
姚順雨首秀為何與市場預期錯位?
出品|虎嗅黃青春頻道
作者|商業消費主筆 黃青春
題圖|視覺中國
姚順雨執掌騰訊混元后的首秀,最終被 DeepSeek-V4 的討論淹沒了。
4 月 23 日,騰訊正式發布並開源混元 Hy3 preview 語言模型——這是姚順雨主導混元技術體系全面重建後,交出的首份落地成果。
在此之前,市場對姚順雨的期待值早已拉滿:清華姚班出身、OpenAI 前核心研究員、AI 領域頂尖專家,入職即獲得集團層面雙線彙報的最高權限,一手推動騰訊混元大模型研發架構重構,還打破盤桓多年的部門牆,讓成立十年的 AI Lab 打散重組。
有鑑於此,外界翹首以盼騰訊拿出一款顛覆性的新模型,但 Hy3 preview 最終的市場聲量與討論度並不及預期。這很大程度上源於,同期 GPT-5.5、小米 Mimo、Kimi K2.6 等新模型密集發布,次日 DeepSeek-V4 也強勢登場。
這讓混元有限的聲量徹底在這輪大模型更新浪潮中「失聲」,業內因此有人揶揄騰訊,「不如關停混元,高價收購 DeepSeek」。
對此,騰訊內部人士向虎嗅透露,與外界期待姚順雨「單騎救主」的英雄主義敘事不同,團隊對這一版本並未設定過高目標,因為 Hy3 preview 並非對 Hy2.0 的迭代,而是騰訊混元技術體系的一次推倒重建。
「Hy3 預覽版與 DeepSeek-V4 的核心差異在於,後者暫不考慮商業化,專注於突破技術上限;而混元從研發之初就以適配騰訊業務生態為核心,強調與場景的深度綁定。如今 AI 行業已進入下半場,模型能力、生態資源與工程化實力將形成協同效應——畢竟騰訊從來不是一家單純的模型公司。」該內部人士表示。


騰訊終究「差了一口氣」?

從官宣預熱到最終發布,Hy3 preview 的表現與市場拉滿的期待存在明顯落差。
自高調宣佈姚順雨加盟以來,騰訊便對其展現了超乎尋常的重視:一人身兼「CEO/總裁辦公室」首席 AI 科學家、AI Infra 部與大語言模型部負責人兩大職務,同時向騰訊總裁劉熾平、技術工程事業群總裁盧山雙線彙報。
這種人事安排在騰訊發展史上頗為罕見,等於從集團層面確立了大模型的戰略核心地位,也向市場傳遞出騰訊 All in AI 的決心。
3 月 18 日的財報電話會上,劉熾平的表態更將市場期待推至頂峯:他明確透露混元全新技術體系下的旗艦模型 Hy3.0 正處於內部業務測試階段,計劃於 4 月對外推出,且相較於 Hy2.0 的能力提升幅度,將超過混元歷史上任何一次版本迭代。
疊加 2026 年二季度全球大模型賽道進入新一輪密集發布期:Anthropic 發布 Claude Opus 4.7、阿里推出 Qwen3.6-Max-Preview、Kimi 開源 K2.6、小米官宣 Mimo 全系列新模型,GPT-5.5 與 DeepSeek V4 前後腳上桌——如此「神仙打架」的貼身肉搏,市場自然期待騰訊能拿出一款足以改寫國內大模型格局的旗艦產品。
然而,與拉滿的市場預期形成鮮明對比的是,Hy3 preview 雖踩點交付,但技術突破有限,在各個維度均未給市場帶來預期中的驚喜。
首先,騰訊高管承諾 4 月推出核心版本,4 月底卻只發布了 Hy3 預覽版,勉強踩中時間節點,未體現出騰訊作為行業巨頭應有的執行力與爆發力。
對此,騰訊內部人士向虎嗅表示,實際上 Hy3 預覽版是技術重建的起點,正式版及更高級別的版本還在同步研發測試中。「Hy3 基本完成了對原有技術架構的全面重構,這個版本的核心目標是驗證全新技術路線、磨合重組後的團隊並跑通完整研發流程,且僅用不到三個月就完成交付,而行業同類技術重構通常需要 6-12 個月。」
其次,在行業動輒以 1T 參數炸場的當下,Hy3 preview 總參數 295B、激活參數 21B 的規格無法給市場帶來衝擊力,被業內人士吐槽不夠頂尖、不夠震撼。
從實測與行業評測結果來看,Hy3 preview 的綜合能力雖達到國內一線水平,但極限推理能力仍遜於 GLM-5、Gemini 3.1 等頂級模型;代碼與智能體能力僅相當於 GLM-4.7——也就是智譜 AI 四個月前的技術水平,既沒有實現市場期待的代差級突破,更談不上對標全球頂級模型。
可如果拋開市場的高預期濾鏡,迴歸模型本身的技術與落地能力,Hy3 preview 已然是騰訊混元歷史上進步幅度最大、實用性最強的版本。
推理效率層面,得益於模型架構與推理框架的深度協同,Hy3 preview 整體推理效率提升 40%,首 token 延遲降低 54%,端到端時長降低 47%,成本較上一代模型大幅下降——等於說,決定用戶體驗與商業化可行性的核心指標均被大幅優化。
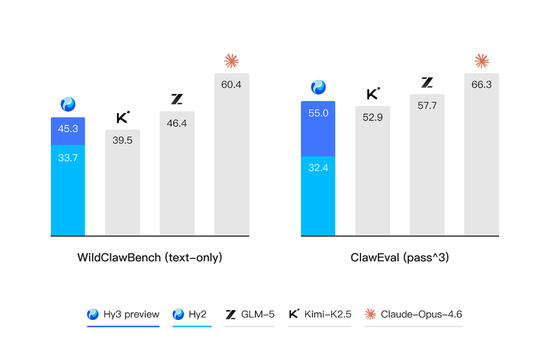
複雜推理能力層面,Hy3 preview 在 FrontierScience-Olympiad 拿下 70.0 分、IMO Answer Bench 達到 84.3 分,整體表現超過 GLM-5、Kimi-K2.5,接近 Gemini 3.1 Pro 與 GPT-5.4。
代碼與智能體能力是 Hy3 preview 提升最顯著的方向。在 SWE-Bench Verified 基準測試中達到 74.4% 的通過率,逼近 GLM-5 與 Kimi-K2.5;在 Terminal-Bench 2.0 測試中取得 54.4% 的得分,超過 GLM-4.7 等模型,擠進行業第一梯隊;在涵蓋 16 項基準的 Agent 綜合評測中,平均得分從 Hy2 的 35 分躍升至 56 分,接近 GLM-5 與 Kimi-K2.5 所在的旗艦區間。
這些能力躍升背後,是 Hy3 preview 從研發之初就確立了與產品深度協同設計(Co-Design)的研發路線。
虎嗅獲悉,Hy3 preview 發布之時,已率先接入騰訊雲、元寶、IMA、CodeBuddy、WorkBuddy、QQ 等十餘條核心產品線,且在每一個落地場景中都拿到了可量化的業務成果。
在辦公場景,騰訊文檔 AI PPT 功能接入後,生成成功率提升 20%,評測得分提升 10%,生成耗時縮短 20%,在模板選擇、內容生成、視覺匹配等環節幻覺顯著減少,契合度大幅提升;WorkBuddy 產品接入後,與國內同尺寸模型的用戶盲評勝率達到 56%,能穩定覆蓋文檔處理、數據分析、知識檢索、工具鏈編排等複雜辦公場景。
在社交與內容場景,元寶 APP 已與模型完成深度協同優化,提升了意圖理解、文本創作、深度搜索的核心能力,能為用戶帶來更具「活人感」的交互體驗;公衆號 AI 分身場景中,模型在用戶意圖理解、複雜上下文承接、知識信息組織方面的能力顯著提升。
在遊戲場景,《和平精英》已全面接入 AI NPC 玩法,局外人設扮演場景中,模型能精準理解角色設定,輸出高關聯、高增量的交互內容;局內複雜對戰場景中,回覆節奏貼近真實玩家,展現了極強的穩定性與擬人化能力,累計體驗用戶已突破 1.1 億。
除此之外,QQ 瀏覽器、騰訊新聞、騰訊客服等數十款騰訊核心產品,均在接入過程中,Hy3 preview 已真正融入騰訊業務生態,而非一款孤立的實驗室模型。


務實主義的路線錯位?

「Hy3 preview 是混元大模型重建的第一步。」在 Hy3 preview 發布的官方推文中,姚順雨如是寫道。
即便首秀沒能刷出與騰訊影響力匹配的聲量,並不意味着 Hy3 preview 是一款失敗的模型。虎嗅認為,某種程度上,姚順雨為混元制定的核心路線,與當下行業的狂歡邏輯、市場的期待方向,存在明顯的偏移與錯位。
騰訊混元團隊向虎嗅表示,外界多是圍觀視角,難以體會此次技術重建之難——不僅要搭建全新的基礎設施,還要更換整套訓練範式,幾乎等同於從零開始重做一個大模型。
「比如數據審核就是姚順雨親自抓的,在三個多月內主導完成了對過往繁雜、冗餘 SFT 數據的全面去重與精細化管控。目前,模型效果已經取得階段性進步,但仍存在一些已知問題,比如工具調用中的錯誤恢復能力不足,以及對推理超參數較為敏感。希望通過這次開源和發布,獲得來自開源社區和用戶的真實反饋,助力 Hy3 正式版進一步提升實用性。」上述人士說道。
事實上,姚順雨入職騰訊後,對混元團隊推行的第一項核心變革,就是否定「唯排行榜論」的研發邏輯。他在內部會議上指出,過去混元模型過度追逐排行榜成績,甚至直接將打榜專用語料混入訓練集,導致數據被嚴重污染,影響模型在真實場景中的表現。有鑑於此,姚順雨為團隊劃出一條清晰的路徑:不迷信打榜,更不用盯着排行榜做事。
虎嗅獨家獲悉,今年 2 月,姚順雨主導重建了預訓練和強化學習的基礎設施,並確立了模型研發追求實用性的三大核心原則:
-
能力體系化:不推崇偏科,即便是代碼智能體這類單一應用場景,也涉及推理、長文、指令、對話、代碼、工具等多種能力的深度協同。
-
評測真實性:主動跳出易被刷榜的公開排行榜,通過自建題目、最新考試、人工評測、產品衆測等方式評估和改進模型的真實戰鬥力。
-
性價比追求:實用性離不開商業合理性,通過深度協同模型架構與推理框架設計,大幅降低任務成本,讓智能用得起、用得好。
與此同時,混元團隊在繼續擴大預訓練和強化學習的規模,提升模型的智能上限,並通過與騰訊更多產品場景的深入協同設計,進一步探索基於產品場景的特色能力。
基於這一理念,Hy3 preview 跳出行業通用的公開評測體系,騰訊混元團隊自建了 50 餘個基準測試集,通過自建題目、最新考試、人工評測、產品衆測等多種方式,綜合評估模型的真實戰鬥力。
據虎嗅了解,騰訊專門打造了 CL-bench、CL-bench-Life、Hy-Backend、Hy-SWE Max 等一系列貼合真實業務場景的評測體系,核心目標只有一個:驗證模型在真實場景中的可用性,而非實驗室裏的紙面跑分。
要知道,當下大模型賽道,公開排行榜的分數是最直觀、最易傳播的能力證明,更是模型出圈、獲得市場認可的保證——如果不打榜、不拿出碾壓同行的排行榜數據,市場就會默認你不具備對應的能力,普通用戶更不會感知到你的技術進步。
拿 Hy3 preview 受爭議的 295B 參數規格來說,這恰恰是姚順雨「實用優先、放棄炸場」路線的體現。在行業普遍通過「堆參數、規模擴容(Scale Up)」實現能力提升的當下,姚順雨選擇反其道而行之:Hy3 preview 總參數甚至小於前一版本,核心資源並未投入到參數規模擴張上,而聚焦於數據質量的提升,近乎完成了對 Hy2 模型底座的重構。
這一反行業常規的演進路線,源於騰訊混元對技術實用性的判斷:
-
能力邊界:複雜推理、長上下文理解、指令遵循等核心實用能力,在 300B 參數量級已能充分釋放,盲目擴大參數帶來的能力邊際收益已大幅遞減。
-
成本控制:300B 級混合專家模型(MoE)經量化後可實現單機部署,而 1T 級模型必須跨節點運行,多機通信會導致延遲、吞吐和運維複雜度顯著上升,推理成本更是相差數倍。
-
落地可行性:絕大多數商業場景可通過檢索增強生成(RAG)、智能體(Agent)等工程手段彌補與頂級模型的能力差距,而 300B 級模型的低推理成本和低微調門檻,讓私有化部署與行業定製化成為可能。
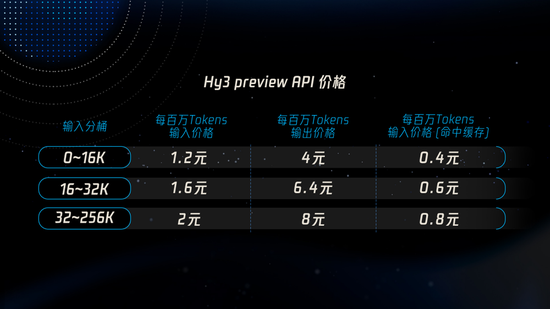
順着上述判斷,Hy3 preview 要將價格打下來:騰訊雲公開的 API 定價,在 0-16K 上下文範圍內,輸入最低 1.2 元 / 百萬 tokens,命中緩存後低至 0.4 元 / 百萬 tokens,輸出最低 4 元 / 百萬 tokens;與此同時,推出的個人版套餐最低 28 元 / 月,在同級別旗艦開源 MoE 模型賽道中,處於最低價梯隊。
然而,市場期待的是騰訊向上突破、拿出一款「碾壓同行、對標 GPT」的頂級旗艦,期待看到巨頭拿出炸場的參數、震撼的行業跑分,而非精打細算的性價比、面向落地的工程化產品。
這種市場期待與騰訊實際戰略選擇之間的錯位,正是市場產生心理落差的核心原因。

當然,騰訊在 AI 賽道最大的底牌是其無可替代的生態體系與工程化能力,這也是市場始終對騰訊混元抱有逆襲期待的核心原因。
在生態層面,騰訊「兩肋生風」:手握微信 14.18 億月活的國民級流量入口,還有 QQ、遊戲、辦公、內容、金融等全場景應用矩陣,是國內擁有最多真實應用場景的互聯網巨頭——而真實場景的用戶反饋、海量的業務數據,是模型迭代最核心的「燃料」。
在商業化層面,AI 正扛着騰訊業務跑:
-
2025 年騰訊廣告收入按年增長 19% 至 1449.73 億元,核心驅動力就是 AI 改寫了廣告業務的底層邏輯;
-
遊戲業務收入按年增長 22% 達 2416 億元,超 40 款騰訊遊戲落地 AI 應用,覆蓋研發、玩法、運營全鏈路,人效與收入均實現大幅提升;
-
騰訊雲更是首次實現規模化盈利,大模型相關產品收入近兩年增長 50 倍。
從最終結果來看,姚順雨僅用三個月時間完成技術重建,並實現全業務場景快速落地,讓此前掉隊的騰訊混元重新躋身國內大模型第一梯隊。他為騰訊混元制定的「不偏科、不刷榜、重性價比、深度貼合業務場景」研發路線,正契合 AI 行業從參數狂歡向落地實用迴歸的長期大趨勢。
正如姚順雨年初回應虎嗅的那樣,大模型上半場競爭的核心是模型訓練與參數突破,下半場的競爭重心將轉向任務定義、系統構建與真實問題解決能力——從這個角度看,騰訊的生態優勢、工程化能力、商業化體系,在 AI 下半場擁有巨大的想象空間。