
作者 | 陳駿達
編輯 | 雲鵬
智東西4月30日報道,今天,智譜發布了一篇名為《Scaling Pain:超大規模Coding Agent推理實踐》的技術報告,披露了GLM-5系列模型在Coding Agent場景下遇到的推理基礎設施挑戰與對應解法。
報告透露,在每日數億次Coding Agent調用壓力下,部分用戶遭遇了GLM-5系列模型亂碼、復讀和生僻字等異常,這些現象在表面上與長上下文場景下常見的「降智」相似,但智譜並未進行降低模型精度的優化,相關問題主要由高併發、長上下文的極端條件觸發。
通過數周排查,智譜鎖定了兩個底層競態問題:PD分離架構下的KV Cache異步Abort引發顯存寫入衝突,以及HiCache加載流水線缺少同步約束導致「數據未就緒即被讀取」。針對性修復後,相關異常發生率從約萬分之十幾降至萬分之三以下。
報告還公開了智譜自研的KV Cache分層存儲方案LayerSplit,在Context Parallel場景下將單卡KV Cache顯存壓力大幅降低,實測系統吞吐提升10%至132%,且上下文越長收益越大。
一、本地無法復現,高壓才露頭:投機採樣指標成「照妖鏡」
從今年3月起,智譜GLM-5出現了三類異常:亂碼、復讀、生僻字。排查初期,智譜對線上異常案例做了本地回放,但未能復現,說明大概率不是模型問題。進一步模擬線上高壓環境後,在每萬次請求中穩定復現3-5次異常。這種「與內容無關、與壓力相關的特徵」,將問題指向高負載下的推理狀態管理。
三類異常中,復讀較易檢測,亂碼和生僻字則難以用正則或模型判別高效覆蓋。分析推理日誌後,智譜發現投機採樣指標可作為重要參考:
投機採樣本為性能優化而設計:草稿模型生成draft token,目標模型校驗後決定是否接受,並記錄spec_accept_length與spec_accept_rate,從而在不改變最終輸出分佈的前提下提升解碼效率。
針對亂碼/生僻字問題,智譜發現spec_accept_length極低,draft token幾乎全被拒絕,表明KV Cache狀態存在顯著偏差。
針對復讀問題,智譜發現spec_accept_rate偏高,損壞的KV Cache使注意力退化,陷入重複循環。
據此,智譜團隊建立了在線監控策略。將投機採樣從一項單純的性能優化技術,拓展為質量監控信號。
二、鎖定時序漏洞,兩個競態Bug如何導致輸出異常
定位問題後,智譜進一步分析其原因。通過對請求生命周期以及推理引擎中PD分離執行時序的分析,智譜發現該問題源於請求生命周期與KV Cache回收與複用時序之間的不一致,從而引發的KV Cache複用衝突。
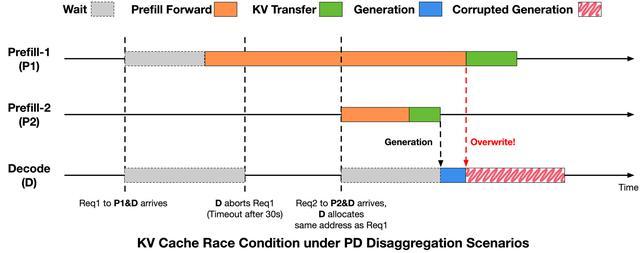
為消除上述問題,智譜在推理引擎中引入了更嚴格的時序約束,在請求終止與KV Cache寫入完成之間建立顯式同步關係。
這一問題的具體修復方案是在Decode觸發Abort後通知Prefill側,僅在RDMA未開始或已完成時才允許回收複用,確保KV寫入不跨越顯存複用邊界。修復後,異常發生率從萬分之十幾降至萬分之三以下。
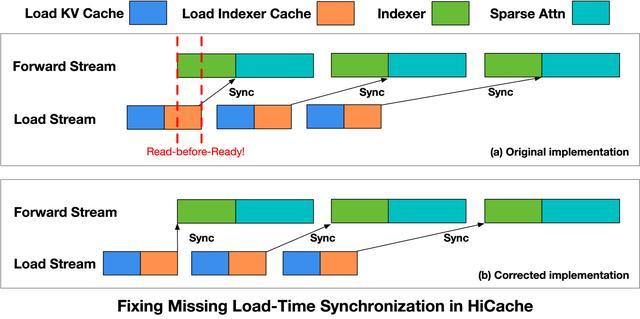
智譜面臨的第二個bug與Coding Agent場景的特性有關。Coding Agent場景輸入長、前綴複用率高,HiCache成為關鍵優化。但KV Cache換入與計算重疊執行時,未保證數據加載完成後再使用。
為修復這一問題,智譜在Indexer算子啓動前引入同步點,確保數據就緒後才啓動計算。修復後,相關問題完全消失,相關修復已提交至SGLang社區。
三、Prefill吞吐成瓶頸,LayerSplit讓吞吐最高漲132%
上述兩個問題揭示了一個共同的系統瓶頸:在長上下文的Coding Agent服務場景中,Prefill階段主導了系統性能。修復狀態一致性問題後,核心挑戰迴歸瓶頸本身,也就是如何提升Prefill吞吐、降低KV Cache顯存佔用。為此,智譜團隊設計並實現了KV Cache分層存儲方案LayerSplit。
Coding Agent負載具有上下文長、Prefix Cache命中率高的特徵,使得Context Parallel(CP,上下文並行)成為Prefill節點的主要並行策略。然而,SGLang開源實現中每張GPU保存全部層的KV Cache,冗餘存儲導致顯存容量成為計算資源利用率的瓶頸。
LayerSplit方案的核心思路是:每張GPU僅持有部分層的KV Cache,從而顯著降低單卡顯存佔用。計算時,持有某一層Cache的CP rank會在Attention計算前將其廣播給其他rank。
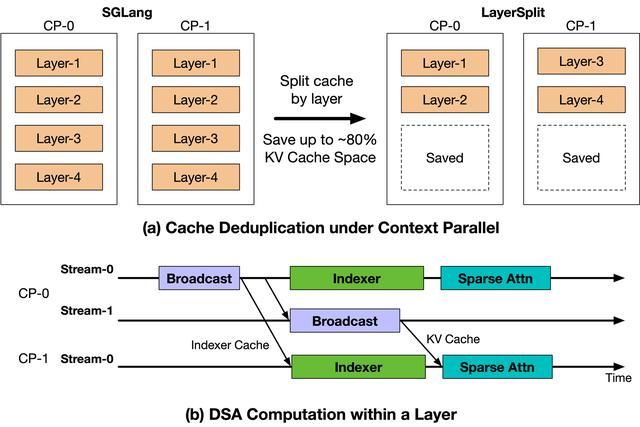
為進一步減少開銷,智譜設計了KV Cache廣播與Indexer計算的重疊機制,使二者在時間上相互掩蓋。整個流程僅額外引入約為KV Cache體量1/8的Indexer Cache廣播,通信成本對性能影響可忽略。
實驗結果表明,在Cache命中率90%的條件下,請求長度從40k到120k區間內,系統吞吐量提升幅度在10%至132%之間,且上下文越長收益越顯著。
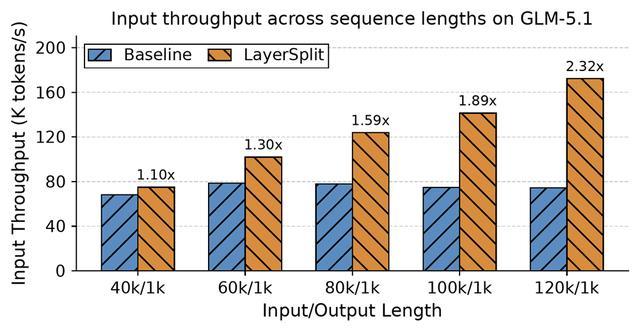
該優化從架構層面緩解了Prefill側的顯存瓶頸,與此前兩項BugFix共同構成了一套完整的推理基礎設施優化方案,提升了智譜GLM-5在Coding Agent場景下的服務能力。
結語:輸出質量成高併發長上下文場景新痛點
高併發長上下文場景下,推理基礎設施的挑戰已不止於吞吐和延遲,輸出質量同樣不可忽視。智譜此次公開的技術細節,從異常識別方法、兩個競態Bug的定位與修復,到LayerSplit顯存優化,構成了一套相對完整的排查與優化鏈路。
對於同樣在大規模部署推理服務的團隊而言,這份報告在故障復現、指標選型、架構層面的時序一致性等方面提供了可參考的實踐經驗。智譜將這些經驗公開分享,客觀上為社區填補了部分長上下文推理場景下的工程資料空白。