前不久,Anthropic 停止允許訂閱用戶通過 OpenClaw 等第三方工具接入 Claude API。理由並不複雜,一個OpenClaw 代理運行一天,消耗的算力成本在1000美元到5000美元之間,而用戶每月只付了200美元。
Claude Code 負責人 Boris Cherny在 聲明裏說,訂閱服務「並非為這些第三方工具的使用模式而設計」。這句話沒有錯,但它遮住了一個更基礎的問題:沒有任何訂閱服務能被設計成覆蓋這種使用模式。Agent 場景下的 Token 消耗量沒有上限,也沒有歷史數據可以參考,任何固定月費都是在對一個無法建模的變量做猜測。
3月底,中國國家數據局公布了另一組數字:中國日均 Token 調用量突破140萬億,兩年增長超千倍。同期,字節的 Token 調用量躋身全球三甲,與 OpenAI、谷歌並列。無問芯穹CEO 夏立雪在一場行業論壇上描述這個增速時說,上一次看到類似的曲線,是3G時代手機流量從每月100MB開始普及的時候。當時沒有人預料到,流量放開之後會跑出抖音、微信和外賣。
兩件事放在一起,描述的是同一個現實:Token的消耗正在以罕見的速度增長,但支撐整個行業運轉的定價邏輯,依然建立在兩年前聊天機器人時代的假設之上,即用戶的使用量是可以被歷史數據預測的,輕度用戶會自然地覆蓋重度用戶,整體成本可以被攤平。
智能體們打破了這個假設的每一個前提,市場變化的速度,超過了任何定價模型的響應能力。縱觀過去兩年 Token 市場的演化,每一個優勢窗口的終結,都由同一個邏輯驅動,即當競爭者能夠複製優勢——規模可以被追趕,算法可以被開源,場景可以被大平台的分發能力碾壓。
目前唯一難以被快速複製的,是將 Token 效率內化為產品架構、定價邏輯和工程文化的能力。而在這件事上真正做到體系化的,只有 Anthropic。
失去意義的平均價格
Token 之所以不同於電力、鋼鐵等傳統生產要素,在於它具備獨一無二的「可編程性」。沒有任何一種傳統生產要素,能僅憑「指令不同」就將自身價值改變十萬倍。這種可編程性,是 Token 作為新型生產要素的本質特徵,也是理解當前 AI 經濟混亂的前提。
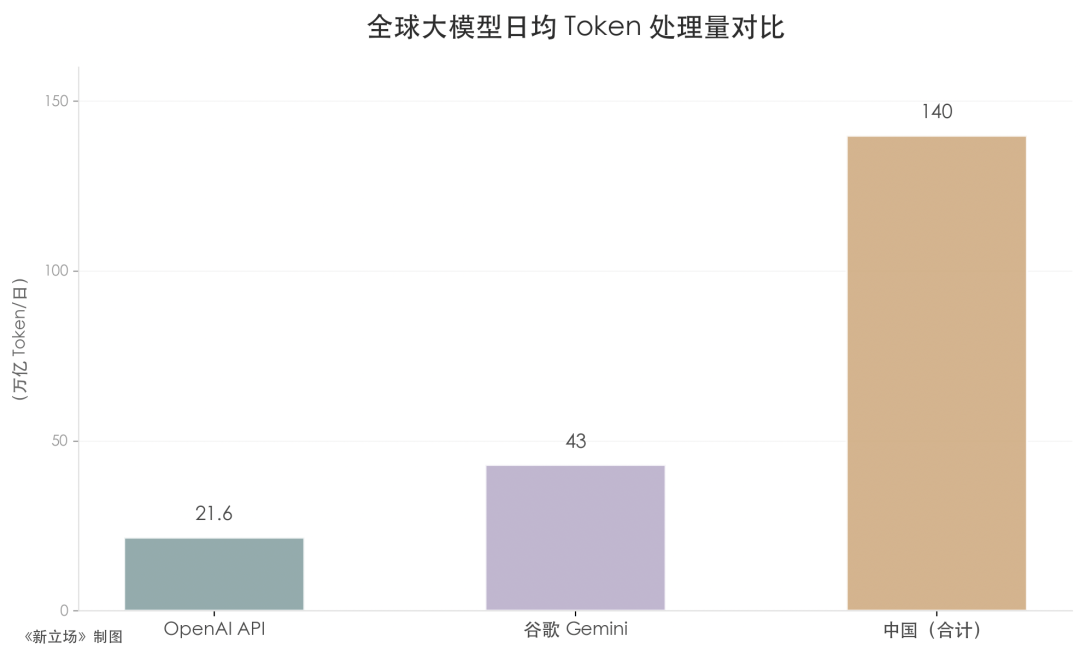
理解這一點,需要先建立量級感。36氪報道,OpenAI API 日均處理約21.6萬億 Token,谷歌Gemini 日均約43萬億,而中國的140萬億約為前兩者之和的兩倍有餘。摩根大通預測,僅中國的AI推理 Token 消耗,就將在五年內再增370倍。這個量級本身說明了,Token 已經是一個經濟規模指標。
此外,Token 的大量消耗使用發生在公有云的統計口徑之外。金融機構在本地服務器上跑票據識別,車端智能座艙的對話在車內閉環完成,工業機器人的視覺模型以毫秒級響應運行在邊緣設備上,這些都不會出現在任何公開數據裏。一位從業者估算,非公有云API的調用量至少是公有云的五到十倍。
規模之外,Token 的價值結構與生產成本更應該關注。黃仁勳今年3月在一篇署名文章裏把AI產業拆成五層:能源、芯片、基礎設施、模型、應用,並將 Token 定義為現代 AI 的基本單位,也是AI的語言和貨幣。這個定義的精妙之處在於,它同時指向了Token的兩種屬性:作為語言,它是計算過程的原子;作為貨幣,它是價值流通的媒介。
但生產一個 Token 的代價,遠比這個定義看起來複雜。據 Sam Altman 和 Epoch AI 披露,ChatGPT 發送一條文本提示大約消耗0.3瓦時。谷歌搜索的耗電量(0.03瓦時)僅為其一小部分。谷歌2025年也曾披露,Gemini發送一條典型的文本提示大約消耗0.24瓦時,併產生約 0.03 克二氧化碳。
隨着模型複雜度的增加,推理成本也相應上升。GPT-5級別的系統每次查詢可能消耗約18瓦時,而進行擴展推理時則可能消耗高達40瓦時。 差距來自兩個地方,一是模型大小,參數越多,生成每一個Token所需的計算量就越大;二是推理模式,新一代模型在輸出每一個可見 Token 之前,會在內部進行大量隱式推演,用戶看到一個字,模型內部可能已經「想」了上百步。單個可見 Token 的真實成本,被這個思考過程成倍放大了。
這是 Token 與電力、石油這類生產要素的根本區別,Token的價值並不由生產成本決定,而完全由使用場景決定。同樣一百萬個 Token,用於閒聊,市場價約0.01美元;用於代碼生成,可以值200美元;用於法律文件審查,價值可能超過1000美元,價值差距達十萬倍。耶魯大學研究者將這一特徵描述為 Token 的「可合同化」屬性:數量可以精確計量,但價值取決於它被編程去做什麼。
當整個行業用同一個價格邏輯去覆蓋價值差距十萬倍的使用場景時,系統性的定價混亂就不是偶然,而是必然。
因此,所謂平均 Token 價格,就像用平均客單價來描述一個既有路邊攤又有米其林餐廳的商圈,即便數字正確,但毫無意義。Collis 和 Brynjolfsson 曾在2025年的估算顯示,生成式AI在2024年僅為美國消費者創造的消費者剩餘就高達約970億美元,用戶實際獲得的價值,遠超過他們支付的金額。這個數字的絕大部分,集中在高價值應用場景。
Token經濟的窗口期正在合攏
在 Token 經濟中,競爭優勢是跟隨技術躍遷、產品形態轉變與市場結構共同決定的時間窗口。每一個窗口的受益者,都在無意識中為下一個顛覆者鋪路,而能在多個窗口連續卡位的玩家,纔是真正的贏家。
2025年初,算法是 Token 第一個窗口。DeepSeek V3 發布後,混合專家架構(MoE)將同等能力的推理成本壓低了一個數量級:模型內部包含多個專家子模塊,每次推理只激活其中一小部分,在保留完整模型能力的同時,將單次推理的實際計算量大幅壓縮,將推理成本下降了一個數量級。
但算法窗口的悖論在於,打開它的那把鑰匙,同時也是關上它的鎖。DeepSeek 選擇了開源,將核心模型權重和架構設計公開,吸引全球開發者接入生態。這個選擇在短期內快速擴大了市場份額,在中長期則主動壓縮了算法領先的窗口期。當架構創新被開源,整個行業的 Token 成本基準被同步重置,算法優勢也就從專有壁壘變成了公共基礎設施。
同年底,規模成為第二個窗口。火山引擎將互聯網流量戰的打法平移了過來,用大規模的機場廣告宣告自己在 Token 市場的存在。譚待在4月2日的最新的業務進展分享中提到,兩年之內,火山引擎的 Token 調用量增長了1000倍,萬億級 Token 消耗企業增至140家。

不過規模優勢存在一定時效性,譚待在接受《第一財經》的採訪時也談到,在 Token 大規模調用量中,包含了大量無效算力。譚待以解數學題為例:枚舉法計算量大,模型能力不足就會採用類似方式,造成無謂消耗;更優秀的模型能找到簡潔解法,優化空間很大。規模數字的背面,是大量本可以避免的算力浪費。當競爭從「消耗了多少」轉向「每個Token創造了多少價值」時,規模窗口就開始關閉。
場景,是當前 Token 競爭最激烈的地方。智譜、MiniMax、月之暗面沒有字節的流量規模,也沒有阿里、騰訊的雲計算生態,但它們在 To B 高價值場景裏找到了立足點。智譜與 MiniMax 的市值一度超過快手等傳統互聯網公司,充分說明場景窗口在特定階段能創造的估值溢價有多大。
但這個窗口如今也正在收窄。在一場行業論壇上,楊植麟問智譜CEO 張鵬:你們為什麼漲價?張鵬的回答是,完成一個 Agent 任務消耗的 Token 量,是回答簡單問題的十倍甚至百倍;長期依賴低價競爭,對整個行業都沒有好處。
這場對話背後,一場更大規模的場景爭奪戰正在展開。字節通過飛書和釦子(Coze)平台,將大模型能力直接嵌入企業的協同工作流與海量流量節點;騰訊依託微信生態與企業微信,掌握着企業觸達並服務客戶的最短社交鏈路;阿里則將旗下 AI 業務統籌為 ATH 事業群,Token 消耗被直接打包成企業數字化底座的一部分。
這三家公司擁有在企業端已經建立多年的信任關係和系統整合能力。獨立廠商依賴模型質量差異維繫的場景優勢,正在被這種結構性優勢快速壓縮。
Token效率是當前正在形成的第四個窗口,也是最難被快速複製的一個。這一窗口的競爭,目前集中在 Coding 場景。Anthropic 封禁第三方工具後,大量習慣於低成本接入 Claude 的用戶開始尋找替代方案。OpenAI 迅速將自己定位成更易上手的選擇。但 Anthropic 押注的是訓練和運行模型的效率,OpenAI 的心態是奧特曼總能籌集到更多資金支持算力規模。
用資本堆算力換市場份額,是一種可以奏效但難以持續的策略。截至今年3月底,OpenAI 的 API 每分鐘處理量已突破150億 Token,而2025年10月這個數字還是60億。但算力供給的增速遠遠跟不上,GPU 租賃價格在兩個月內漲了48%,英偉達最新一代 Blackwell 芯片的每小時租用費用已升至4.08美元,數據中心的建設周期以年計算。OpenAI 甚至部分暫停了 Sora 視頻生成工具,騰出計算資源給編碼和企業級產品。
Anthropic 看到的是 Harness Engineering 這條路,通過重新設計 Agent 的調度架構,從系統層面減少無效 Token 消耗,讓更少的算力做更多的事。這是在算力稀缺的現實約束下,重新定義效率本身的含義。
而在中國市場,阿里雲也開始切入效率窗口,其將 Token 的定價、調用追蹤與企業賬單管理整合進統一的雲計算基礎設施。吳泳銘提到,很多企業已經不把 Token 消耗當IT預算,而是當作生產資料和研發成本來覈算。這是一種更慢的建法,但也更難被顛覆。
在算力供給觸及物理極限、需求仍在加速增長的現實下,真正稀缺的不是便宜的 Token,而是在有限算力約束下能產出最高價值密度的 Token。
封禁OpenClaw,只是結果
在算力稀缺、定價體系失效、Agent 消耗失控的多重壓力下,Anthropic 是迄今為止唯一一家不只是調整了定價策略,還從工程架構層面重新回答了「Agent應該怎麼運行」這個問題的公司。封禁是被動應對,Managed Agents 纔是主動給出的答案。
Harness 是 Agent 框架的調度層,負責決定何時調用模型、如何管理上下文、出錯時怎麼處理。在 Chatbot 時代,這套邏輯相對簡單。進入 Agent 時代後,Harness 開始承載更復雜的任務,也開始產生大量本不必要的 Token 消耗。

Anthropic 工程博客提供了一個具體案例,Claude Sonnet 4.5,存在一種被工程師稱為「上下文焦慮」的行為當模型感知到上下文窗口接近上限時,會提前終止任務。Harness為此添加了上下文重置機制,在適當時機強制清除並重載上下文,以確保任務繼續。這在當時是合理的工程補丁。
問題發生在 Claude Opus 4.5 上線之後。新模型已經不再出現「上下文焦慮」,但舊的重置機制仍在每次執行時觸發,消耗着不必要的 Token,增加着不必要的延遲。這些機制從解決問題的補丁,變成了製造成本的負擔。Anthropic 工程師將其稱為「死重」。
這是 Harness 框架的結構性缺陷:每一套 Harness 都是對某一時刻模型能力的快照。模型在持續進化,但快照被當作永久規則執行。模型迭代越快,這種錯位就越嚴重。
在商業場景裏,這個問題被進一步放大。OpenClaw 在處理單次用戶查詢時,實際產生的 API 請求數量是 Claude Code 官方框架的數倍,每次請求攜帶超過10萬 Token 的上下文窗口。換算成 API 費率,單次查詢的真實成本是訂閱價格的幾十倍。無論個人的主觀使用頻次高低,通過這類框架發起的請求,天然具有重度用戶的成本畫像。平台對重度用戶的補貼,由此從概率問題變成了確定性問題。
Anthropic 的應對是 Managed Agents,核心思路是為 Agent 領域建立接口穩定,實現自由替換的抽象層。「上下文焦慮」消失了,對應的重置機制自然退場,不會留下「死重」。內部測試數據顯示,在結構化文件生成任務中,Managed Agents 將任務成功率提升了最高10個百分點,提升最顯著的是最難的任務。
同期出現的 Hermes Agent,從另一個方向印證了同一個判斷。這個強調「閉環學習循環」的框架,在更新已積累的操作流程文件時,選擇以 patch 方式寫入,只傳入需要修改的具體字段,而非重寫整個文件。patch只觸碰問題所在,Token 消耗也更少。這是 Token 效率意識在框架設計層面最具體的體現之一。
Token 經濟的新競爭,已經細微到「誰能讓每一個 Token 產出更高的價值」。羅福莉在自己那篇瀏覽量超過73w+的帖子最後寫道,真正的出路不是更便宜的 Token,而是模型和 Agent 的協同進化。

這句話說的不只是技術路線,也包括整個行業定價邏輯應該完成的轉變:從按量計費,到按價值定價;從管理成本,到創造結果,這是整個行業需要完成的轉變。
Anthropic 在 Harness 架構上的探索,給出了目前最清晰的一個方向。但中間這段路,還很長。