文|超聚焦
國民級AI應用,也要收錢了?
5月3日,據第一財經報道,字節跳動旗下AI應用「豆包」最快將於5月中下旬上線首款付費包月產品。App Store頁面顯示,付費訂閱分為三檔:標準版連續包月68元、加強版200元、專業版500元,年費最高達5088元。

針對付費會員,豆包官方回應稱,豆包始終提供免費服務,在免費服務的基礎上,豆包也在探索推出更多增值服務,相關方案細節目前還在測試階段。
有接近豆包的人士透露,付費功能將主要專注在複雜任務和生產力場景,如PPT生成、數據分析、影視製作等。隨着模型能力持續升級,產品已經能滿足越來越多的複雜高價值任務。
但此類任務需消耗更多算力與推理時間,因此豆包計劃上線付費服務,滿足好這部分複雜場景需求,免費版本則繼續面向用戶的日常使用。
為何豆包會在這個時點選擇試水付費?又能否在保障用戶體驗的同時,走通商業化的道路?
一、免費的豆包,字節也養不起了
在互聯網時代,月活人數越多代表着可變現的能力越強,大家也都信奉着一條鐵律:流量即資產,規模即壁壘。
一個App只要月活足夠高,其邊際成本就會隨着規模效應無限趨近於零。隨之而來的廣告、電商、遊戲聯運等變現手段,足以讓企業通過「羊毛出在豬身上」的模式賺得盆滿鉢滿。
但在AI時代,月活人數越多,卻可能意味着企業「破產」速度越快,其與移動互聯網核心的差異在於「邊際成本」。
傳統的圖文或短視頻分發,多一個用戶刷新信息流,服務器增加的成本微乎其微;但AI大模型是典型的「重資產、高消耗」模式,每一次對話交互、每一份長文本處理、每一張圖片的生成,AI芯片的需求都是線性增長的。
而QuestMobile發布的《2026年3月人工智能洞察》數據顯示,字節就是最「負重前行」的那個。
2026年第一季度,國內AI應用季度活躍用戶排名裏,豆包以3.4億的絕對優勢穩坐頭把交椅。排在後面的DeepSeek是1.27億,元寶5735萬,Kimi只有834萬。豆包一家的用戶量,比後面九名加起來還多。
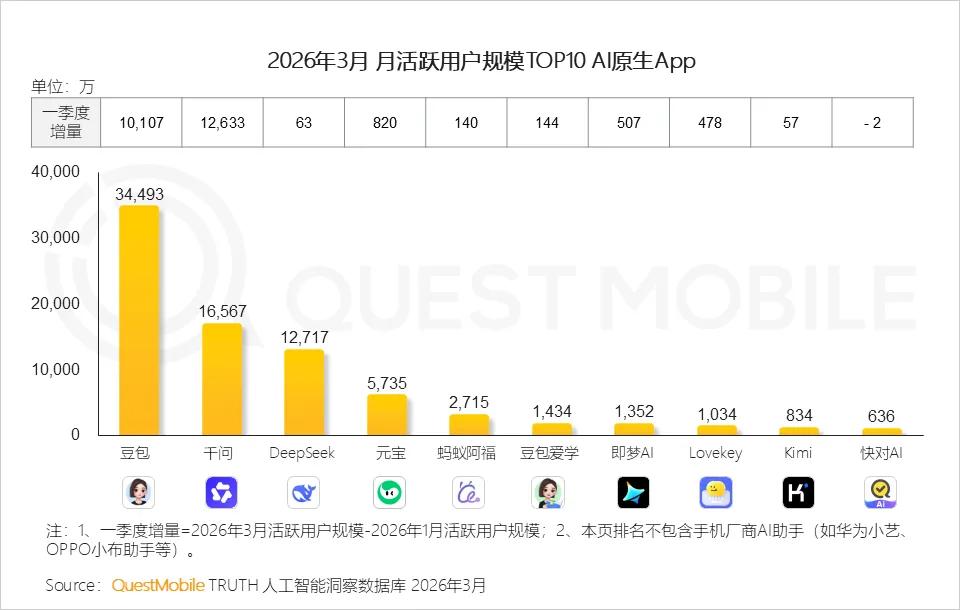
頭部地位聽起來風光,但3.4億活躍用戶背後,是每天數以億計的對話請求。每一次問答、每一次生成,都是實打實的算力消耗。用戶越多,燒錢也就越快。
但在AI時代,單純看「月活用戶數」其實已經是一種落後的估值維度了。用戶規模只是表象,真正代表算力消耗、能夠衡量大模型運轉壓力的核心指標,是AI時代的「水電煤」Token。
2024年5月,豆包大模型的日均Token消耗量還只有0.12萬億;而在不到兩年之後,這個數字已經狂飆到了驚人的120萬億。短短兩年時間,消耗量實現了1000倍的暴漲。
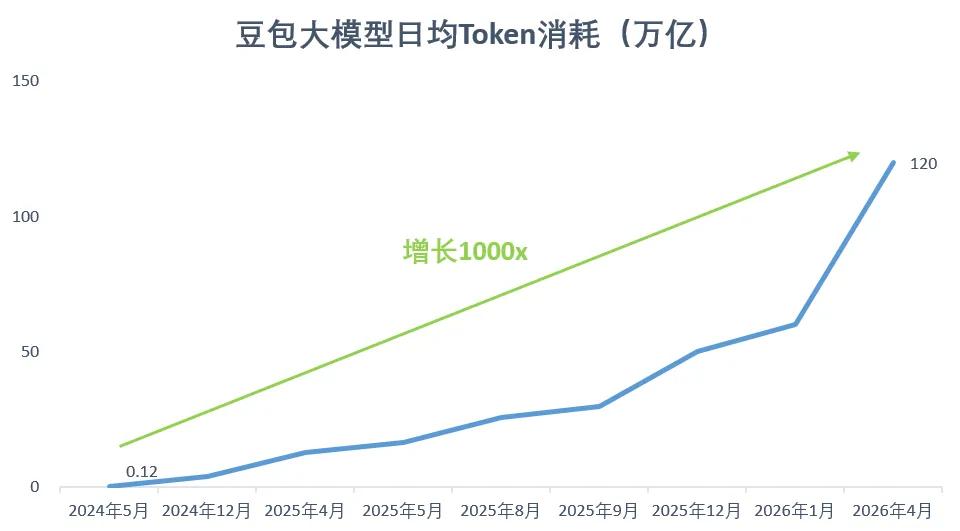
放眼全球,日均Token消耗能夠突破「百萬億」級別的,還只有OpenAI和谷歌這樣的絕對頭部玩家。
而字節憑藉豆包成功躋身了全球大模型調用量的「第一梯隊」,但也意味着它正在獨自承受着堪比硅谷巨頭的基礎設施成本壓力。這對於在國內AI基建有許多掣肘、只能購買相對落後的國產推理卡的字節來說,難度比只要有錢就能買到卡的OA和谷歌高上太多。
此外,這僅僅是國內業務跑出來的數據,完全不包含TikTok及其他海外業務部門的調用。這意味着,字節已經把算力需求拉到了一個極度誇張的水位。
支撐這日均120萬億Token吞吐的,是真金白銀的重資產投入。而到了2026年,大模型的競爭更是進一步從算法比拼,演變成了算力基礎設施軍備競賽。
從BAT過去三年的Capex走勢圖可以看出,三家大廠在2023年的資本開支還相對剋制;2024年,隨着AI戰略的全面鋪開,三家的投入開始齊頭並進地大幅增長;而到了2025年,字節的Capex就出現了明顯超過另外兩家友商的增長。
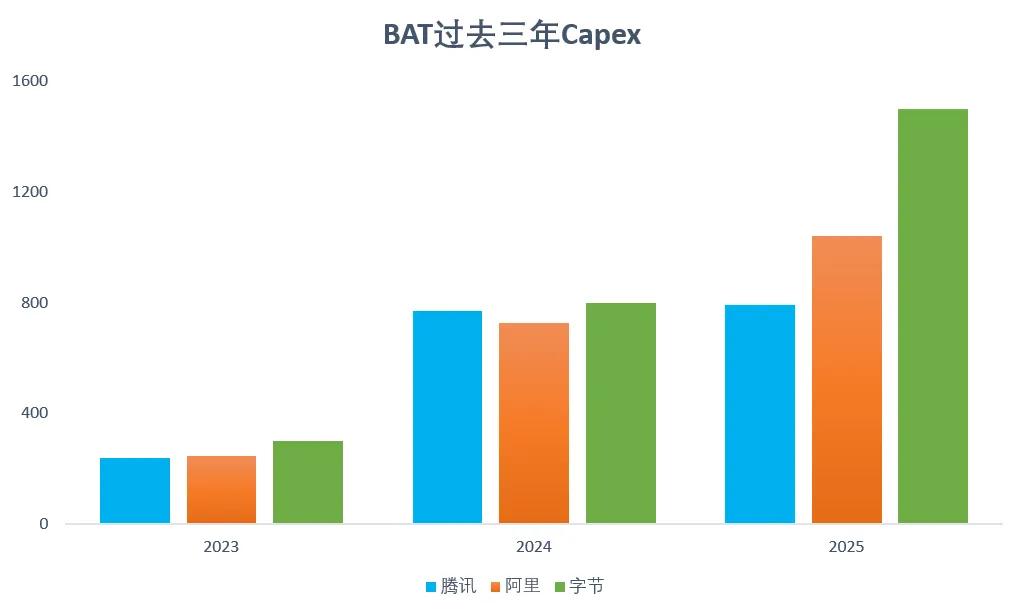
作為一家尚未上市的全球最大超級獨角獸,字節跳動不需要像阿里、騰訊那樣每個季度都要向公衆股東交出利潤答卷,也不必因為短期利潤率的下滑而面對資本市場的嚴苛拷問。這種未上市的獨立性,給予了字節在關鍵技術轉折點「大力出奇跡」的底氣。
但在絕對的重資產規模面前,即便是字節,也不可能永遠無限期地單向輸血。有產業內的資深分析師對超聚焦表示:「為了打贏這場大模型之戰,字節目前的基建投入力度,已經完全在向北美CSP看齊了。」
一邊是堪比硅谷巨頭的超重資產狂奔,一邊是國內3.4億用戶帶來的海量Token消耗。當Capex的增長曲線變得越來越陡峭時,字節面前的選擇其實只剩下一個:必須跑通高價值任務的商業化驗證。
所以,豆包在這個時點推出最高達5088元年費的專業版,並不是因為字節突然缺錢了,而是AI商業規律倒逼下的必然結果。它標誌着國內頭部大模型正式告別了「燒錢換流量」的蠻荒時代,開始向「算力成本與用戶價值相匹配」的良性商業循環過渡。
對於字節而言,開啓商業化的探索,是早晚要做出的選擇。
二、5088元的「天價」AI,字節能賣給誰?
商業化的動機雖然理順了,但「應該收錢」和「怎麼收錢」,不是一碼事。
站在2026年審視豆包的會員策略,字節遇到的最大問題,是在習慣了免費的中國市場,究竟誰會為一個通用的國產大模型支付高達5000元的年費?
坦白講,真正對AI有極度重度生產力需求的高淨值人群,為了追求極致的推理邏輯或代碼生成,這批覈心用戶往往會想方設法去購買Claude、ChatGPT或是Gemini的服務。國內大模型作為核心生產力工具的能力和心智,在專業用戶圈層中尚未建立。
而從用途上來說,放眼全球AI應用市場,目前唯一能讓用戶和企業心甘情願掏出真金白銀的驅動力,也只有Coding。
近期,Anthropic公布的年化收入反超了OpenAI。支撐這場逆襲的,正是Claude在Coding場景下的絕對統治力,它證明了,在當下的大模型賽道,「敲代碼」纔是唯一跑通了海量變現的殺手級場景。
相比之下,豆包拿什麼來支撐高達五千元年費的溢價?
誠然,今年2月發布的Seedance 2.0,讓字節向外界狠狠秀了一把肌肉。作為業界頂流的音視頻聯合生成大模型,Seedance 2.0的確拔高了豆包在多模態領域的上限,也讓外界看到了字節在視頻生成上的恐怖實力。
但視頻生成終究是個偏低頻的創意場景,豆包真的足以像Coding那樣,成為普通人每日必不可少的剛需,從而支撐起如此高昂的連續訂閱費嗎?答案顯然要打個問號。
更何況,中國用戶是一直以來都是「先上車後補票」,習慣了「白嫖」的用戶群體,不像北美、歐洲有B2C軟件付費基因,想從中國C端用戶口袋裏面掏錢不是件容易事。
在豆包之前已經有Kimi幾乎跑通了2C會員制的道路,但問題就是,豆包的體量、用戶群體和Kimi是完全不同的。
Kimi作為國內最早跑通付大模型費模式的先行者,目前仍然經歷着嚴重的免費與付費用戶之間的「零和博弈」,在巨大的算力缺口下,免費用戶的體驗幾乎已經被「戰略放棄」。
在各大社交平台上,關於Kimi「變笨」和「罰站」的吐槽幾乎成了日更貼。
一位大模型作為生產力的用戶就曾公開抱怨:「我其實是習慣用Gemini的,但這幾個月來明顯感覺到降智了,就開始嘗試國內的大模型了,Kimi確實很好用,就是算力有些捉急了。」
「我一開始用免費版,上傳一份幾十頁的PDF經常一直提示‘Kimi有點累了’,後來充了49元的月會員,以為終於能暢通無阻了,結果用高級Agent並行處理幾份研報數據時,沒用幾下就提示觸發了資源限制,需要等3個小時的CD才能恢復。花錢買生產力工具,結果用起來像打遊戲一樣還要等技能冷卻,體驗極其割裂。」
要知道Kimi的月活不過800多萬,在這樣的體量下算力分配就已經捉襟見肘到了如此地步。而豆包面對的,是高達3.45億的月活。這種算力分配的困境一旦爆發,絕對會被無限放大。
如果豆包為了保住5000元專業版客戶的體驗,將核心計算資源向付費VIP進行大幅傾斜,那麼龐大的免費基本盤勢必面臨響應遲緩、智商「降級」的災難體驗。對於一款靠國民級流量起家的產品而言,一旦免費用戶的口碑崩塌,其賴以生存的護城河可能迎來決堤的風險。
反之,如果在AI原生雲的底層架構調度上做不到嚴格的算力隔離,怎麼保證花了大價錢的付費用戶會甘心和3億免費用戶一起在晚高峯排隊等待生成?如果兼顧免費,付費用戶又能獲得多少實質性的算力躍升?這都是擺在台面上的現實。
在評估豆包的用戶變現潛力時,其用戶結構與付費意願也值得探究。
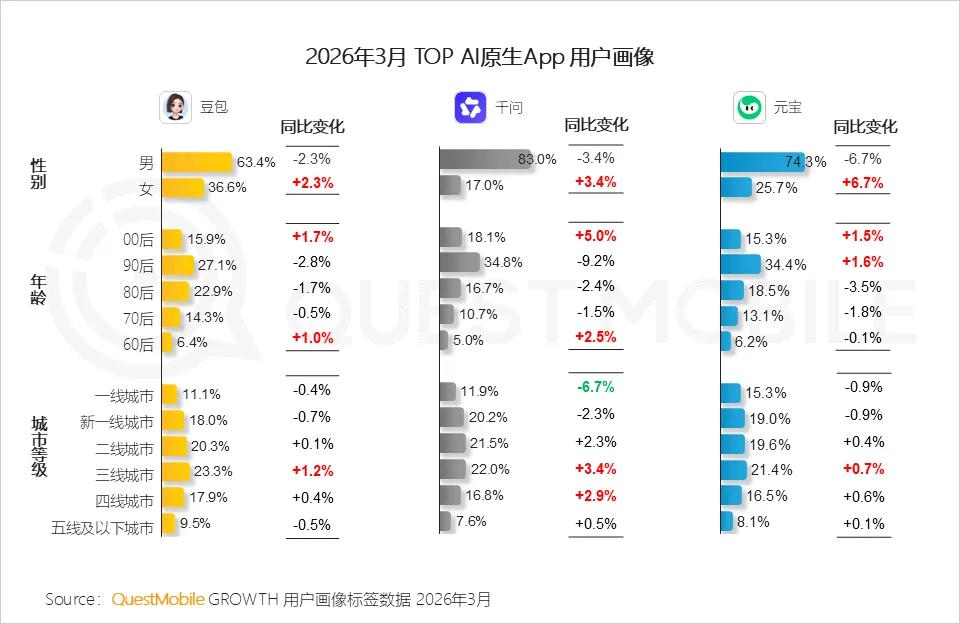
據QuestMobile數據,截至2026年3月,與千問和元寶相比,豆包60-80後(即45-65歲群體佔比更高),四線和五線城市用戶的佔比分別達到17.9%和9.5%,其TGI指數(目標群體指數)更高,表明對下沉市場用戶的吸引力顯著高於平均水平。
Kimi之所以能跑通付費,是因為它在過去兩年中依靠超長文本的硬核功能,在冷啓動階段就精準圈粉了一二線城市的白領、研究員和大學生。這批人有真實的生產力焦慮,且本就具備為AI SaaS工具買單的習慣。
除了用戶畫像的挑戰,巨大的算力消耗也構成了商業化的剛性約束。
據火山引擎公布的數據,截至2025年12月,豆包大模型的日均Token使用量已突破50萬億,較去年同期增長超過10倍,基於當前架構維持如此規模的實時推理,每日硬件及能耗成本可達數百萬元量級。
在此背景下,上架68元/月起的會員方案,從收入模型來看,若以現有活躍用戶結構為基礎,即使實現1%的付費滲透率,其月度訂閱收入也較難覆蓋推理成本。
所以,豆包會員的推出,在當前階段更像是字節一次建立在垂直場景上的戰略探路。
先把收銀台建起來,把商業化的管道打通,以此來摸底市場的真實付費水位。未來隨着大模型能力的進一步爬坡,再逐步把更多具備不可替代性的增值服務裝進這個框架裏。
至於這條路最終能走多寬,就看字節的算力基建和模型迭代速度,能不能跑贏這場曠日持久的消耗戰了。