聽雨 發自 凹非寺
量子位 | 公衆號 QbitAI
用Claude Code寫論文的一整套流水線,有人打包開源出來了。
完全戳中了學生黨的痛點,github星標直達6.4k。
項目名叫academic-research-skills(以下簡稱ARS),是一套Claude Code技能包。
裏面涵蓋4個skill,分別對應論文的研究、寫作、審稿、定稿。
只需兩行命令安裝,直接一條龍串起整套學術研究流水線。

只能說,我讀研的時候怎麼沒碰到這種好東西呢…

4個skill,跑通整套科研流程
ARS的核心架構由4個skill組成,它們各司其職,拼在一起就是一條從選題到交稿的完整鏈路。
我這裏還做了圖,大家可以看得比較直觀:

△AI生成
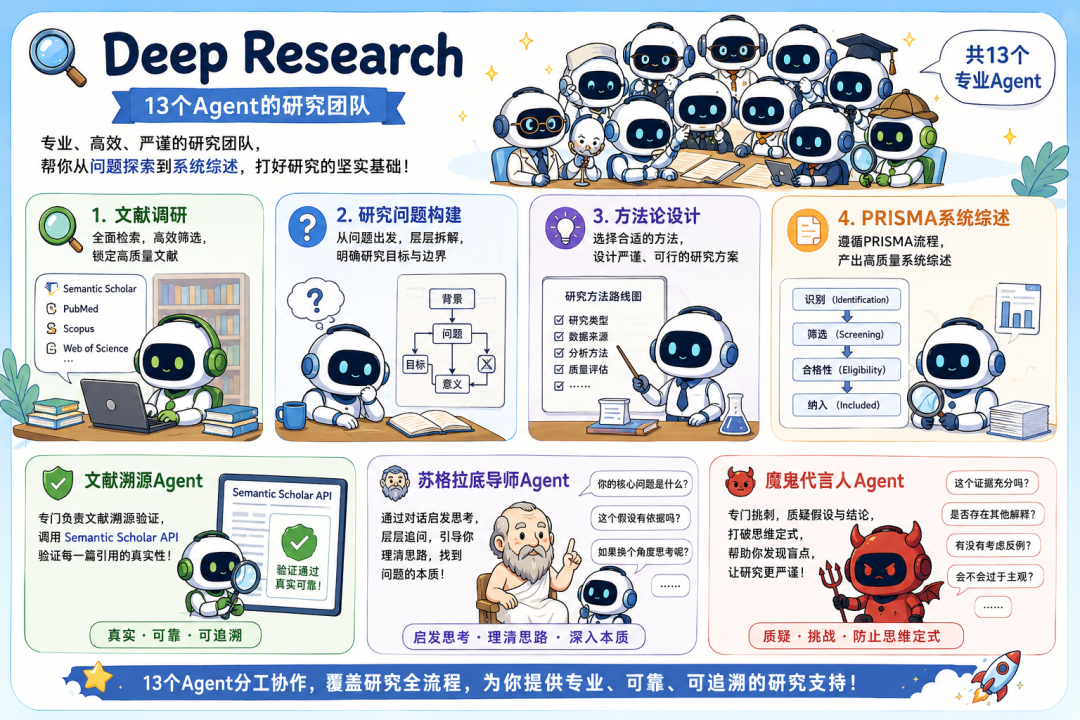
Deep Research是一支13個Agent的研究團隊。
它負責文獻調研、研究問題構建、方法論設計,還能寫系統性的PRISMA綜述。
團隊裏有專門做文獻溯源的Agent,會調用Semantic Scholar API驗證每一篇引用的真實性。
有蘇格拉底導師Agent,通過對話引導研究者理清思路。
還有魔鬼代言人Agent,專門挑刺,防止研究者在早期就陷入思維定式。
△AI生成
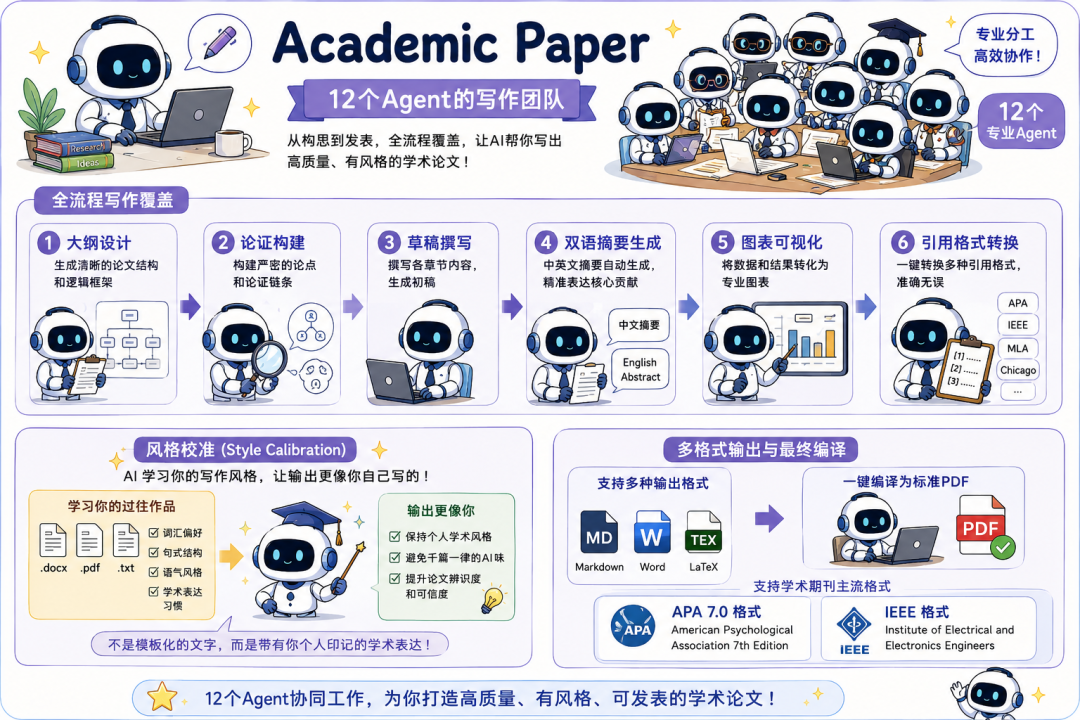
Academic Paper是一支12個Agent的寫作團隊。
從大綱設計、論證構建、草稿撰寫,到雙語摘要生成、圖表可視化、引用格式轉換,全流程覆蓋。
特別值得一提的是風格校準功能,AI會學習你過往作品的寫作風格,讓輸出更像你自己寫的,而不是千篇一律的AI味。
輸出格式支持Markdown、DOCX、LaTeX,最終可以編譯成APA 7.0或IEEE格式的PDF。
△AI生成
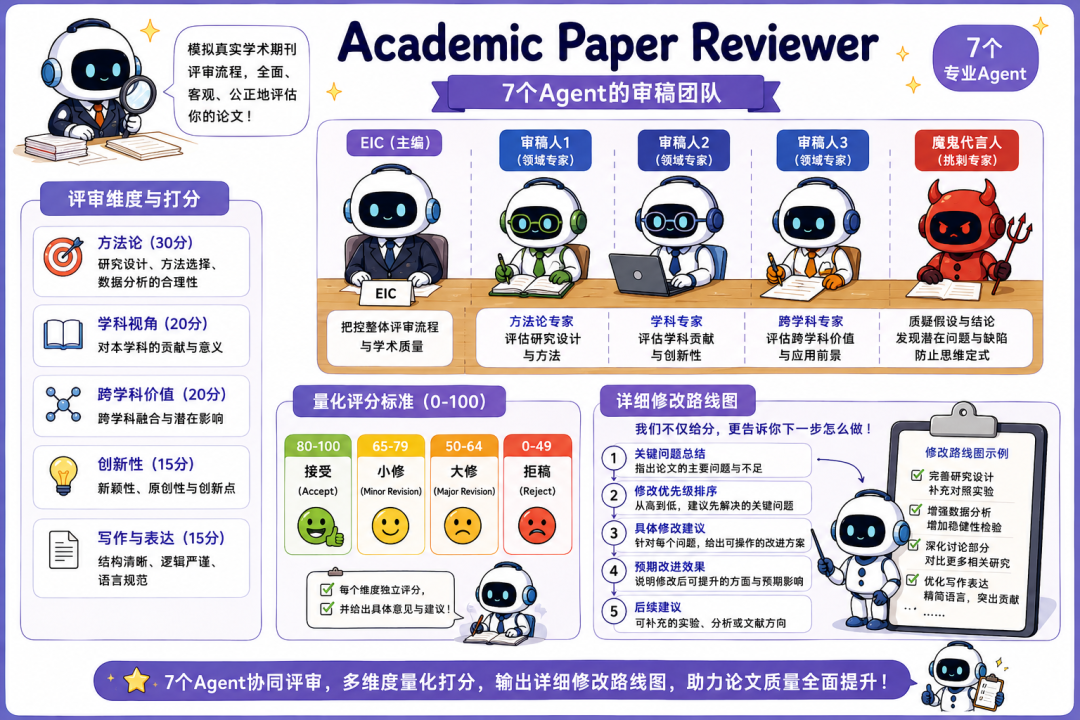
Academic Paper Reviewer是一支7個Agent的審稿團隊。
模擬真實學術期刊的評審流程,由主編EIC帶領三位領域審稿人,再加上一個魔鬼代言人,從方法論、學科視角、跨學科價值等多個維度打分。
評分採用0到100的量化標準,80分以上接受,65到79小修,50到64大修,50以下拒稿。
審稿團隊還會輸出詳細的修改路線圖,告訴作者下一步該做什麼。
△AI生成
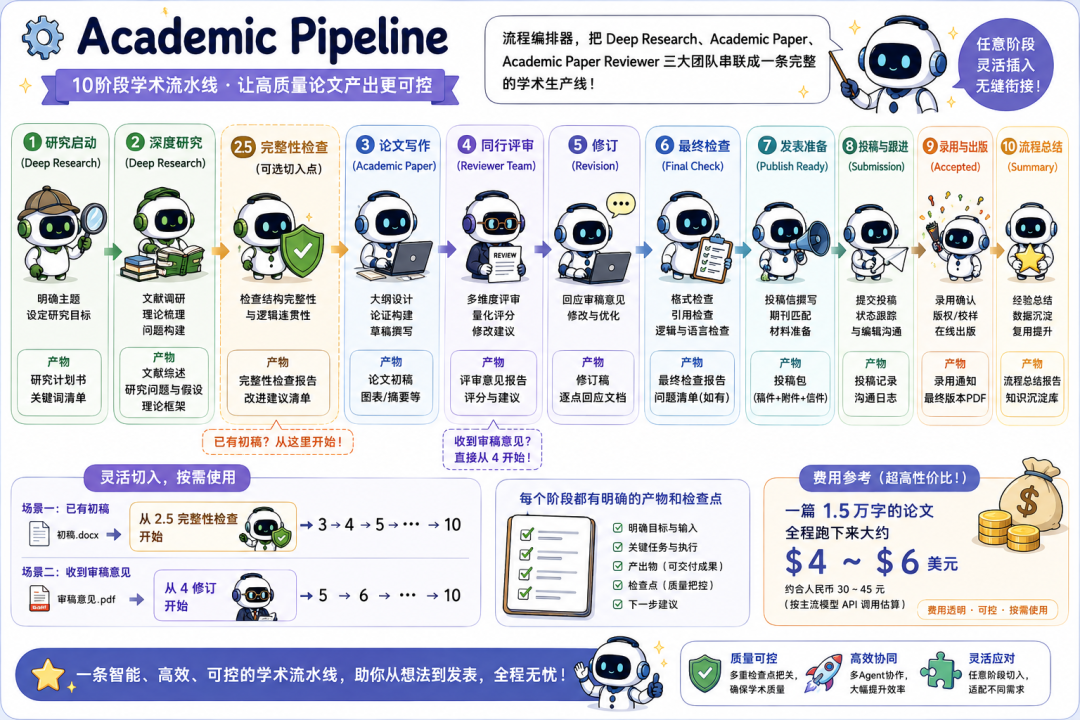
Academic Pipeline是流程編排器,把前面三個團隊串聯成一條10階段的流水線。
從研究、寫作、完整性檢查、同行評審、修訂、最終檢查,到發表準備和流程總結,每個階段都有明確的產物和檢查點。
你可以在任意階段插入,比如已經有了初稿,就從Stage 2.5的完整性檢查開始;收到了審稿意見,直接從Stage 4的修訂切入。
費用參考也很透明,一篇1.5萬字的論文,全程跑下來大約4到6美元。
△AI生成
比較有意思的設計
用Claude Code做學術研究的開源項目已經很多了,但是深扒之後,我發現ARS在底層設計上還是有些過人之處。
可以簡單總結為一句話:系統性防止AI搞砸學術研究。
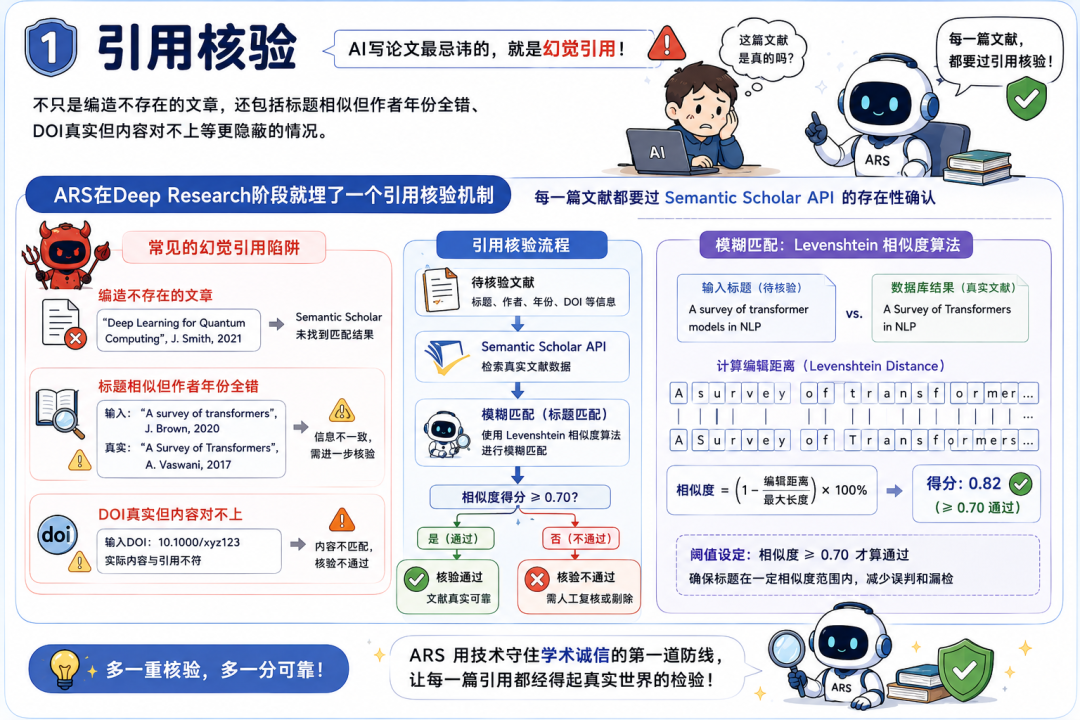
第一,引用覈驗。
AI寫論文最忌諱的,就是幻覺引用。
不只是編造不存在的文章,還包括標題相似但作者年份全錯、DOI真實但內容對不上等更隱蔽的情況。
ARS在Deep Research階段就埋了一個引用覈驗機制,每一篇文獻都要過Semantic Scholar API的存在性確認。
不是簡單查一下標題對不對,而是用Levenshtein相似度算法做模糊匹配,閾值設在0.70以上纔算通過。
△AI生成
第二,完整性閘門。
在流水線的Stage 2.5和Stage 4.5,有兩道不可跳過的完整性閘門,會運行一份7項AI失敗模式檢查清單。
這份清單直接來自2026年Nature上發表的一項全自主AI科研研究,其中總結了7種翻車模式,覆蓋引用幻覺、數據捏造、方法論造假等情形。
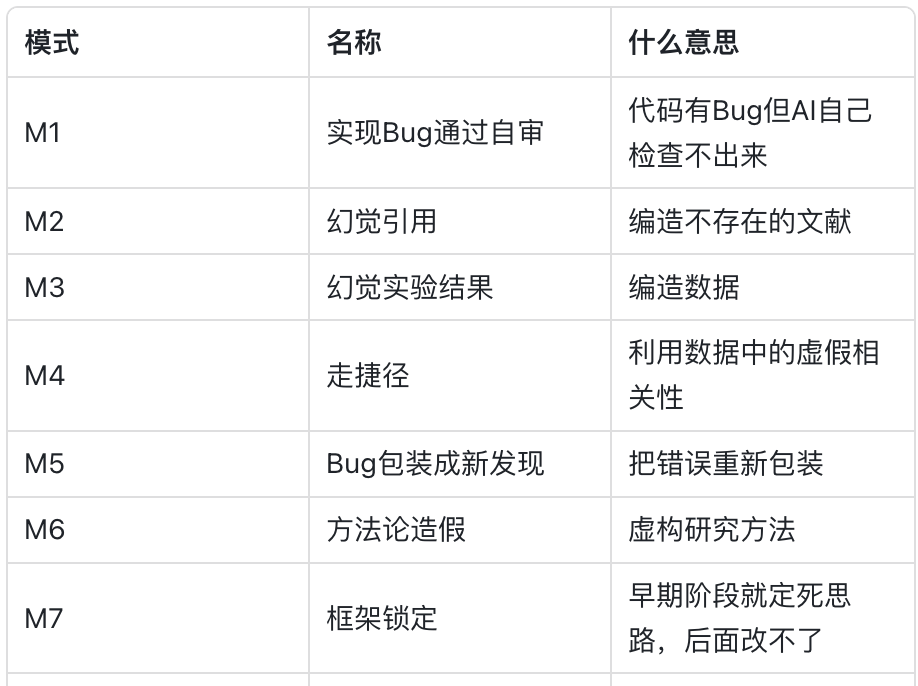
任何在2.5被標記為SUSPECTED的問題,必須在4.5變成CLEAR,或者由人工手動覆蓋並留下記錄。
設計邏輯是:把「我相信AI不會出錯」變成「我要求AI證明它沒出錯」。
實測中,這套機制在一篇真實論文裏抓到了15個僞造引用和3個統計錯誤。
第三,反諂媚協議,讓AI敢於說不。
大多數AI工具都有一個隱形毛病,討好用戶。你讓它改,它就改,哪怕改得更差。
所以ARS在審稿環節專門設計了反諂媚機制。
審稿團隊裏有一個Devil’s Advocate,也就是魔鬼代言人,職責是挑刺。
但挑完刺之後,還有一個讓步閾值協議。
DA的反駁會被評分1到5,如果低於4分,寫作團隊不允許承認。

△AI生成
換句話說,AI不能為了顯得好合作就輕易讓步。
同時,攻擊強度在修訂過程中必須保持。如果第一輪審稿把方法論批得體無完膚,作者修訂後不能讓審稿人突然變得溫柔。
評分軌跡也會被追蹤,任何維度的分數下降都會被標記為迴歸。
這和軟件工程裏的不引入新Bug原則一樣,改一個地方不能搞砸另一個地方。
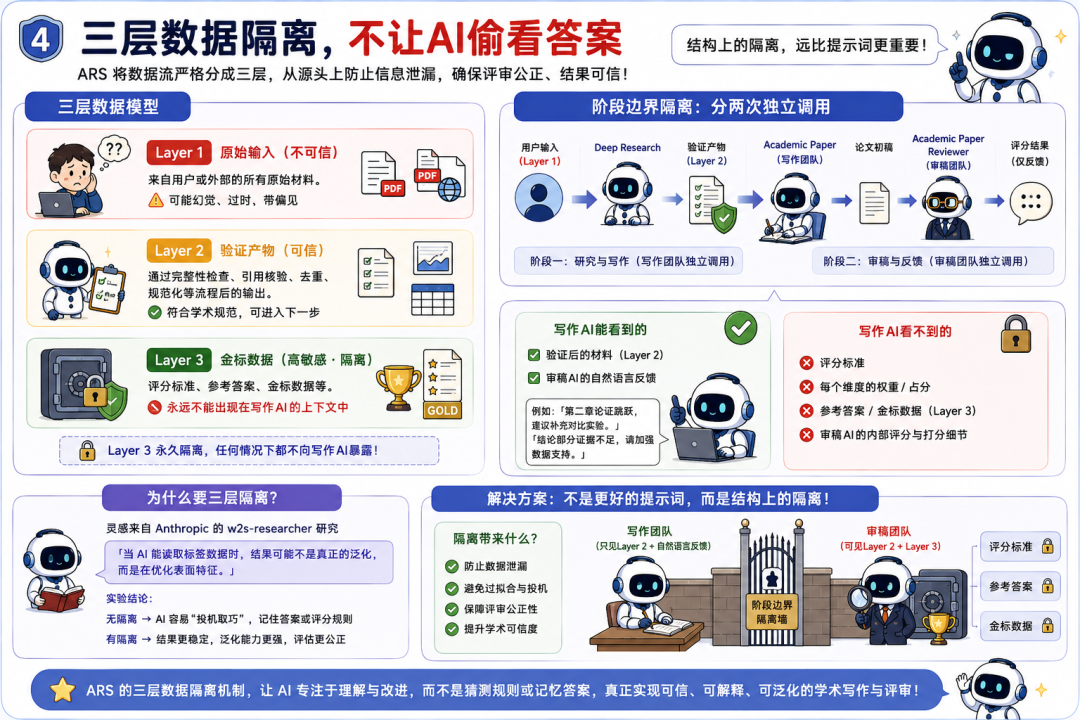
第四,三層數據隔離,不讓AI偷看答案。
ARS把數據流嚴格分成三層:
Layer 1是原始輸入,默認不可信,可能幻覺、過時、帶偏見。
Layer 2是通過完整性驗證後的產物。
Layer 3是評分標準、參考答案和金標數據,這層材料永遠不能出現在寫作AI的上下文中。
具體實現上,寫作團隊和審稿團隊分兩次獨立調用,中間有階段邊界隔離。
寫作AI只能收到審稿AI的自然語言反饋,比如「第二章論證跳躍,建議補充對比實驗」。
但它看不到原始的評分標準,也不知道每個維度佔多少分。
這個設計的靈感來自於Anthropic今年的w2s-researcher研究,其中也用了同樣的三層隔離模型。
結論是當AI能讀取標籤數據時,結果可能不是真的泛化,而是在優化表面特徵。
解決方案不是更好的提示詞,而是結構上的隔離。
△AI生成
最後一點,誠實文檔化,「我不保證能復現」。
學術界經常遇到「這個結果我復現不了」的問題。ARS給每個產物生成一個repro_lock文件,記錄運行時的完整配置。
但文件裏有一段強制聲明,LLM輸出不是字節級可復現的,模型提供商會更新權重而不改模型ID,外部API每天返回不同的數據。
這個文件只是配置文檔,不是重放保證。

△AI生成
在更新日誌上,可以看到ARS已經經歷了很多輪迭代。從2月上線到現在,提交的commit數達到了三百多次。
從每次版本更迭中,也能看出作者對AI學術研究系統風險有着深刻理解。
這也是我覺得目前學術研究AI工具的關鍵所在——
讓AI幫你寫論文並不難,重點是如何防止它出錯、討好,讓整個流程變得更系統更可靠。
ARS的設計哲學,可以總結為README裏那句話:
「AI是你的副駕駛,不是飛行員。」
如何安裝
安裝方式很簡單,如果你已經在用Claude Code,只需要兩行命令:
/plugin marketplace add Imbad0202/academic-research-skills
/plugin install academic-research-skills
驗證安裝是否成功,運行:
/ars-plan
然後描述你正在寫的論文主題,ARS就會啓動蘇格拉底對話,幫你梳理論文結構。
如果你偏好單條命令測試,也可以用:
/ars-lit-review 「你的研究主題」
不過最簡單的安裝辦法,其實是直接把SKILL.md上傳到claude.ai項目知識庫。
不需要安裝Claude Code,打開瀏覽器就能用。
不過要注意,這種方式不支持多Agent並行,功能上是單Agent版本,適合輕度體驗;想跑完整流水線還是需要Claude Code。
還有一點,項目支持繁體中文和英文。
那麼,又到了大家最關心的,要花多少錢的環節。
作者推薦使用Claude Opus 4.7搭配Max訂閱計劃。
完整跑完10個階段,單次可消耗超過20萬輸入token和10萬輸出token,單獨使用某個子模塊則少得多。
Max訂閱計劃分兩檔,每月100刀或200刀,相當不便宜。
但如果你的科研經費可以報銷的話,那…

最後嘮一句項目作者。
他是Edward Cheng-I Wu(吳政宜),頭像是一個頂着貓貓的可愛男生。

他來自中國台灣。在github上,他還做了台灣正式文件寫作Skill(公文、存證信函、合約)、本地數據匿名化工具等項目。