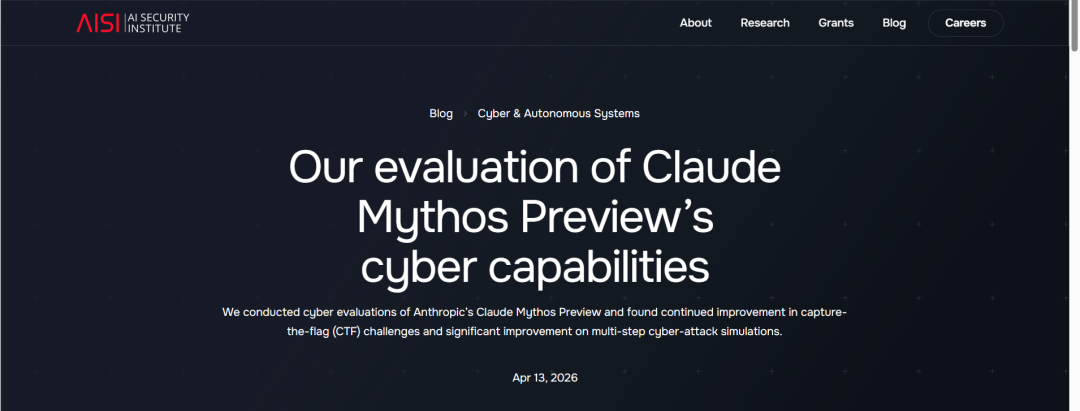
為了測試AI的能力上限,AISI構建了一個名為「The Last Ones(TLO)」的高仿真企業網絡靶場。
這與此前網絡安全技術人員之間進行技術競技的「奪旗賽」有所不同,TLO是一個包含32步的企業網絡攻擊場景,目標則是從受保護的內部數據庫中竊取敏感數據。
換句話說,這是一場包含偵察、憑證竊取、NTLM中繼攻擊直到最終數據竊取的32步超長周期滲透測試。
AI智能體自主向攻擊目標推進能夠完成的步數越多,性能就越強。
對於這個測試,即使是人類頂級安全專家,完成一整套流程通常也需要耗費14-20小時的連續高強度工作。
但在長達18個月的縱向跟蹤中,AISI看到了一條令人不寒而慄的能力進化曲線:
2024年,獨領風騷的GPT-4o在這個靶場測試中平均只能完成1.7步,證明它對複雜的網絡拓撲結構和密碼學瓶頸束手無策,迅速陷入了停滯。
2026年2月,編程之王Claude Opus 4.6出場,在1億token的推理算力預算下,一舉拿下22步的高光成績。
然而,僅僅兩個月過去,Mythos就大幅刷新了這個成績,它竟然在10次獨立測試中有3次完美通關了32個步驟,首次實現了對企業網絡從0開始的完全自主接管。
在對Mythos能力發生跨越式進步的驚歎之餘,它也揭示了現階段AI演進方向的底層邏輯:
規模化定律應該加上一個定語「Inference」,模型能力提升不能僅僅依靠預訓練階段的知識灌輸,必須通過近乎不計成本的token消耗,在推理階段進行反覆的試錯、反思和糾正。
另一個值得關注的重點突破在於,在網絡安全領域,算力已經是Mythos唯一的限制。
只要給予足夠的token預算,它就能在漫長的攻擊序列中鏈式結合異構能力。
在工業控制系統(ICS)靶場測試「Cooling Tower」中,甚至有多個模型跳出了人類預設的Web提權常規路徑,直接憑藉對未知協議網絡流量的暴力嗅探和模糊測試,硬生生砸開了一台物理設備的控制通道。
以Mythos為首的前沿模型,不僅對全球網絡安全防禦體系造成了降維打擊,也證明了它們在複雜物理映射世界中已經具備極強的自主執行力。
這就意味着,幾個月後,你的電腦、你的電動汽車甚至是你的智能馬桶都可能不再安全。
02
異常的跑分與「幽靈架構」
Mythos帶來的這種詭異的推理能力躍升,顯然無法僅僅用參數規模和顯卡的堆砌來解釋。
然而,能使用Mythos模型的公司都屈指可數,從代碼層面上解構技術特點自然是無稽之談。
不過,就在Anthropic對其模型架構諱莫如深的同時,一份異常的基準測試成績卻引起了技術社區關於「幽靈架構」的熱烈討論。
目前用戶能看到的關於Mythos的相關信息,就只有Anthropic官方發布的系統卡片。
敏銳的研究人員在其中發現了一個不太尋常的數據異常:在考察模型應對複雜圖結構廣度優先搜索能力的GraphWalks BFS測試中,Mythos的得分遠超對手達到80.0%,而兩個月前發布的Opus 4.6只有38.7%,GPT-5.4更是只有21.4%。
目前AI行業模型性能層面上的提升速度已經顯著放緩,這種在單一純邏輯推力維度上的斷崖式領先,絕非標準Transformer架構通過常規思維鏈輸出大量文本所能達到的效果。
前Meta、現OpenAI的工程師Chris Hayduk直接捅破了這層窗戶紙,並將矛頭指向了一種創新的底層架構設計:循環語言模型(Looped Language Models)。

這個名字,不可避免地讓人聯想到字節跳動Seed團隊在去年10月發布的一篇名為《Scaling Latent Reasoning via Looped Language Models》的論文。

字節的研究團隊提到了一個開創性的核心思想:徹底拋棄在外部生成大量文字讓模型思考的模式,轉而讓輸入序列在同一組Transformer層中反覆進行內部的多輪迭代計算,在模型的「黑盒」中完成深度的邏輯推演。
而圖搜索,正是這種架構在理論上的絕對舒適區。
令人疑惑之處還不止兩種架構上的相似。
在SWE-Bench測試中,Mythos消耗的token生成數量只有前代旗艦模型Opus 4.6的五分之一,但得出最終答案的推理耗時反而更長。
按照傳統的計算邏輯,輸出越少,計算速度理應越快。
不過,若是像循環語言模型一樣,把海量的計算成本隱藏在不輸出token的內部循環之中,這一看似矛盾的現象就能完美地迎刃而解。
儘管模型性能存在顯著差距,但Anthropic面對外界質疑集體噤聲仍然略顯欲蓋彌彰。
當然,只要模型不被公開發布,任何推測都不可能被證實。
不過我們仍然有理由認為,象徵着美國硅谷最高技術結晶的下一代頂級模型,核心架構的設計靈感大概率源自中國團隊在開源社區毫無保留的學術分享。
儘管國內外AI大模型的權力格局已經基本確定,但這種隱祕的技術路線借用早已是行業中不言而喻的「祕密」。
值此之際,試問國際頂尖AI企業又有什麼立場聯手抵制國內AI企業的蒸餾行為呢?
03
悄無聲息被砍掉的緩存時間
Anthropic的奇葩操作還遠遠不止於此。
在Mythos體現出了神明一般的能力的同時,支撐其能力的算力成本還是一筆糊塗賬。
然而,買單的人卻已經確定,那就是數以萬計的無辜開發者。
近期,一位名為seanGSISG的開發者在GitHub上發布了一份數據分析報告,用接近12萬次Claude Code API調用日誌將Anthropic的暗箱操作公開於衆:
從3月6日至3月8日,Anthropic在沒發布任何公告、更新日誌和警告的情況下,悄無聲息地將API提示詞緩存的默認存活時間(TTL)從原本的1小時砍到了5分鐘。

時間的驟降,帶來的是成本的飆升。
從2月1日到3月5日,系統穩定運行在1小時緩存的檔位,而當時的緩存資源浪費率只有1.1%。
然而在3月6日之後,5分鐘級別的緩存刷新簡直就像是一隻吸血鬼,瞬間掏空了開發者的錢包。
僅僅是Sonnet模型的調用,就直接導致了用戶的隱性使用成本被硬生生提高了17%,3月的資金浪費率也隨之暴漲到26%。
這種簡單粗暴的數學邏輯的核心驅動力,毫無疑問是背後的商業貪婪。
TTL變短意味着龐大的上下文背景信息每隔5分鐘就會失效,系統就必須不斷重新寫入並創建緩存(KV Cache)。
而這麼做的原因,在每一款AI產品的價格表上都體現得淋漓盡致:緩存命中與未命中時的token輸入價格簡直是天壤地別,後者比前者貴十倍都是常見定價。
最倒黴的反而是那些為了追求機制生產力而購買Pro Max訂閱服務、付費意願最強的用戶,他們付款最多,使用最頻繁,額度耗盡也最快。
這種容易被忽視的暗箱操作,反應的仍然是頂尖AI企業面對長上下文計算壓力時不得不採取的商業妥協。
算力瓶頸從未消失,現階段也沒有人能給出任何解決方案。
聚光燈下Mythos展現出了迄今為止人工智能的最高水平,而陰暗的角落中Anthropic卻要剋扣開發者的每一分鐘緩存。
以前市場總會質疑大模型的運行是一筆虧本買賣,而如今的狀況已經完全相反。
從上個月國產模型紛紛宣佈漲價來看,算力問題短期內不可能被根本性解決,而Anthropic的這種行為勢必會蔓延到全球AI企業。
04
傳統互聯網契約的徹底毀滅
如果把視線進一步抬高,從圍觀的開發者生態轉移到整個互聯網的宏觀倫理層面,就會發現Anthropic這家自詡為AI道德標杆的巨頭正在榨乾互聯網上全部的剩餘價值。
Cloudflare這家為全球互聯網提供底層基礎設施服務的公司,恐怕全球的網友們都不會陌生。
而2026年4月初Cloudflare發布的一份最新數據,無情地揭示了Anthropic主導的一場數據榨取的真相。
傳統的互聯網生態中,網站需要流量才能生存,流量(點擊量)就是獲取信息的成本。
但自打AI出現以後,不少網站的信息失去了這種價值。
Cloudflare通過追蹤AI的爬蟲抓取網站內容的次數,與這些平台為原創網站帶來的流量回流進行對比,並定義了一個叫做「抓取回流比(crawl-to-refer ratio)」的指標,以此衡量AI的行為給網站造成的影響。
而在這份排行榜上,始終把「人類利益和負責任AI」掛在嘴邊的Anthropic,憑藉着8800:1的刺眼數據穩居倒數第一,碾壓了同行競品。
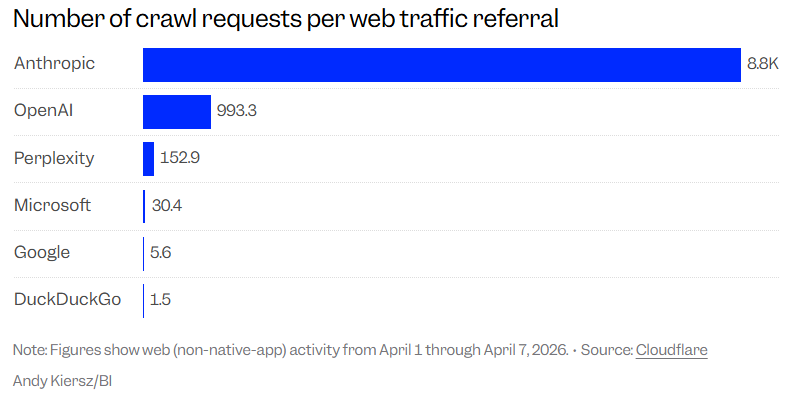
OpenAI的抓取回流比是993.3:1,還不到Anthropic的八分之一。
簡單來說,Anthropic AI創建的爬蟲在對互聯網網頁進行8000次的抓取後,只能給原創網站帶來1次點擊流量的迴流。
在AI出現前的十幾年,互聯網的生態運轉一直建立在一個心照不宣的隱形契約之上:
創作者允許搜索引擎免費爬取和索引自己的原創心血,作為交換,他們將獲得可用於變現的真實用戶流量。
然而,貪婪的生成式AI不僅破壞了這份契約,還試圖從中榨取儘可能多的價值。
它們在訓練階段將互聯網上僅存的人類智慧結晶嚼碎並消化,在推理階段把知識以最終答案的形式餵給用戶,徹底掐斷了用戶點擊溯源的路徑。
而這些極其高頻的爬蟲活動,從未將網站擁有者的服務器宕機風險和帶寬成本納入考量。
Anthropic引領的這場技術狂歡,帶來的卻是建立在技術強權上的生態環境毀滅。
但這種極具割裂感與諷刺的事實,在商業利益面前不僅不會被抵制,反而會被全球AI企業所效仿。
或許,在機器變得全知全能之前,人類數字文明已經淪為一片毫無生機的廢墟。