
作者 | 王涵
編輯 | 心緣
智東西6月2日報道,近日,百度正式發布文心衍生視覺識別模型PaddleOCR-VL-1.6。
在權威文檔解析能力評測集OmniDocBench v1.6上,PaddleOCR-VL-1.6總指標達到96.33%,超越Gemini-3-Pro、GPT-5.2、MinerU-2.5-Pro、GLM-OCR等,綜合性能第一。
在面向真實複雜場景構建的Real5-OmniDocBench評測中,PaddleOCR-VL-1.6總指標達到93.19%,較 Gemini-3-Pro提升近4%,在掃描件、彎折文檔、螢幕拍照、光照變化及傾斜文檔等五大真實場景下均表現較優。
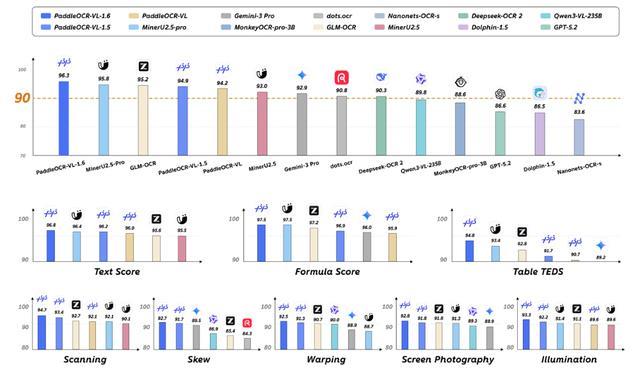
實測數據表明,相較於市面主流開源、閉源識別模型,PaddleOCR-VL-1.6在常規文字、數學公式、表格三大基礎識別維度綜合表現更優。
針對表格解析、繁體古籍、冷僻用字等高難度識別場景,該模型效果較上一代明顯優化,印章甄別、文字定位、圖表信息提取等細分任務性能也同步改善,可以適配各類文檔數字化落地場景的實際使用要求。

目前,PaddleOCR-VL-1.6已上線PaddleOCR官網,支持網頁端和API調用。同時,模型代碼及權重已同步開源至GitHub和Hugging Face。
PaddleOCR官網:paddleocr.com
Github:github.com/PaddlePaddle/PaddleOCR
HuggingFace:huggingface.co/PaddlePaddle/PaddleOCR-VL-1.6
據文心團隊介紹,PaddleOCR基於文心大模型訓練而來,是文心大模型多模態能力的重要部分,支持超100種語言識別,用戶覆蓋170多個國家和地區。
此次發布的PaddleOCR-VL-1.6,基於PaddleOCR-VL-1.5改進通過模型驅動的數據構建機制和漸進式訓練優化,在保持0.9B輕量化架構的情況下,模型準確率和複雜場景適應能力進一步提升。
由於兩代模型模型結構一致,開發者和企業用戶無需進行額外適配,即可平滑遷移。
近年來,百度先後推出PaddleOCR-VL、PaddleOCR-VL-1.5等多款模型。PaddleOCR的GitHub星數已突破79.2K,超過谷歌開源OCR項目Tesseract OCR。