昨天,微信讀書 Skill 詞條登上熱搜。
用戶連接微信讀書賬號後,AI 可以調用個人閱讀數據,完成查書、看書架、統計閱讀習慣、整理筆記和推薦書籍等任務。
從功能上看,微信讀書 Skill 主要分為六類。
查閱書架:瀏覽個人書架,快速了解藏書全貌。
書籍搜索:在書城搜索書籍,獲取書名、作者、評分等關鍵信息。
閱讀統計:分析閱讀時長、閱讀天數、偏好深度,量化閱讀習慣。
書籍詳情:查看書籍詳情、章節目錄和閱讀進度。
筆記和劃線:查看劃線與想法,導出筆記,回顧閱讀思考。
推薦好書:根據閱讀偏好做個性化推薦,或推薦相似書籍。
安裝過程可以分成兩個關鍵步驟:把 Skill 部署到 AI 助手裏,再用 API Key 綁定自己的微信讀書賬號。
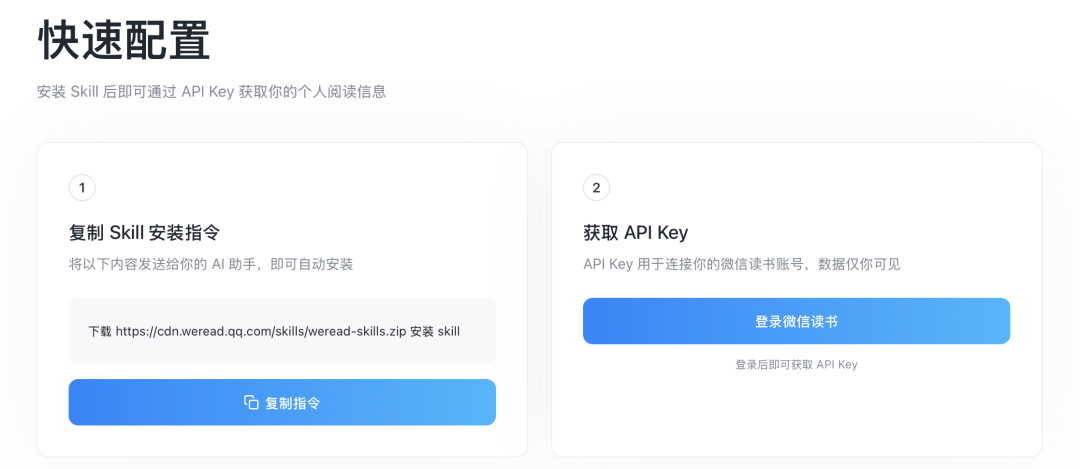
第一步,打開微信讀書 Skill 頁面:
🔗 https://weread.qq.com/r/weread-skills
進入頁面後,可以看到微信讀書 Skill 的相關說明和安裝文件。接下來打開 Codex、Claude Code、WorkBuddy 等工具,考慮到適用於國內用戶的網絡環境,這裏我們選擇騰訊 AI 助手 WorkBuddy。
第二步,在 WorkBuddy 裏新建一個對話,把下面這行指令完整發送給它:
下載 https://cdn.weread.qq.com/skills/weread-skills.zip 安裝 skill
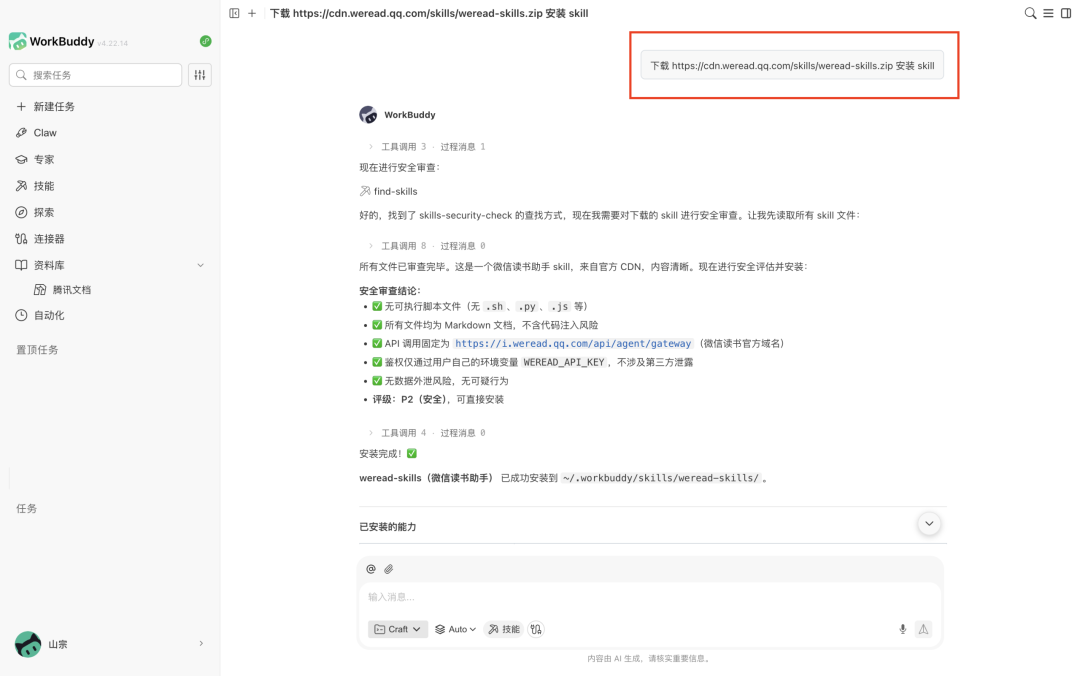
這條指令的作用,是讓 WorkBuddy 從微信讀書提供的地址下載 Skill 壓縮包,並完成安裝。發送之後,等待 WorkBuddy 執行。一般幾分鐘後,它會提示部署完成。
不過,部署完成還不能直接使用。因為 AI 要訪問的是用戶個人賬號裏的書架、閱讀進度和筆記,所以還需要用 API Key 完成授權。
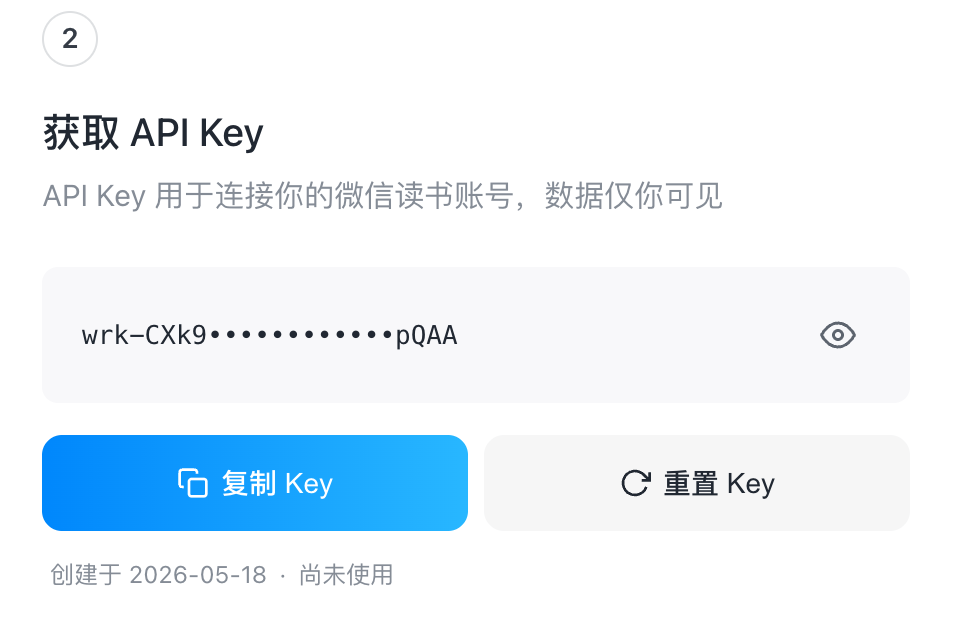
API Key 需要通過掃碼登入微信讀書獲取。用戶按照頁面或 WorkBuddy 給出的提示完成掃碼登入後,系統會生成一串 API Key。它相當於連接微信讀書賬號的授權憑證,建議不要公開發布,也不要發到不可信的地方。
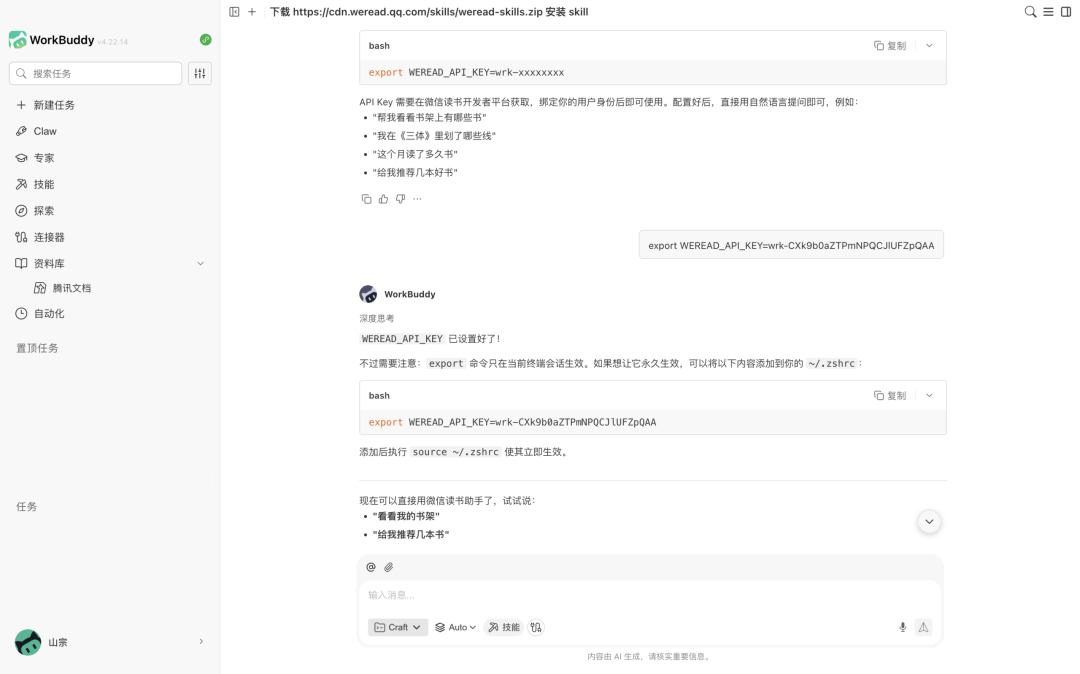
拿到 API Key 後,可以直接把它發送給 WorkBuddy,讓它完成配置,也可以用環境變量的方式配置:
export WEREAD_API_KEY=複製你得到的 API Key
這裏要把「複製你得到的 API Key」替換成掃碼登入後生成的真實 API Key。配置完成後,WorkBuddy 會識別授權信息,並連接用戶的微信讀書賬號。
安裝和授權都完成後,可以用一個簡單問題測試是否可用。
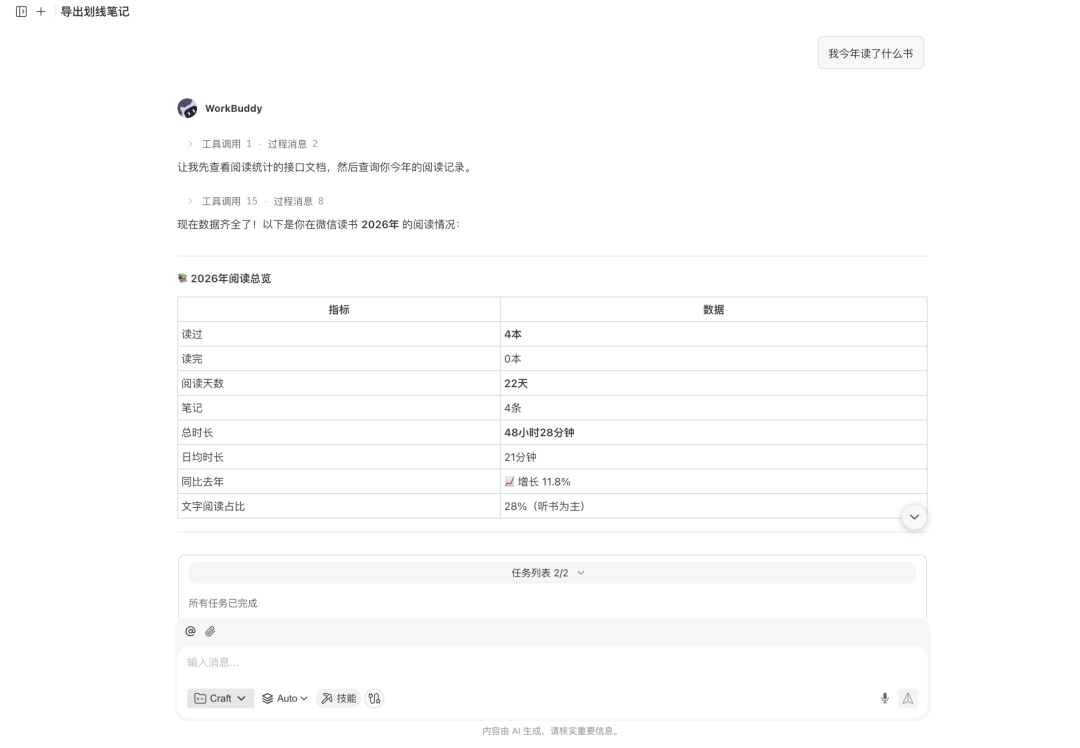
比如查看我的微信讀書書架,或者我今年在微信讀書讀了哪些書?如果 WorkBuddy 能返回書架、閱讀記錄或相關統計,就說明微信讀書 Skill 已經可以正常使用。
完成安裝和授權後,我們也幫你整理了一些關於微信讀書 Skill 的創意玩法。
第一類是量化閱讀習慣。
過去,用戶想知道自己一年讀了什麼、讀書時間集中在哪些時段,往往要翻閱讀記錄或者自己做整理。接入 Skill 後,這些問題可以直接交給 AI,讓它幫助你更直觀地理解自己的閱讀狀態。
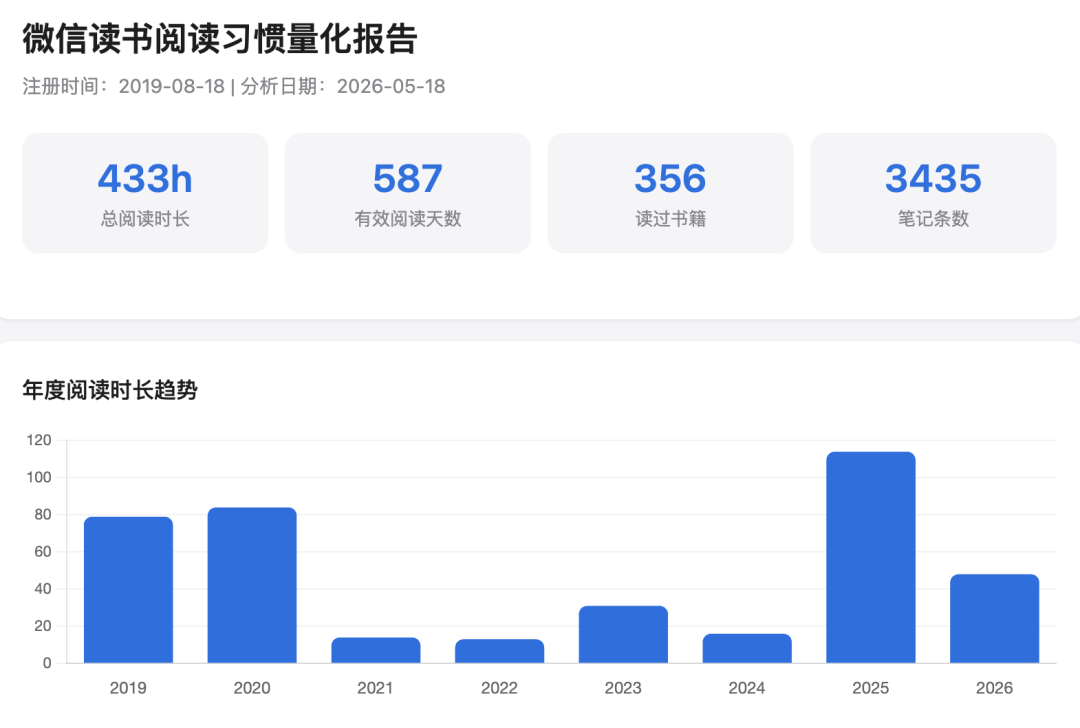
可以試試這些提示詞:
我今年讀了哪些書?請按月份、書籍類型和閱讀進度整理成表格
量化我的微信讀書習慣,包括閱讀時長、閱讀天數、常讀類型和閱讀連續性
我的閱讀時間主要集中在一天中的哪個時段?請按早晨、上午、下午、晚上和深夜分類
我連續讀書最長的一段時間是哪本書?請告訴我對應時間、閱讀天數和閱讀進度
根據我的閱讀記錄,分析我最近三個月和今年整體閱讀習慣有什麼變化
第二類是個性化推薦。
微信讀書本來應該有推薦系統,但 Skill 的不同之處在於,它可以圍繞用戶自己的書架和閱讀歷史生成更具體的建議。它不是只推薦熱門書,而是可以進一步看你讀過什麼、偏好什麼、最近關注什麼,再給出更貼近個人背景的書單。
可以這樣問:
基於我的閱讀偏好,推薦 10 本我可能感興趣的散文作品,並說明推薦理由
我想讀《人間滋味》,幫我查作者、評分、分類、出版社、出版時間和 ISBN
我最近對 AI 話題很感興趣,看看我的書架裏有哪些書可以幫我快速建立背景知識
根據我的閱讀記錄,推薦 5 本和我最近讀過的書相似的作品

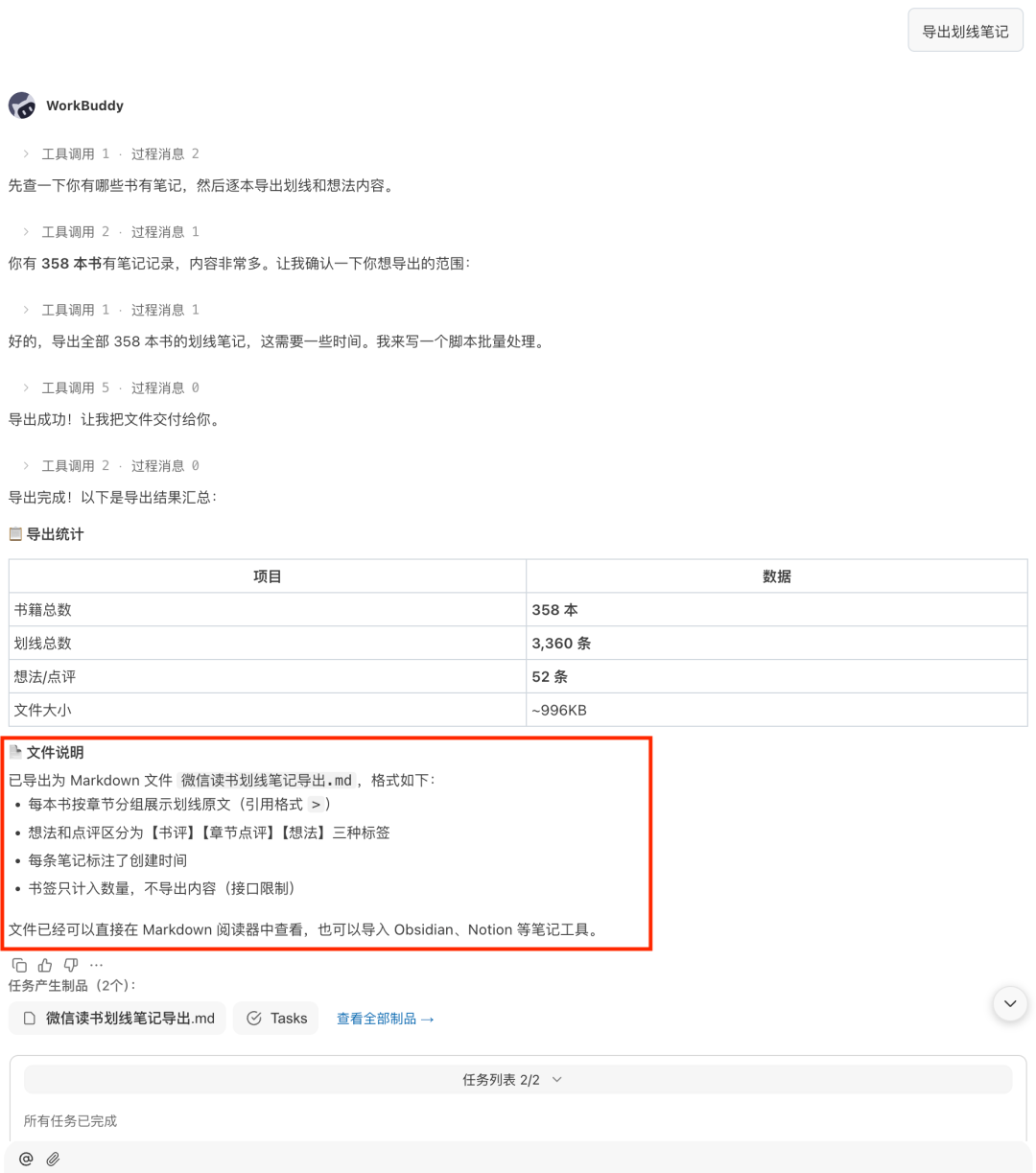
第三類是整理筆記與發現認知盲區。
對於長期在微信讀書裏劃線、寫想法的人來說,真正麻煩的不是沒有筆記,而是筆記分散在不同書裏,很少被系統整理。Skill 的價值之一,就是把這些閱讀痕跡重新組織起來。
可以試試這些提示詞:
導出我最近讀完的三本書的劃線筆記,並按書名整理
把《某本書》的全部劃線導出,按主題歸類,並提煉 10 條核心觀點
分析我讀書時更喜歡劃事實、觀點、故事、方法論,還是情緒表達
根據我的劃線內容,判斷我更關注問題分析、經驗總結、人物敘事,還是價值判斷
把《某本書》的劃線全部導出,然後根據這些內容出 5 道題考我,看看我到底讀懂了多少
最後還有一類更進階的場景,是發現認知盲區。
長期讀同樣的內容,難免陷入信息繭房,因此不要讓 AI 繼續推薦你原本熟悉的內容,而是基於閱讀記錄找出較少接觸的領域,再推薦可能補足知識結構的書。
比如長期看商業書的人,可能缺少歷史視角;長期看技術書的人,可能缺少社會學和倫理討論;長期看文學的人,也可能缺少經濟、科技和組織管理相關的知識。不只是讓它告訴你讀過什麼,還可以反過來分析你沒有讀什麼。

可以這樣問:
根據我的閱讀歷史,判斷我在哪些知識領域有明顯空白
基於我的閱讀記錄,推薦我需要補充哪些書,幫助我提高認知,避免知識結構過窄
分析我的書架,告訴我哪些領域讀得比較多,哪些領域幾乎沒有覆蓋
基於我的閱讀歷史,給我一份認知補全書單,按文學、歷史、科技、商業、社會學、哲學分類
結合我近期的對話記錄,找出我最需要改進的地方,再從我的微信讀書書架裏定位到具體書籍和具體章節
上述最後一個提示詞,更接近定向檢索多玩法。比起泛泛推薦一本書,不如把你當下的問題、已有書架和具體章節連接起來。
簡言之,微信讀書 Skill 最值得關注的,不在於幫你查了幾本書或導出了幾條筆記,而是它把用戶多年積累的閱讀痕跡,轉化成了 AI 可讀取的知識索引。
書架、進度、劃線、想法……這些過去沉睡在 App 裏的行為數據,現在都被激活了。與其說用戶在使用一個閱讀 App,不如說是在餵養一個不斷理解自己的個人知識庫 Agent。
過去的閱讀產品解決的是「在哪裏讀」,推薦系統解決的是「下一本讀什麼」。而在大模型的加持下,Skill 開始觸碰第三個更深層的問題:讀過的東西,如何重新參與我們當下的思考、寫作與決策?
尤其是,幾千年來,閱讀都是一個人的單向過程。我們一頭扎進書海,能記住多少、用上多少,全憑記憶力和悟性。而 AI 的介入,讓閱讀變成了一場真正的雙向奔赴。
何其妙哉。