
2026年4月24日,備受期待的DeepSeek-V4終於發布了。
沒有特別盛大的發布會,沒有幾個人出來直播,沒有倒計時預熱,也沒有大規模媒體採訪。
用戶群發個通知,官網更新,App上線,API同步更新,開源模型掛到HuggingFace上。

整個AI圈隨後開始刷屏,大家都在講這件事。
模型參數是多少,API價格是多少,跑分怎麼樣,上下文長度是多少;
到底有沒有適配國產卡,和GPT、Claude、Gemini比到底是什麼水平。
這些信息當然都重要。
但我沒有第一時間寫。
不是因為這件事不重要。
恰恰相反,是因為我覺得它太重要了。
如果只是跟着寫一篇「DeepSeek-V4發布了,參數如下,價格如下,跑分如下」的文章,當然也能講清楚一部分事實,但我覺得這會把這件事寫小。
參數只能解釋DeepSeek這次發了什麼,但它解釋不了這件事到底意味着什麼。
因為當天有一位記者朋友給我打電話,問我怎麼看DeepSeek-V4。
我們聊了一會兒。
聊完之後,我更確定,這篇文章應該寫,但不能寫成一篇快訊。
因為DeepSeek-V4真正值得看的,不是它某一項跑分贏了誰,也不是它終於支持了100萬Token上下文,而是它把幾個更大的問題同時放到了台面上:
強模型能不能更便宜?
開源模型還能不能追上閉源模型?
國產算力能不能承接前沿模型?
普通人未來能不能用得起強AI?
以及,如果未來每個人每天都要和模型打交道,我們有沒有機會不被少數閉源巨頭完全卡住入口?
今天,我想用普通人能理解的方式,講講DeepSeek-V4對我們這些普通人來說意味着什麼?
PART.01
這次到底發了什麼?
DeepSeek-V4這次不是只發了一個模型,而是同時放出了DeepSeek-V4-Pro和DeepSeek-V4-Flash。
Pro是旗艦模型,1.6T總參數,49B激活參數。
Flash更輕,284B總參數,13B激活參數。
兩個模型都支持100萬Token上下文。

如果只看這些數字,很容易把它理解成一次常規升級:
參數更大,上下文更長,能力更強。
但這裏真正值得看的,不只是參數本身,而是DeepSeek為什麼要同時做Pro和Flash。
Pro很明顯是用來打高難任務的。
複雜推理、代碼、Agent、長上下文分析,這些任務需要更強的模型能力,也能接受更高的調用成本。
Flash則更像日常入口。
它沒有Pro那麼重,但價格低很多,更適合高頻使用。
普通問答、基礎推理、日常辦公、產品裏的大規模調用,都更適合交給Flash。
這和過去很多人理解的大模型不太一樣。
以前大家總習慣問:哪個模型最強?
但真正進入應用之後,問題會變成:什麼任務該用什麼模型?
不是所有場景都需要最貴的模型。
就像不是所有出行都需要坐頭等艙,也不是所有文件都需要請最強律師看。
很多日常任務需要的是夠好、夠快、夠便宜;
少數高難任務,才需要調用最強能力。
所以DeepSeek-V4這次真正有意思的地方,不是單純做了一個更強的Pro,而是同時給出了一個更便宜的Flash。
Pro負責攻堅,Flash負責鋪開。
一個解決上限,一個解決普及。
如果未來強AI要真正進入普通人的軟件、工作流和日常生活,它就不能只有一個最強模型。
它必須有便宜入口,也必須有高端能力。
DeepSeek-V4這次的Pro和Flash,正是在往這個方向走。
這件事比跑分刷到了多高更重要。
PART.02
V4很強,但不是神話
當然DeepSeek-V4確實很強。
官方技術報告裏,它直接拿自己和ClaudeOpus4.6、GPT5.4、Gemini3.1Pro這些最頂尖閉源模型的高階版本做對比。
作為一箇中國開源模型,敢把對手放到這個級別,本身就很說明問題。
從報告裏的結果看,DeepSeek-V4-Pro-Max在知識、推理、代碼、Agent和長上下文任務裏都已經進入非常靠前的位置。
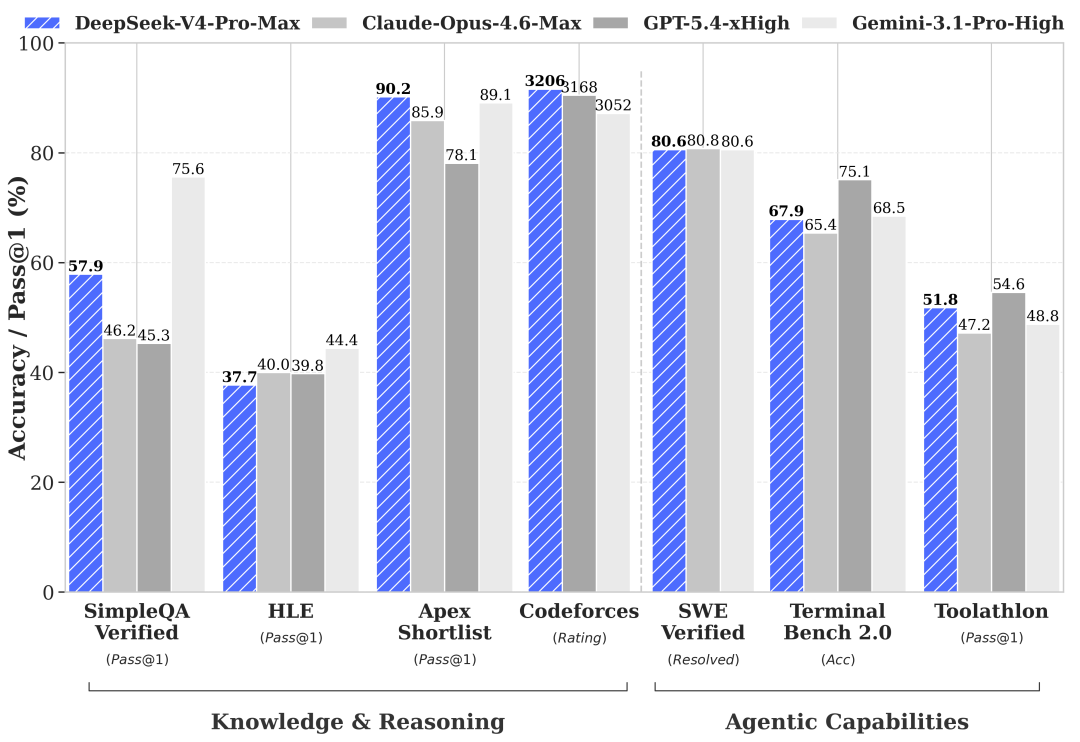
尤其是代碼、推理、長上下文和Agent相關場景,是它這次最值得關注的部分。
但它不是神話。
這個也要說清楚。
DeepSeek官方報告寫得也比較剋制。
在一些知識任務上,它仍然落後最頂級的閉源模型。

在推理任務上,它仍然略低於GPT5.4和Gemini3.1Pro,大概落後當前最前沿模型3到6個月;
在Agent任務上,它和KimiK2.6、GLM5.1這些開源模型大體處在一個梯隊,但還是略弱於最頂級閉源模型。
我這幾天也進行了實際測試和看了一些朋友反饋。
我的感受是,有些任務表現很好,尤其是長上下文、代碼、推理和Agent相關任務。
但在一些實際使用裏,它也確實沒有外界期待中那麼誇張。
這很正常。
DeepSeek-V4被期待得太久了。
過去半年,關於它跳票、關於DeepSeek是不是被超越了、關於梁文鋒到底在幹什麼的討論,已經來來回回跑了好幾輪。
期待一旦被拉得太滿,任何模型發出來都會被放在顯微鏡下看。
所以我不想把DeepSeek-V4寫成一次完美發布。
它不是完美發布。
但它依然非常重要。
它重要的地方,不是它已經打穿所有閉源模型,而是它證明了一件事:
開源模型仍然可以進入全球最前沿模型的牌桌,而且不是靠情緒、靠期待,是靠真實能力、工程效率和成本結構。
這已經很難了。
PART.03
技術報告裏,真正有意思的幾個點
很多人看到DeepSeek-V4,第一反應會是100萬token上下文。
這個當然是亮點,但我反而覺得,它不是這次最核心的意義。
因為1M上下文並不是第一次在開源模型裏出現,單純把上下文拉長,也不等於真正解決了真實場景面臨的問題。
真正值得看的,是DeepSeek-V4為了讓長上下文、深度推理和Agent任務跑起來,在底層做了哪些工程選擇。
這次技術報告裏有很多名詞。
普通人不需要全都理解,真正值得記住的,大概有四個:
CSA/HCA、KVcache、FP4和Muon。
我們一個一個來理解:
第一個是CSA/HCA,也就是新的混合注意力機制。
CSA/HCA做的事情,可以簡單理解成:
模型不再每次都把整座圖書館搬進腦子裏,而是先把內容壓縮、索引、篩選,再決定當前最需要看哪一部分。
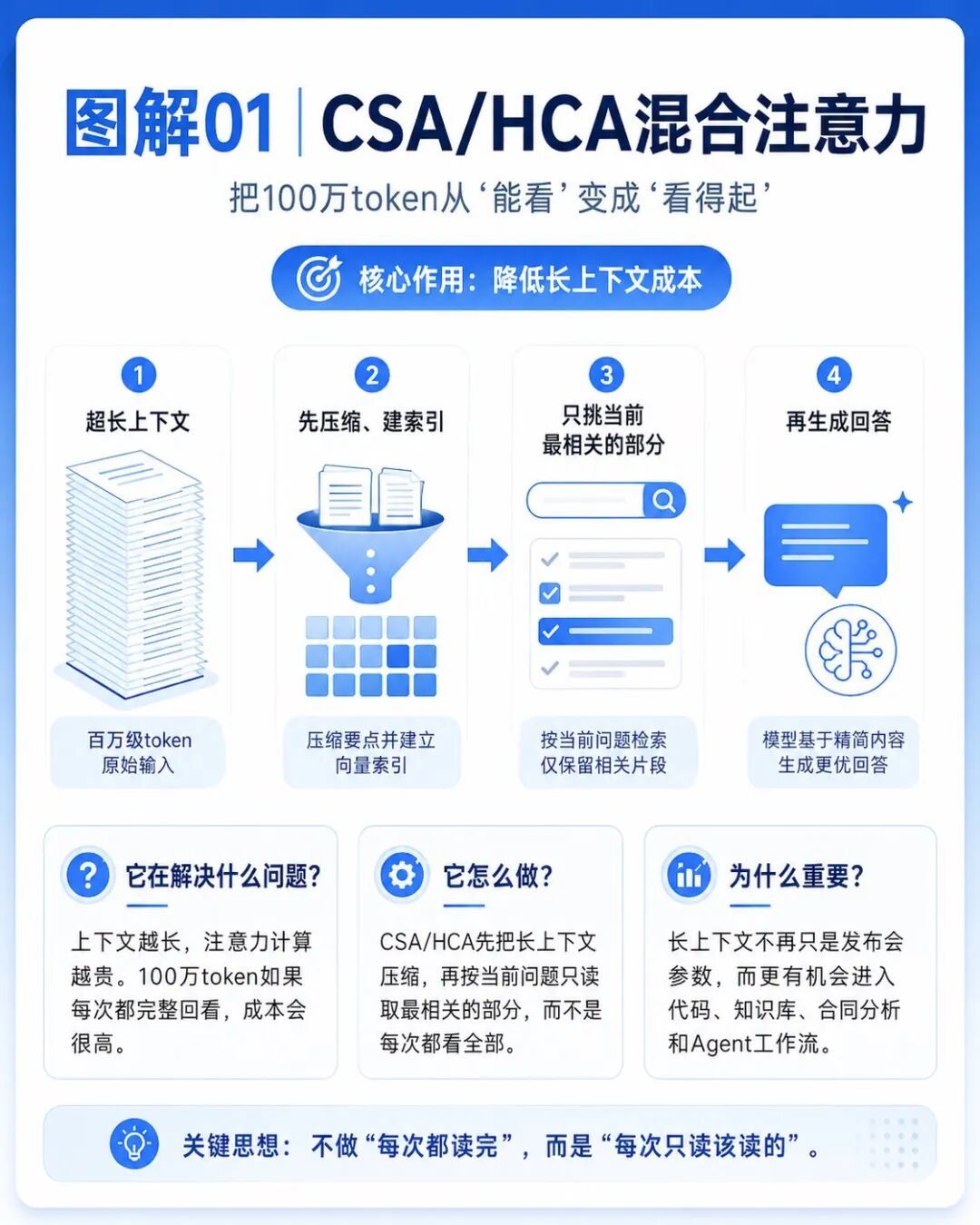
這套機制解決的是長上下文成本問題。
模型處理幾十萬、上百萬Token時,如果每次都完整回頭看一遍,成本會非常高。
所以它不是為了炫耀100萬Token上下文,而是為了讓長上下文真的用得起。
第二個是KVcache。
KVcache可以理解成模型的上下文緩存。
模型處理過一段內容之後,可以把一部分中間結果緩存下來,後面繼續使用時,不必每次都從頭計算。
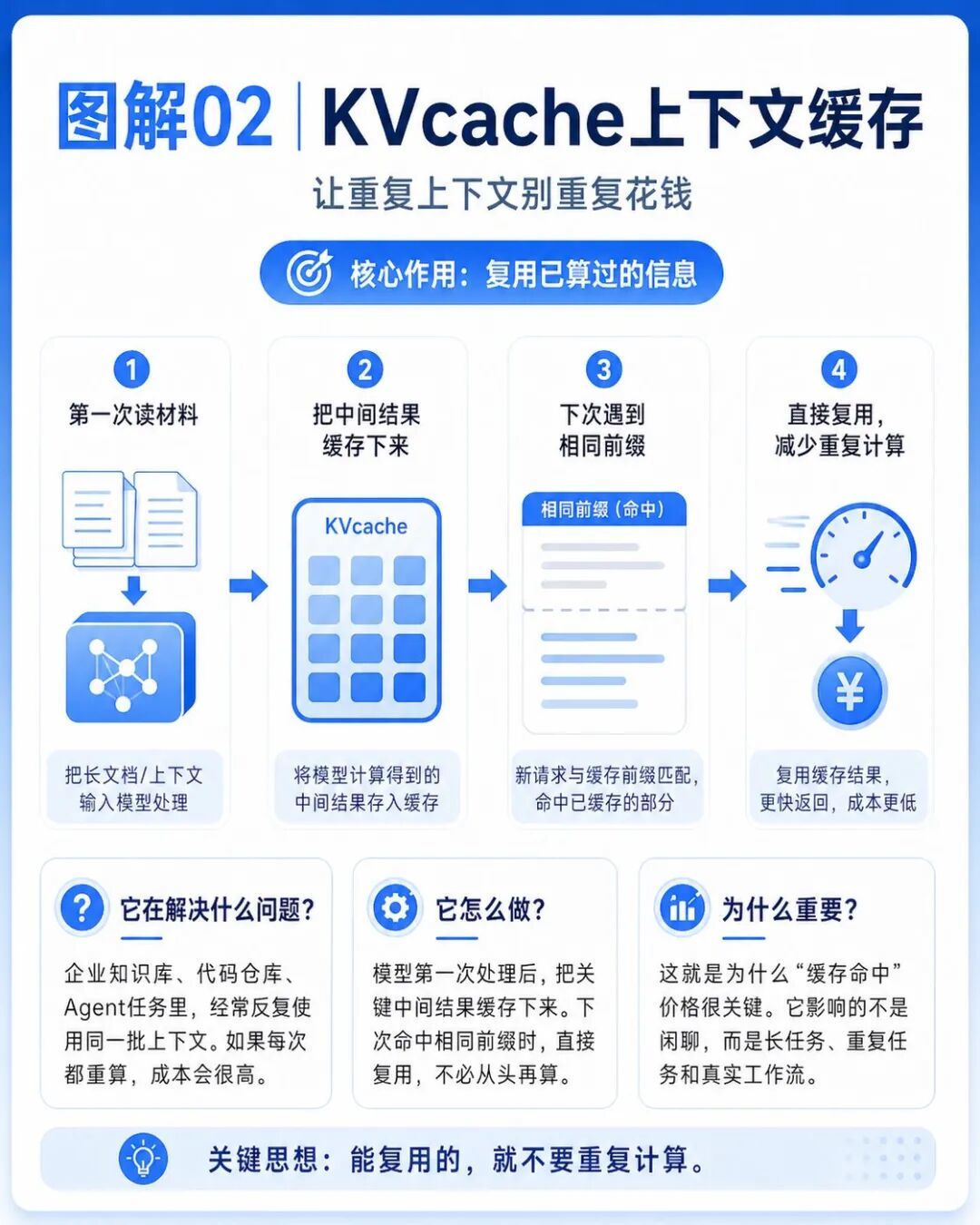
這對真實應用非常重要。
它降的不是閒聊成本,而是長任務、重複任務和真實工作流的成本。
第三個是FP4。
FP4是一種更低精度的計算和存儲方式。
普通人可以理解成:在不明顯損失能力的前提下,用更省空間、更省算力的方式表示模型裏的部分數字。
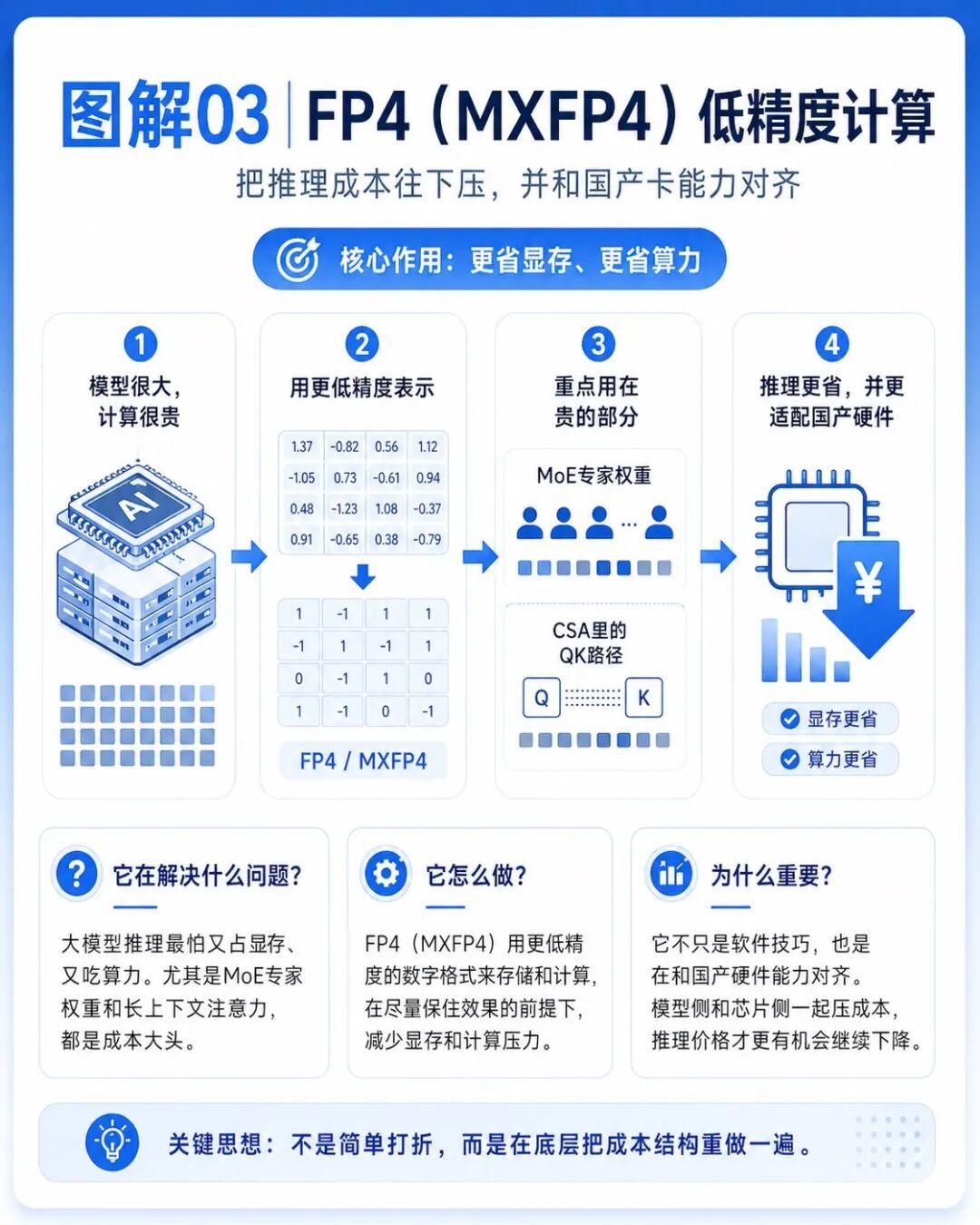
這個點看起來很小,但其實很重要。
DeepSeek-V4技術報告裏寫到的是FP4(MXFP4)量化,它不是孤立的軟件技巧。
升騰950PR這一代國產推理卡,也開始明確支持FP4/MXFP4這類低精度格式。
這意味着DeepSeek-V4的模型設計,和國產算力的硬件能力是原始適配的。
模型側把計算壓到FP4,硬件側開始支持FP4,二者合在一起,纔有可能讓未來推理價格繼續往下走。
第四個是Muon。
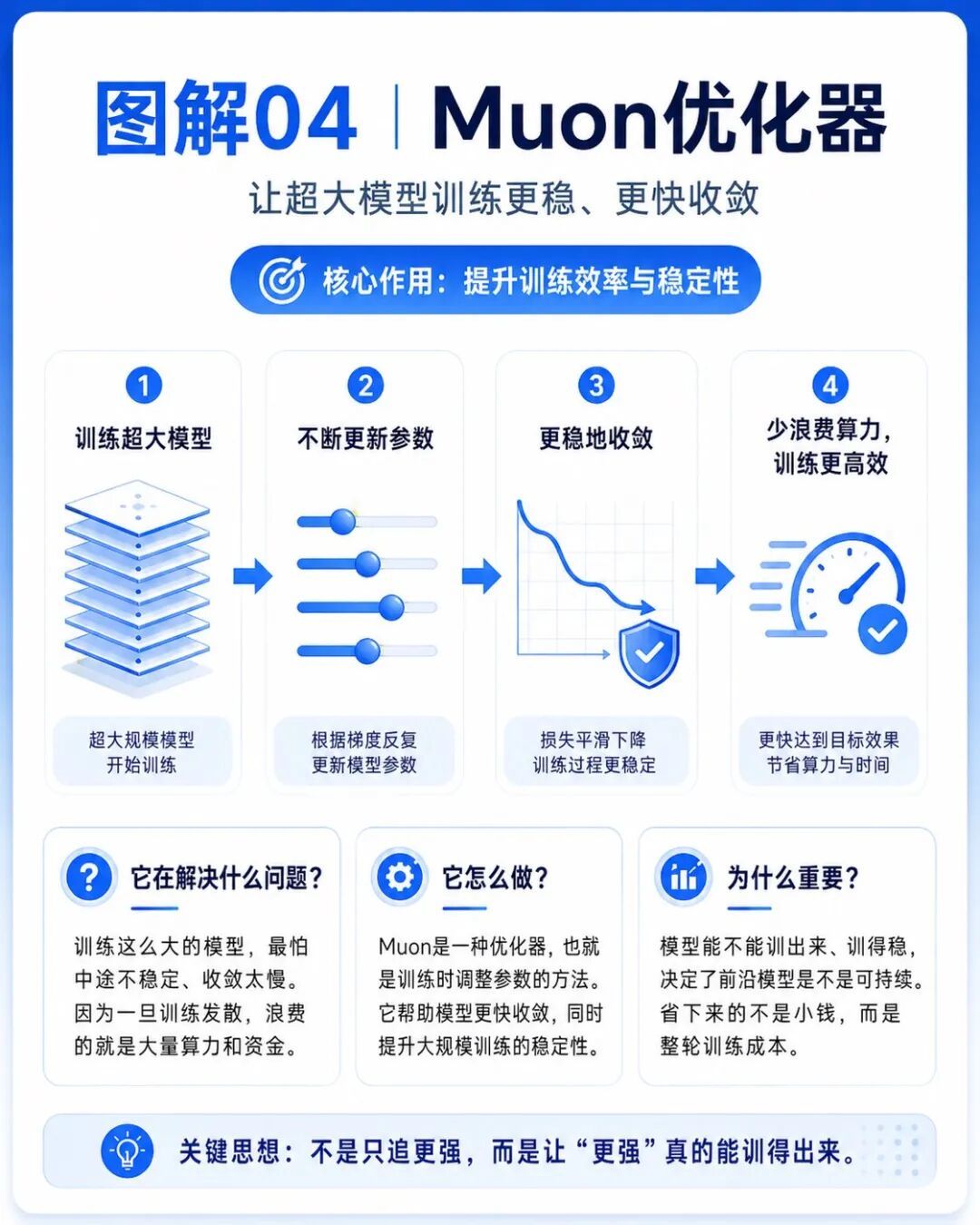
Muon是這次引入的優化器,它來自於另一個國產大模型公司月之暗面開源的項目。
它可以理解成訓練模型時用來調整參數的方法。
訓練這麼大的模型,最怕的不是慢,而是不穩定。
因為一旦訓練中途不穩定,浪費的不是一點時間,而是大量算力和資金。
Muon的意義,就是讓模型訓練更快收斂、更穩定,減少大規模訓練裏的浪費。
PART.04
不只在論文裏省成本
技術報告裏講的是模型怎麼做,價格表裏看到的是這些選擇有沒有真的落到外面。
DeepSeek-V4剛發布時,很多人看到V4-Pro的價格,會覺得它並不便宜。
這個判斷沒錯。
Pro本來就是旗艦模型,不是給所有普通任務隨便調用的低價版本。
最早的官方圖裏,Pro緩存命中輸入是1元/百萬token,緩存未命中輸入是12元/百萬token,輸出是24元/百萬token。
這個價格並不低。
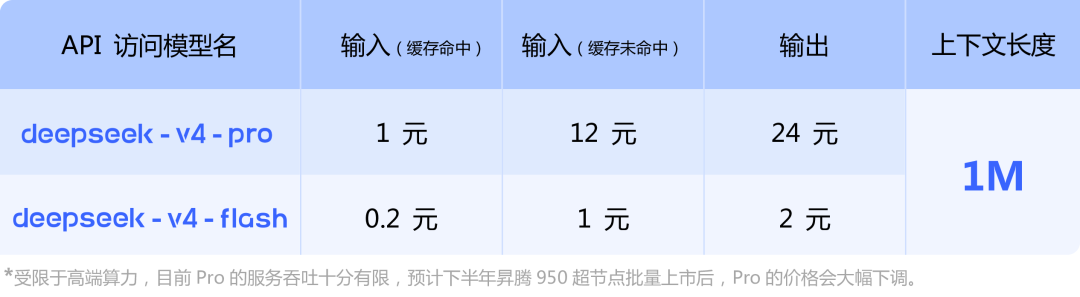
真正便宜的是Flash。
Flash緩存命中輸入是0.2元/百萬token,緩存未命中輸入是1元/百萬token,輸出是2元/百萬token。
所以不能說DeepSeek-V4一發布就把最高端能力打成白菜價。
Pro依然是旗艦模型,真正承擔普惠入口的,是Flash。
但過去幾天,DeepSeek很快又調整了價格。
現在官網顯示,V4-Pro目前開啓了2.5折優惠。
緩存命中輸入是0.025元/百萬token,緩存未命中輸入是3元/百萬token,輸出是6元/百萬token。
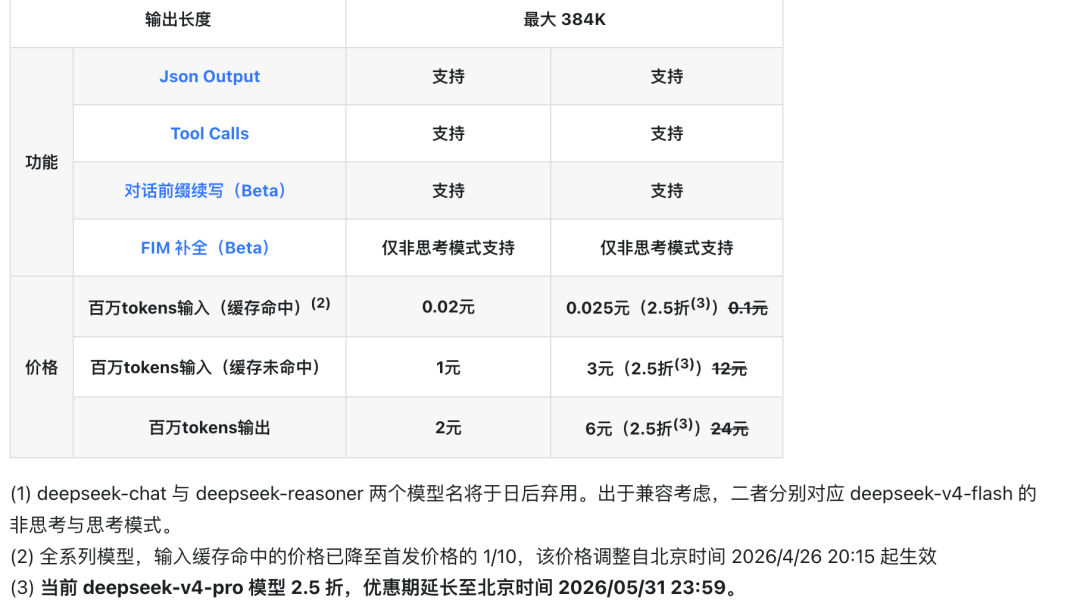
這個2.5折優惠期持續到北京時間2026年5月31日23:59。
但這些數字裏,最值得看的不是Pro或者Flash的價格,而是緩存命中輸入價格。
全系列模型的輸入緩存命中價格,已經降到首發價格的1/10。
這個調整從北京時間2026年4月26日20:15起生效,目前官網沒有寫明確結束時間。
這不是普通打折。
普通打折解決的是「這幾天便宜一點」。
緩存命中降價解決的是「真實工作流能不能長期跑起來」。
因為真正的AI應用,大部分都不是一次性問答。
企業知識庫、代碼倉庫、多文檔分析、Agent工作流,都會反覆使用相同的上下文,反覆讀取同一批材料,反覆在同一個任務空間裏推理。
這些場景最喫緩存。
緩存越便宜,長任務越便宜。
長任務越便宜,AI才越有機會從演示Demo變成日常工作的一部分。
PART.05
便宜模型不應該等於低端模型
為什麼這件事對普通人重要?
因為強模型真正進入日常,靠的不是一次演示有多驚豔,而是普通人和開發者敢不敢高頻使用。
前段時間那波「龍蝦熱」,其實已經把這個問題暴露得很清楚。
很多人跟風把國際頂尖模型接進自己的OpenClaw,一開始都很興奮,效果確實好,能力也確實強。
但很快大家就發現另一個問題:賬單太貴了。

前面我們也講過了,一個Agent任務跑起來,不是簡單問一句答一句。
如果緩存沒有命中,或者每一步都要重新計算,token消耗會非常快。
所以強模型落地時最現實的問題,不是它能不能回答得更好,而是你敢不敢讓它一直跑。
如果每一次調用都要心裏算賬,如果一個工作流跑幾輪就開始擔心費用,如果開發者把模型接進產品後發現用戶多用幾次就虧錢,那這個模型再強,也很難成為日常工具。
這也是為什麼「便宜模型」不能被輕視。
但便宜不應該等於低端。
在AI時代,便宜意味着更多人能用,更多開發者能接,更多中小公司能試,更多普通場景能跑起來。
未來模型很可能會像搜索、地圖、手機、水電一樣,成為每天都要接觸的基礎能力。
如果真是這樣,模型價格就不只是商業定價問題,而是智能使用權的問題。
誰能長期、穩定、低成本地接入強模型,誰就會有更好的學習、工作、創作和組織能力。
誰只能用弱模型、限額模型、廣告版模型,或者每次使用都要擔心賬單,就會天然處在另一個位置。
所以便宜模型不應該是低端模型的代名詞。
它是普通人進入AI時代的入口。
PART.06
開源的最終是議價權
但問題在於,便宜不能只靠某個模型的一次打折,也不能只靠某家公司短期補貼。
如果未來強AI真的變成基礎設施,那麼它的價格能不能長期下降,普通人和開發者有沒有選擇,最終取決於市場裏有沒有足夠多的競爭者。
這就是開源模型、開放權重、本地部署和低價API的重要性。
它們不是技術愛好者的玩具,也不是理想主義裝飾,而是一種現實的議價權。
如果世界上只有少數閉源模型最強,大家當然也可以用。
你可以調用API,可以付訂閱費,可以把它接進自己的產品裏。
但這種使用是被動的。
你可以調用,但不能擁有。
你可以付費,但不能決定價格。
你可以接入,但需要接受對方的商業策略、政策邊界、供應限制和生態規則。

閉源模型當然有它的價值。
OpenAI、Anthropic、Google這些公司會繼續把模型能力往上推,很多最前沿的能力也確實會先出現在閉源系統裏。
這不是問題。
真正的問題是,如果未來AI世界只剩下這些閉源入口。
強智能就會變成少數公司定義價格、規則和能力邊界的基礎設施。
而一旦它變成基礎工具,誰來定價、誰來提供、誰能部署、誰能修改,就不再只是商業問題。
這也是中國這一批開源模型公司的意義。
DeepSeek、Qwen、Kimi、GLM這些模型,不一定每一項都比最強閉源模型更強。
事實上,在很多最前沿任務上,閉源模型仍然領先。
但它們提供了另一條路線:更開放、更低價、更可部署,也更適合形成競爭。
過去在搜索、操作系統、移動生態裏,人類已經經歷過很多次類似的事情。
一個入口一旦被少數公司控制,後來者就只能在它們的規則裏做生意。
這通常會帶來壟斷和剝削。
AI不應該再簡單重複這條路。
所以開源不是情懷,低價也不是慈善。
它們的意義,是不斷把強AI從少數人的高級服務裏釋放出來,讓更多人真的用得起、用得上、用得久。
這纔是DeepSeek-V4更大的意義之一。
它不是只在發布一個模型。
它是在告訴市場:
強AI不應該只有一種入口,也不應該只由少數公司來定價。
PART.07
最後,梁文鋒到底在做什麼
所以回頭看,梁文鋒為什麼要持續做開源DeepSeek這件事?
我覺得這不是一個簡單的商業選擇。
從純商業角度看,做前沿模型本來就很重。
訓練重,推理重,工程重,成本重,輿論也重。
更不用說,DeepSeek還在持續開源、持續降價、持續做國產算力適配。
這不是一條輕鬆的路,也不是一個適合賺快錢的方向。
但這件事總要有人做。
DeepSeek-V4不是一次完美發布。
它還是preview版本,世界知識和最前沿閉源模型仍然有差距,超長上下文也不是魔法,國產算力從適配到大規模穩定生產還需要繼續爬坡。
但它至少說明,DeepSeek還在沿着一條很難的路往前走:
讓強模型變得更便宜、更開放、更可部署。
這件事對普通人重要,因為未來模型可能會像水、電、搜索、手機一樣,成為每天都要接觸的基礎能力。
這件事對中國重要,因為如果沒有自己的強模型、自己的算力適配和自己的低價供給,我們就只能在別人的智能基礎設施上做應用。
這件事對世界也重要,因為如果沒有開源模型和低價模型持續競爭,最強智能就會越來越像一種昂貴入口,價格、規則和能力邊界都由少數公司決定。
所以DeepSeek-V4真正重要的,不是它讓AI第一次變強。
AI早就變強了。
它真正重要的是,它繼續把強AI往更便宜、更開放、更可部署的方向推。
未來AI競爭,不只是「誰的模型更強」。
而是誰能讓更多人用得起強模型。
誰能讓強模型不只屬於少數公司和少數人。
誰能在未來智能基礎設施裏,給普通人、開發者和一個國家留下位置。
這纔是DeepSeek-V4我真正覺得值得寫的地方。