
4月22日報道,上周衝上OpenRouter熱榜(Trending)第一的匿名測試模型Elephant Alpha今早正式揭曉真身——螞蟻旗下的百靈模型Ling-2.6-flash。
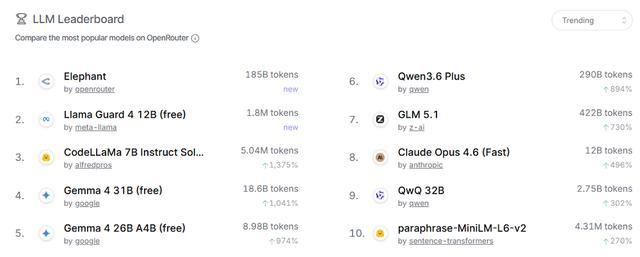
匿名上線以來,該模型調用量持續增長,連續多日位列熱榜榜首,日均tokens調用量達100B級別。不少網友試用後表示印象深刻,有人稱這是「用過最快的模型」「token效率很高」。
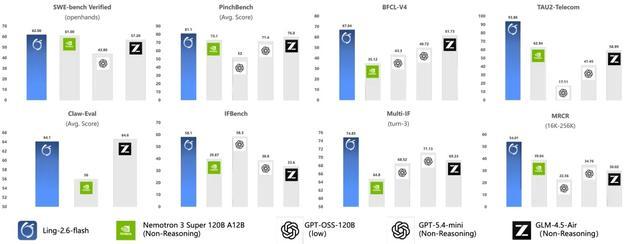
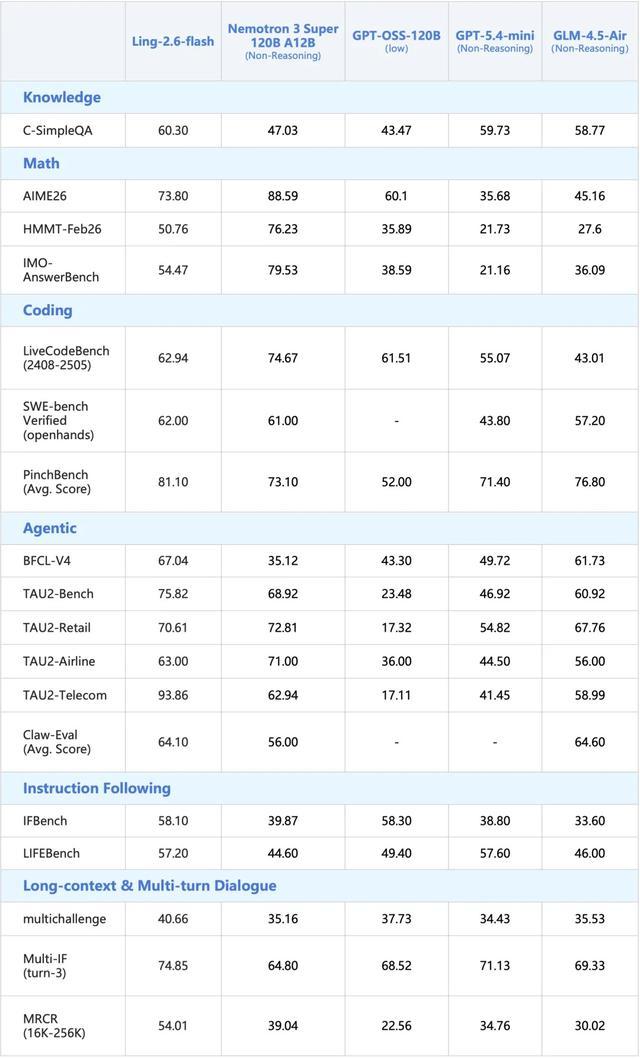
螞蟻今日宣佈正式推出Ling-2.6-flash。該模型總參數量104B,激活參數7.4B,為Instruct模型。如下圖所示,該模型在Agent相關基準上達到同尺寸SOTA水平,並在其他核心能力上表現出色。
Ling-2.6-flash追求的是在控制token消耗的前提下,保持對Agent任務的強競爭力,主要具備以下三大核心能力:
1、混合線性架構,釋放推理效率:通過引入混合線性架構,模型從底層優化計算效率。在4卡H20條件下,推理速度最快可達340 tokens/s,Prefill吞吐達到Nemotron-3-Super的2.2倍。
2、token效率優化,提升智效比:訓練過程中對token效率進行針對性校準,力求以更精簡輸出完成目標。在Artificial Analysis完整評測中,Ling-2.6-flash僅消耗15M tokens,約為Nemotron-3-Super等模型的1/10。
3、面向Agent場景定向增強:針對工具調用、多步規劃與任務執行能力持續打磨。在BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench等評測中,即使面對激活參數更大的模型,依然取得相近甚至SOTA級別的表現。
從智東西上周對該模型的實測來看,其在執行速度、指令響應、前端原型開發與長文件處理上表現高效,Agent規劃與工具調用能力較強,但在項目級應用開發上仍有侷限。總體而言,這是一款在輕量級、高頻任務中具有優勢的高效模型。

智東西用該模型接入類OpenClaw產品生成泰國7日遊攻略網站
Ling-2.6-flash將在OpenRouter與官方平台同步提供一周免費API調用。
官方免費期結束後,平台仍將提供每日50萬tokens免費額度;超出部分按量計費:輸入0.6元/百萬tokens,輸出1.8元/百萬tokens。模型的BF16、FP8、INT4等版本也將於近期開源。
一、實測:秒級響應、指哪打哪,幾十分鐘產出百萬字長篇
智東西在體驗中首先嚐試了一些編程小項目,發現其響應速度和Agent工具調用能力較強。
首先是一個網站,這主要考察模型的前端能力。拿到開發任務後,該模型對網站的幾個核心組件進行了規劃,並主動為這一網站加入了明暗模式切換、移動端響應式設計等我們並未要求的功能,最終耗時1分鐘左右完成開發。
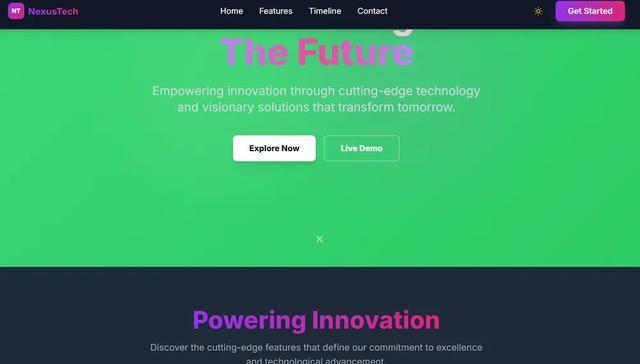
當我們要求它將網站的主色調改成綠色後,該模型用不到10秒鐘就完成了修改,其他大部分模型在處理修改任務時往往需要通讀上下文,逐一修改,花上幾分鐘。
而它基本做到了指哪兒打哪兒,這對於一些快速、高頻的網站調試需求是很實用的。
我們也試了試它有沒有打造項目級任務的能力,讓它根據自己的內部知識,復刻一個支付軟件。我們是在Kilo Code插件中體驗的模型編程,由該模型驅動的多個子Agent並行工作,進一步放大了它的輸出速度優勢,但是其最終打造的結果僅能算是一個原型。這種表現可能與其較小的參數量有關。
(更多體驗案例移步→《匿名模型「大象」攪局OpenRouter:100B參數衝到熱榜第一,實測結果如何》)
螞蟻官方也公布了一些Ling-2.6-flash的實戰演示:
在代碼場景,以網頁生成為例,Ling-2.6-flash兼具高審美表達與高速代碼生成能力,能準確調用前端組件與圖標庫,適合單頁面演示和原型製作中的快速驗證。
其INT4量化版本可在DGX Spark上運行,下面視頻為基於Ling-2.6-flash&DGX Spark 構建業界SOTA Hermes一體機教程。
Ling-2.6-flash結合Kilo Code可將視覺指令快速轉化為高質量界面,勝任個性化視覺風格生成、報刊級排版及周刊、報告等辦公內容的即時生成。
在文本場景,Ling-2.6-flash僅憑Prompt即可勝任多步驟文本任務執行,在指令遵循、文風調整與實時生成方面表現突出。
在Agent工具調用場景,該模型具備強大的上下文檢索、工具調用與高速響應能力,適合複雜信息處理與知識增強場景。
基於Ling-2.6-flash,長篇寫作助手autonovel可覆蓋世界觀設定、角色構建、大綱生成到正文創作的全流程,以200+ tokens/s的生成速度,僅需幾十分鐘即可產出百萬字長稿。
在需求整理和排期等真實工作場景中,Ling-2.6-flash能穩定參與信息檢索、任務拆解、內容處理與工具協同,具備較低的幻覺率與較高的結果可用性。
二、架構升級:推理吞吐最高提升4倍
Ling-2.6-flash延用了Ling 2.5的模型架構設計:在Ling 2.0架構基礎上引入混合線性注意力機制,通過增量訓練將GQA注意力機制升級為1:7的MLA+Lightning Linear高效混合架構。
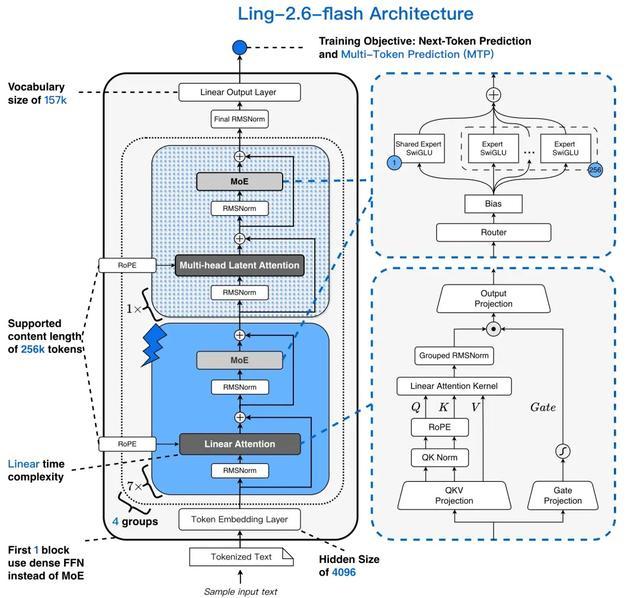
得益於混合注意力機制與高度稀疏化的MoE架構,Ling-2.6-flash在推理效率上優勢顯著。與同尺寸級別的主流SOTA模型相比,首字響應更快,長輸出場景下的生成效率更高,Prefill吞吐與Decode吞吐最高均可達到約4倍提升。隨着上下文長度和生成長度增加,吞吐優勢進一步放大。
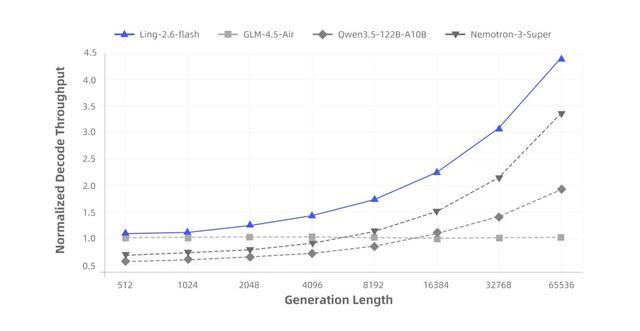
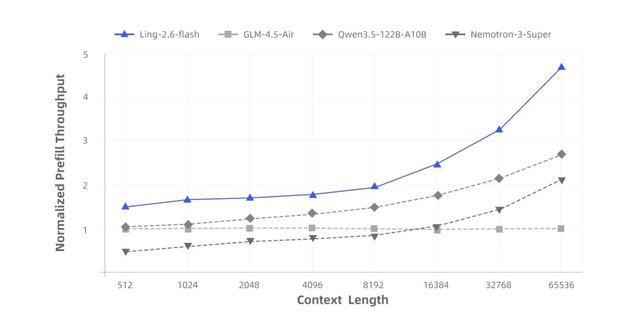
在預訓練階段,團隊通過大規模算子融合提升訓練效率;推理側則圍繞真實部署場景深度適配,使融合算子在融合粒度、實現路徑與數值行為上儘可能與訓練側保持一致。相關推理算子將隨linghe陸續開源。
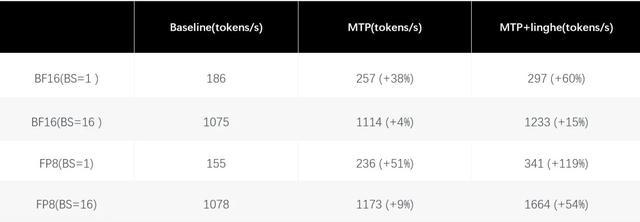
針對不同精度場景,推理鏈路進行了系統性優化:
BF16推理:實現QK Norm+RoPE、Group RMSNorm+Sigmoid Gate等關鍵算子深度融合,MoE Router GEMM與LM Head GEMM採用BF16 Input+FP32 Output計算方式。
FP8推理:進一步融合RMSNorm、SwiGLU與量化算子,針對小Batch Size引入Split-K的Blockwise FP8 GEMM,以此帶來更高的系統吞吐、單用戶TPS、更短的等待時間,以及在真實交互場景下更穩定、更流暢的使用體驗。
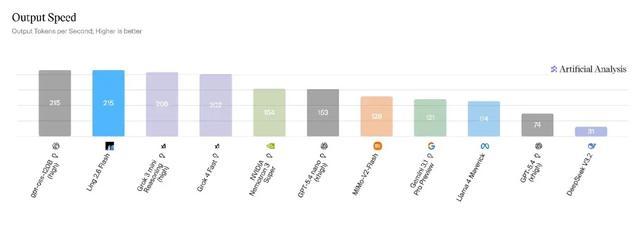
在Artificial Analysis排行榜的Output Speed維度測評中,Ling-2.6-flash以215 tokens/s的輸出速度處於第一梯隊。
三、更優性能,token消耗僅為同行十分之一
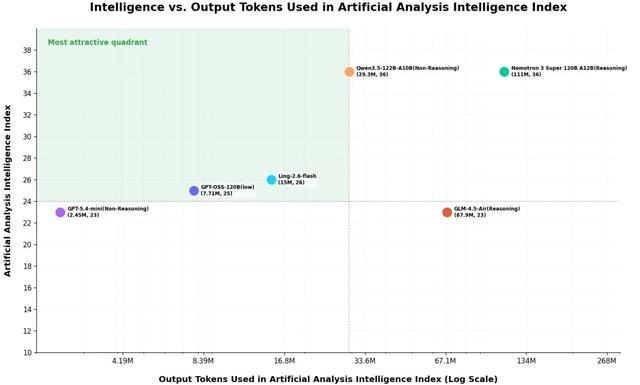
在Artificial Analysis的Intelligence vs. Output tokens對比中,Ling-2.6-flash展現了突出的token效率優勢:以15M output tokens實現了26分的Intelligence Index,在保持較強智能水平的同時將輸出消耗控制在相對更低的位置。相比部分依賴更長輸出換取更高分數的模型,它在「智能表現」與「輸出成本」之間取得了更優平衡。
對於開發者和企業場景而言,這種能力帶來的價值可能是更低的推理開銷、更快的首字響應、更短的整體生成時延,以及更流暢的交互體驗。
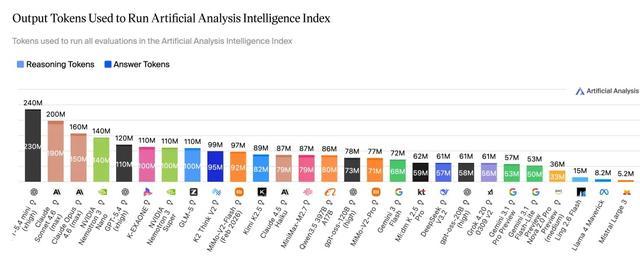
基於AA排行榜的官方測評分數繪製
從token消耗看,在 Artificial Analysis Intelligence Index 的完整評測中,Ling-2.6-flash的總消耗僅為15M tokens,而Nemotron-3-Super等模型達到或超過110M tokens——僅用約1/10的token消耗完成同類評測任務,智效比更高。
四、強化學習特訓:Agent能力對標SOTA
為增強模型Agent能力,團隊顯著擴展了Ling-2.6-flash訓練數據的難度與廣度,依託自研的大規模高保真交互環境,進行了針對性的General Agent與Coding Agent強化學習(RL)訓練。
模型在指令遵循、工具調用、多步規劃及長程執行方面表現提升顯著,在BFCL-V4、TAU2-bench、SWE-bench Verified、PinchBench等排行榜上表現優異。通過RL優化泛化性與穩定性,在Claude Code、Kilo Code、Qwen Code、Hermes Agent、OpenClaw等框架中均展現了良好的使用體驗。
此外,Ling-2.6-flash在通用知識、數學推理、指令遵循及長文本解析等維度保持優秀水準,各項指標對齊同尺寸SOTA模型。
結語:部分高複雜度場景受限,將繼續探索智效比邊界
經過一周的持續迭代和優化,Ling-2.6-flash在Agent場景的泛化性和穩定性方面獲得進一步提升。
Ling-2.6-flash在工具調用、多步規劃與長程任務執行等關鍵維度上實現了明顯提升。但百靈團隊坦言,部分高複雜度場景中,受限於推理深度,模型仍可能出現一定的工具幻覺;此外,在中英雙語自然切換、複雜指令遵循等方面仍有優化空間。
該模型後續迭代將繼續探索智效比的更優邊界,在保持高效推理特性的同時,進一步推動智能產出質量與token效率之間的深度平衡。