
智東西
作者 | 雲鵬
編輯 | 漠影
今天,AI算力軍備競賽如火如荼,從搶芯片到囤算力,GW(吉瓦)級數據中心一座接一座拔地而起,海外科技巨頭更是動輒掀起數萬億元級別的AI基建大工程。
但錢真的「花在刀刃上」了嗎?或者說,「囤」的算力真的有被充分利用嗎?
根據國內RISC-V架構AI芯片領域頭部玩家之一奕行智能的研究團隊測算,各類AI加速器的實際利用率遠低於理論峯值。
問題不在於芯片不夠強,而在於現有的軟件調度方式,無法在運行時靈活地「餵飽」硬件。有人將賣算力比作AI「賣鏟子」,但同樣一把鏟子,用什麼力度、角度去挖,在老師傅和菜鳥的手裏,效率或有天壤之別。
我們看到,AI算力領域的下一波紅利,在於購買更高利用率的芯片,把每一分算力,真正用滿、用好。
在此背景下,近期智東西與奕行智能進行了深入交流,了解到其最新突破性研究正直指這一AI芯片行業痛點,其內部已研發實現基於Tile級虛擬指令集實現AI加速器的動態調度(TISA)。
簡單來說,TISA構建了一套「讓芯片在運行時自己做決策」的動態調度架構——在編譯器和硬件之間建立一種新的調度語義契約,使芯片能基於實時狀態智能分配任務。
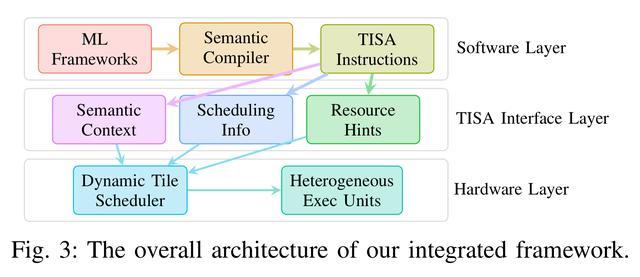
TISA整體架構示意圖
值得一提的是,TISA 動態調度架構論文《Dynamic Scheduling for AI Accelerators via TISA》正式入選 ISCA 2026,這也是國內AI芯片公司在ISCA上的重要突破。
要知道,ISCA如同計算機體系結構界的Nature,是該領域歷史最久、最具影響力的會議,這代表奕行智能的核心技術路線已經獲得國際同行的正式認可。
可以說,讓有AI算力需求的玩家們「花小錢辦大事」,在AI時代更好地把握機遇方向上,奕行智能實現了一次重要突破,給產業破局提供了一種新的思路。
一、芯片買了錢花了,為什麼效率提升跟不上?解密TISA三項核心突破
當前,各類前沿AI芯片單卡算力動輒達到幾PFLOPS(每秒千萬億次浮點運算)甚至幾十PFLOPS,峯值算力大幅提升,但相比算力的大幅提升,芯片算力利用率的提升卻遠未達到理論峯值。
從AI芯片內部結構來看,矩陣計算單元、向量計算單元,以及數據搬運單元協同運行,三者各司其職,同時持續滿負荷運轉才能實現最高效率。但當前AI芯片中主流採用的「編譯時靜態調度」模式,會在在程序運行前就把所有任務的執行順序一次性排定。
這就像工廠廠長提前排好了生產計劃,卻不考慮工人臨時請假、設備臨時故障、原料臨時缺貨等情況(對應芯片運行時的帶寬爭用、溫控降頻等隨機擾動),很容易造成流水線「空轉幹等」。
即便部分現代GPU在線程束(warp)調度等底層機制上引入動態調度,但這些機制僅在極細的指令粒度上運作,僅能解決CUDA Core內部的指令調度問題,無法協調數據搬運單元TMA、Tensor Core與CUDA Core三者的併發執行,仍存在侷限性。
相比之下,TISA架構是如何突破這一瓶頸的?整體來看,主要是三項關鍵技術創新。
首先是語義保留編譯器,其作為「翻譯官」,可以做到不丟失「背景信息」。傳統編譯器把AI模型翻譯成芯片指令,往往會丟棄算子類型、依賴關係等關鍵語義信息,就像轉述菜譜是只說操作步驟,卻不說每一步需要用什麼材料、什麼廚具、目的是什麼。而奕行智能的編譯器在翻譯每一步時都會刻意保留這些「上下文」,讓芯片執行的每一個計算任務都有完整說明,這是後續智能調度的信息基礎。
第二個重要創新是給每一個計算任務都附帶一張標準化「任務說明卡」,實現Tile級指令集TISA,說明卡會註明計算類型、所需硬件、依賴數據結果等信息,藉此,芯片在運行時不再需要「猜測」就能精準判斷和規劃任務的並行和等待。
形象地來看,在AI計算過程中,AI編譯器會將大算子切分為可獨立調度、並行執行的小塊,抽象成為一個個「Tile(數據塊)」,就像把一座積木城堡拆解為一個個積木塊,在保證計算完整的同時,能顯著提升調度靈活性與硬件利用率。
這已經成為目前行業的共識,2025年Tile編程範式迎來爆發:從英偉達發布CUDA 13.1與cuTile工具鏈到北大開源TileLang獲得「國產Triton時刻」的讚譽,再到DeepSeek更宣佈新模型算子優先用TileLang做精度基線。可以說,讓Tile抽象成為行業共識,既能適配AI模型特性,又能充分挖掘芯片並行潛力。
第三是構建芯片的「實時大腦」,奕行智能對其命名為衝突感知運行時調度器,這也是整套系統的核心。調度器持續監控芯片上所有計算單元的狀態,一旦發現某個單元空閒,會立刻從待執行任務中找出滿足條件的任務推送過去,整個決策過程極為迅速,從判斷到下發僅需幾納秒,不會給芯片帶來額外負擔,但可以大幅降低各單元「空等」時間。
相比在軟件層通過算法進行運行時調度有微秒級延遲,奕行智能的動態調度在硬件層實現,速度可以快100到1000倍,每一個調度決策可以保證在納秒級內完成,減少延遲帶來的損失,可以說,TISA也一定程度上代表了其軟硬協同能力。
從實際案例測試來看,在目前大模型推理中公認最先進的注意力機制實現FlashAttention-3中,相比CUDA版,TISA版本代碼量減30%,同步調用減少50%,性能達到手調基線的95%以上,並且由編譯器自動生成的,無需任何手工優化。

CUDA版代碼(左)與TISA版代碼(右)對比
值得一提的是,同一套TISA指令流不僅可以在奕行智能自研芯片EPOCH上運行,也可以適用於其他第三方硬件平台。
總體來看,TISA首次在AI芯片領域實現了Tile粒度的動態調度,填補了行業空白,首次定義了Tile級ISA作為軟硬件間的調度語義接口。
對於行業來說,奕行智能提供了一條擺脫「算力依賴」,不再一味追求大,而是更高效地充分利用好既有硬件的技術路徑,這對雲端大模型推理和端側AI部署等計算資源受限、成本控制敏感等場景均有直接價值。
二、深耕類TPU架構,兼顧AI計算通用和專用,硬件、軟件、生態一個不能少
TISA架構實現突破的背後,是奕行智能在AI芯片領域長期深耕和深厚技術積累的一次階段性成果展示。在交流中我們也了解到,奕行智能對AI算力產業發展有深入思考和關鍵判斷,TISA技術突破正是其核心戰略方向上的一次技術落地。
從產品技術佈局上來看,在芯片硬件層面,奕行智能研發的國內業界首款RISC-V AI大算力芯片EPOCH已經在今年年初就實現了大規模量產出貨,這也是業內率先採用RISC-V+RVV(RISC-V向量擴展)指令集架構、用於數據中心領域的AI算力芯片,填補了國內RISC-V架構在高性能AI計算領域的空白。

EVAS解決方案亮點
實際上,近期RISC-V架構在數據中心領域的應用已經成為行業重要趨勢方向,包括英偉達重金投資RISC-V龍頭企業SiFive以推動其數據中心業務與RISC-V生態系統的融合、Meta面向數據中心的AI芯片MTIA 300也利用了RISC-V向量核心、谷歌將RISC-V作為TPU芯片的底層指令集架構,與此同時,高通、Tenstorrent等相關領域全球科技巨頭也在持續加大對「RISC-V+AI」的投入。
奕行智能可以說很早就看清並認定了這一方向,在其團隊看來,RISC-V是當前最適合構建AI芯片的指令集架構:開放的圖靈完備指令天然支持複雜控制流,可以補上ASIC/NPU的靈活性短板;RVV向量則天然契合AI張量計算,掩碼操作原生支持稀疏矩陣;允許在標準之上擴展專用指令的定製化潛力,則讓AI芯片可以更好地兼顧通用性與專用性。
在當前全球大國博弈日益激烈的背景下,相較於需授權的Arm和x86架構,RISC-V作為開源開放的指令集架構,天然具有中立性,在打破壟斷、構建開放生態、構建自主可控的AI算力底座方面,有着不容忽視的戰略意義。
在RISC-V的基礎上,奕行智能在芯片架構設計方面有別於傳統通用GPU,類谷歌TPU架構專門針對AI計算場景進行了原生優化,可以實現更高能效比,進一步提升AI訓練與推理效率,降低算力部署成本。
其自研的E Link互聯技術,既可作為AI計算模組內部的芯片間高速互聯方式,同時還支持Scale Up與Scale Out融合組網,集合通信庫加速,可以滿足多種互聯拓撲下對大帶寬、低延遲的智算互聯需求,支持前沿的在網計算。
可以說,這是國產自主高速互聯的重要突破。
奕行智能的芯片產品已經面向國產主流大模型進行了深度適配優化,實測性能可以達到國內領先、對標國際一流的水準。在實測中,相比國際競品,奕行智能芯片在模型推理速度顯著提升:RestNet50提升52%,BERT-Base提升31%,GPT-J-6B提升25%,LLAMA2-13B提升43%,提升幅度明顯。
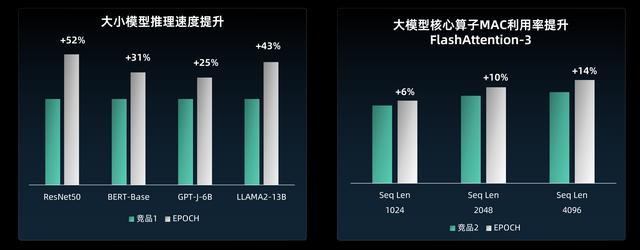
EPOCH與競品芯片性能對比
實際上,類谷歌TPU的專用AI加速芯片通常都會在性能和能效比上有着比通用GPU更大的優勢,但其主要挑戰來自於生態適配成本,這也是行業努力的方向。
在降低生態適配成本、吸引開發者高效編程方面,基於Tile的編程模式本就能提供更友好的編程接口,提升算子開發效率,而此次入選頂會的獨創Tile級動態調度架構,由Tile級虛擬指令集、智能編譯器和硬件調度器組成,原生適配Tile生態範式,能實時適配硬件行為,充分挖掘芯片潛力,在編程方面也更為乾淨簡潔。
Tile級動態調度架構的自動管理指令間依賴、指令順序流水和內存切分,都可以顯著提高編程易用性。
生態層面,奕行智能正積極與vLLM、Triton、gitee等國內外開源社區互動,與Triton國際社區合作,把Triton編譯導流到RISC-V DSA後端,並將開源其虛擬指令集,合力打造針對RISC-V DSA的CUDA生態,對於RISC-V DSA整個產業的發展具有重要的戰略意義。
值得一提的是,奕行智能還計劃舉辦RISC-V AI 應用大賽,面向高校及科研院所開放合作,包括資源支持、技術培訓交流等,進一步加速RISC-V產學研生態的發展和成熟。
三、最新旗艦AI芯片已大規模量產,拿下行業頭部客戶
此次奕行智能在TISA技術方面的突破可以快速落地到自家芯片以及各類主流算力芯片中,並非只是停留在實驗室中的技術。實際上,在產業落地和商業化方面,奕行智能已經取得了長足進展。
奕行智能已經發布了多款AI芯片產品,據稱其最新一代EPOCH在行業頭部客戶中持續取得商業突破,可以說是真正走到產業中去了。

當然,芯片賽道歸根結底是「技術為王」,紮實的技術研發和產線體系的建立是奕行智能長期在堅持推進的,其核心團隊來自業界頂尖系統與芯片公司,目前佈局北京、上海、深圳、杭州、南京、廣州等地。
從AI內核架構、編譯器、ESL 建模,到芯片前後端設計、封測與量產的全鏈條自研能力,奕行智能均有佈局。簡單來說,他們有着全流程端到端交付能力和全鏈路商業化閉環能力。
作為國內唯一實現RISC-V雲端AI算力芯片大規模量產的公司,奕行智能無疑已經成為AI時代RISC-V陣營在AI芯片賽道的核心扛旗手。
結語:從通用算力競賽到能效比對決,AI芯片設計轉向「運行時智能」
在交流中,奕行智能相關負責人提到,TISA架構突破帶來的並不是一個簡單的性能數字提升,而是AI芯片系統設計思路的一次重要轉變:從「靜態確定性」向「運行時智能」,編譯器可以描述意圖,進而讓硬件實現實時決策。
當然,這背後離不開多項關鍵技術的創新以及完善軟件工具和生態的支撐,在追尋更高能效比、更極致成本的今天,奕行智能着實給行業提供了一種新思路。
面向未來,行業變革仍在繼續,成本的重壓有增無減,AI算力產業已經從 「通用算力競賽」進入了「能效比對決」時代,以TPU為代表的專用領域AI計算架構,以突出的能效比取得了市場成功,而奕行智能是其中跑的最快的一批。
在算力版圖逐漸重塑、國內AI芯片競爭激烈之下,奕行智能已經成為強有力的行業挑戰者和行業賦能者。