編輯|重點君
如果提到LLM路線的反對者,李飛飛和楊立昆(Yann LeCun)一定是繞不開的兩人。
近期,楊立昆在科技頻道Welch Labs詳細闡述了他反對僅依靠大語言模型(LLM)來通向AGI的理由,並說明了基於聯合嵌入預測架構(JEPA)架構的世界模型技術細節。
作為深度學習的主要推動者之一,楊立昆認為,單純的自迴歸大語言模型與生成式AI無法實現通用人工智能(AGI),絕大部分人類智能來自於對真實世界的無監督學習。如果AI只進行逐字預測的文本生成,或者逐個像素預測的圖像生成,它就無法真正掌握物理世界的內在運行規律。
基於這樣的判斷,楊立昆試圖推進一種不同於主流生成式大模型的研發方向:通過構建在抽象表徵空間內進行預測的JEPA架構,彌補AI在認知與推理方面的能力缺失。
我們整理了這場訪談的主要信息,以下是重要內容:
1.大語言模型追求復現,而世界模型強調預測
在楊立昆看來,AI具備物理推理能力的層次要高得多。
生成式大模型是復現邏輯,模型本質上是在重現訓練數據中的統計規律,它的主要任務是模仿,只要輸出結果在視覺或語法上合理即可。
世界模型則是預測邏輯,模型的主要任務是推理。它必須在面對未知環境時,準確判斷行為產生的物理結果。AI的最終目標是具備真正的常識,成為能夠自主規劃和行動的智能體。
2.大語言模型存在固有缺陷,世界模型才能通向AGI
楊立昆認為,當前的生成式大語言模型受制於自迴歸機制。系統只是在計算下一個最可能出現的字符或像素,並未在全局層面建立對事物內部邏輯的認知。隨着輸出內容的增加,誤差也會持續累加,最終必然導致嚴重偏離客觀事實的輸出結果。單純依靠擴大模型參數量無法解決這一結構性難題,概率統計過程本身無法直接轉化為嚴謹的因果推理能力。
而世界模型在系統內部建立了反映現實邏輯的預測機制。這使得AI在實際執行任務前,能夠先在抽象層面上準確預判不同行動路線的物理後果。這種基於客觀規律進行內部推演和決策的能力,改變了機器只能被動響應靜態數據的現狀,賦予AI主動干預現實的基礎認知,這是機器獲取通用人工智能的必要條件。
3.JEPA世界模型技術路線摒棄像素級預測,轉向數學表徵空間(Representation Space)
主流的生成式模型試圖重構圖像或視頻的每一個視覺細節。由於物理世界充滿了不可預測的隨機干擾信息,這種嘗試往往會導致模型生成模糊的圖像,或者消耗極其龐大的計算資源。
與注重視覺生成效果的模型不同,JEPA架構的主要特徵在於剔除無用的環境細節。它通過孿生網絡(Siamese Networks)等結構,將輸入信息壓縮成高度概括的數學表徵。這意味着模型不再需要完全還原環境,而是直接在抽象層面上預測事物的運動規律和發展趨勢。
JEPA目前已被用於提升機器視覺與物理推理能力,研究人員通過V-JEPA等模型,讓機器人在不依賴海量人工標註數據的情況下,學會理解物體之間的相互作用。
4.解決表徵坍塌(Representation Collapse)難題,世界模型即將迎來技術突破
為什麼在抽象空間內進行預測的AI發展面臨困難?主要阻礙在於模型容易進入表徵坍塌的錯誤狀態。在這種狀態下,模型會輸出恒定不變的錯誤結果來強行匹配預測目標。
為了解決這一難題,楊立昆團隊採用了Barlow Twins等技術策略。通過最大化不同特徵之間的信息差異,迫使模型學習真實有效的環境信息。隨着表徵學習技術的成熟,基於JEPA的世界模型領域即將迎來大規模擴展的技術突破時刻。
以下是楊立昆訪談實錄:
1.尋找取代LLM的全新架構:JEPA
主持人:人工智能傳奇人物楊立昆籌集了十億美元,用於探索人工智能的替代方案。與大型語言模型不同,楊立昆的方法既不以語言為基礎,也不是生成式的,它在設計上就不會輸出文字、圖片或視頻。取而代之的是,他提出了JEPA方案。
JEPA不是單一的AI模型,而是一種全新的架構或用於訓練AI模型的框架。在人工智能和機器學習的許多成功案例中,模型都是通過給定輸入X來預測輸出Y進行訓練的。比如大型語言模型接收輸入文本X並被訓練來預測接下來出現的文本Y;圖像分類器接收輸入圖像X並被訓練來預測相應的標籤Y。
但JEPA的工作原理並非如此。在JEPA中,輸入X和輸出Y被分別輸入到名為編碼器(Encoder)的模型中。這些編碼器會返回一個數字向量或矩陣,也就是通常所說的嵌入(Embedding)。隨後,第三個被稱為預測器(Predictor)的模型會基於X的嵌入來預測Y的嵌入。
為什麼這可能是構建AI系統的一種更好方式?你認為JEPA或者基於世界模型的方法未來有一天會取代LLM嗎?還是說它們其實是在解決不同的問題?
楊立昆:初期它們解決的是不同問題,但最終它們確實會取代LLM。因為LLM雖然非常擅長處理語言,但除此之外基本毫無建樹。在語言本身即為推理基底的領域,相比主流的生成式語言AI方法,它們的表現非常出色。
主持人:JEPA存在於聯合嵌入架構(Joint Embedding Architectures)這一替代路徑上。有趣的是,楊立昆在這兩條路徑的發展初期都發揮了重要作用。
在這個由兩部分組成的系列訪談的第一部分中,我們將探索通往JEPA的這條替代路徑。我們將深入探討為什麼楊立昆會在生成式架構於語言領域嶄露頭角之時選擇放棄它,並探尋他在解決困擾聯合嵌入架構多年的表示崩潰(Representation Collapse)問題時所獲得的靈感。最後我們將深入研究JEPA架構本身。在第二部分中,我們將深入探討JEPA的實現方式,並看看這些模型與驅動LLM的方法相比究竟表現如何。
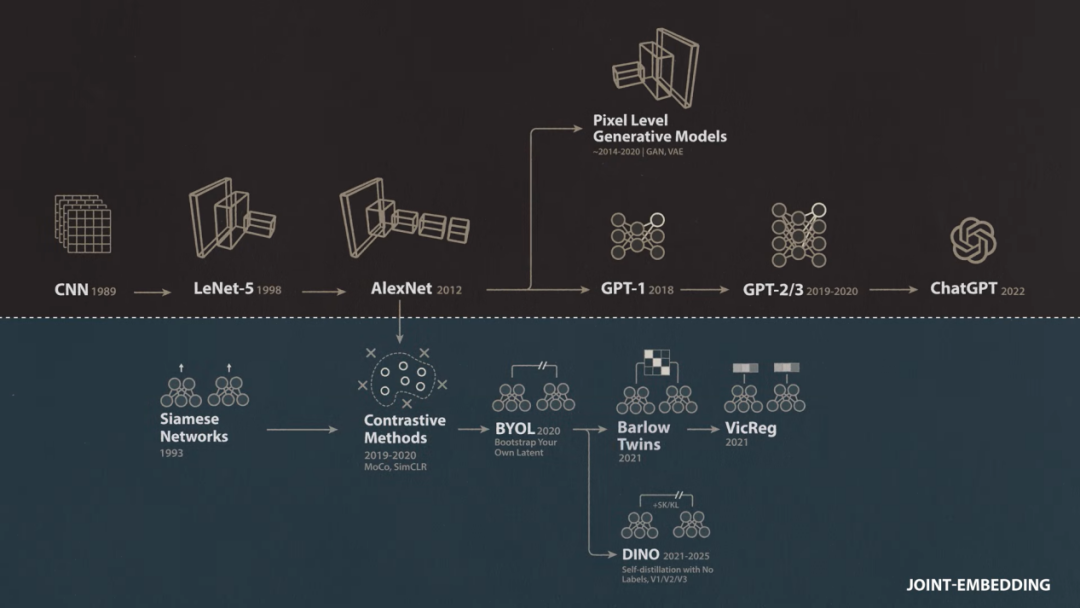
楊立昆在20世紀80年代就預見到了這場變革的到來。當時AI領域的大多數人正忙於構建顯式編程而非從數據中學習的專家系統,而他開創了卷積神經網絡。25年後當深度學習開始崛起並佔據AI主導地位時,突破性的深度學習模型AlexNet被發現與楊立昆在20世紀90年代提出的卷積網絡驚人地相似。
然而隨着深度學習在2010年代繼續高歌猛進,楊立昆和其他研究人員變得愈發擔憂,因為這種AI方法過度依賴帶標籤的訓練數據。AlexNet是在龐大且經過精心標註的ImageNet數據集上通過監督學習進行訓練的,它被訓練去匹配人類標註者為每張圖像分配的標籤。相比之下,兒童只需極少數明確標記的示例就能學習到像「狗」這類概念且極具通用性的表示。
隨着手動標記數據成為監督學習的瓶頸,人們對替代方法的興趣日益濃厚。強化學習讓模型通過與環境交互而非從標記數據中學習,它在2010年代中期經歷了多次復興,Google DeepMind在Atari遊戲以及高度複雜的圍棋(Go)上的突破性表現就凸顯了這一點。與此同時楊立昆等人探索了從無標籤數據中學習的無監督方法,其中包括一種被稱為自監督學習(Self-supervised Learning)的變體,其標籤直接取自數據本身。
楊立昆:大約在2015年,我開始在機器學習社區展示一張後來變成梗的幻燈片。我在上面說如果把智能比作一個蛋糕,那麼自監督學習就是蛋糕的主體,監督學習是蛋糕上的糖霜,而強化學習只是頂端的那顆櫻桃。當時人們對強化學習已近乎瘋狂,所以我試圖告訴他們這種方法太低效了,永遠不可能帶我們達到接近人類或動物智能的水平。事實證明,自監督學習的成功在文本和語言領域發生得要比在視覺等更自然的模態中快得多。

2.生成式模型在視覺領域的困境
主持人:楊立昆這裏指的是通過預測下一個Token來訓練大型語言模型(LLM)所取得的成功。OpenAI成立於2015年,最初致力於強化學習,創建了OpenAIGym和Universe並在複雜的視頻遊戲中展示了令人印象深刻的性能。
當公司大部分精力都集中在強化學習上時,Ilya Sutskever和Alec Radford等人開始對來自Google的一種新型神經網絡架構Transformer產生興趣。它最初是為語言翻譯設計的,但在實驗過程中Radford嘗試了一種有趣的修改。他沒有讓Transformer將一種語言轉換為另一種語言,而是轉向了一種更簡單的自監督方法:訓練文本被分解為序列,Transformer接收除了最後一個Token之外的所有內容,並被訓練來預測最後一個Token是什麼。
Radford和他的OpenAI同事們在一個包含7000本書的龐大內部數據集上訓練了他們的Transformer。這個階段現在被稱為預訓練(Pre-training),隨後他們使用標準的有監督學習在特定的語言任務上進一步訓練模型。
這種兩階段訓練方法效果顯著,在包括高中水平閱讀理解在內的九項語言基準測試中創下了新的SOTA結果,表現超越了針對每個單獨任務專門設計的架構。Radford的模型也就是現在的GPT-1,雖然當時沒有引起太多公衆關注,但它是一個巨大的突破,使模型擺脫了對人工標註數據的依賴並開啓了前所未有的規模化水平。
OpenAI的其他研究人員迅速領悟了這項研究的重要性,團隊全力投入這種方法,在2019年激進地擴展到GPT-2,2020年推出GPT-3,以及2022年發布ChatGPT。在2012年AlexNet是在約一百萬個樣本上訓練的,而到2020年GPT-3的訓練樣本量已達到數千億個。
有趣的是這種新出現的訓練範式完全符合楊立昆幾年前的預測:廣泛的自監督預訓練階段,隨後是監督學習,最後是強化學習,將原始的下一個Token預測模型塑造成為一個實用的AI助手。然而儘管這些自監督生成方法在語言領域取得了明顯突破,但在圖像和視頻數據方面的情況卻模糊得多。
楊立昆:我一直在研究視覺領域。最初的想法是使用生成式架構來訓練一個預測視頻中會發生什麼的系統,基本上就是在像素層級訓練視頻後續的發展。
主持人:在GPT-1成功的前幾年,包括楊立昆在內的研究人員曾嘗試將同樣的自監督生成式方法應用於視頻。在最直接的實現中,神經網絡接收一系列視頻幀的RGB像素值,然後像GPT模型預測語言中的下一個Token一樣去預測下一幀的像素值。
然而當我們使用這些模型來預測下一幀時,結果是模糊的,而且這種模糊感在更長周期的預測中會劇烈累積。大語言模型是自迴歸(Autoregressive)的,當ChatGPT回答問題時它一次生成一個Token,並在每一步將最新生成的Token傳回輸入端以產生下一個輸出。如果我們嘗試將這種自迴歸方法應用於下一幀視頻預測模型,結果會迅速退化為模糊的虛無。
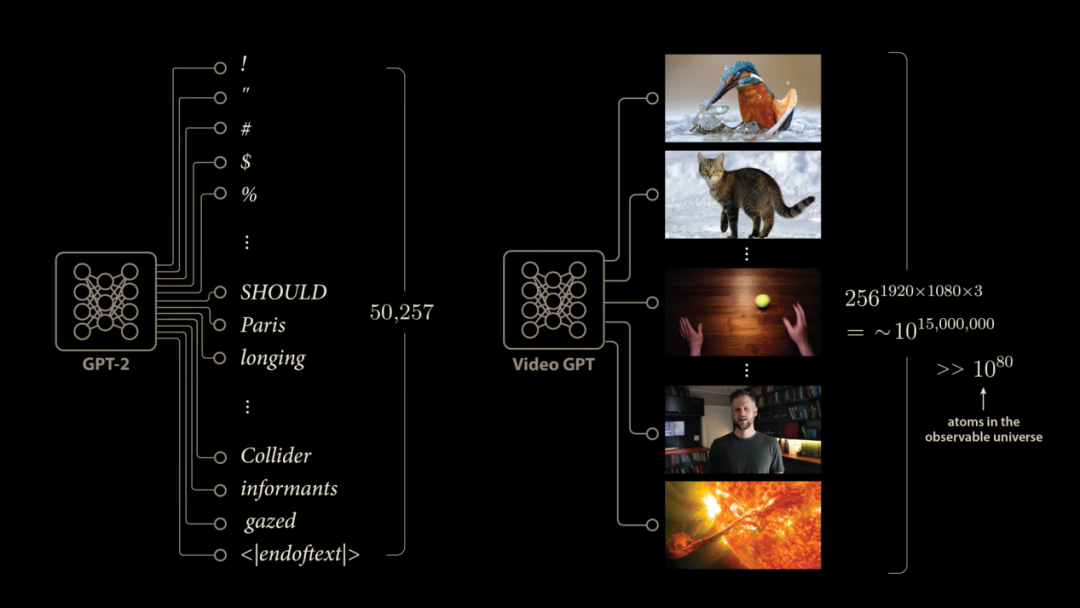
生成式視頻預測方法產生的模糊幀並不是什麼未解之謎。語言雖然複雜且不可預測,但與視頻相比根本不算什麼。語言模型使用固定大小的詞彙表,比如GPT-2擁有50257個離散輸出對應下一個可能生成的Token。這種完全枚舉的方法在視頻領域行不通。
對於全高清視頻,在最一般的情況下每個像素可以取256個離散值,而我們擁有1920×1080×3個彩色像素。這意味着下一幀視頻可能有大約10的1500萬次方種可能性,這令可觀測宇宙中的原子數量都相形見絀。因此視頻預測模型不可能像語言模型那樣為每一個可能的下一幀提供離散輸出。相反那個時代的許多生成式視頻方法讓網絡直接輸出像素強度值,這種方法面臨的巨大挑戰是模型如何學習處理不確定性。
如果我們對比LLM學習補全句子「球彈向了xx地方」和一個預測球體彈跳視頻下一幀的神經網絡,就能清楚看到問題所在。在LLM訓練案例中,模型在訓練集中會看到各種示例,由於模型為每個Token都有獨立輸出,它基本上可以獨立更新這些概率。
但我們的視頻模型就沒有這麼輕鬆了。如果數據集包含球從同一路徑開始運動然後向各個方向彈跳的視頻,由於模型被迫針對給定輸入直接預測單個輸出幀,面對這種歧義性它能做的最好處理就是預測這些結果的平均值。當我們對視頻的像素值取平均時,最終得到的就是一片模糊褪色的混亂畫面。
雖然這只是最天真的方法,在過去幾十年里人們也嘗試了許多圖像預測策略並取得了不同程度的成功,但這些自然產生的挑戰促使楊立昆等研究人員提出了一個有趣的問題:我們的模型真的必須是生成式的嗎?在GPT示例的關鍵預訓練階段,模型是否具有生成能力其實並不重要。
在針對「預測下一個Token」進行預訓練之後,我們得到的是一個本質上非常出色的自動補全模型。但真正重要的是模型為了解決預測任務而學習到的內部表示和特徵,正是這些內部表示使得預訓練模型能夠被快速適配成強大的AI助手。語言上的下一個Token預測是智能的一種代理指標,事實證明這種方法效果驚人。但是否還有其他信號和方法可以用來學習構建智能系統所需的強大內部表示(Representations)呢?
3.聯合嵌入架構的引入
楊立昆:與此同時在2017到2018年左右,我們開始意識到學習圖像表示的最佳系統是那些非生成式的系統。它們不進行重構。
你輸入一張圖像將其通過一個編碼器(Encoder),接着你嘗試引導這個編碼器在具備某些特性的前提下提取儘可能多的信息。例如你拍攝同一場景的兩張圖像,或者拍攝一張圖像並以某種方式對其進行損壞或轉換。你將它們都通過Encoder運行,然後告訴系統無論提取出什麼,這兩張圖像的表示都應該是相同的,因為它們在語義上代表同一個事物。我
從90年代起就一直在研究這類聯合嵌入(Joint Embedding)的想法,這並不是新概念,我們以前稱之為孿生神經網絡(Siamese Neural Net)。
主持人:楊立昆提到的孿生網絡是由他及其合作者於20世紀90年代初在貝爾實驗室(Bell Labs)開發的,當時是為了開發檢測欺詐簽名的系統。
該系統的工作原理是將一對簽名圖像輸入到兩個相同的神經網絡副本中。這些網絡副本並非為了生成任何數據而訓練,相反它們輸出的是數字向量也就是嵌入向量(Embedding Vectors)。
網絡副本在兩類樣本上進行訓練:正樣本包含一個參考簽名和一個非欺詐簽名,即出自同一人之手;負樣本包含一個參考簽名和一個欺詐簽名。對於欺詐樣本,網絡被訓練為產生差異最大的嵌入向量;對於正樣本,則生成相似度最大化的嵌入向量。當新簽名出現時,我們可以將其傳入網絡計算出一個嵌入向量並與參考簽名生成的向量進行比較,如果相似度不足該簽名將被檢測為僞造。
通過對簽名進行聯合嵌入,孿生網絡學習到了簽名圖像中非常有用的內部表示,值得注意的是這一過程無需學習預測或生成任何實際的簽名圖像。正如基於GPT的方法那樣,聯合嵌入為視頻模糊問題提供了一個潛在的可行解決方案。
楊立昆:你獲取一張圖像將其輸入編碼器,接着你嘗試引導這個編碼器提取儘可能多且具有特定屬性的信息。例如你拍攝同一場景的兩張圖像或者獲取一張圖像並對其進行損壞或轉換。你將它們通過編碼器運行並告訴系統,無論提取出什麼這兩張圖像的表示都應該是相同的,因為它們在語義上代表同一個事物。

4.攻克聯合嵌入的表示崩潰難題
主持人:所以這裏的思路是,我們避開了在生成式模型中看到的視頻模糊問題。通過使用聯合嵌入架構,將經過損壞或轉換處理的圖像或視頻副本映射到相似的嵌入向量。理想情況下,這個經過訓練的模型將學習到圖像或視頻的有用的內部表示,我們可以將其重新用於其他任務,正如GPT模型在預訓練期間學習內部表示並最終被調整為AI助手的行為一樣。
然而這種聯合嵌入(Joint Embedding)策略存在一個巨大的問題。由於我們訓練網絡的目的是使原始圖像或視頻與損壞後的版本儘可能相似,網絡可能會找到一個平凡解,即無論傳入什麼輸入,它都簡單地返回相同的嵌入向量。如果網絡學會了對任何輸入都輸出全1的向量,那麼它對於同一圖像的受損和未受損視圖都會返回全1,從而使產生的相似度最大化,但實際上並沒有學到任何有用的東西。這個問題被稱為表示崩潰(RepresentationCollapse)。
在楊立昆最初的孿生網絡(SiameseNetwork)方法中,團隊使用瞭如今被稱為對比學習(ContrastiveLearning)的方法來避免表示崩潰,並在訓練時為網絡提供正負樣本。事實證明這種對比方法同樣適用於圖像和視頻,我們可以訓練網絡使其對同一底層圖像或視頻的不同視圖輸出相似的嵌入,而對不同的圖像或視頻輸出不同的嵌入。
這些對比方法雖然在圖像和視頻領域取得了成功,但在擴大規模時卻面臨困境,往往需要海量的計算資源和龐大的負樣本庫才能學習到有意義的表示。楊立昆認為在最壞的情況下,對比樣本的數量可能會隨表示維度的增加呈指數級增長。
到2010年代末,楊立昆等人已經清楚認識到,使用生成式模型去完全重建圖像和視頻並不是自監督學習的有效路徑。但當時業界並沒有一個直接的解決方案來處理表示崩潰問題,這也阻礙了聯合嵌入架構學習到與大語言模型同等強大的通用內部表示。
楊立昆:很明顯,對於圖像和視頻這類信號採用重建的方法並不是個好主意。後來我恍然大悟,因為我們當時用來訓練聯合嵌入架構的方法多少有些取巧。直到我和Meta的幾位博士後同事,特別是阿德里安·巴德斯(AdrienBardes)做了一些研究,他提出了一種名為Barlow Twins的技術。這項技術基於計算神經科學和機器學習領域的一個古老理念,傑夫·辛頓(GeoffreyHinton)也曾研究過類似觀點,即系統需要有某種衡量信息內容的標準並嘗試將其最大化。著名的理論神經科學家霍勒斯·巴洛(HoraceBarlow)在這方面做過一些開創性的基礎研究。
主持人:這裏楊立昆引用的是霍勒斯·巴洛的研究工作。1961年巴洛提出假設,認為動物和人類視覺系統中的神經元是通過減少相互之間的冗餘信息來運作的。2020年,楊立昆的博士後研究員斯蒂芬·德尼(StephaneDeny)基於對巴洛研究的了解,提出將巴洛的理念應用於網絡輸出端,以此作為避免表示崩潰的一種途徑。
在我們討論的聯合嵌入架構中,嵌入向量是由網絡最後一層的人工神經元生成的。如果嵌入向量長度為128,那麼每個網絡的輸出層就包含128個神經元。如果傳入一批多樣的圖像並觀察遍歷過程,第一個神經元可能在狗的照片上強烈激活,但在貓的照片上則無反應。
在聯合嵌入方法中,網絡接收同一批圖像的變形視圖,其核心目的就是讓同一底層圖像生成的嵌入表示趨於相似。因此我們希望第二個網絡中第一個神經元的輸出能與第一個網絡中第一個神經元的輸出保持高度一致。標準架構只需測量並最大化這兩個向量的相似度即可,但這極易導致網絡簡單地為所有輸入輸出相同值,即發生表示崩潰。
引入巴洛的假設後,團隊選擇通過計算兩個網絡輸出向量之間的互相關(Cross-Correlation)來減少不同神經元輸出間的冗餘。計算過程包括對每個向量進行縮放並求點積,最終得到皮爾遜相關係數(PearsonCorrelationCoefficient)。為了減少冗餘,我們希望這種相關性趨近於零。
將兩個編碼器的神經元輸出分別垂直和水平排列,計算所有神經元對之間的相關性並構建成一個矩陣。由於聯合嵌入架構的核心理念是為同一圖像的不同失真版本產生相似輸出,我們希望兩個編碼器中對應的神經元具有高度相關性,同時希望非對角線上對應不同神經元的元素相關性為零。理想狀態下,這個互相關矩陣應該呈現為單位矩陣(IdentityMatrix)。
楊立昆及其合作者由此設計了一個全新的損失函數,用於衡量互相關矩陣與單位矩陣之間的偏差。這種被稱為Barlow Twins的新方法效果驚人,它在成功學習訓練圖像強大內部表示的同時,完美避開了表示崩潰的陷阱。團隊採用了多種方法來驗證這些內部表示的質量。
正如早期自監督預訓練讓GPT-1超越了純監督模型一樣,當時視覺任務最重要的基準測試是ImageNet數據集的分類準確率。2012年原始的AlexNet在驗證集上實現了59.3%的準確率。為了將自監督的Barlow Twins與全監督模型進行直觀對比,團隊使用了線性探測(LinearProbe)方法,即在凍結的Barlow Twins編碼器輸出端添加一層神經元,並使用監督學習進行分類訓練。結果令人矚目,該模型在ImageNet上達到了73.2%的準確率,比全監督的AlexNet高出整整10個百分點。
然而在2012年到2021年間,全監督方法本身也取得了長足進步,例如谷歌團隊在2020年將Transformer架構應用於圖像分類,創下了88.6%的新紀錄。因此到2021年,儘管自監督學習在視覺任務中進展迅猛,但其綜合表現仍略遜於最頂尖的全監督方法。在語言領域推動大模型快速發展的生成式預訓練範式,在圖像和視頻領域依然難以跑通。
楊立昆:事實證明我們選擇的是一條正確的道路。在那之後我們發布了Barlow Twins的簡化版VICReg,效果同樣出色。與此同時我們在巴黎的同事也在研究類似路線,最終演變成了DINO系列。這也是一種JEPA技術,事實非常明確,聯合嵌入在圖像表示的自監督學習方面具有顯著優勢。
主持人:2025年8月發布的DINOv3論文標誌着視覺領域的一個重要轉折點。它利用聯合嵌入架構實現了88.4%的極高圖像準確率,緊逼當前行業的最先進水平。
正如作者在論文中所述,這是自監督學習首次在圖像分類任務上達到與監督模型相匹敵的成果。DINOv3在零人工標籤介入的情況下展現出的表徵學習能力令人震撼。它為分析的每個圖像塊(Patch)輸出一個嵌入向量。如果從測試圖像的手部區域提取嵌入向量並與圖像其他部分進行相似度比對,DINO能夠精準地將手部從複雜背景中完美分割出來,這種能力同樣適用於球、貓或書本等任何物體。
在Barlow Twins、VICReg和DINOv1取得連串成功後,楊立昆於2022年將這些思路凝練成了一篇長達60頁的重磅立場論文《邁向自主機器智能之路》(A Path Towards Autonomous Machine Intelligence)。與他以往專注於機器學習具體技術細節的論文不同,這篇文章採用基於第一性原理的全局視角,深刻探討了我們究竟該如何構建真正的智能機器。論文首先犀利指出,目前的AI方法距離人類的學習能力還差得很遠,比如一名青少年只需20小時左右的練習就能熟練掌握開車技能。
楊立昆:這基本上就是Tesla正在努力的方向。但是他們距離真正實現Level3至Level5的自動駕駛還差得很遠。然而一個17歲的少年只需幾個小時的練習就能學會開車。這究竟是如何實現的?難道我們不應該弄清楚這背後隱藏的智能奧祕嗎?我的核心推測是,這個奧祕就是世界模型(World Models)。
5.世界模型:邁向自主機器智能
主持人:楊立昆壓下重注的論斷是:現代AI缺失的最關鍵一環正是世界模型,即能夠對物理世界運行規律做出準確預測的模型。正如他在2022年論文中所闡釋的,常識本質上可以被視為一系列世界模型的集合,它們負責告訴智能體什麼是可能的、什麼是合理的以及什麼是絕對不可能的。憑藉這些世界模型,動物只需極少量的試錯就能掌握新技能,它們能夠預判自身行為的後果,進而進行推理、規劃、探索並為複雜問題構思出全新的解決方案。楊立昆進一步論證,聯合嵌入架構為構建這種世界模型提供了最堅實的底層基礎。
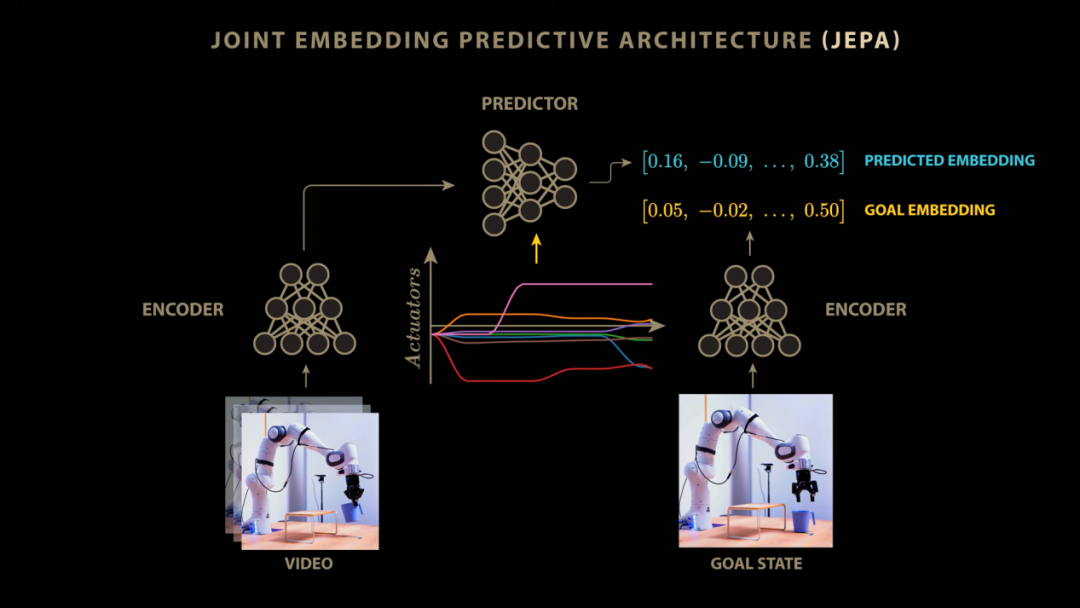
楊立昆:JEPA代表聯合嵌入預測架構(聯合嵌入PredictiveArchitecture)。其運行機制是先獲取對世界的當前觀測狀態,再獲取下一個觀測狀態,並將它們依次通過編碼器進行處理。隨後預測器會嘗試根據時間t的狀態去預測時間t+1的狀態,你還可以通過輸入具體的動作指令來對預測過程進行干預和調節,這樣你就獲得了一個完整的世界模型。
主持人:舉個具體的例子,與其使用傳統的生成式架構去逐個預測視頻下一幀的龐大像素值,我們完全可以將視頻當前幀和下一幀映射到精簡的嵌入空間中。然後訓練一個預測器模型,讓它在給定當前視頻嵌入的情況下直接預測下一幀的嵌入。在這種實現機制下,JEPA架構成功將模型從預測海量像素的繁重且低效的任務中解脫出來,使預測器能夠全神貫注於分析場景中經過編碼器篩選的那些核心顯著特徵。楊立昆在這裏提出了一個極佳的思維實驗。
楊立昆:如果你訓練一個模型來預測行車記錄儀畫面中接下來會發生什麼,傳統的生成式模型會把極其寶貴的算力資源浪費在預測道路兩旁樹葉的隨機擺動上,這些內容本質上毫無預測規律可言,卻佔據了畫面中大量移動的像素。
主持人:正如楊立昆之前提到的,我們可以通過引入動作條件將JEPA的應用邊界進一步拓寬。在V-JEPA2的研究中,團隊將機械臂接收到的具體動作信號作為約束條件輸入到JEPA模型中。JEPA在觀察機械臂及其所處環境的連續圖像序列時,不僅要通過訓練預測下一幀畫面的嵌入表示,還要同步處理發送給機械臂的控制信號。這使得預測器能夠深度學習並準確預測出各種不同的控制指令將如何實際改變機械臂在未來嵌入圖像中的空間位置。
這種經過充分學習的世界模型隨後就可以直接用於機器人的複雜規劃與精密控制。給定一張代表目標狀態的圖像(例如將杯子移出平台),該圖像被傳入下一幀編碼器生成目標狀態的嵌入。在此基礎上,系統可以使用控制算法在世界模型中進行預演和探索,測試各種假設性的動作干預,最終反向推導出一系列能夠引導模型預測狀態完美匹配目標狀態的最優動作序列。正如楊立昆所評價的,這確實是用前沿架構對一個經典舊理念的全新重塑。
楊立昆:你構建了一個強大的模型,它能根據當前的世界狀態以及你設想採取的控制動作,精準提供下一個時間步的世界狀態。一旦擁有了這個模型,你就可以在虛擬空間中預測任意動作序列的最終結果,並通過數學優化計算出一條最優的操作路徑以達成特定目標。這是非常經典的優化控制(Optimal Control)理論,其歷史淵源可以追溯到20世紀50年代末的蘇聯以及60年代初的西方學術界。
主持人:這確實是控制理論中極其經典的核心內容。
楊立昆:是的。但這套架構中不那麼經典的部分在於,你需要用最前沿的機器學習技術來從零訓練這個模型。更具顛覆性的是,你還要讓網絡自行學習出一種高度抽象的輸入狀態表示,並在這個抽象的狀態空間中完成模型的學習閉環,這正是JEPA的精髓所在。
讓我拋出一個可能會得罪不少硅谷同行的爭議性觀點。我根本無法理解你們怎麼能設想去構建一個高級的智能體系統,卻不賦予它預測自身行為後果的基礎能力。變分自編碼器(VAE)做不到這一點,當前火熱的大語言模型也同樣不具備世界模型。它們根本無法在行動前預判自己的輸出會造成什麼後果,它們只是盲目地生成token採取行動,然後就像某位法國國王所說的那樣——「我死後哪怕洪水滔天」。
如果你真的想構建安全可靠的智能體系統,它們絕對必須具備預測行為後果的能力,只有這樣它們才能合理規劃行動序列以完成複雜任務,並在此過程中嚴格確保安全護欄不被突破。在這樣的系統裏,推理過程已經演變成了一個嚴密的搜索與推演過程,而不再是簡單的自迴歸預測。這就是世界模型的全部核心理念與終極價值。