智通財經APP獲悉,4月29日,騰訊混元推出極致量化壓縮版本翻譯模型 Hy-MT1.5-1.8B-1.25bit,把支持 33 種語言的翻譯大模型壓縮至 440MB,無需聯網,下載即可直接在手機本地運行,翻譯質量優於谷歌翻譯。
基於混元翻譯大模型Hy-MT1.5打造,翻譯效果比肩商用翻譯模型
Hy-MT1.5 是騰訊混元團隊打造的專業翻譯大模型,原生支持 33 種語言、5 種方言/民漢及 1056 個翻譯方向。從常見的中英互譯,到法語、日語、阿拉伯語、俄語,甚至藏語、蒙古語等少數民族語言,它都能遊刃有餘地處理。
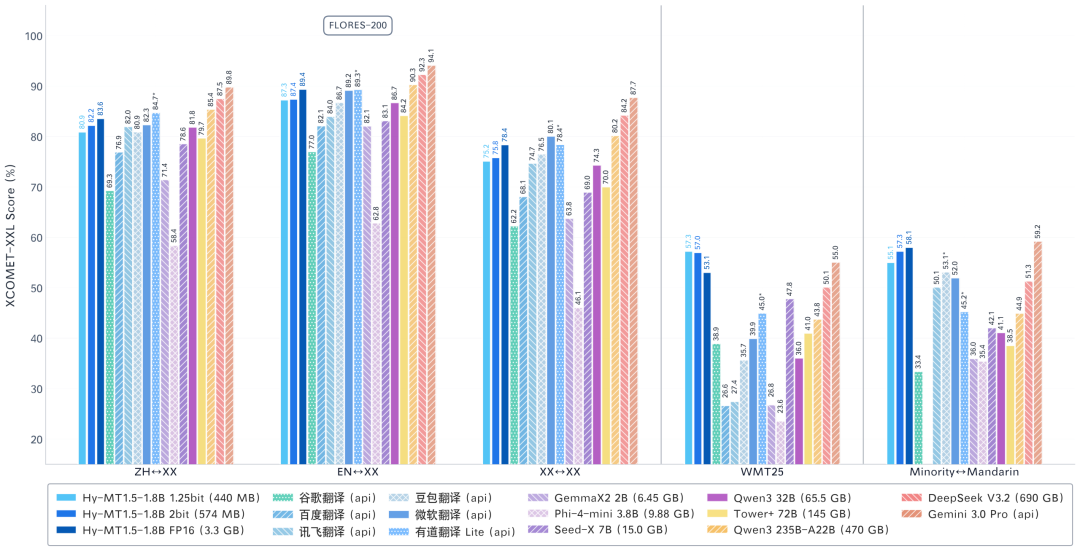
僅以 1.8B 參數量,Hy-MT1.5 實現了比肩商業翻譯 API 和 235B 級大模型的翻譯效果 。在嚴格的評測基準中,其翻譯質量不僅超越了谷歌翻譯等主流系統,更證明了在高效優化下,輕量級模型能夠迸發出令人印象深刻的翻譯能力。
最極致的量化壓縮,把模型裝進手機
量化壓縮,簡單來說就是:把模型裏原本用16位數字(16-bit)表示的參數轉用更低位數字儲存。這就像把一幅高清照片壓縮成縮略圖,文件小了很多,但你還是能看清楚裏面的內容。 針對不同的手機用戶,騰訊特別推出了2-bit 與 1.25-bit 兩種極致的量化壓縮方案。
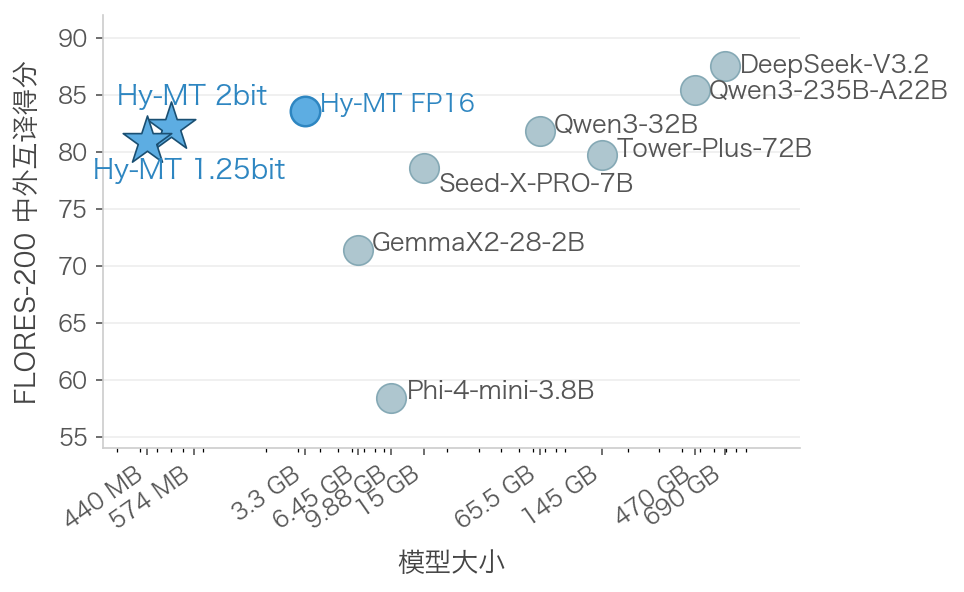
不同大小的模型在FLORES-200中外互譯的效果評分
2-bit模型:性能與質量的平衡(適用:中高端機型)
2-bit 模型採用了業內頂尖的拉伸彈性量化(SEQ),將模型參數量化至{-1.5,-0.5,0.5,1.5},並結合量化感知蒸餾,在將模型體積壓縮至 574MB 的同時,實現了幾乎無損的翻譯質量,效果超越上百GB的大模型。在支持 Arm SME2 技術的移動設備上,2-bit 模型能夠實現更快速、更高效的推理。
1.25-bit模型:Sherry 極致壓縮(適用:全系機型)
為了達成極致的輕量化,騰訊推出了基於 Sherry(稀疏高效三值量化) 技術的 1.25-bit 模型。該技術方案已經被NLP頂級學術會議ACL 2026錄用。
Sherry 壓縮方案的核心邏輯在於「細粒度稀疏」策略:每4個模型參數,3個最重要的用 1-bit 儲存,1個用0儲存,平均每個參數僅需 1.25-bit。
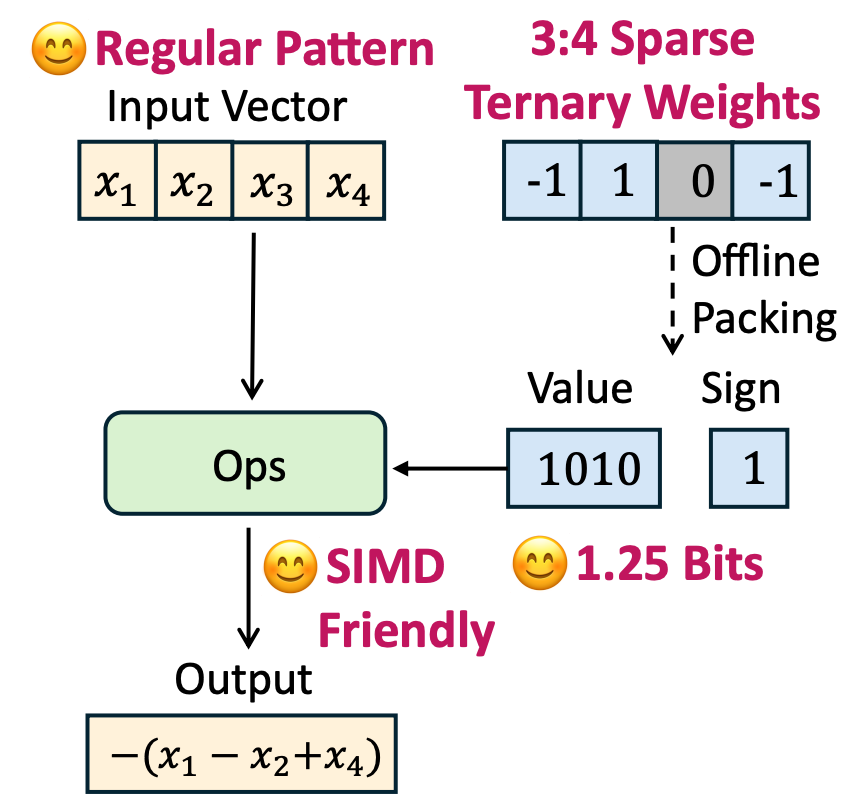
配合騰訊專門為手機 CPU 設計的 STQ內核,該方案實現了對 SIMD 指令集的完美適配。最終,3.3GB 的原始模型被進一步壓縮至 440MB,輕鬆常駐後台,讓內存緊張的普通手機也能順滑進行高質量離線翻譯。
本次開源不僅包含模型權重,還特別製作了一個實際可用的騰訊混元翻譯Demo版,特別適配了「後台取詞模式」。無論是在本地查看郵件還是瀏覽網頁,混元翻譯都能隨叫隨到。無需網絡,無需訂閱,完全本地處理、不涉及個人信息的採集和上傳,一次下載永久使用。