
作者|江宇
編輯|漠影
智東西5月15日報道,昨日,豆包輸入法macOS版正式上線,用戶終於可以在電腦上直接「張嘴打字」了。
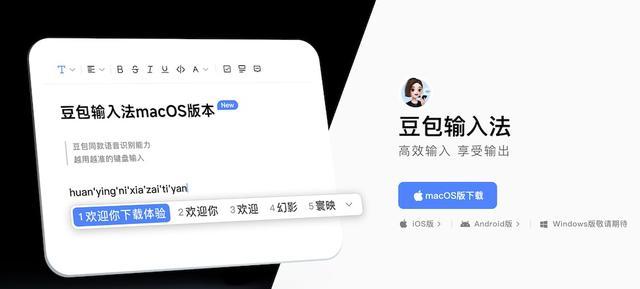
和傳統輸入法裏的「語音轉文字」功能不同,這次豆包輸入法主打的,是一整套AI語音輸入能力。
其背後採用的是豆包App同款語音模型,重點強調「邊說邊出字」「中英文混說」「智能糾錯」和「長文本輸入」等能力。
目前,豆包輸入法支持在任意對話框中實時語音轉文字,且沒有時長限制,適合長文案、小說、會議記錄等持續輸入場景。
同時,它還支持中英文混說、多種方言識別,無需手動切換輸入法,可自動識別語言。
在AI能力部分,豆包輸入法加入了「智能糾錯」和「個性化記憶」功能,其能夠自動修正部分語氣詞、語病和口誤,並逐漸記住用戶的改詞習慣,讓語音輸入越用越準。
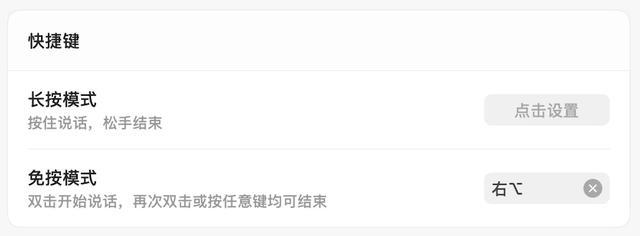
此外,豆包輸入法還支持輕聲識別和抗噪能力,在辦公室、咖啡店、圖書館等環境中,也能進行低音量輸入。交互模式上,則提供「長按」和「免按」兩種方案。
某種程度上,AI語音輸入正在成為新的輸入趨勢。過去,語音輸入更多還是手機上的「臨時替代方案」,但隨着Vibe Coding等場景越來越普及,很多用戶開始長時間「和電腦說話」。
目前,市面上已經出現了微信輸入法、智譜AI輸入法(小凹)以及Typeless等AI語音輸入產品,其中不少已經開始收費。相比之下,豆包輸入法目前免費推出,這或許也會成為它吸引用戶的一大優勢。
那麼問題來了:豆包輸入法,真的好用嗎?
這次,我們從延時、中文準確率、中英文混說、方言識別、智能糾錯以及個性化記憶幾個維度,對它進行了實測。
一、普通話幾乎邊說邊出,粵語還在等AI「補作業」
語音輸入最核心的問題,其實只有一個:跟不跟得上人說話。
在普通話場景下,豆包輸入法整體表現還是比較流暢的。無論是短句、長句,還是中英文混說,基本都能做到「邊說邊出字」。
主觀感受下來,它的首字延遲大概會略高於1秒,完整句子的生成延遲通常會控制在1秒以內。而且在連續長文本輸入過程中,它的整體卡頓感並不明顯。
但到了方言場景,尤其是粵語等複雜方言,體驗就會大不相同。它不像普通話那樣一句話剛說完立刻就能識別,反而是「先聽一遍,再靠AI後處理」。
很多時候,前半句幾乎沒識別出來,後面纔開始通過上下文一點點修正。部分長句甚至會出現超過5秒以上的完整句延遲。
原句(粵語):譁,出面做乜突然間落咁大雨嘅?系囉,明明頭先仲好地地。死火,我趕住出去呀。不過依家大風大雨,好易溼身㗎。唔使驚!我帶咗遮同埋雨褸添。都系你夠醒目!
對應普通話:「哇,外面怎麼突然下這麼大雨?就是啊,明明剛纔還好好的。糟糕了,我趕着要出去呀。蕭漢過現在風大雨大,很容易溼身的。不用怕!我帶了傘還有雨衣呢。還是你夠聰明!」

比如在我們的測試中,第一句「哇,出面做乜突然間落咁大雨?」其實被完整識別了出來,準確度是沒有問題的。
但到了後半段,識別結果就開始出現較大偏差,大部分內容都沒有正確識別出來。
東北話的表現則明顯更穩定一些。在我們的測試裏,除了「旮沓」等個別詞彙出現問題之外,其餘內容大體都能正常識別。
原句(東北話):哎呀媽呀,咱東北這旮沓老好了,那雪下的老大了,跟棉花套子似的。凍梨啃一口,甜滋滋的,拔涼拔涼的。鐵鍋燉大鵝,那香味老霸道了。

閩南語則基本屬於「困難模式」。目前識別效果仍較差,很多句子幾乎無法正確轉寫。
當然,這本身也是整個行業裏最難的問題之一。不同方言之間,口音、連讀和詞彙差異本來就很大。如果你本身會說方言,或許也可以自己試試看,它到底能聽懂多少。
二、甄嬛傳名場面沒翻車,但外國人名還是有點難
中文準確率,是這類產品另一個核心能力。
這次,我們專門選了兩個「難題」。
第一個,是《甄嬛傳》「滴血認親」名場面。因為文言式表達、人物稱謂、停頓節奏和長句結構,本身都比較複雜,對語音識別其實很不友好。
原話:臣妾要告發熹貴妃私通,混亂後宮,罪不容誅。宮規森嚴,祺貴人不得信口雌黃。臣妾若有半句虛言,便叫五雷轟頂,永不超生。我還以為是什麼毒誓呢,生死之事誰又能知啊?可見祺貴人不是真心的了。臣妾以瓜爾佳氏一族起哲,若有半句虛言全族無後而終。

但實際測試下來,豆包輸入法的表現比預期更穩定。它在長文本輸出過程中,能夠持續進行動態修正。包括人稱、斷句、標點,甚至部分誤讀內容,都會在後續識別過程中不斷調整。
最終結果裏,文言表達、標點符號和整體句意沒有錯誤。這種「邊識別邊回改」的機制,近乎可以看成AI寫作過程中的實時潤色。
第二個測試,則是科技新聞場景。我們讀了一段關於「馬斯克訴奧爾特曼案第三周庭審」的內容,重點測試它對外國人名的識別能力。
這一部分難度更高。因為很多英文人名本身就存在多種中文譯法,而且中文互聯網裏也沒有統一標準。
原話:馬斯克訴奧爾特曼案進入第三周,被告方關鍵證人相繼出庭,微軟CEO薩提亞·納德拉、OpenAI聯合創始人兼前首席科學家伊利亞·蘇茨克維,以及OpenAI基金會董事會主席佈雷特·泰勒作證。此前在第二周庭審中,馬斯克方主導舉證,OpenAI前CTO米拉·穆拉蒂、前董事海倫·託納、塔莎·麥考利、前員工羅茜·坎貝爾,以及非營利治理專家戴維·希澤等證人的證詞和庭審材料陸續浮出。

實際結果裏,部分名字能夠正確識別,但也出現了譯名不統一的問題。比如「戴維·希澤(David Schizer)」並沒有被識別成常見譯名,部分外國人名中間的分隔點「·」也出現缺失。
日常聊天問題不大,但如果是新聞寫作、法律文件或正式場景,後續還是需要人工再覈對一遍。
三、中英文混說準確率很高,「外企黑話」也能聽懂
如果說方言是困難模式,那中英文混說,則是豆包輸入法目前完成度較高的一部分。
無論是人名、英文縮寫,還是各種辦公場景的常用語,它都能較穩定地識別出來。而且,它對於中英文切換時的斷句和標點處理,也比傳統輸入法自然很多。
原句:Jennifer,晚上跟Global的會議改到明天早晨7點,你記得reschedule一下。還有換個大點的meeting room,因為FinanceEric and HR的Susie也要參加,還有提前把要講的topic再go through一遍。辛苦跟Laura說下,會上幫忙記下meeting minutes。so far我就想起這麼多,如果有新的update我再跟你sync。

很多時候,用戶輸出並不需要刻意放慢語速。整體主觀感受下來,中英文混說場景的準確率,大概率已經可以穩定達到95%以上。
對於外企辦公的人來說,這部分功能其實是比較實用的。
四、能清理語氣詞,但暫時還不會「主動潤色」
相比識別能力,「智能糾錯」其實是這次最讓人期待的功能之一。它涉及一個問題:AI到底應該「忠實記錄」,還是主動讓AI幫你改。
從實際測試來看,豆包輸入法目前整體偏向前者。比如一些簡單語氣詞,像「嗯」和「呃」之類,它確實可以自動清理。
但更復雜的口語化重複、邏輯跳躍或者臨時改句,它目前還不會主動幫你重寫。
例如們在測試時說:「我想11點……不對,是11點半,請李銘喝咖啡。」

最終輸出裏,「11點」並不會被自動刪掉,而是完整保留了用戶原本的修改過程。
包括一些講話過程中不斷反覆修改句子的情況,它也不會主動整理成更通順的書面語言,儘量保留原話。

目前,市面上一些AI語音輸入產品,如Typeless和智譜AI輸入法(小凹),已經開始覆蓋「自動潤色」「自動改寫」等功能。它們會主動刪除廢話、重組句子,直接幫用戶優化表達。
相比之下,豆包輸入法當前的策略會更保守一些,強調對原始表達的保留。
五、改錯一次之後,它就會記住你的寫法
個性化改詞,是這次體驗裏最實用的功能之一。
比如在人名場景裏,語音識別經常會遇到同音字問題。
第一次輸入時,系統可能會給出錯誤寫法。這時候,用戶只需要手動修改一次。等到第二次再語音輸入同樣的人名時,豆包就會優先採用用戶之前修改後的版本。

長期使用後,這種「記憶」也是是明顯感知到的。除了人名之外,一些公司名、產品名或者固定術語,也存在類似情況。這類高頻專有名詞,其實是很多人日常語音輸入裏最容易反覆修改的部分。
結語:不需要鍵盤了?或許我們更需要一個麥克風
相比鍵盤輸入,語音輸入最大的優勢,其實一直都是「更快」。
而在AI能力加入之後,語音輸入也不再只是簡單「轉文字」了。實時修正、自動斷句、上下文記憶,以及更高的識別準確率,都開始讓它變得更實用。
與此同時,語音輸入的使用場景也在擴大。
過去,很多人只會在開車、走路時偶爾使用語音輸入。但現在,隨着輕聲識別、抗噪等能力出現,辦公室、咖啡店、圖書館等環境,也開始能夠正常使用。
某種程度上,AI語音輸入法正在重新改變人與電腦的輸入方式。或許未來很多人想打字,第一反應不是找鍵盤,而是先找麥克風。