
啓用新協議,一級核心交換機可直接重啓不影響模型訓練。
芯東西5月7日消息,昨日晚間,OpenAI與AMD、博通、英特爾、微軟、英偉達聯合發布全新開放網絡協議MRC(多路徑可靠連接),可幫助大型AI訓練集群更快、更可靠地運行。OpenAI通過開放計算項目(OCP)發布了MRC。
MRC已部署在OpenAI所有用於訓練前沿模型的超級計算機上,包括位於美國德克薩斯州阿比林的美國甲骨文雲基礎設施(OCI)站點,以及微軟Fairwater超級計算機等。
MRC是一種內置於最新800Gb/s網絡接口中的新網絡協議,可將單次數據傳輸分流至數百條路徑、微秒級繞開故障鏈路,同時還能簡化網絡控制面架構。
OpenAI官方博客提到,近期為ChatGPT與Codex訓練一款前沿大模型時,他們不得不重啓四台一級核心交換機,以往重啓交換機需運維團隊極度謹慎,引入MRC之後,他們甚至無需與集群訓練任務的運維團隊提前協調就可重啓。
在打造基建項目Stargate之前,OpenAI已與合作伙伴在幾年間開發並維護了前三代超級計算機,這使其認識到要在超級計算機上高效利用算力併成功完成任務,需要大幅降低堆棧每一層的複雜性,包括重新設計網絡。
OpenAI官方賬號X的評論區有不少網友肯定了MRC的發布,稱其是真正的基礎設施進步、標誌着基礎設施競爭轉向標準化集群通信效率時代。

01.
破解網絡難題
MRC對擴展超級計算機有三大助力
訓練大模型時,一個步驟可能涉及數百萬次數據傳輸,而一次延遲傳輸可能會在整個作業中波動導致GPU處於空閒狀態,而網絡擁塞、鏈路和設備故障是傳輸延遲和抖動最常見的原因。
隨着算力基建規模的增大,這些問題發生得更頻繁且更難解決。其面臨兩個關鍵的網絡挑戰:要儘可能降低網絡擁塞的發生概率,儘量減少網絡故障對訓練工作本身的影響。
基於此,OpenAI聯合多家芯片公司打造了MRC。其目標是打造一個即使在出現故障時也能提供高度可預測性能的網絡,以保持訓練任務能持續推進。
MRC是對聚合以太網RDMA(RoCE)的擴展。RoCE是由無限帶寬行業協會制定的標準,能夠在GPU與CPU之間實現硬件加速的遠程直接內存訪問。MRC借鑑了超以太網聯盟(UEC)研發的技術,並基於SRv6源路由對其進行能力擴展,從而支撐大規模AI網絡架構組網。
該網絡架構已依託英偉達和博通的硬件,支撐多款OpenAI模型訓練。
AMD為MRC貢獻了擁塞控制技術,以提升MRC的實際性能,且AMD已經與頭部雲服務商合作,在測試集群中大規模部署MRC,在MRC規範開發之前,AMD已有改進版RoCEv2傳輸協議的預標準實現,該協議演變為今日的MRC標準。AMD的官方新聞稿提到,其是最早且唯一在400G網卡上實現MRC的公司之一,他們可以無縫過渡到AMD Pensando「Vulcano」800G AI NIC的應用,該NIC同樣支持MRC傳輸協議。
MRC是首次在英偉達Spectrum-X以太網上驗證並優化的新傳輸協議,其故障繞過技術可以在僅幾微秒內檢測網絡路徑故障,並在硬件中自動重路由流量。英偉達官方博客提到,這種繞過失敗技術對於AI訓練集群尤為重要,因為成千上萬的GPU必須保持同步,即使是短暫的網絡中斷也可能減緩甚至中斷整個訓練任務。
博通Thor Ultra是一款面向AI負載與多平面架構網絡設計的800Gbps高性能以太網卡。該產品基於數代RoCE網卡技術打造,新增支持MRC以及高級RoCE技術。博通官方博客稱,其將這項技術與經驗投入到了MRC生態合作研發當中。Thor Ultra集成了使用網絡編程語言(NPL)實現高帶寬線率可編程數據路徑,實現先進擁塞控制(基於發送端和接收端)、負載均衡以及可靠傳輸等功能,可以降低系統成本和複雜度。
英特爾在官方X賬號發帖稱,藉助MRC技術,英特爾正構建多平面以太網組網架構,該架構可實現超大規模集群部署,同時減少交換機層級、降低功耗、提升整體可靠性。
MRC為其擴展超級計算機帶來三個關鍵優勢:
首先,該技術僅通過兩層以太網交換機,就能搭建出可承載十萬塊GPU規模超算的多平面高速網絡。這套架構具備充足冗餘能力,可平穩抵禦網絡故障;同時相比同等規模的三層、四層單平面網絡,功耗更低。
其次,MRC的自適應數據包散射具備極佳的負載均衡能力,使得網絡核心基本不會出現擁塞。
這降低了同步訓練中各數據流之間的吞吐量波動,而消除異常延遲正是同步訓練性能優化的核心關鍵。同時,即便多項任務共享同一個超算集群,彼此之間也不會產生性能干擾。
最後,MRC採用SRv6源路由快速繞過故障鏈路,僅在正常可用路徑上轉發數據包。
這使得其可以採用簡潔的靜態網絡控制面,並從根本上規避一大類動態路由特有的故障異常問題。
02.
支持多平面網絡
可實現更低成本、功耗
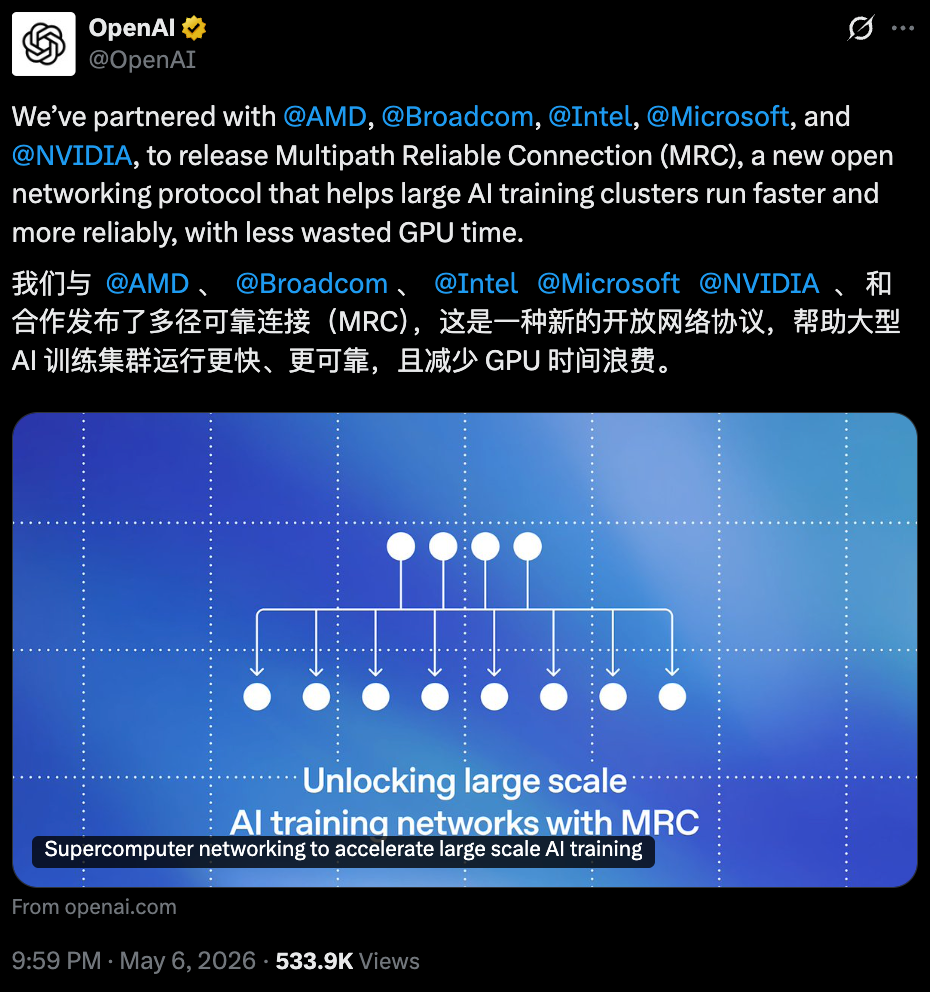
MRC採用了多平面網絡,不再把每個網絡接口視作一條800Gb/s的鏈路,而是將其拆分為多條更小粒度的子鏈路。例如,單個網絡接口可同時連接八台不同交換機。由此便可搭建八路獨立並行網絡(網絡平面),每路帶寬為100Gb/s,而非構建單一的800Gb/s網絡。
這樣做的好處是,一台原本支持64個800Gb/s端口的交換機,改用後可提供512個100Gb/s端口,藉此僅用兩層交換機就能搭建出可全互聯約 131000塊GPU的網絡;而傳統800Gb/s組網則需要三層甚至四層交換機架構。
▲支持多平面網絡
這樣設計的網絡成本、功耗都更低,且比傳統網絡設計能提供更多路徑多樣性的網絡,還允許更多流量留在第0層交換機本地,從而提升性能。
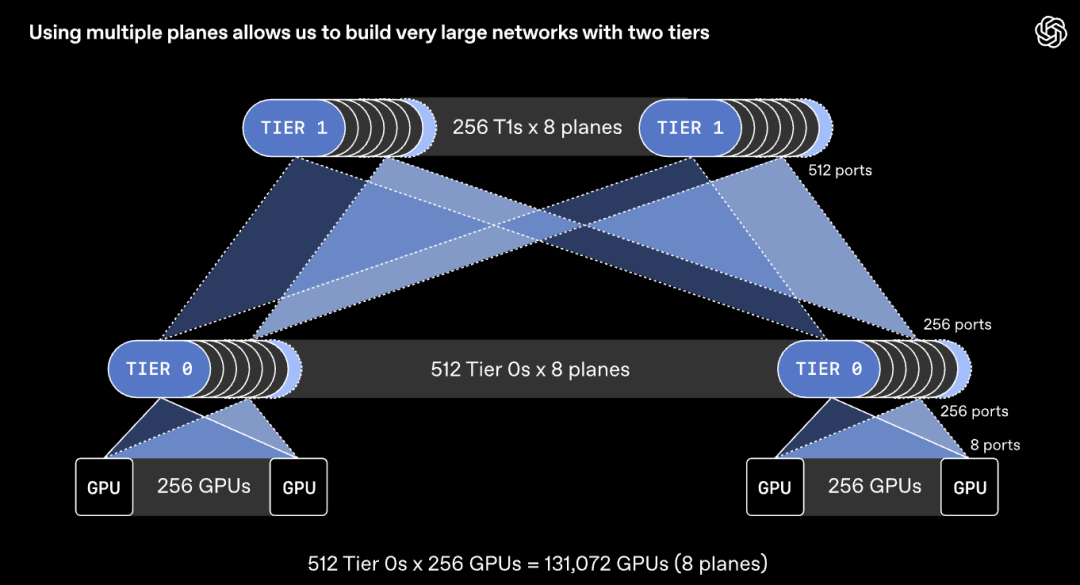
然而,這樣的路徑多樣性往往難以被充分利用。用於AI訓練的傳統網絡協議,通常要求每次數據傳輸固定走單一路徑,以保證數據包按序到達。
在大規模多平面網絡中,這會帶來兩大問題:一是不同數據流可能爭搶同一條鏈路,引發網絡擁塞;二是單條數據流只能佔用衆多網絡平面中的其中一條。如果不做針對性優化,多平面網絡反而會出現嚴重擁塞,整體性能表現會大打折扣。

▲數據包流相互碰撞導致擁塞
03.
跨數百條路徑進行數據包散射轉發
MRC從根本上改變了這一模式。
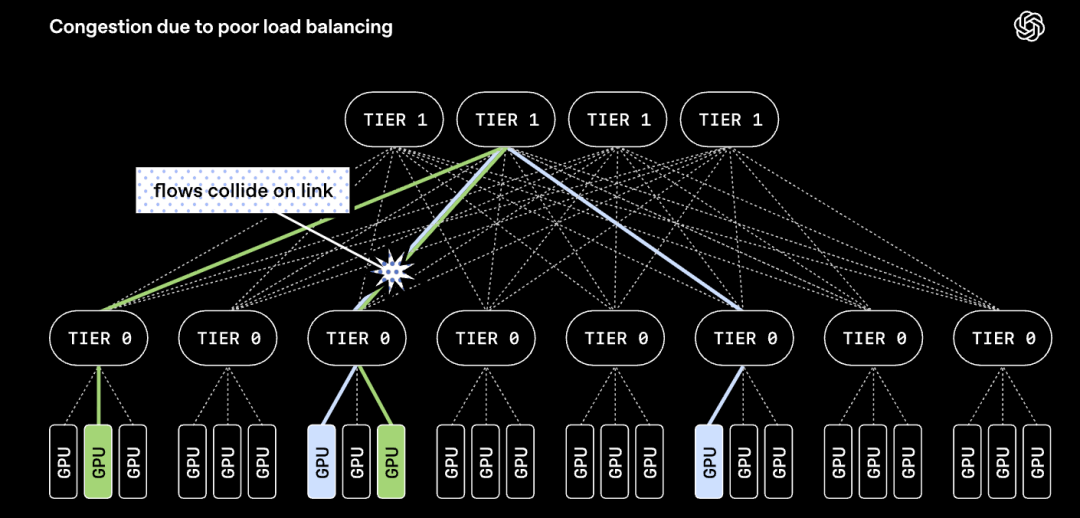
其不再將一次數據傳輸限定在單條路徑上,而是把單次傳輸的數據包分散分發到網絡中數百條路徑、跨所有獨立網絡平面並行傳輸。
數據包可以亂序到達,但所有MRC數據包都攜帶最終內存地址,因此接收端無需等待排序,可隨到隨寫入內存。
這樣一來,每條MRC連接都會為其所使用的衆多路徑維護少量狀態信息。一旦檢測到某條路徑出現擁塞,就會立刻切換至其他路徑,從而均衡全網負載。

如果發生丟包,MRC會採取穩妥策略,默認該路徑可能已出現故障,隨即立即停用該路徑,並對可能丟失的數據包進行重傳。
在淘汰某條路徑後,MRC會發送探測包覈查是否確實存在故障;若確有故障,則進一步檢測鏈路是否已經恢復。
還有一個丟包原因是目標端擁塞。MRC可以通過報文截斷機制處理這類場景:當交換機因擁塞即將丟棄報文時,並不會直接整包丟棄,而是裁減掉有效載荷,僅將報文頭部轉發至目的端,以此觸發顯式重傳請求。
並且報文截斷能夠有效減少誤判,避免把單純擁塞導致的丟包,錯誤判定為路徑故障。
結合多平面拓撲、數據包散射轉發、負載均衡與報文截斷這些機制,MRC連接能夠微秒級檢測網絡故障並完成迂迴繞行,降低對同步訓練任務的影響。相比之下,傳統網絡架構往往需要數秒甚至數十秒才能完成收斂穩定、實現故障繞行。
04.
進一步簡化網絡
一旦丟包即停止路徑
MRC在簡化網絡方面更進一步。
傳統方案中,交換機都會運行BGP(邊界網關協議)這類動態路由協議,用以計算可用路徑並實現故障迂迴。
但交換機本身結構複雜、運行的軟件也十分龐雜。一旦出現隱匿性異常,這類問題往往難以排查,還會持續引發連接中斷,直至故障修復。
採用MRC後,一旦某條路徑出現丟包,MRC便會停止使用該路徑。
其採取的方案是,關閉動態路由,轉而採用IPv6分段路由(SRv6)。SRv6允許發送端直接指定每個數據包在網絡中的轉發路徑,實現方式是將交換機標識序列嵌入每個數據包的目的地址字段。
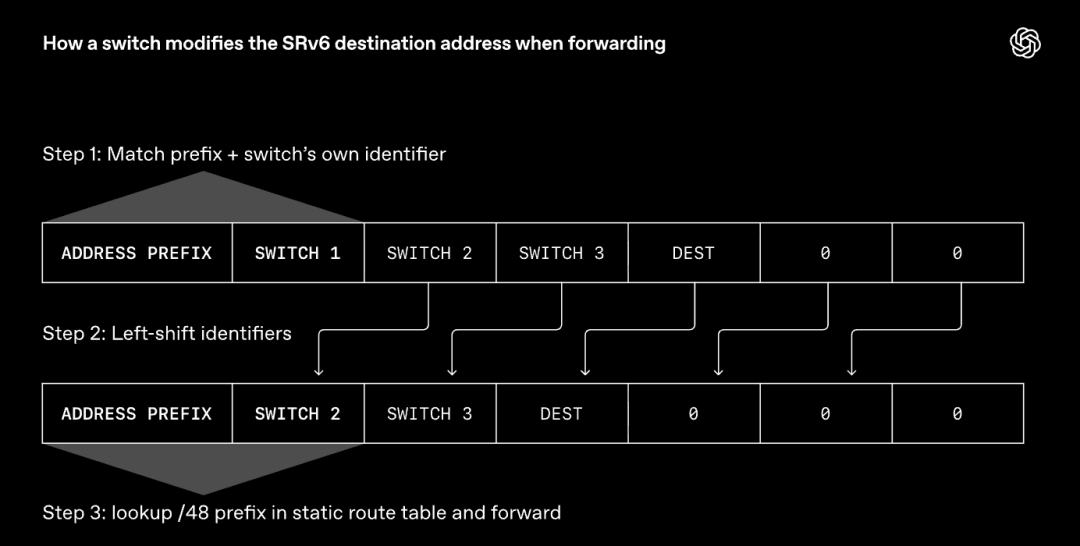
拆解原理如下:
交換機在轉發報文時,會檢查自身標識是否在路徑列表中。如果命中,就通過偏移目的地址字段移除當前自身標識,露出下一跳交換機的標識。
隨後交換機在靜態路由表中查詢該標識,據此決定報文的下一跳轉發去向。
與動態路由不同,這類靜態路由表在交換機初始配置階段一次性部署完成,後續不再變更。
MRC利用SRv6在所有網絡平面間分散分發數據包,同時在每個平面內並行使用多條路徑。一旦某條路徑發生故障,MRC直接停止選用該路徑即可。
交換機無需重新計算路由,只需嚴格按照預設的靜態路由規則進行轉發,無需額外做任何複雜處理。
05.
結語:大廠聯手
打破超算集群算力利用率瓶頸
根據官方博客,MRC顯著提升了OpenAI訓練全新大模型的能力,同時讓網絡架構能夠匹配其AI發展路線圖。
隨着訓練集群規模持續擴張,網絡設計愈發決定可用算力的實際利用率。MRC能夠讓GPU集群在遭遇擁塞、鏈路故障和運維維護時保持協同穩定運行,而這類事件在過去都會中斷訓練任務。
在超大規模算力場景下,這種可靠性與運行效率或將成為支撐前沿大模型同步訓練得以實現的基礎前提。