谷歌將AI芯片戰略推向新階段。
在周三拉斯維加斯舉行的Google Cloud Next 2026大會上,谷歌雲發布第八代張量處理器(TPU)的兩款新品——專為訓練設計的TPU 8t與專為推理優化的TPU 8i,這是谷歌首次將訓練與推理任務拆分至獨立芯片,標誌着其AI硬件路線的重大轉向。
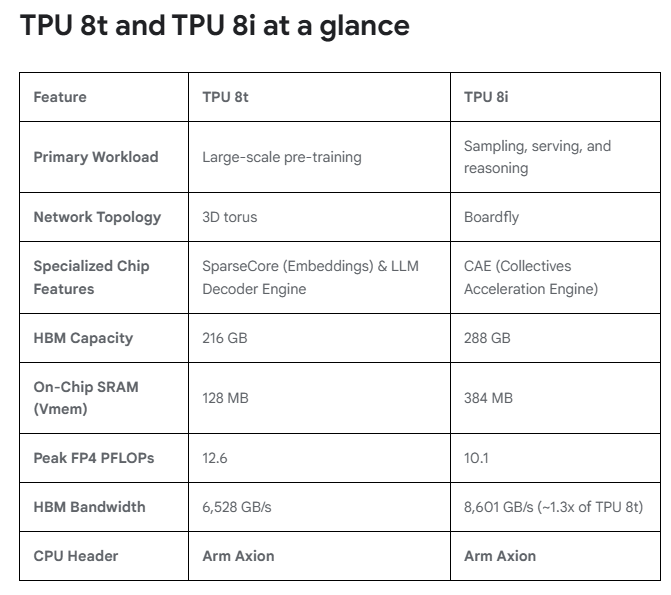
兩款芯片均計劃於2026年晚些時候正式對外供應。與去年11月發布的第七代Ironwood TPU相比,TPU 8t在同等價格下性能提升2.8倍,TPU 8i性能提升80%;兩款芯片每瓦性能均較上一代提升逾一倍,TPU 8t達124%,TPU 8i達117%。
谷歌高級副總裁兼AI與基礎設施首席技術官Amin Vahdat表示,隨着AI智能體的興起,"業界將受益於針對訓練和推理各自需求專門優化的芯片"。Alphabet首席執行官桑達爾·皮查伊亦在博客中指出,這一架構旨在"以具有成本效益的方式,提供同時運行數百萬個智能體所需的大規模吞吐量和低延遲"。
為何拆分為兩款芯片
此次將第八代TPU一分為二,是谷歌對AI工作負載日益分化趨勢的直接回應。預訓練、後訓練與實時推理在計算特性上已顯著分化:訓練任務追求極致吞吐量與規模擴展,推理任務則對延遲和併發更為敏感。單一芯片難以同時兼顧兩類場景的效率最優。
谷歌在技術博客中指出,第八代TPU的設計哲學圍繞可擴展性、可靠性與效率三大支柱,兩款芯片共享谷歌AI軟件棧的核心基因,但各自針對不同瓶頸進行了專項優化。
兩款芯片均集成了基於Arm架構的Axion CPU,以消除數據預處理延遲造成的主機側瓶頸,確保TPU計算單元持續滿載運行。
TPU 8t:面向超大規模訓練的算力引擎
TPU 8t定位為預訓練與嵌入密集型工作負載的專用加速器,谷歌稱其能夠"將前沿模型開發周期從數月壓縮至數周"。
在規模上,TPU 8t最多可將9600塊芯片組合為單一超級計算節點(superpod),並通過JAX與Pathways框架將分佈式訓練擴展至單一集群超過100萬塊TPU芯片。
芯片層面,TPU 8t引入了三項關鍵技術創新。
其一是SparseCore加速器,專門處理嵌入查找中不規則的內存訪問模式,將數據依賴的全局聚合操作從矩陣乘法單元(MXU)中卸載,避免通用芯片常見的零操作瓶頸。
其二是原生FP4支持,通過4位浮點數將MXU吞吐量翻倍,同時降低數據搬運的能耗,使更大的模型層可駐留於本地硬件緩衝區。
其三是更均衡的向量處理單元(VPU)擴展設計,使量化、softmax等向量操作與矩陣乘法實現更好的流水線重疊,提升芯片整體利用率。
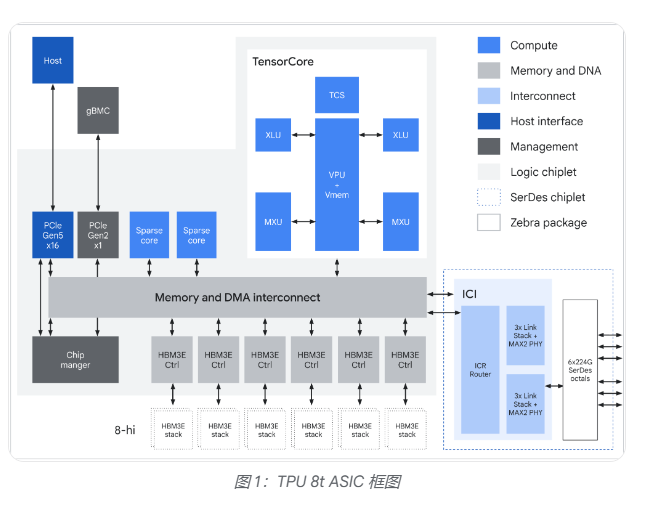
網絡層面,谷歌為TPU 8t引入了全新的Virgo網絡架構,採用高基數交換機與扁平化兩層非阻塞拓撲,將數據中心網絡(DCN)帶寬較上一代提升最高4倍,芯片間互聯(ICI)帶寬提升2倍。單一Virgo網絡可連接逾13.4萬塊TPU 8t芯片,提供高達47拍比特/秒的非阻塞雙向帶寬,整體算力超過160萬ExaFlops。
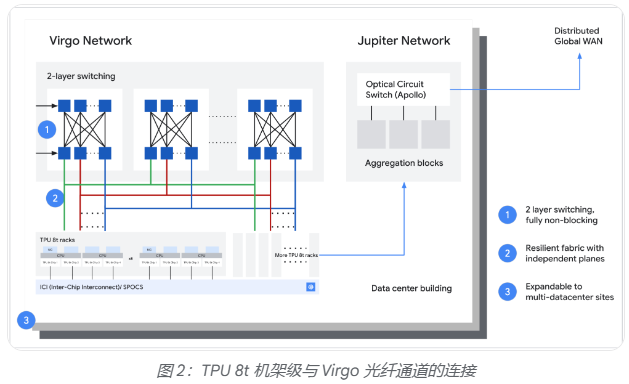
存儲方面,TPU 8t引入TPUDirect RDMA與TPUDirect Storage技術,繞過主機CPU直接在TPU高帶寬內存(HBM)與網卡、高速存儲之間傳輸數據,存儲訪問速度較第七代Ironwood TPU提升10倍,可確保MXU在處理大規模多模態數據集時保持滿載。
TPU 8i:面向高併發推理的低延遲專家
TPU 8i針對後訓練階段與高併發推理場景設計,其架構重心在於降低延遲、提升每芯片的併發處理能力。
片上存儲是TPU 8i最顯著的硬件特徵。每塊芯片集成384MB靜態隨機存取存儲器(SRAM),是上一代Ironwood的三倍,可將更大的KV Cache完整保留在芯片上,大幅減少長上下文解碼過程中核心的空閒等待時間,對需要多步驟推理的AI任務尤為關鍵。
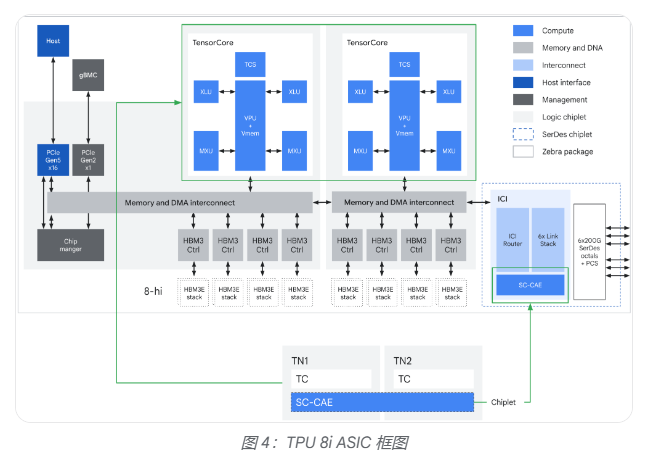
TPU 8i還引入了集合加速引擎(CAE),專門加速自迴歸解碼與"思維鏈"處理中的歸約與同步步驟。每塊TPU 8i芯片包含兩個張量核心(TC)與一個CAE芯粒,取代了上一代Ironwood中的四個SparseCore,片上集合操作延遲降低5倍,直接提升了同時運行數百萬智能體所需的吞吐量。
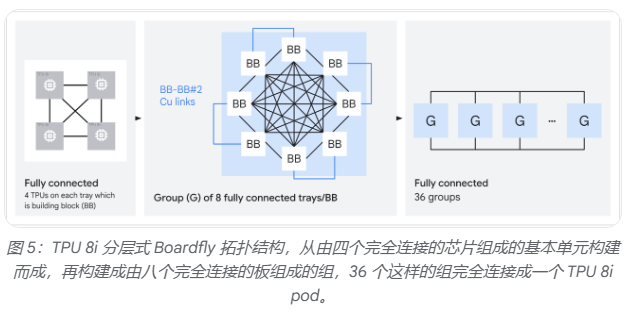
網絡拓撲方面,TPU 8i放棄了TPU 8t沿用的3D環面(torus)結構,轉而採用全新的Boardfly互聯拓撲。3D環面在1024芯片配置下,任意兩芯片間最多需要16跳;Boardfly通過高基數設計將最大跳數壓縮至7跳,網絡直徑縮減56%,全對全通信延遲改善最高50%,對混合專家模型(MoE)和推理模型中頻繁的跨芯片令牌路由尤為有利。Boardfly採用分層結構,從四芯片構建塊逐級擴展至最多1152塊芯片的完整Pod,並通過光學電路交換機(OCS)實現組間互聯。
軟件生態與市場意義
谷歌強調,硬件性能的釋放有賴於配套軟件棧的協同。
第八代TPU延續第七代Ironwood建立的軟件體系,支持JAX、PyTorch、Keras及vLLM等主流框架,並提供Pallas自定義內核語言以充分挖掘SparseCore與CAE的硬件潛力。
谷歌同時宣佈,原生PyTorch對TPU的支持現已進入預覽階段,用戶可直接將現有PyTorch模型遷移至TPU運行,無需修改代碼。
從市場角度看,谷歌此次雙芯片策略直接回應了AI基礎設施成本壓力。訓
練與推理對硬件的需求差異顯著,統一芯片意味着在某一場景下必然存在資源浪費。通過專項優化,谷歌得以在價格性能比上實現更大幅度的提升,為雲客戶提供更具競爭力的單位算力成本。
兩款芯片均已納入谷歌雲AI Hypercomputer超算架構,與硬件、軟件及網絡深度集成,覆蓋AI全生命周期工作負載。