
agent正在變得越來越能幹,但它還有一個很尷尬的問題,那就是幹着幹着,就忘了自己要幹什麼了。
長任務、跨會話、連續執行,這些的確是agent的發展方向,可前提是它必須有一套可靠的記憶系統。否則,再強的模型也只能在一次次對話裏反覆「重新認識世界」。
騰訊最近開源的AgentDB,瞄準的正是這個問題。
這一個是專門用來解決記憶問題的獨立組件,一共只有幾MB的大小,下載到電腦以後,在OpenClaw或者Hermes Agent裏輸入一個指令,AgentDB就安裝完成了。
就是這麼一個「小玩意」,在發布的同時,騰訊專門為其開設了獨立的X賬號( @TencentDBAbxo2),並由團隊親自在社交媒體上與開發者互動。

雖然騰訊不同業務都有X賬號,比如混元、騰訊雲等等,但這是騰訊第一次為一個開源工具單獨開X賬號,可見騰訊對這個開源項目的重視程度。
那就別說別的了,直接進入主題吧!
01
AgentDB解決了什麼問題?
對於模型記憶這個問題,Codex和OpenClaw曾嘗試用壓縮的方式解決,把冗長的歷史對話壓縮成一小段摘要,但這種做法會不可逆地損失記憶的細節。
當Agent需要回溯某個具體決策的依據時,那些被壓縮掉的信息就永遠找不回來了。
這就是傳統記憶系統的現狀。要麼把所有歷史對話無腦塞進上下文窗口,導致token消耗爆炸,成本直線上升。要麼用總結壓縮歷史,雖然省了token,但細節永久丟失,Agent在需要考證時只能靠模糊的印象瞎猜。
這兩種方案都不夠優雅,也都不夠實用。
AgentDB本質上是一個分層漸進式的Agent記憶管道系統。它採用「符號化短期記憶+分層長期記憶」的雙軌架構,試圖在token效率和信息完整性之間找到平衡點。
這套系統的設計理念包含三個維度。
第一個維度,拒絕暴力堆積,也拒絕不可逆壓縮。
AgentDB設計了L0到L3四層記憶金字塔。L0是原始對話,完整保留每一輪交互的原始記錄。L1是提取的原子記憶,由LLM自動從對話中提取結構化事實、用戶偏好、任務約束和中間結論。L2是場景聚合,按任務類型自動歸納相關記憶,形成場景塊。L3是用戶畫像,持續提煉信息,形成穩定的長期用戶檔案。
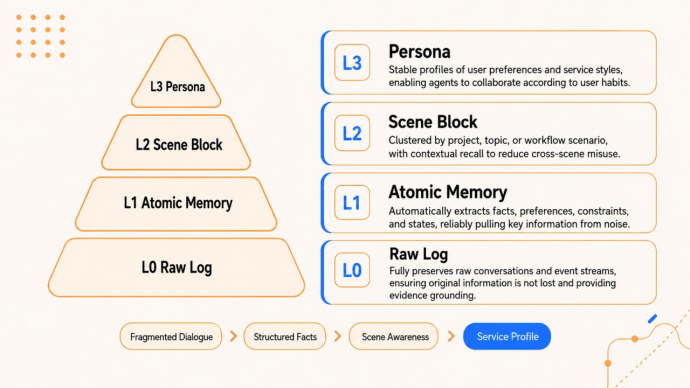
這種分層設計的核心價值在於「可壓縮、可展開、可追溯」。
平時Agent工作時,只需要加載高層的Persona和場景塊,就能把握用戶偏好和任務脈絡,token消耗極低。當需要考證細節時,再通過索引機制檢索底層的原子記憶和原始對話,完整還原證據鏈。整個過程沒有任何信息被不可逆地丟棄,所有壓縮都是有損但可恢復的。
它就像圖書館一樣,把記憶放在不同的區域,比如國外文學、工具書之類。平時為了省時間,只看目錄和摘要,需要細節時再去原始記錄裏找,以保證不丟失信息。
這套機制的實際效果相當顯著。在PersonaMem長期記憶測試中,AgentDB的準確率從傳統方案的48%躍升至76%。這使得Agent能夠在跨會話的場景中穩定地記住用戶的偏好和歷史決策,而不是每次對話都像第一次見面一樣從零開始。
第二個維度,符號化記憶解決長任務中的信息過載。
在複雜任務中,最消耗token的往往不是對話本身,而是那些冗長的中間日誌。
搜索結果可能有幾千字,代碼片段可能有上百行,錯誤堆棧可能佔滿整個螢幕。如果把這些內容全部塞進上下文,token很快就會爆表。
AgentDB的做法是將這些冗長內容offload到外部文件系統,同時用Mermaid圖譜提取其中的關係結構。注入到Agent上下文中的只是輕量級的符號化表示,比如一個任務節點的ID、一段代碼的摘要、一個搜索結果的關鍵詞。
當Agent需要回溯細節時,通過node_id精準召回原始文本。這種設計讓上下文從「數十萬token的日誌堆」壓縮為「幾百token的關係圖譜」。
也就是說,AgentDB把大段大段的日誌、代碼、搜索結果存到外面,只在AI的「工作台」上放一個索引編號和關鍵詞摘要。需要時再根據編號去調取原文。
在WideSearch任務中,這套機制的效果尤其明顯。token使用量降低了61.38%,而任務成功率反而提升了51.52%。
這個反直覺的結果揭示了一個重要事實,更多的上下文並不總是意味着更好的表現。當無關信息稀釋了注意力時,Agent反而會迷失在信息的海洋中,做出錯誤的決策。
符號化記憶通過結構化的方式呈現信息,讓Agent能夠清晰地看到任務的全貌和執行路徑,從而做出更準確的判斷。
第三個維度,全本地化、零外部依賴。
AgentDB默認使用SQLite加sqlite-vec作為後端,無需連接任何外部API或雲服務。這對企業場景至關重要。記憶數據往往包含敏感的業務邏輯、用戶偏好和項目細節,全本地化意味着數據主權完全掌握在用戶手中。
大多數記憶系統都依賴雲端向量數據庫或第三方embedding服務,數據必須上傳到外部服務器才能使用。
尤其是對於金融、醫療、政務這些行業來說,這種依賴是有問題的,所以這類公司往往都是私有云,把數據存在本地裏,但本地的服務器又跑不動大模型。
AgentDB的全本地化方案解決的正是這個問題。
從技術實現來看,AgentDB的四層記憶管線是完全自動化的。
對話開始時,系統自動通過向量檢索或混合搜索召回相關記憶,加載用戶畫像,注入到系統上下文中。對話結束後,系統自動錄製對話消息,雙寫到IMemoryStore和JSONL文件。
當累積到一定輪次後,Pipeline調度器按序觸發L1、L2、L3的提取和歸納流程。整個過程對用戶和Agent都是透明的,不需要手動干預。
你只需要在OpenClaw或Hermes Agent中安裝插件,配置好LLM接口,AgentDB就能開始工作。
所有字段都有合理的默認值,零配置即可使用。對於有特殊需求的用戶,AgentDB也提供了豐富的配置選項,可以調整每一層的觸發閾值、間隔時間、提取策略等參數。
AgentDB的另一個亮點是可追溯性。壓縮或抽象最大的風險是「丟失證據」,當召回的記憶出錯時,用戶只能看到一堆向量分數,無法判斷問題出在哪裏。
AgentDB保留了關鍵的中間產物作為可讀文件。
每一條信息都100%可找回、可恢復,無論是短期記憶中被卸載的一段報錯日誌,還是長期記憶裏總結出的一條用戶偏好,Agent或開發者都可以沿着「高層符號→中層索引→底層原文」的鏈路進行完美溯源與恢復。
02
姚順雨的「上下文理論」找到了最佳實踐
AgentDB這個產品,某種程度上來說,就是騰訊對姚順雨「上下文理論」的一個落地方案。
姚順雨此前多次強調,AI的核心能力不在於參數規模,而在於對上下文的理解、管理和利用。
這個觀點在他加入騰訊後發布的第一個模型Hy3 preview中,得到了充分體現。
Hy3 preview這個模型最特別的地方在於,它把「出色的上下文學習和指令遵循能力」單獨拎出來,寫進了核心能力清單的第一條。
當其他廠商都在卷agent能力、代碼生成、多模態的時候,Hy3把上下文能力放在了最顯眼的位置。
姚順雨加入騰訊後發布的第一個研究成果是CL-bench,這是一個專門用來測試模型能否從上下文中學習新知識並正確應用的基準。
在Hy3 preview的性能展示中,第一張圖放的不是SWE-Bench Pro或者Terminal-Bench 2.0這種agent和代碼排行榜,而是AdvancedIF、AA-LCR,以及CL-bench這些看上下文推理、檢索和指令遵循的排行榜。
騰訊認為上下文管理能力,纔是AI下一階段賽道。
其實市面上有不少模型廠商都會在宣傳時都會強調自己支持多長的上下文,包括OpenAI和Anthropic,從一開始的32K到128K,再到1M甚至微軟曾經提到過的10M上下文。
但你真正用的時候就會發現,上下文越長,模型的表現往往越差。
信息密度被稀釋,注意力被分散,模型在海量的無關信息中迷失方向,反而做出更多錯誤的決策。
姚順雨團隊的消融實驗驗證了這個觀點,無關信息會稀釋了注意力。這也是AgentDB的分層設計想要去解決的問題。
騰訊為AgentDB專門開設X賬號,並由團隊成員主動發起AMA,這在騰訊的開源項目中並不常見。這種高調姿態背後,是騰訊希望將AgentDB打造成「上下文管理」領域標杆的野心。
然而AgentDB目前在實戰這塊並沒有很搶眼的表現,騰訊需要給AgentDB「帶貨」。
AgentDB的價值需要通過具體場景才能被感知。
比如,騰訊可以拿出混元模型,結合AgentDB構建一個「連續工作30天不丟失上下文的代碼審查Agent」,或者「記住用戶所有偏好的個性化內容推薦Agent」。
只有當開發者看到「某個模型+AgentDB」產生的化學反應,大家纔會去用它。
03
唐傑的「上聯」,姚順雨的「下聯」
就在AgentDB發布前夕,智譜創始人唐傑深夜發布了一條長文反思,核心觀點直指,長周期任務將是今年AI最可能的突破點。
唐傑認為,AI的真正價值不在於單輪對話的智能,而在於通過與環境持續交互,完成複雜、延展的任務。

他舉了一個黑客的例子,一個能24/7不間斷搜尋軟件漏洞的AI,本質上是在學習黑客的高階直覺和方法論,而非簡單的搜索。
這種「長周期學習+持續執行」的能力,纔是下一階段AI所需要的。
而要實現長周期任務,唐傑指出了三大技術支柱,記憶、持續學習、自我判斷。
其中,記憶被他列為「通過巧妙工程手段最先被解決」的能力。
這個判斷和AgentDB的產品邏輯幾乎是重合的。
如果說唐傑出了一個「上聯」,「長周期任務需要記憶作為前提」,那麼騰訊用AgentDB對了一個「下聯」,「分層記憶讓長周期任務成為可能」。
Agent需要記住自己做了什麼,為什麼這麼做,接下來該做什麼。如果每執行幾步就忘記之前的決策,那麼長周期任務根本無法完成。
更有意思的是,唐傑還在文中提到了「自我判斷」能力,雖然AgentDB體積很小,但它的架構中也允許AI進行「自我判斷」。
當Agent能夠通過Mermaid圖譜清晰地看到自己的任務進展、通過分層記憶回溯歷史決策,它就具備了「元認知」的基礎。
知道自己做了什麼、為什麼這麼做、接下來該做什麼。
這種結構化的自我認知,正是自我判斷的前提。
從這個角度看,AgentDB不僅是一個記憶系統,更是騰訊對「長周期任務時代」的一次技術押注。
唐傑描繪了願景,騰訊拿出了工具。
而在這場「長周期競賽」中,記憶系統就是Agent的燃料箱。容量決定續航,結構決定效率。
AgentDB的開源,意味着騰訊把這個燃料箱的設計圖紙公開了,而且還是免費的。
智譜在長周期任務上已經有了一些初步的成果。在GLM-5.1的白皮書中提到,GLM-5.1在不需要任何人工干預的前提下,能夠持續作業8小時。
但這只是一張成績單,要真正讓企業放心,還得看它在更多場景裏會不會掉鏈子,遇到沒見過的問題時能不能靠自己的手段解決。
長周期任務不是一個通用產品,它需要針對不同行業、不同場景做深度定製。
這也是AgentDB的機會所在。
作為一個獨立的記憶組件,AgentDB可以和任何模型、任何Agent框架集成。智譜可以用,字節可以用,阿里也可以用。
這種開放性讓AgentDB有機會成為長周期任務的基礎設施。
而長周期任務也不是某一家公司的專利,是整個行業的共同方向。誰能率先在這個方向上取得突破,誰就能在下一輪競爭中佔據先機。
而在這場競賽中,記憶管理能力將是決定性的因素之一。
騰訊把這套方案開源出來,既是一種技術自信的展示,也是一種對生態建設的投資。
如果AgentDB能夠成為長周期任務的標準記憶組件,那麼騰訊在這個領域的影響力就會遠遠超出一個開源項目本身。