
DeepSeek 之於大模型,就像蜜雪冰城之於奶茶。你不必糾結性價比,因為它的本事你挑不出毛病,你的錢包它也從不為難。
最近,DeepSeek 官方宣佈,DeepSeek-V4-Pro 模型 API 將永久降價。同時,DeepSeek 表示,API 已完成輸出提速與服務擴容,速度更快,服務更穩定,默認支持 500 併發,企業用戶可以在線申請更高併發。
發布模型,再給出折扣,接着降低緩存命中價格,最後把臨時優惠變成長期價格。大模型 API 的價格基準正在被重新改寫,而低價模型背後的下一站,很可能是 Agent。

DeepSeek 永久降價,梁文鋒把 Token 價格打骨折了
讓我們先來簡單梳理一下 DeepSeek 的降價時間線:
4 月 24 日,DeepSeek V4 預覽版正式發布。
4 月 25 日,DeepSeek 宣佈 V4-Pro 開啓 2.5 折優惠。
4 月 26 日,DeepSeek 宣佈緩存命中價格調整為首發價的十分之一。
4 月 28 日,DeepSeek 宣佈 V4-Pro 的 2.5 折優惠延期至 5 月 31 日。
5 月 22 日,DeepSeek 宣佈 V4-Pro 永久降價為原價的四分之一。
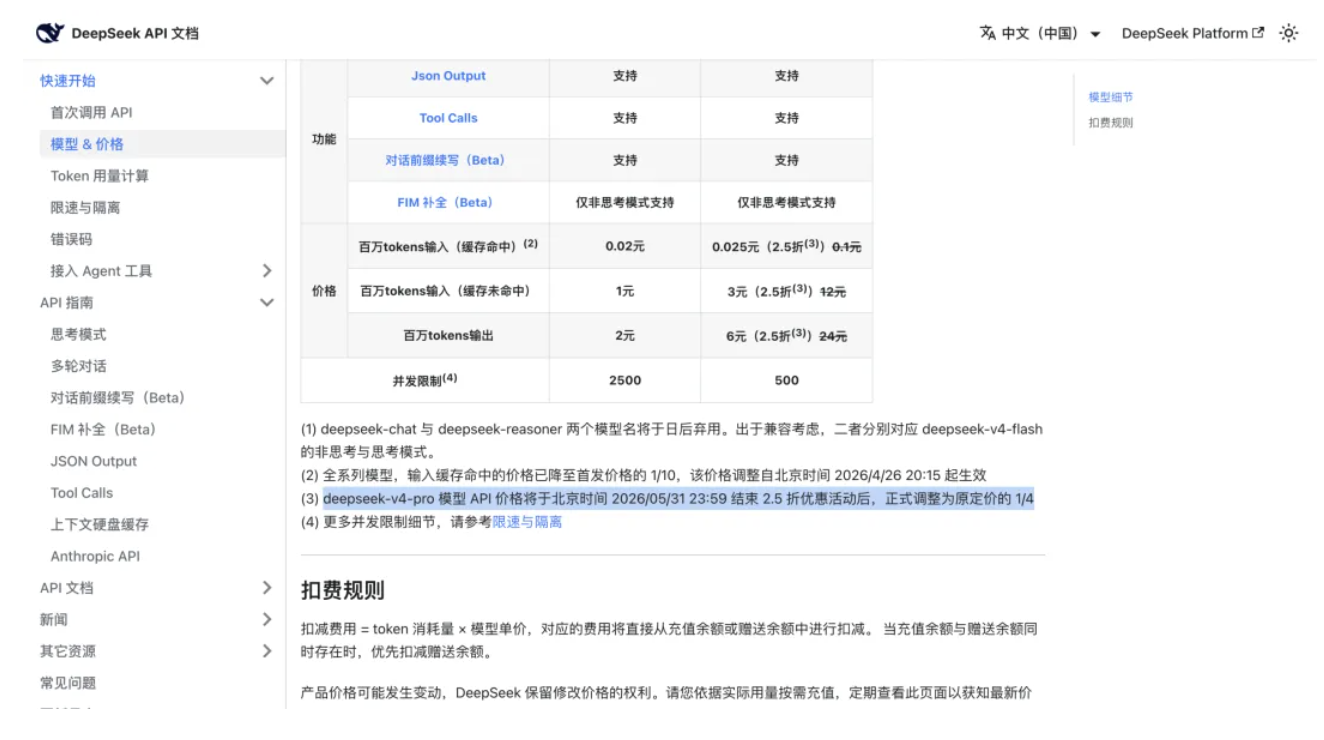
時間線的關鍵之處,在於臨時折扣變成了永久降價。調整之後,DeepSeek-V4-Pro 輸入緩存命中價格從 0.1 元每百萬 Tokens 降至 0.025 元,輸入緩存未命中價格從 12 元每百萬 Tokens 降至 3 元;
輸出價格從 24 元每百萬 Tokens 降至 6 元。疊加默認 500 併發和服務提速後,官方 API 對開發者和企業的吸引力進一步提高。
▲
https://api-docs.deepseek.com/zh-cn/quick\_start/pricing
而價格下調最直接的影響,是把任務成本推到開發者決策的更前端。
在代碼場景裏,一次任務可能要讀取項目文件、分析日誌、多輪修改、反覆運行測試,Tokens 消耗很容易放大。
長上下文、代碼庫分析、批量重構、自動測試、Agent 多輪執行這些高消耗場景,開始更接近個人開發者和小團隊的預算範圍。
過去,開發者選擇 Claude、OpenAI 或 Gemini,主要看模型能力、穩定性、生態和使用習慣。DeepSeek 打骨折的永久降價,也意味着在絕對的性價比面前,開發者使用習慣也是可以輕易改變的。

順着這條線,DeepSeek 一貫的市場角色也更清楚了:用低價、開源和強推理能力,持續建立大模型市場的價格優勢。對國內模型廠商來說,V4-Pro 永久降價相當於重新劃了一條 API 定價線。
智譜、MiniMax、月之暗面這類同樣依賴 API 收費、又面向開發者和企業客戶的模型,壓力可想而知。反觀 Claude、OpenAI、Gemini 等海外頭部模型,由於市場、客戶結構和生態位置不同,短期衝擊則相對有限。
但如果 DeepSeek 後續推出類似 Claude Code 的編碼工具,再用低 token 成本支撐高頻調用,價格敏感的開發者群體會更容易被吸引過來。
梁文鋒此前對 DeepSeek 定價哲學的解釋,也能放到今天理解。
早在 2024 年 DeepSeek V2 降價時,梁文鋒就提到,DeepSeek 只是按照自己的節奏做事,覈算成本後定價,原則是不貼錢,也不賺取暴利。他還說,降價一部分來自下一代模型結構探索帶來的成本下降,另一部分原因是 API 和 AI 都應該是普惠的、人人用得起的東西。
比起把 API 當成高毛利收費入口,DeepSeek 則更像是在用過硬的 Infra 實力壓低推理成本,再用低價吸引開發者、應用和下游生態進入自己的軌道。
X 平台博主 @bookwormengr 最近在一篇題為《DeepSeek’s 10 trillion USD grand strategy(DeepSeek 的十萬億美元棋局)》的長文中,給出了一個更激進的解釋。
他認為,DeepSeek 的真正目標未必是和智譜、月之暗面、MiniMax 競爭,也不是急着補齊多模態、語音、視頻這些產品線,而是通過持續降低訓練和推理的資源需求,推動一套更便宜、更分散的 AI 硬件生態成形。
在他看來,DeepSeek 的長期價值不只在模型本身,而在於讓更多國產存儲、GPU、ASIC、網絡芯片和異構硬件進入大模型訓練與推理體系。

這個判斷未必能完全兌現,但它解釋了 DeepSeek 一系列選擇背後的方向:
MoE、MLA、DSA、GRPO、RLVR、KV Cache 壓縮、Dual Path、TileLang,表面上看是模型架構和推理工程優化,往深處看,都是在降低對高端 HBM、頂級 GPU 和 CUDA 生態的依賴。
一系列降價公告裏,最值得關注的不只是輸出價格下降,還有緩存命中價格下降。
在大模型推理過程中,KV Cache 是一個關鍵成本項。模型處理長上下文時,需要把歷史 tokens 對應的 Key 和 Value 存起來,後續生成時反覆使用。上下文越長,需要保存和讀取的緩存越多,對顯存、帶寬和存儲系統的壓力也越大。
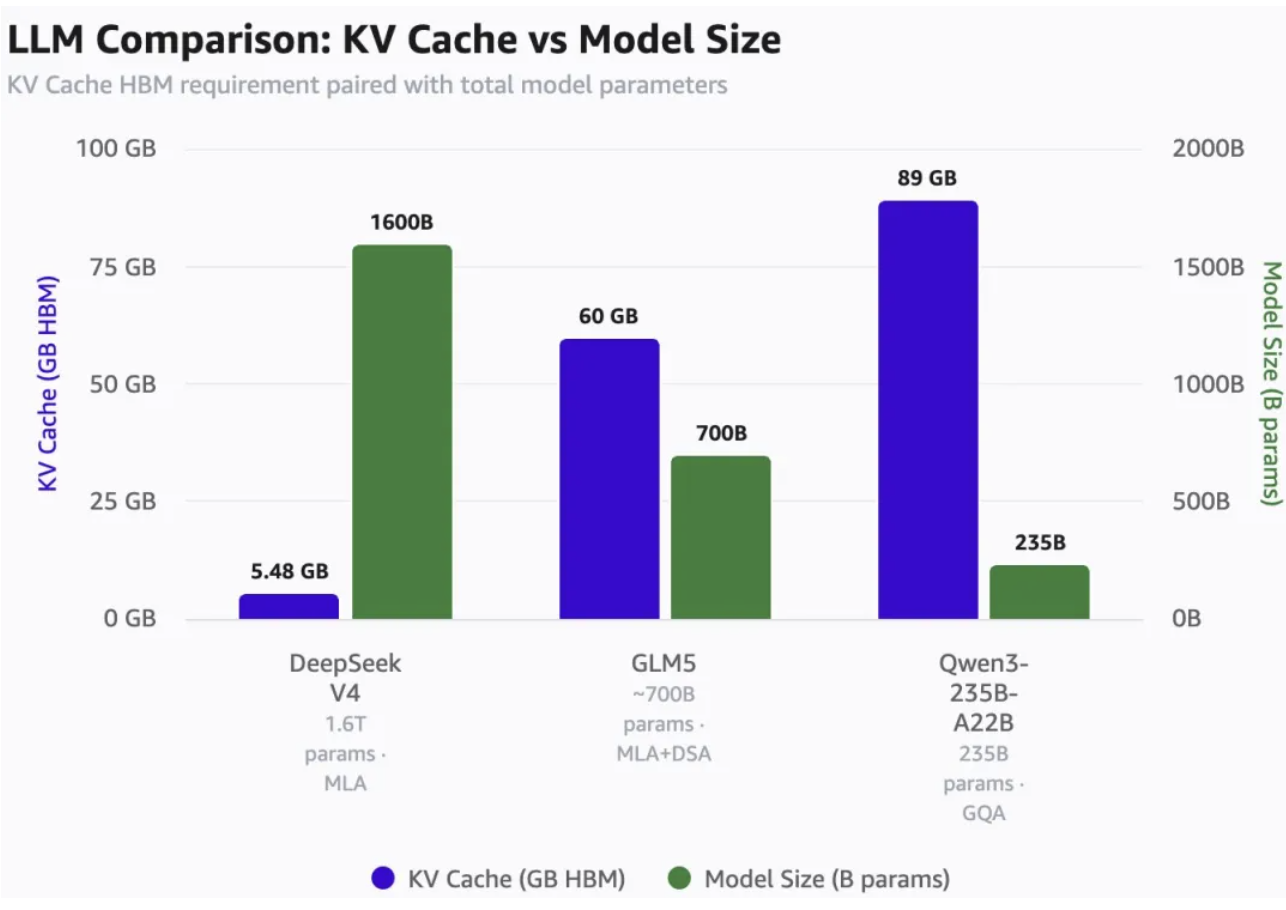
普通聊天裏,緩存壓力不一定明顯,但在進入代碼、長文檔和 Agent 任務後,成本結構會迅速變化。@bookwormengr 在長文裏專門算了一筆 KV Cache 賬。
他以 100 萬 tokens 上下文、8 bit KV 精度和 16 bit 索引精度為前提,估算 DeepSeek V4 只需要約 5.48GB HBM,而 GLM5 約為 60GB,Qwen3-235B-A22B 約為 89GB。
長上下文和 Agent 任務真正貴的地方,不只是模型生成本身,還有緩存、顯存、帶寬和重複上下文搬運。
一個 Code Agent 處理項目時,可能要反覆讀取同一個代碼庫結構、同一批文件、同一段任務歷史、同一套系統提示詞和同一批測試日誌。若每一輪都按完整上下文重新計費,長任務很快會變貴。緩存命中價格下降後,重複上下文的成本會明顯變低。
DeepSeek 近年來在 MoE 架構、長上下文、KV Cache 壓縮和推理效率上持續投入的表現有目共睹。降價是技術迭代後的必然結果,也將徹底攪動 AI 編程市場格局。
為什麼必須做中國版「Claude Code」?
最先被牽動的,是 AI 編程工具的訂閱模式。
市面主流 AI 編程工具均推出 Coding Plan 月付訂閱,為用戶提供代碼補全、模型調用、Agent 執行等權益。在輕量化補全時代,單次調用消耗極低。
但 AI 編程已從單次補全迭代為全流程 Agent 自動化編碼,模型可獨立完成代碼修改、測試運行、報錯修復,單次任務 Token 消耗大幅提升。
當底層 API 又同時大幅降價,Coding Plan 也必須找到新的支撐點。這個支撐點,更可能落在工程能力上——比如能不能更好地讀懂項目結構,能不能精準選擇上下文,能不能控制 tokens 消耗,能不能穩定修改代碼,能不能處理 Git、終端、CI/CD,能不能在企業環境裏管理權限和審計記錄?
同樣要重新定位的,還有 API 中轉站。對個人開發者來說,便宜和好用仍然重要。但對企業來說,穩定、可審計、可控、可遷移更重要。
沿着這個邏輯繼續看,Coding Plan 和中轉站的改變只是表層。低價之後更值得追問的,是開發者入口究竟掌握在誰手裏。

Google CEO Sundar Pichai 最近接受了《Hard Fork》採訪,他首次公開承認,Google 在文本、多模態、語音、推理和整體智能上都很有競爭力,但在 agentic coding 這一類能力上,尤其是工具調用、指令跟隨和長周期任務,目前還有差距。
他還提到,更關鍵的是把模型放到真實世界裏使用,讓數據迴流,繼續迭代。Pichai 特別說到,coding 是一個需要接觸 data flows(數據流)的領域。
終端工具能看到開發者如何提出任務,如何追問,什麼時候接受建議,什麼時候放棄,什麼時候要求模型繼續修復。它還可以通過測試結果、終端日誌、文件變更和 Git 提交,判斷一次 Agent 執行是否完成任務。這類數據,對 coding model 和 Agent 產品都非常有價值。
從公開招聘動作看,DeepSeek 近期圍繞 Agent 的動作也變得密集。
我們也可以看到崗位裏出現了 Agent 深度學習算法研究員、Agent 數據策略工程師、產品經理、研發工程師等角色。更關鍵的是,DeepSeek 資深研究員陳德里直接發出招聘信息,提到要從零開始構建 Code Harness。
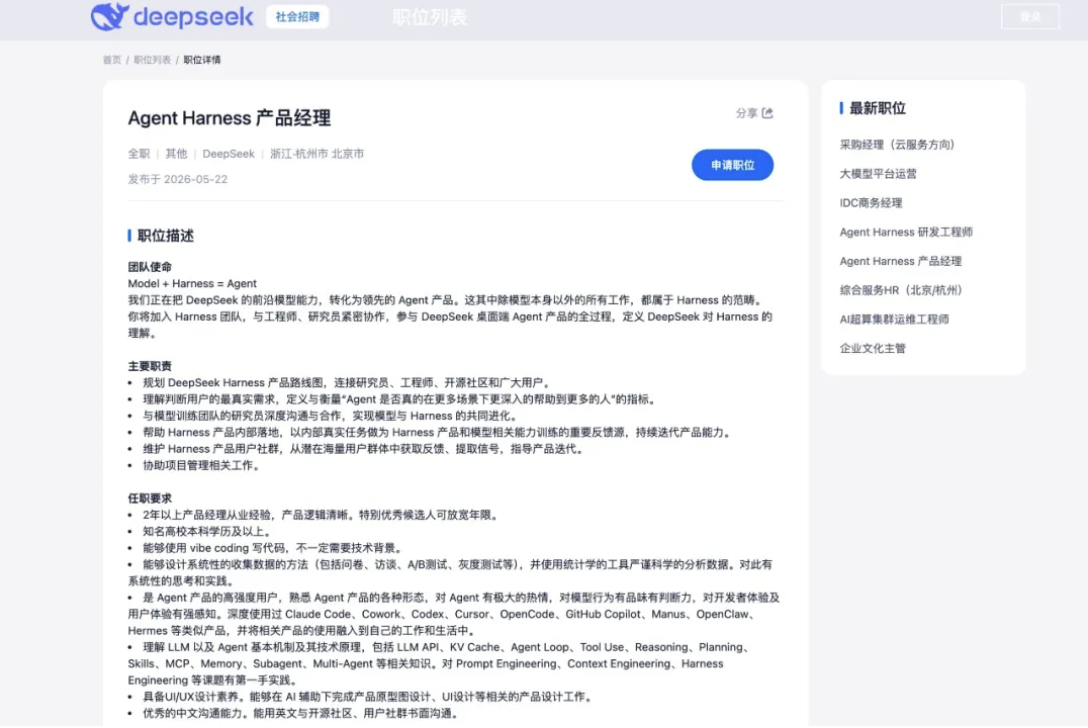
如其所說,Model + Harness = Agent,在 Agent 產品中,模型負責理解和生成,Harness 負責把模型能力帶入真實工程環境,相當於模型外面那套「執行系統」。
DeepSeek 版 Claude Code 不能只給開發者一個對話框,而要給開發者一個能持續執行任務的工程系統。
崔添翼加入 DeepSeek 後受到關注,也和 Code Agent 的工程屬性有關。
公開信息顯示,崔添翼本科畢業於浙江大學計算機系,曾因信息學競賽保送浙大,6 次獲得 ACM 亞洲區域賽金牌,之後在 Jane Street 工作 9 年,並聯合創立 TSY Capital。

Code Agent 的難點不只是生成代碼,還要在真實項目裏持續執行任務。量化交易系統長期強調低延遲、穩定性、自動化執行和風險控制,這些經驗放到 Agent Harness 上,至少在工程範式上是相通的。
而 Agent 工具的產品能力,不只包括寫代碼,也包括權限、審計、數據隔離和安全策略。
這反過來給 DeepSeek 這樣的國產模型提供了機會。如果 DeepSeek 能把低成本模型、Code Harness、本地部署、企業級權限控制結合起來,它在政企、金融、製造、能源等對數據敏感的行業裏,會有更強的替代價值。
DeepSeek 做中國版 Claude Code 的邏輯也正在於此:低價 tokens 把更多開發者吸引進來。低緩存價格讓 Agent 任務運行成本下降。Code Harness 讓模型進入開發環境。真實工作流又會反過來幫助 DeepSeek 改進模型和產品。
就像滾下坡的雪球,越滾越大,滾得越快。降價只是推下山的第一把力,往後它會自己越滾越沉,誰也攔不住。