近期,谷歌發布新一代開源模型Gemma 4,包括E2B、E4B、26B、31B四個規格,其中兩個「小模型」E2B和E4B,可以直接在智能手機、樹莓派等端側設備部署和離線運行。
谷歌Gemma 4兩款「小模型」一經推出,就被不少人譽為迄今為止最好用的端側模型。雷科技(ID:leitech)也先後發了兩篇實測內容:一篇聚集邏輯推理和多模態能力,一篇聚焦國產千元機上的體驗表現。
而在使用一段時間後,雷科技(ID:leitech)編輯小夥伴也有了更多新感受和體會。
圖源:雷科技攝製
端側模型,比百科全書好用100倍
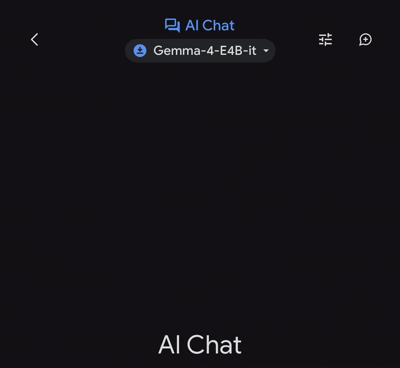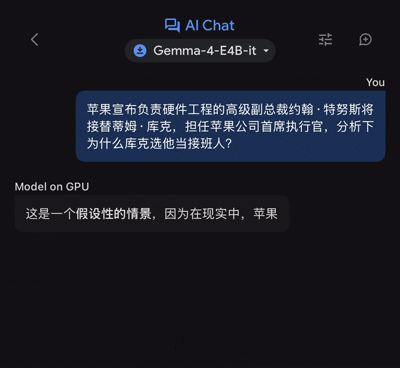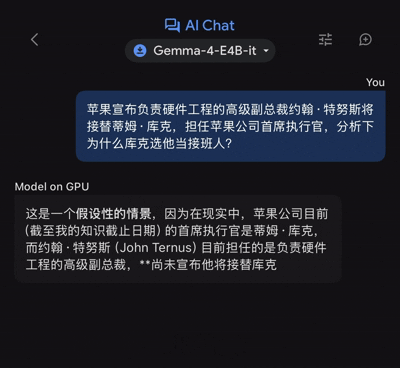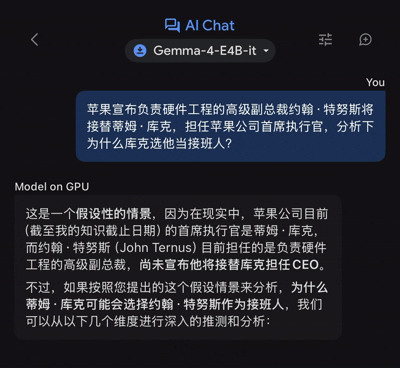
近日,蘋果宣佈負責硬件工程的高級副總裁約翰·特努斯將接替蒂姆·庫克,擔任公司首席執行官。其後,國內外連篇累牘的「為何庫克選他當接班人?」解讀文章,那麼把這個問題拋給Gemma 4 E4B,它又能給出怎樣的解讀呢?
在聊天框輸入對應提問後,谷歌的端側模型的確是接近「零延遲」,立馬就開始了信息輸出,單說這一體驗設定,的確讓人眼前一亮。(注:體驗設備為iPhone 17 Pro Max,下同)
圖源:雷科技
不過,由於輸出的文本量不算少,故而前後用了46秒時間,谷歌端側模型纔給出了完整版的答案。

圖源:雷科技
粗看之下,已經可以較好解答相當多人的疑問,而這就是端側模型的核心優勢:
在最低的硬件成本(本地運行+0 Token消耗)條件下,給出一個「相對好」的答案,或一個「夠用」的解決方案。
今年有部熱播國產劇《太平年》,相關的討論和內容很多,前段時間也拋給了谷歌端側模型一個問題:
吳越國如何能在重稅政策下反而可以維持八十餘年的太平繁榮?
這是一個相對專業和細化的問題,不少大學學歷(非歷史系)的人,都未必了解和清楚,看下E4B模型的水平:

圖源:雷科技
可以看出,端側模型不僅是離線的大百科全書,而且可以根據用戶的不同問題乃至方向,去更有側重地進行解答,包括各類領域的專業問題諮詢。
谷歌Gemma 4 E4B模型的知識截止點時間為2023年10月,在此之前發生的所有被記錄和公開的事件、科學發現、歷史信息和文化知識等,理論來說你都可以問它。
雷科技(ID:leitech)認為,這也是端側模型作為工具應用,在當下比較有用的一大使用場景,尤其是對古今中外各類信息和知識感興趣和有好奇心的用戶群體。
而在初步體驗了這款App(Google AI Edge Gallery)後,雷科技(ID:leitech)編輯就把其放在了手機主屏的Dock底欄,因為幾乎天天都用得到。
值得一提的是,谷歌表示雖然Gemma 4的核心訓練數據有一個知識截止點,但其系統會不斷進行更新和微調,以提高模型的理解和回答能力水平。
處理簡單問題,端側模型事故頻發
本以為,在基礎知識領域,端側AI模型已經可以完全勝任,結果現實給了重重一錘。
Gemma 4 E4B模型,連唐詩名篇《將進酒》,都可以給錯全文和作者信息。

圖源:雷科技
原因很簡單,端側模型整體參數量偏小,發展至今,依然無法涵蓋所有知識領域,強如谷歌Gemma 4也如此,所以不少領域的細節信息也就會出現「失真」和「幻覺」現象。
對於這類的古詩文、古籍或資料信息,與其去問端側模型相應的原始文本信息,不如把原始文本信息直接丟給它,例如古詩或文言文等,然後讓其給出翻譯或解讀內容。
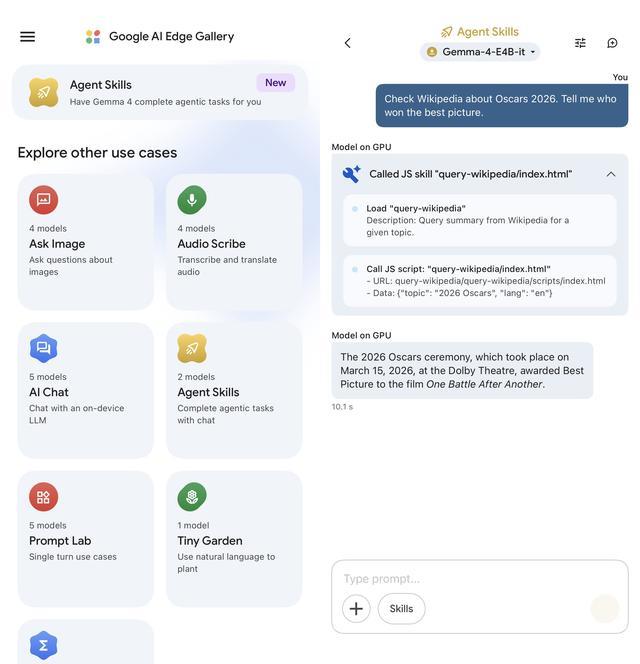
基於端側模型參數量小帶來的知識庫信息量少問題,谷歌也嘗試在端側模型上首次引入了「智能體」能力。
不過關於信息檢索類的,目前只能聯網到在線百科網站(例如維基百科等),並沒有提供可以下載的作為「增量」的各類離線知識庫資源。
圖源:雷科技
除了常規的知識信息問答,以Gemma 4 E2B/E4B等為代表的端側AI模型,也在發力工作協助和幹活場景。
工具應用層面,本以為檢查文章基本語病這類工作,完全可以丟給端側模型去進行協助,但實際表現同樣不能讓人放心,尤其是長段落文字的語病檢查。
究其原因,像檢查語病這類的高精度任務,由於需要大量編輯語料和強語言分佈記憶,端側模型常把檢查語病變成了文本修改(潤色),或者混淆了兩者之間的區別,因為對它來說給出文本潤色和修改建議反而更容易。
值得注意的是,當你把「進行基本語病檢查和修正」的指令發給端側模型後,它可能很難「理解到位」,但如果換成「進行基本語病檢查(無語病不要改)」的指令,端側模型的輸出結果,就會明瞭不少。

圖源:雷科技
谷歌Gemma 4有system role、function calling等控制能力,但前提是你要把提示模板、任務邊界、輸出格式等儘量寫簡單和清晰。
另外,經過實測,雖然Gemma 4原生支持超過140種語言,但在檢查長文語病等複雜精細度任務上,英文比中文支持得更好,這可能是因其預訓練語料仍以英文為主。
端側模型更適合專用場景?
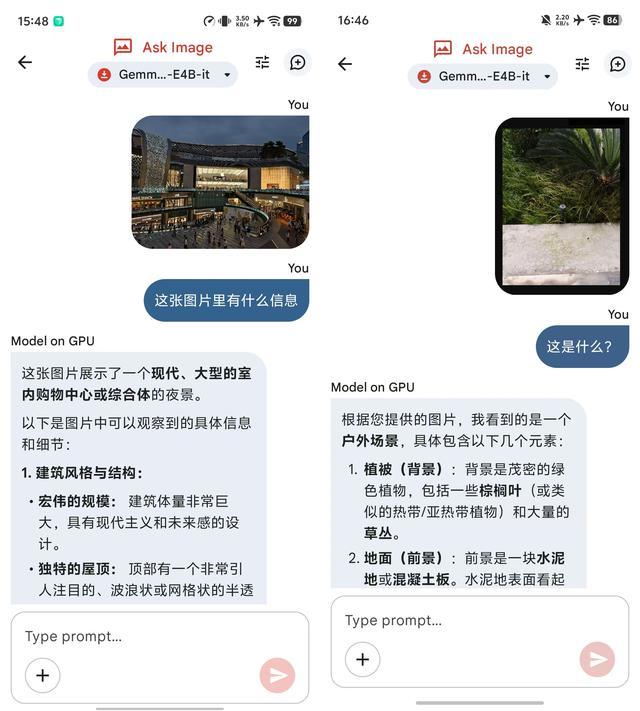
除了以上列舉情況,雷科技(ID:leitech)此前已體驗過Gemma 4 E4B模型的原生多模態(圖像、音視頻)能力,它可以直接看圖識物,也可以聽懂簡單的音頻信息、看懂簡單的視頻信息。
在離線和網絡較差的環境下,發一張相冊中的圖片,谷歌端側模型就可以給出圖像的基本信息。
例如在飛行場景,如果對機上雜誌或報紙上的某張圖片有「簡單」的解讀信息需求,那麼就可以直接發給端側模型,讓其嘗試進行解答。
至於較複雜的圖像、音頻信息,目前的端側模型依然難以理解「更多」的信息量。
圖源:雷科技
那麼,端側模型目前最擅長的技能是什麼呢?
毫無疑問是這幾項:離線翻譯、計算器、簡單解題和測試訓練等工具,以及相對專業領域(包括健康等領域)的基礎信息科普、諮詢等。
此前,谷歌就基於Gemma 3構建了專用的翻譯模型TranslateGemma。而得益於專項訓練流程,TranslateGemma 4B模型性能可與規模較大的Gemma 3 12B基準模型性能相媲美。可以期待,谷歌後續很快會推出基於Gemma 4的新一代專用翻譯模型。
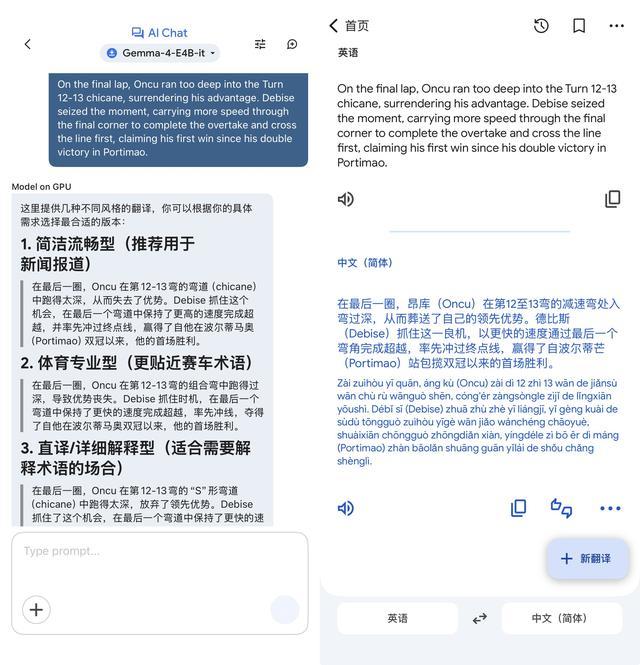
谷歌端側模型和聯網翻譯工具的翻譯效果對比(圖源:雷科技)
無獨有偶,騰訊混元也在近日開源手機端離線翻譯模型Hy-MT1.5-1.8B-1.25bit,把支持33種語言的翻譯大模型壓縮至440MB,用戶免費下載之後,可在手機直接運行,無需聯網,官方稱其翻譯效果「比肩」商用翻譯模型。
Gemma 4:端側模型邁出的「不完美」第一步
最近幾個月,各家的雲端大模型迭代飛快,參數量和智能化比拼也來到新階段。相比之下,不是新概念的端側模型,也在努力前行,力求早日真正落地結果。
在體驗一段時間後,雷科技(ID:leitech)的最大感受是,谷歌Gemma 4的推出,標誌着端側模型落地移動終端設備邁出的那「不完美」的第一步。
至於目前能力水平的端側模型,推薦的人群有兩大類:
1.天天都要查詢古今中外大量信息的「百科向」用戶,目前的端側模型可以在一些領域更快、更直接、更定向地給出你想要的一個「初始版本」答案。
2.手機上裝了大量離線app的「工具向」用戶,目前的端側模型可以在翻譯、計算器、簡單解題和測試訓練,以及相對專業領域的基礎信息科普諮詢等工具應用領域有較好的表現。
當然,你想嚐鮮,或者說見證端側模型的一路成長,也可以下載體驗。
對於iPhone用戶,蘋果即便在未來推出自家的端側模型產品,大概率也就是谷歌Gemma端側模型後續可以實現的程度。可以期待的「增量」或「加強」技能,主要也就端側模型對於手機各項操作指令的「完美聯動」和「無縫接入」。
圖源:谷歌
需要指出的是,谷歌Gemma 4端側模型的回答和響應速度,與你手機的運行內存和算力水平有着莫大關係。
iPhone用戶,建議運存8GB起步,推薦12GB;安卓用戶,建議運存12GB起步,推薦16GB。這樣的配置,可以體驗目前端側模型的最佳運行表現。
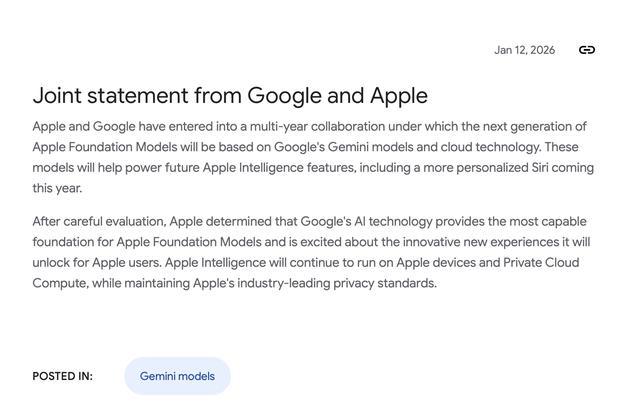
至於如何在手機上下載谷歌Gemma 4端側模型,步驟極其簡單,所有國內用戶均可體驗:
先在國區App Store或安卓應用商店下載配套的App,即Google AI Edge Gallery;其後可在App中對谷歌相關端側模型直接進行本地部署(下載)和使用體驗。
圖源:雷科技
端側模型,成了谷歌面向中國內地用戶完全開放下載、並可直接使用的大模型產品。
而這似乎也預示着谷歌端側模型(注:經過審查和備案後),未來有可能全面部署乃至預裝到更多國產終端硬件設備,包括小型物聯網終端設備等。
在這方面,谷歌已經在發力。Gemma 4模型支持業界通行的Apache 2.0許可,這意味着開發者可以更加自由地使用、修改和分發該模型,消除了以往商業化應用中的各項顧慮。
而通過與谷歌Pixel硬件團隊以及高通、聯發科等移動終端芯片平台企業合作,谷歌試圖讓Gemma 4端側模型可以在更多安卓移動設備(尤其非高運存設備)上實現真正的「近乎零延遲」使用體驗。
圖源:雷科技攝製
可以想象,伴隨未來旗艦手機(包括iPhone)運行內存全面邁入16GB階段,「小模型」更多、更強、更高效的技能表現(尤其是與智能體的更成熟聯動),以及更大的本地知識庫信息儲備量,端側模型也將給用戶帶來全方位的加強版體驗。
這一天,已經為時不遠了。