AI投資正從「拼GPU算力」轉向「全棧系統效率」。智能體時代,瓶頸已從算力變為編排:GPU決定能不能做,系統決定能不能賺錢。下一輪超額利潤將加速流向CPU、內存及載板等擴產最慢的供應鏈環節,基礎設施重定價的大幕已然拉開。
AI投資的主敘事正在經歷一次結構性遷移。摩根士丹利最新研究指出,隨着AI從「生成內容」走向「自動執行任務」,下一輪AI基礎設施的增量邏輯將從「單芯片算力競賽」擴展為「全棧系統工程」——GPU依然是核心,但不再獨享預算與溢價。
據追風交易台,摩根士丹利研究部分析師Shawn Kim在報告中直接寫道,「智能體AI標誌着從計算到編排的結構性轉變。」在智能體工作流中,CPU側編排時間可佔總時延的50%至90%,由此推導出到2030年新增325億至600億美元的CPU增量市場空間,並將服務器CPU總TAM推至825億至1100億美元量級。
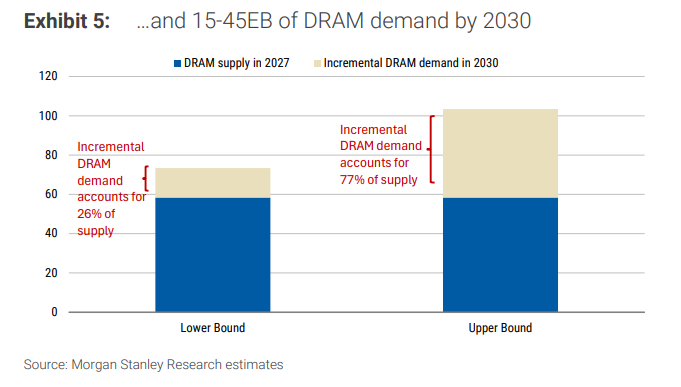
與此同時,DRAM、ABF載板、晶圓代工、存儲、連接器與被動元件等環節,均將從「配角」躍升為新的瓶頸與利潤池。將在2030年額外催生15至45EB的DRAM需求,規模相當於2027年全行業年供給的26%至77%。
這一判斷對市場意味着:AI資本開支的受益者將從少數芯片巨頭擴散至整條全球供應鏈,下一輪超額收益,可能更多來自那些在智能體工作流中最先成為瓶頸、且最難快速擴產的"使能環節"。隨着瓶頸在不同環節遷移,AI價值鏈的權重分佈隨之改變。
從「生成」到「行動」:智能體把瓶頸從算力推向編排
生成式AI的典型工作流結構相對簡單:用戶請求到達後,CPU完成少量預處理,GPU負責token生成,隨後返回結果。整個鏈路中,GPU是絕對主角,CPU僅承擔輔助功能。
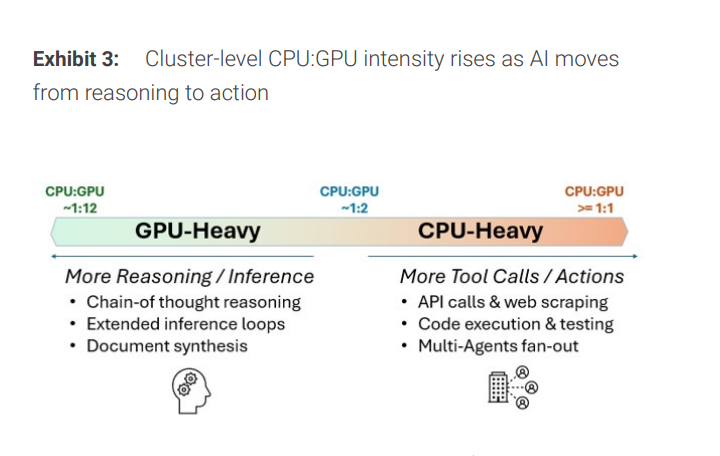
智能體的運作邏輯截然不同。完成一個任務,系統需要經歷規劃、檢索、調用外部工具與API、執行、反思迭代等多個步驟,還涉及多智能體協作、權限管理、狀態持久化與調度等大量「控制面」能力。大摩的核心結論是:智能體帶來的不是更"重"的單次推理,而是更多步驟、更多狀態、更多協調,而這些工作天然更適合CPU處理。
由此帶來兩個直接後果:其一,集群層面CPU與GPU的配比將系統性上升;其二,DRAM從「容量配置項」升格為「性能與吞吐的核心繫統組件」。數據中心的瓶頸將越來越多地出現在內存帶寬、數據搬運、互連時延與系統級協調,而非單純的GPU算力。
CPU配比正在重估:從"1:12"走向"1:2"乃至反轉
過去,"1顆CPU服務約12塊GPU"曾是AI服務器的典型架構描述。但報告指出,隨着智能體工作流變長、工具調用與上下文管理趨於複雜,這一比例正在快速收窄。
以NVIDIA路線圖為例,更新估算顯示:在Rubin平台附近,CPU與GPU的配比已接近1:2;若向Rubin Ultra等更激進形態演進,甚至可能出現2顆CPU對應1顆GPU的反轉配置。即便僅從1:12改善至1:8,對超大規模部署而言,CPU的絕對需求量也將出現量級跳升。
一旦這一方向成立,CPU的需求彈性將從「跟着服務器出貨走」轉變為「跟着智能體複雜度走」,這意味着CPU需求的增長將更具結構性,而非僅僅是傳統硬件換代周期的延續。
CPU TAM重算:2030年825億—1100億美元,增量來自編排
摩根士丹利採用「系統分層」方法,將智能體帶來的CPU機會從傳統服務器更新換代邏輯中剝離,建立三個獨立分析口徑:
Head Node CPU對應貼近GPU系統的機架控制層,以2030年全球約500萬顆AI加速器、每顆加速器配2顆高端CPU、CPU平均售價約5000美元為假設,對應約500億美元TAM。
Orchestration CPU覆蓋智能體編排新增需求,包括規劃與調度、工具鏈、RAG管線、KV cache與向量庫相關內存服務、策略與可觀測性等。算額外新增1000萬至1500萬顆CPU、ASP約3000美元,對應300億至450億美元TAM。
Other CPU涵蓋存儲節點、部分網絡節點等,對應約25億至150億美元。
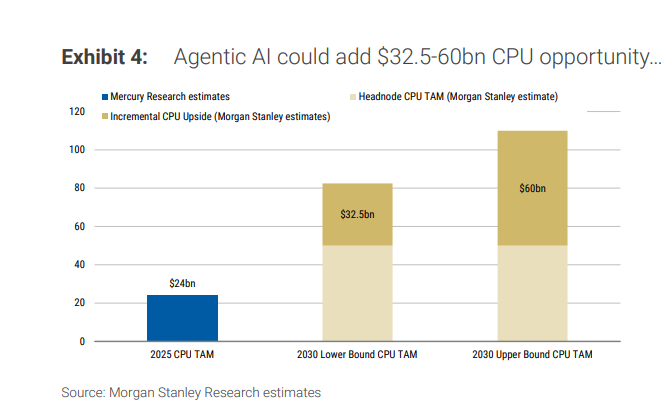
三項合計,2030年服務器CPU總TAM約825億至1100億美元,其中智能體帶來的增量約325億至600億美元。整個測算的底層錨點是對2030年全球AI數據中心基礎設施銷售額約1.2萬億美元的判斷(2025年約為2420億美元)。
報告同時給出了「上修開關」:若按NVIDIA口徑,2030年AI基礎設施銷售額達到3萬億或5萬億美元,則CPU TAM區間將被整體推至2060億至2750億美元,乃至3440億至4580億美元。這並非基準預測,但揭示了"AI工廠"規模擴張對CPU需求的系統性放大效應。
內存從配角變主線:2030年新增DRAM需求15至45EB
智能體的真正差異化不只在推理能力,更在「可持續的上下文與記憶」。持續上下文、KV-cache、工具調用中間態與併發智能體工作集,CPU側DRAM實質上成為HBM的功能性延伸。
測算模型直接明瞭:新增DRAM需求等於新增編排CPU數量乘以單CPU平均DRAM配置。兩檔假設分別為:新增1000萬顆編排CPU、每顆配置約1.5TB;偏樂觀情形為1500萬顆、每顆約3TB。由此推導出2030年智能體可帶來15至45EB的新增DRAM需求,相當於2027年DRAM行業年供給的26%至77%。
在周期判斷上,報告還注意到一個市場結構變量:多數內存供應商正在與大客戶討論3至5年長期協議(LTA),這可能令定價下行斜率趨緩,並將2027年前的盈利能見度抬高。「內存層級正在成為AI系統的核心變現路徑"——主機DRAM、內存接口芯片、CXL擴展及SSD/HDD分層存儲,都將成為更可持續的價值承接點。
供給越緊的環節越具定價權:ABF載板、代工與使能組件
而真正具備超額收益潛力的,是那些"產能擴得慢、驗證周期長"的使能環節。報告重點點名了以下幾條鏈:
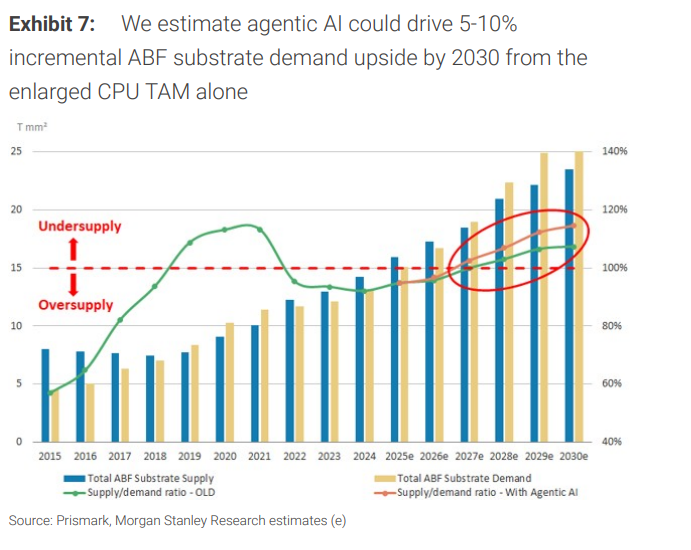
ABF載板:這輪AI驅動的ABF上行周期可能延續至本十年末,2026至2027年附近存在供需缺口風險。僅"CPU TAM擴大"一項,就可能帶來2030年ABF需求5%至10%的上修;其中服務器CPU ABF載板市場到2030年約達47億美元,CPU帶來的增量需求約12億美元。
晶圓代工(尤其先進製程):CPU代工可服務市場2026年約330億美元,2028年約370億美元。台積電在CPU代工領域的份額預計從2026年約70%進一步提升至2028年的約75%;並預計英特爾可能在2027年下半年開始將服務器CPU外包給台積電。
BMC與內存接口:Aspeed被強調為CPU服務器BMC的核心受益者,其在該細分領域約有70%的市場份額,新一代AST2700平台帶來40%至50%的ASP提升空間;Montage則被置於"內存互連"價值鏈,全球收入份額約36.8%。
CPU Socket與被動元件:報告以Lotes與FIT作為CPU socket的直接映射,測算每增加100萬顆CPU需求,Lotes收入約增加0.6%、FIT約增加0.2%(僅按socket口徑計)。被動元件方面,以"每台通用服務器約30美元MLCC內容量"為簡化假設,推算出2030年額外5億美元MLCC需求增量,約佔屆時全球MLCC市場的2%至3%。
CPU是最清晰增量,但"使能環節"更受偏愛
報告承認智能體工作負載增長將結構性利好AMD的雲端份額,但對AMD與英特爾均維持Equal-weight評級,傾向於通過NVIDIA、博通等「資本開支與token增長更直接映射至盈利」的標的來追蹤智能體主題,同時將估值約束列為重要考量維度。
從更宏觀的框架看,這份報告的核心價值在於將AI的投資範式從「單點算力軍備競賽」升級為「系統效率與瓶頸經濟學」:GPU是發動機,CPU是變速箱與控制系統,內存與互連是油路與底盤——單點極致仍重要,但決定規模化回報的是整車協同。
對產業鏈而言,這意味着AI投資的超額收益來源將更加分散也更為長期:不只來自「最強GPU」,更來自那些在智能體工作流中率先成為瓶頸、且最難快速擴產的環節。能夠持續追蹤的高頻驗證指標包括:新平台BOM中CPU數量與內存配置的上修幅度、雲廠商長期協議簽約節奏,以及ABF載板與先進製程產能的利用率走勢。