智東西
編譯 | 劉煜
編輯 | 陳駿達
智東西5月9日報道,今日,百度推出新一代基礎模型文心5.1。百度稱,文心5.1將總參數壓縮至約1/3、激活參數壓縮至約1/2,使用業界同規模模型約6%的預訓練成本,實現同級別模型基礎效果領先。不過,百度並未明確說明這一「6%成本」的具體對標模型範圍與口徑。
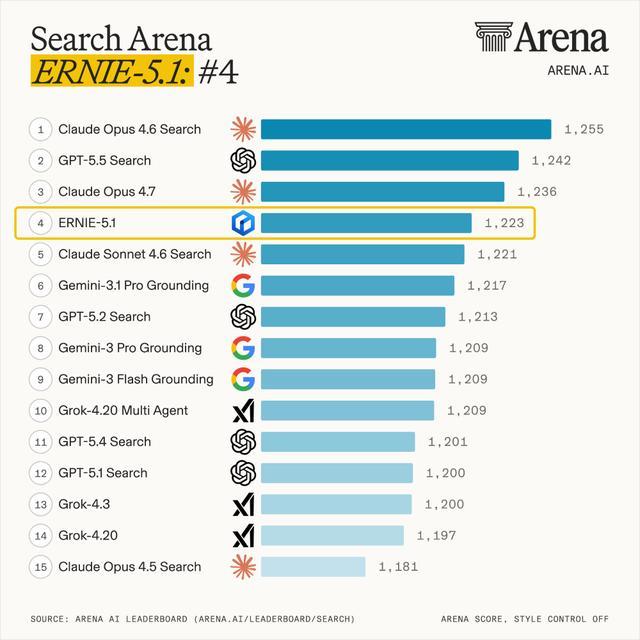
在LMArena 5月7日更新的文本生成大模型排行榜中,文心5.1全球總排名第14。與前面OpenAI、xAI的模型相比,得分存在微小差距。
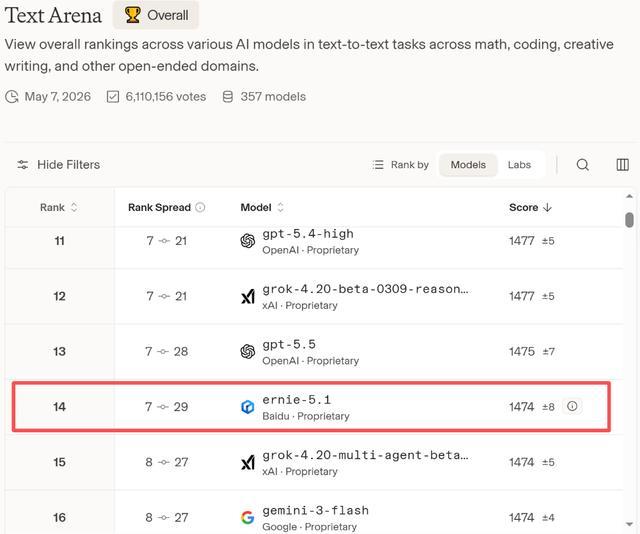
圖源:LMArena官網
文心5.1在Agentic、知識、推理、指令遵循能力測試中,與DeepSeek-V4-Pro、Claude-Opus-4.6及Gemini-3.1 Pro展開了橫向性能對比。
Agentic能力測試中,文心5.1工具調用數學推理能力表現不錯,得分略低於Gemini-3.1 Pro排名第二。多輪工具協作交互能力弱於Claude-Opus-4.6居於第二位,與另外兩個模型能力差距較小。
在深度搜索Agent任務中,文心5.1較其他三款模型仍有差距,電子表格工具操作僅領先DeepSeek-V4-Pro,大幅落後Claude-Opus-4.6與Gemini-3.1 Pro。
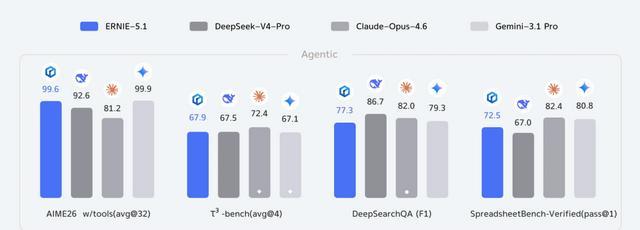
圖源:百度文心公衆號
知識、推理、指令遵循能力測試中,文心5.1整體處於中等水平。高階學科知識推理(GPQA)和複雜指令遵循(AdvanceIF)表現較好,僅次於Gemini-3.1 Pro,領先另外兩款模型。
純數學推理(AIME26)和通用知識問答(MMLU-Pro)在四款模型中均排名末位,與頭部模型差距相對明顯。
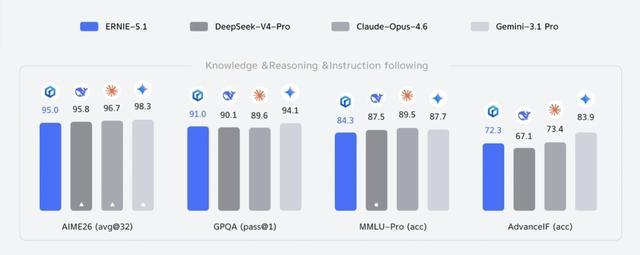
圖源:百度文心公衆號
此次文心5.1推出距離文心5.0正式版上線已時隔三個多月。文心5.1模型發布時,登頂LMArena排行榜裏國內大模型搜索能力榜首位。
圖源:百度文心公衆號
實際評測中,我們從創意寫作、數學推理、信息整合、電子表格操作、編程能力五個維度對文心5.1模型進行了綜合體驗。
其中,創意寫作與電子表格數據分析我們均採用文心5.1思考模型進行二次實測。相比文心5.1快速模型,思考模型產出的內容敘事風格更有質感、情感調性更細膩自然,也未出現基礎性邏輯與文字錯誤;在表格數據分析任務上,思考模型的整體表現同樣更出色。
文心5.1對概率題的解答步驟嚴謹、答案准確;面對開放式模糊需求,能自主拆解任務、輸出表格對比和場景匹配,信息整合能力不錯;但在編程場景中短板突出,生成的代碼無法正常運行,實用編程能力仍有欠缺。
文心5.1模型的體驗鏈接為:
https://yiyan.baidu.com
以下是我們的完整體驗過程:
一、五大場景實測:文心5.1創作、數理、辦公、科普能力全面驗證
案例一:創意寫作能力測試,考察文心5.1故事架構與文學創作能力
針對文心5.1的創意寫作能力,我們首先用文心5.1快速模型進行了測評。
指令一:請為一個懸疑故事寫出前三章大綱,每章150字左右。

總體來看這個懸疑故事的大綱挺完整,敘事結構比較規整,邏輯層次也清晰。人物行動動機比較合理,線索設定具象可落地,最後的身份反轉顛覆感比較強,伏筆呼應也相對完整。不過,與現在市面上的流行的懸疑推理小說還有一定差距,對於模型本身來講,這個水準還不錯。
而後我們用相同的指令,對文心5.1思考模型進行評測。

可以看到,第二篇在切入點、恐怖感上更有新意。對於短篇驚悚故事,這篇的「循環替身」更適合直接收尾,有《恐怖遊輪》的循環壓迫感。不過普通租客為何能查物業記錄這一點可能是個bug。
我們接着讓文心5.1快速模型寫了一篇科幻類型的微小說。
指令二:寫一篇500-600字的科幻微小說。

這篇科幻小說篇幅把控精準,敘事結構完整閉環,人物情感刻畫比較細膩,整體文字流暢、故事完成度也挺高。但這個敘事框架比較常規,同時出現了人物身份混亂,比如文章主角之一是「爸爸」,可在中間的對話中卻說成了「媽媽」。
對於常讀同類科幻故事的讀者來說,劇情走向和結局伏筆可能略顯套路化,缺少出人意料的設定創新。
相同的科幻微小說指令也給了文心5.1思考模型。

可以看到,這一篇也是圍繞「意識上傳」這一經典科幻母題展開的。不過兩篇文章在敘事重心、情感落點、科幻設定和審美取向上存在明顯差異。比第一篇更好一點的是,這一篇沒有出現明顯的人設混亂問題。
從情感共鳴和敘事感染力看,第一篇相對更好。從科幻構思的新穎度和哲學深度看,第二篇略勝一籌。
案例二:給高考數學題,看它能不能按步驟算明白
用戶在使用AI解決數學問題時,痛點比較明確:怕AI沒有邏輯硬算,也擔心AI編造解題步驟和錯誤答案。
於是,我給了文心5.1一道2025新高考一卷的上數學題,看它是否能真正解決用戶遇到的數學問題。
題目為:一個箱子裏有5個球,分別以1~5標號,若有放回取三次,記至少取出一次的球的個數為X,則E(X)為?

文心5.1給出了完全正確的解答,無論是使用指示變量法,還是用分佈法進行交叉驗證,都步驟完整,並且結果準確。
案例三:問兩款大模型怎麼選,看它能不能替普通人做信息整合
普通用戶可能不會區分主流大模型強弱,也不知道按自身場景該怎麼選用。對標文心5.1官方Agent能力裏T³-bench多輪工具協作、深度信息檢索整合的核心維度,我們拋出模糊需求,看看文心怎麼解答。
問題為:我想了解DeepSeek-V4-Pro、Claude-Opus-4.6到底各有什麼強項和短板,普通人該怎麼選、各自適合拿來幹什麼。

可以看到,文心5.1的整體回答表現優秀。首先能夠自主拆解任務邏輯,無需人工指引,自發多維度逐層解釋對比,信息維度全面且細分精準,體現出不錯的信息檢索與歸納能力。
同時貼合了普通人使用習慣,做成表格對比、場景匹配、分人群推薦,最後還點明兩款模型的隱藏短板和使用誤區,給到務實的組合使用建議。
案例四:電子表格與職場數據分析能力測試
職場運營、門店管理、電商運營日常高頻剛需就是員工績效統計、數據篩選、業績排名、均值分析,常用到的是Excel表格來進行辦公。於是我們測試了文心5.1快速版本的電子表格工具操作能力。
需求為:我是門店運營,統計了本店10名銷售人員的當月個人成交業績:12.3萬、18.6萬、9.2萬、25.8萬、16.5萬、11.8萬、20.4萬、8.7萬、22.1萬、14.6萬。
你按照Excel分析數據幫我處理:整理成規範員工業績數據表,計算全員業績平均值、中位數,篩選出業績高於平均值的優秀員工,最後結合整體數據做簡單的團隊績效分析。
結果是,文心5.1在這個電子表格操作以及數據分析任務中,完成度挺高。不過沒有將所有數據放在一張表格裏。
於是我們繼續給出指令:幫我做成一份直觀的Excel表格,包含所有數據,同時可複製。文心5.1給的反饋比最初更精簡了,但指令「一份」可能給該模型帶來了理解誤差。
於是我們再調整指令為:把這些數據僅用同一張表格來顯示。

最後,文心5.1給出的結果還不錯,雖然官方測試中表格操作能力排名靠後,但在文本形態的職場數據分析場景裏,實際體驗並沒有特別差勁,能完成基礎需求。
該模型結果輸出比較磕絆,於是我們用相同的指令測試文心5.1思考模型。結果顯示,這次模型輸出的第一份結果更為簡潔規範,並且更為清晰直觀。與文心5.1快速模型第三次輸出的結果幾乎一樣。
案例五:
我們使用文心5.1思考模型,讓它製作了一個大型沙盒遊戲與小型跑酷遊戲。
指令一:製作一個單文件HTML的3D橫版格鬥遊戲,場景為被霸天虎入侵的破敗城市地圖,敵人為類人型賽博坦機器人,包含武器後坐力效果,採用低多邊形風格並帶有卡通美學。遊戲開始時,玩家位於街道上,周圍有建築廢墟;遊戲中應包含可被擊倒的細節物品,如汽車、樹木、石塊/瓦礫和自動售貨機。玩家可以選擇5種擎天柱陣營角色進行遊戲,並與5種霸天虎變種敵人戰鬥,這些敵人會不斷生成,遊戲為無限時間的沙盒模式。
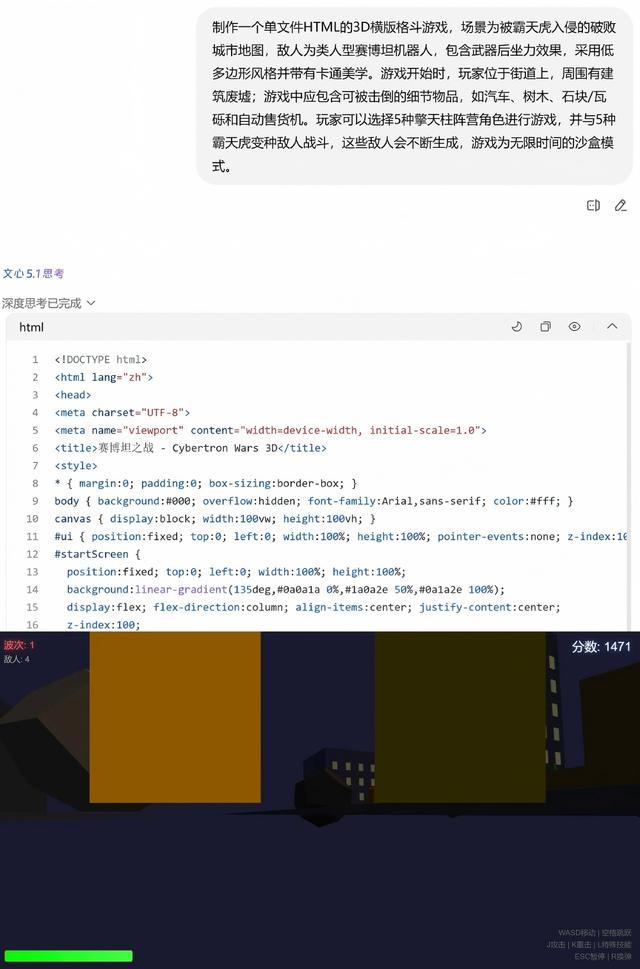
文心5.1思考模型針對該指令生成了700餘行代碼,但實際運行時,該遊戲能夠正常打開,但界面出現兩個遮擋bug,也沒法對遊戲裏的敵人進行攻擊,無法操作。
指令二:製作一個單文件HTML的橫版跑酷遊戲,不依賴外部資源。主角是一名未來都市快遞員,在霓虹城市屋頂之間不斷前進。遊戲採用低多邊形風格,整體偏明亮卡通美術。
要求:
-玩家可進行跳躍、二段跳和下滑
-地圖自動向前滾動,包含屋頂缺口、廣告牌、電箱、無人機等障礙
-路上有可收集的能量電池和金幣
-玩家可以拾取臨時道具,例如護盾、加速和磁鐵吸附
-敵人為巡邏無人機和機械警衛,碰撞後會扣血-分數根據生存時間、移動距離和收集物計算-淑戲失敗後可重新開始
-需要有開始界面、暫停功能和簡單UI(血量、分數、速度)
-所有內容寫在一個HTML文件中,代碼可直接運行
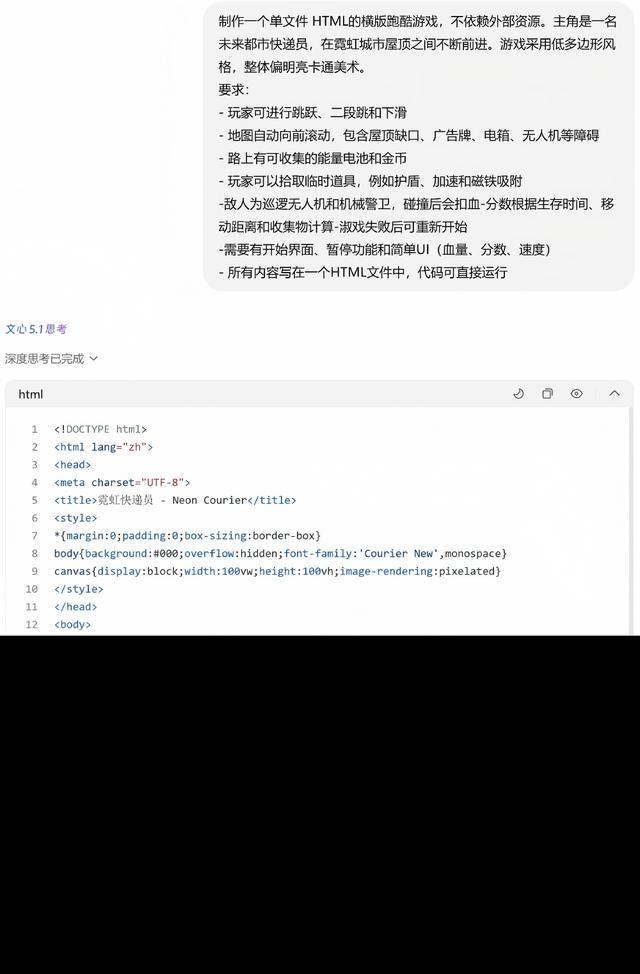
針對第二個指令,該模型耗時3分鐘生成600餘行代碼,但無法打開,界面一片漆黑。可見,該模型在複雜遊戲編程與代碼可運行性上仍存在明顯短板。
二、彈性訓練實現降本,架構與後訓練流程同步革新
文心5.1是在文心5.0基礎上進一步優化得到的版本。它沒有從頭重新訓練,而是從文心5.0訓練好的子模型矩陣中,挑出一個效果最好的子結構直接使用,因此降低了預訓練成本。
其背後的主要技術更新,是一套叫Once-for-All的彈性訓練方法。
傳統做法想適配不同規模的模型,得分別預訓練好幾次;而文心5.0只在一次預訓練裏,通過動態採樣同時優化大量不同尺寸的子模型,最終形成一個覆蓋多種參數規模、不同計算成本的子模型矩陣。
也就是說,這套方法讓文心5.1在訓練階段就把不同模型一次性準備好,上線時直接挑一個最合適的來用,不用每次重新練。
基於上面的彈性訓練方法,文心5.1在參數和成本上的實際變化如下:
1、總參數量壓縮到文心5.0的1/3左右;2、激活參數量壓縮到約1/2;3、預訓練算力成本僅為同規模業界模型的6%。
相比文心5.0,文心5.1推理成本明顯下降,同時在同參數規模下,預訓練模型效果在同規模模型中表現更佳。
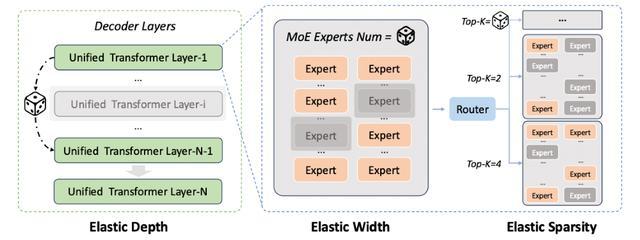
文心5.0彈性訓練示意圖(圖源:百度文心公衆號)
此次更新,文心5.1在其訓練方式上做了三方面改動:
首先是分離式架構。以前訓練、推理、獎勵計算、智能體循環四個環節耦合在一起,一個環節慢了會拖累整個系統。
現在百度將它們完全拆開,各自獨立部署、獨立擴縮容。比如推理算力不夠就只擴推理,不用動其他模塊。各模塊之間通過高性能網絡傳數據,控制流和數據流分開,流水線可以重疊執行,訓練整體耗時更短。
其次是FP8訓推方面。由於模型訓練時和推理時用的精度不一致,會導致效果下降,尤其在MoE結構里路由偏差更明顯。
於是文心5.1用了統一FP8低精度算子庫,並對Rollout Router Replay技術做了優化。結果是在開啓該技術後,訓練推理耗時幾乎沒有增加,但關鍵指標KL散度下降50%,訓練更穩定。
最後是異構彈性調度方面。集群裏會存在很多CPU算力閒置,文心5.1把這些CPU統一池化,用來跑代碼沙箱、驗證器這類邏輯計算密集但不需要GPU的任務。提升了資源利用率,也縮短了訓練迭代時間。
傳統大語言模型的後訓練是串行流程:先做監督微調(SFT),再做多階段混合強化學習。
這種方式存在兩個問題:一是慢,一個階段等一個階段拖慢整體迭代;二是能力會「打架」,想在一次訓練裏同時提升代碼、推理、對話等多個能力,往往提升一個另一個就下降。
文心5.1的做法是把專家訓練和能力融合拆開,分四步走:
第一階段統一SFT。先用高質量的多領域指令數據做一次基礎微調,讓模型具備基本的指令遵循和工具調用能力,作為後續能力擴展的起點。
第二個階段,並行訓練多個領域的專家模型,比如對代碼、推理、智能體等方向分別獨立訓練。每個方向用自己專屬的獎勵信號和算法,互相不干擾。
第三個階段是在線策略蒸餾(OPD)。把上一步訓練好的多個專家模型當老師,統一SFT模型當學生。學生按照自己的策略採樣,通過token級KL方法同時學習多個老師的能力,把不同專家的能力融合進同一個模型裏。
最後是通用在線強化學習。並不是所有任務都適合用蒸餾來融合,比如開放式聊天、創意寫作這類高熵分佈的任務,蒸餾反而效率低,輸出會變得過於平滑。所以這類任務不做蒸餾,而是在蒸餾後的模型上單獨做在線強化學習,保證對話多樣性、指令遵循能力和人類偏好對齊。
可以簡單總結為,代碼、推理這類確定性強的能力,通過蒸餾從專家模型融進主模型;聊天、寫作這類需要多樣性的能力不適合蒸餾,單獨做強化學習。兩套方式配合,既縮短了訓練周期,又避免了能力互相拖累。
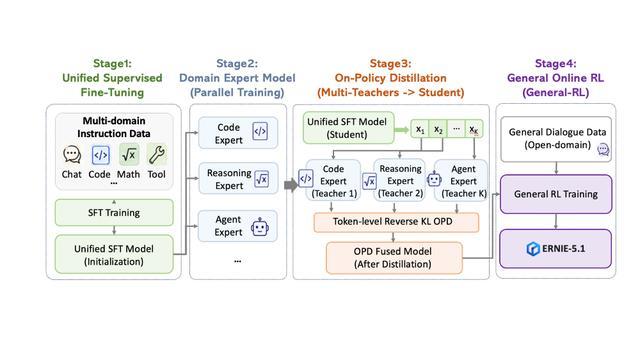
文心5.1後訓練Pipeline示意圖(圖源:百度文心公衆號)
在百度文心內部評測中,文心5.1的創意寫作能力接近Gemini-3.1 Pro。此前文心5.0系列模型已多次登上LMArena文本榜和視覺理解榜,穩居國產模型第一梯隊。
結語:低成本實現性能追趕,能力尚有提升空間
文心5.1最引人注目的不是某一項能力的躍升,而是它試圖回答的問題,能否用更低的訓練成本,換來接近頭部模型的綜合水準。
從百度文心披露的數據看,在知識推理、指令遵循和創意寫作上,它確實站到了同量級模型的第一梯隊;但在工具調用深度、電子表格操作和純數學推理上,與Claude-Opus-4.6、Gemini-3.1 Pro等模型之間仍存在可量化的差距。
從實際體驗來看,文心5.1在數學題解答、生活化知識科普等面向普通用戶的場景中表現比較穩定,信息整合和邏輯拆解能力也可圈可點。創意內容存在套路化問題,高階表格辦公能力相對偏弱,部分場景需要反覆調整指令才能達到理想效果。
縱觀行業,主流模型逐漸呈現能力差異化、使用場景分層化的發展趨勢。對普通用戶而言,成熟的基礎模型能夠降低內容創作、問題解答、數據整理的門檻,提升日常使用效率;對技術廠商而言,低成本、高性能的迭代方案,也將為國產大模型輕量化落地、規模化應用提供了可行路徑。