
編輯:艾倫
【新智元導讀】Grok 4.3 是 xAI 一次務實升級:更便宜、更快、更像能幹活的助手。但它在硬推理、穩定性和可信度上,仍落後 GPT-5.5 與 Claude Opus 4.7。
xAI 發布 Grok 4.3,沒有把聲量拉到最大,馬斯克甚至沒單獨發推,看起來只是個過渡版本。

https://x.com/elonmusk/status/2045590599206875216
它更像一次安靜的產品換擋:把模型放進 API,把價格打下來,把工具能力補上,再告訴開發者可以從舊版 Grok 遷移過來。
沒有 AGI 宏大敘事,也少了馬斯克式的「即將改變一切」。這反而讓 Grok 4.3 看起來更真實。
對普通消費者來說,Grok 4.3 最重要的變化並非某個排行榜分數漲了幾分,而是 AI 助手正在變得更便宜、更快,也更像一個能替人完成文件、表格、演示文稿的合格助手。
然而,Grok 4.3 的聰明程度仍然沒追上 GPT-5.5 和 Claude Opus 4.7。
它是一款性價比很強的新模型,也是一款仍有明顯天花板的模型。
消費者真正需要關心的,是它在哪些場景能省錢省時間,在哪些場景會因為判斷不準、想太久或說太多,反而增加成本。
它確實變強了
尤其像一個更會幹活的助手
Artificial Analysis 給 Grok 4.3 的 Intelligence Index 打到 53 分,比 Grok 4.20 0309 v2 高 4 分,也超過 Claude Sonnet 4.6 和 Muse Spark。
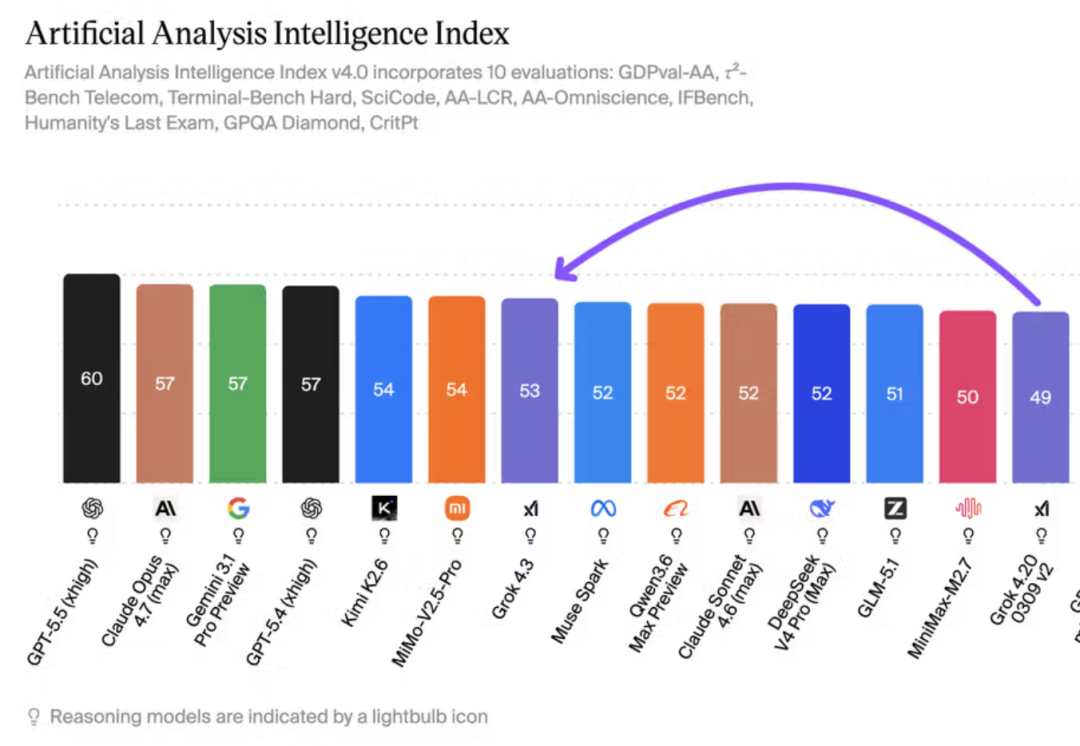
這個提升不算小,尤其在 xAI 自家模型線裏,Grok 4.3 已經是目前最強的一檔。
更值得看的是代理任務表現。
Grok 4.3 在 GDPval-AA 上拿到 1500 Elo,相比 Grok 4.20 0309 v2 的 1179,提升了 321 分。
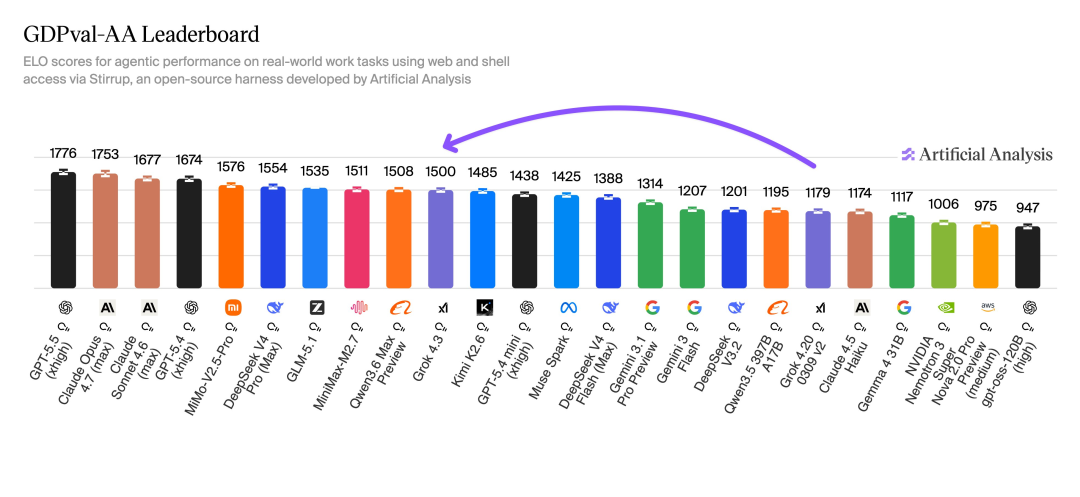
這個排行榜更接近日常「讓 AI 做事」的場景,比如整理資料、執行復雜步驟、處理真實工作流。這對普通用戶有實際意義。
讓 AI 幫忙寫周報、搭表格、做方案、拆會議紀要、生成 PPT,Grok 4.3 的體驗會比前代更完整。
Grok 可以創建演示文稿、文檔和電子表格,可以在一個計算機環境裏寫代碼、運行代碼、安裝依賴併產出文件。
對不懂代碼的用戶來說,這意味着很多原本需要在 Excel、PowerPoint、瀏覽器之間來回切換的操作,可能會被壓縮成一句指令。
這也是 AI 消費級產品真正該競爭的地方——用戶更在意它能不能把一個報銷表做完,把一份旅行計劃排清楚,把一封語氣得體的郵件寫好。
Grok 4.3 在這部分的進步,是真進步。
更便宜
是這次最直接的產品賣點
Grok 4.3 的價格很有侵略性。
它的 API 價格為每百萬輸入 Tokens 1.25 美元、每百萬輸出 Tokens 2.50 美元,相比 Grok 4.20 輸入價格低約 40%,輸出價格低約 60%。

Artificial Analysis 測算,運行整套 Intelligence Index 評測成本約為 395 美元,比 Grok 4.20 0309 v2 低約 20%。

這會影響消費者,只是方式沒那麼直觀。
大多數普通人不會直接調用 API,但他們會用到基於 API 構建的產品。
AI 寫作工具、客服機器人、語音助理、教育應用、辦公插件,背後都要為模型調用付費。
當底層模型價格下降,應用廠商有空間降低訂閱費,或者在同樣價格下提供更多次數、更長上下文、更復雜任務。
Grok 4.3 還有一個優勢是速度。
Artificial Analysis 的 xAI 模型頁顯示,它是 xAI 當前輸出速度最快的模型之一,約 196 Tokens/s,屬於很快的一檔。
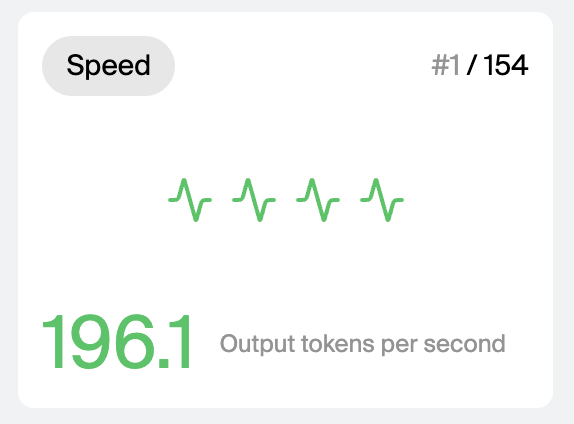
對語音聊天、實時客服、長文生成和批量內容處理來說,等待時間會直接影響體驗。
但速度有一個細節容易被忽略:Grok 4.3 的首 Token 延遲並不低。
它會先「想一會兒」,然後快速輸出。
長答案裏,這種速度優勢明顯;短對話裏,用戶可能先感受到停頓,再感受到快。
用於客服、語音助手、移動端聊天時,這個差異會被放大。
它更會說人話
這是 Grok 的隱藏優勢
Grok 一直有一個微妙優勢:語氣更像真人。
Hacker News 上有人提到,一些英語非母語用戶認為 Grok 在把握文本語氣、正式程度和微妙人際表達上,比其他模型更自然。
有人拿它和 ChatGPT、Claude 比,認為 Grok 在非正式朋友語氣、同事溝通、語音輸入識別上表現更貼近真實交流。

https://news.ycombinator.com/item?id=47972447
Grok 可能受益於 X 平台海量口語化表達訓練。
它更容易捕捉社交網絡裏的語氣、節奏、鬆弛感等;它也可能因此繼承社交網絡的噪音、偏見和表達習慣。
對 C 端用戶來說,這種「更自然」的能力會讓 Grok 在寫消息、口語轉寫、語音助手、輕辦公場景裏很討喜。
它未必最聰明,但可能更像一個願意按你的語氣說話的助手。
Yes, BUT...
它比不過 GPT-5.5 和 Claude Opus 4.7
Grok 4.3 最大的問題,是它看起來已經進入第一梯隊邊緣,卻還沒站到最前面。
Grok 4.3 的 Intelligence Index 為 53,GPT-5.5 為 60,Claude Opus 4.7 為 57。
這個差距不只是排行榜上的幾分。
對普通消費者來說,它會體現在複雜推理、代碼調試、長文覈查、專業諮詢和多步驟任務的穩定性上。
在 GDPval-AA 上,Grok 4.3 的提升很大,但仍落後 GPT-5.5 xhigh 276 Elo,按標準 Elo 公式,面對 GPT-5.5 的預期勝率約 17%。
它在幻覺控制上也有代價。
Grok 4.3 的 AA-Omniscience Accuracy(準確率)提升 8 分,但 Non-Hallucination Rate(非幻覺率)下降 8 分。

這裏的準確率和非幻覺率是不同的,準確率只看你答對了多少,而非幻覺率是看你沒答出來的問題裏面,有多少是模型老實承認自己不會的——不會但振振有詞,就是所謂的「幻覺」。
換言之,Grok 4.3 的知識覆蓋率變高了,但也更容易出現幻覺了。
而消費者最怕的情況就是 AI 答得很流暢、很自信、很像那麼回事,結果關鍵事實錯了。
人類已經很擅長自信地犯錯,機器不必急着加入這個傳統項目。
這意味着,在醫療、法律、金融、學術和工程等高風險場景裏,Grok 4.3 仍需要謹慎使用。
它適合幫用戶起草、整理、生成初稿,適合做低風險的輔助工作;涉及最終判斷,GPT-5.5 和 Claude Opus 4.7 仍更穩。
長上下文和工具能力很好
但消費者買賬的是結果
Grok 4.3 提供 100 萬 Token 上下文窗口,這對長文檔、代碼庫、合同、報告和資料庫很有吸引力。

用戶可以丟進去更多材料,讓模型在更完整的信息環境裏工作。
對研究、辦公和創作來說,這是一種實用能力。
它還支持文本和圖像輸入,輸出文本,並圍繞工具調用、網頁搜索、X 搜索、代碼執行、文件搜索、RAG 等能力加強。
xAI 還推出了 Custom Voices、語音代理、TTS 和 STT 等產品,把 Grok 的邊界從文字擴展到語音。
對普通用戶來說,未來的 Grok 可能不只是一個聊天框,而是一個能讀文件、查網頁、寫表格、說話、聽話的多模態助手。
問題在於,功能多不等於體驗好。
消費級 AI 的競爭,最後會回到三個樸素標準:少等、少錯、少折騰。
Grok 4.3 在「少等」和「少花錢」上明顯前進,在「少錯」上還沒給出足夠強的答案。
Grok 4.3 的準確定位:
性價比模型,不是最強模型
Grok 4.3 最適合的定位,是一款高性價比的工作型模型。
它適合高頻內容生成、語氣改寫、長文本初篩、語音產品、客服場景、批量辦公任務、輕量級代理工作流。
它也適合那些對成本敏感、對響應速度敏感、對最強推理沒有執念的產品。
很多消費者並不需要每次都調用最強模型,就像不應該只是為了買菜開超跑,除非另有所圖。
但如果任務要求深度推理、嚴謹事實覈查、複雜代碼、數學證明、長期項目記憶和專業判斷,Grok 4.3 還不該成為第一選擇。
GPT-5.5 和 Claude Opus 4.7 仍然更適合承擔這些高價值、高風險任務。
這次 xAI 的策略很清楚:先把模型做得足夠強,再把價格打下來,用速度和工具能力擴大可用場景。
它沒有贏下「最聰明模型」的頭銜,但可能會贏走一部分真實使用量。
因為市場並不總獎勵最強者,也獎勵夠強、夠快、夠便宜的選擇。
Grok 4.3 的意義正在這裏。它把 xAI 從一個經常靠馬斯克聲量吸引注意的模型供應商,往更務實的 API 和消費級工具競爭者方向推進了一步。
它看起來很好,確實很好;只是還沒好到能讓 GPT-5.5 和 Claude Opus 4.7 緊張。
消費者可以期待它降價、提速、讓更多 AI 應用變得便宜。
也該記住,在需要真正聰明和可靠的地方,Grok 4.3 仍然只是備選項。