
騰訊雲數據庫正在通過「DB For AI」和「AI in DB」兩條腿,構建屬於Agent時代的AI原生數據庫。
文|遊勇
編|周路平
數據庫技術的演進有着一條相對清晰的脈絡,過去十幾年國產數據庫的蓬勃發展大致可以劃分為三個階段。1.0時代,以騰訊雲為代表的一批互聯網廠商的數據庫系統誕生,他們大多源於自身業務發展需要,從單機數據庫轉向分佈式,成功扛住了互聯網業務的高併發帶來的數據洪峯,實現了國產數據庫的高可用和高可靠。
到2.0時代,自主可控的需求緊隨而來,國產替代成了業內的主導方向,大量關鍵基礎設施和重點行業的核心繫統開始進行國產替換。
如今,行業的指揮棒轉向了AI Agent,數據庫正式進入3.0時代。如何適應和滿足AI Agent的需要,已經成為了全行業的課題。
就在上周,騰訊雲數據庫面向Agent場景進行了產品的全面升級,為Agent、AI編程和智能運維三大場景提供原生的AI數據庫能力。當天,騰訊雲不僅發布了Agent Memory、DatabaseClaw兩款Agent原生產品,也對旗下最核心的雲原生數據庫TDSQL-C和分佈式數據庫TDSQL-B進行了系統性升級,全面適配AI原生。
01
Agent爆發,數據庫面臨多重挑戰
數據庫過去幾十年的演進邏輯並沒有發生太大改變,其本質是為人服務,比如控制台、註冊流程、文檔都是給人使用。但Agent依賴的是智能體之間的交互和工具的自主調用,數據庫的用戶從人變成了Agent,新的範式和業務需要改變了數據庫的運行邏輯。
首先,多模態數據成為主流。過去,數據庫處理的大量是訂單、用戶、交易記錄等結構化信息,但AI的爆發,使得數據形態發生了巨大變化,「現在92%的新增數據都是非結構化」,比如會話狀態、行業知識、上下文、圖片視頻等。
以前,單一模型的數據庫會針對特定類型數據進行優化。比如訂單、賬戶等結構化、強事務的數據,放在MySQL;半結構化、低延遲的數據放在MongoDB或Redis;非結構化的大文件放在對象存儲。
這也意味着,多模態數據天然就散落在異構系統之間,而一旦需要跨系統融合分析,應用層的開發複雜度急劇攀升,非常割裂和痛苦。

「在一個複雜的企業級 AI Agent 應用架構中,我們會依賴和傳統數據庫迥然不同的能力。」騰訊雲副總裁王義成說,比如查詢不再僅僅基於關係模型,而需要向量和語義;數據不再僅僅是結構化,而可能是文本、圖片。「這個時代真正需要的是多模存儲和語義檢索為原生的能力,並結合我們既有產品強項,例如高可用,支持SQL,高性能等,重新設計的產品。」
其次,是開發模式的轉變。過去使用數據庫,整體還是可預見的、訪問模式也相對固定。而Agent的併發規模遠超人工,對數據實時性也有更高的要求。尤其是當下,AI輔助編程讓很多非專業人士也可以通過多輪對話創建Agent,越來越多AI應用開始直接訪問數據庫,帶動了數據庫實例的數量大幅上升,而且Agent多步驟任務又要求中間存檔、隨時回滾,傳統備份恢復跟不上節奏。
「Agent是以人類無法比擬的速度去寫代碼、寫用例、進行測試,跟團隊做整體的組織協同,使得傳統數據庫的設計顯得比較笨重,無法匹配。」王義成說。而Neon的數據也顯示,2025年以來,由AI Agent創建的實例數量已經是開發者創建的4倍之多。
再者,數據庫調用模式也在發生變化。過去的數據庫偏離線分析,而Agent轉向實時檢索與持續性記憶。傳統的解決方案遇到了很大的瓶頸,比如上下文窗口有長度限制和成本焦慮,RAG檢索又丟失結構化推理路徑,需要為Agent打造專屬的記憶系統。
另外,隨着Agent能力的增強和數據庫治理複雜度的提升,Agent也在反過來協助DBA和研發人員更好地管理數據庫,包括用自然語言做數據庫的巡檢、故障排查以及SQL優化。
02
DB For AI,為Agent重做數據底座
隨着Agent在千行百業加速落地,業內也發現,Agent在真實場景的落地中最大的問題往往不是模型智商不夠,而是容易出現記憶斷片。
相比於過去問答型的人工智能,Agent這類複雜的長線任務,需要多步驟執行,需要調用各種工具和skill,非常考驗記憶能力。比如系統不僅要聽懂當下的指令,更要記得過去定下的代碼規範、約束條件和推進節點。
不久前,Meta的AI對齊與安全總監就因為AI「指令遺忘」,導致其個人郵箱中200多封郵件被小龍蝦批量刪除。
針對Agent的記憶痛點,騰訊雲數據庫重磅推出了Agent Memory服務,重新為Agent打造了一套記憶系統。其核心是通過引入結構化與分層機制,對記憶進行統一管理。
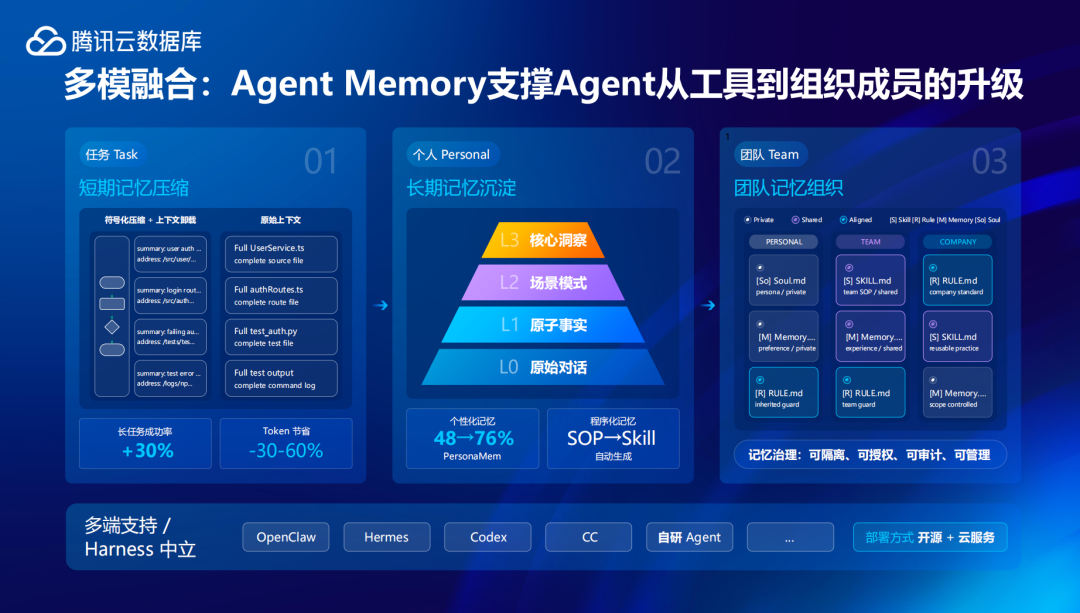
比如對短期記憶進行壓縮,騰訊雲數據庫自研了符號化壓縮和上下文的卸載能力。以符號化壓縮為例,主要有兩種思路:一種是摘要壓縮,將繁瑣的原始全文提煉為一行結構化的摘要,去掉廢話,留下事實,提升單條信息的密度;另一種是結構化圖壓縮——用一張圖替代一堆文字,讓結構化的圖來呈現不同操作背後的因果關係、狀態,用最少符號承載最大語義。
而且,騰訊雲數據庫針對短期記憶設計了一套三級壓縮策略,可以根據不同任務和負載,自動觸發不同級別的處理。比如當上下文佔比達到 60%時,自動用摘要替換原文,相對溫和;而當上下文佔比達到80%時,直接清理不再相關的舊任務消息,為當前任務騰出空間。
在長任務場景下,這套壓縮機制不僅幫助Agent提升了30%的任務成功率,也讓Token最高節省60%以上。「短期記憶我們做得比較領先,業界沒有太多的方案。」騰訊雲數據庫副總經理羅成說。
針對長期記憶,騰訊雲數據庫也設計了從L0-L4的語義金字塔:其中L0包含原始的對話記錄,L1是從對話中提取的原子化事實片段,L2是將原子事實組織成行為場景,L3則是從場景中歸納出用戶畫像、偏好、習慣用戶。
藉助這一機制,系統在執行過程中能夠調用更穩定的關鍵信息,而不再依賴單一上下文,比如底層的原子事實只在需要覈實細節時才按需檢索。
甚至,騰訊雲數據庫在短期記憶和長期記憶之外,也在推動構建團隊記憶。Agent在企業場景的應用往往依賴團隊協作,這意味着企業級Agent需要能共享整體團隊的上下文信息,理解同一套工作規則和標準,讓多個Agent能像團隊一樣協作。不難發現,在Agent從個人工具轉向組織協作的必然趨勢下,騰訊雲數據庫已經開始從記憶層面幫助企業做着相應的數據準備。
而騰訊雲數據庫的Agent Memory已經對外開源,並且在開源社區受到了歡迎。上線兩周時間,Agent Memory的開源代碼就收穫了近5K的Stars。
除了Agent Memory,AI也需要對會話的運行狀態、行業信息等,進行長期的保存。
而每一種數據庫都有各自的應用場景,比如結構化的業務數據用SQL查詢,知識庫語料又要用向量的召回,日誌跟文檔又要用全文搜索做關鍵詞搜索。這也使得在企業的IT環境裏,存在大量異構的數據庫系統。
「Agent可能花了80%的時間在找數據,只有20%的時間在思考怎麼用數據。「王義成說,Agent在執行任務時,要拿到一份完整新鮮的數據,往往需要穿越多套數據系統,應對不同數據庫的延時,以及適配多種數據庫的一致性協議。
針對這一痛點,騰訊雲數據庫發布了最新的TDSQL Boundless,這是一個面向AI時代的企業級多模態的數據存儲底座。它支持一鍵納管MySQL/PG、Mongo/Redis、COS、ES等數據源,讓文本、圖片、音視頻等不同模態數據可以在同一個數據庫內對齊。而且支持多模的計算,一次查詢能同時調動語義、關鍵詞、圖譜、聚合四種能力,「這是任何單一數據庫目前很難做到的」。
在存儲架構上,TDSQL-B支持本地SSD、雲硬盤和對象存儲的多級存儲雲原生設計,存算分離,彈性按需擴展。數據規模從GB平滑增長到數十TB無需手動分庫分表,冷熱數據自動分層至對象存儲,在保障高性能訪問的同時大幅降低存儲成本。
據悉,今年Q2,TDSQL Boundless將會重點推出面向向量索引和全文索引的應用場景,下半年則重點打磨基於對象存儲原生和統一開放原數據服務的能力,而明年上半年會着重增強混合檢索、融合檢索,以及提供更完整的多模體驗。
另外,針對AI Coding場景下數據庫頻繁複制、測試與回滾的新需求,騰訊雲TDSQL-C也做了一次系統性升級,既支持MySQL也支持原生PG,可以一站式對接騰訊雲cloudbase的baas平台以及Cursor、FastGPT等這些AI 開發者應用,用MCP、REST等協議統一接入。
這一次的升級核心是引入數據庫Branch能力,讓1TB數據庫從過去小時級複製壓縮至秒級「分叉」;疊加Serverless秒級啓動、閒時歸零的能力,更貼合 AI 編程「高頻創建、低頻使用」的長尾負載;提供AI Toolkit工具箱,實現了億級向量零損召回、列存實時分析提速10倍、向量檢索內存再降75%——RAG、長期記憶、實時洞察這些複雜AI需求,開發者不用再東拼西湊,一庫直達。
此外,TDSQL-C為了更好適配Agent應用,重構了新一代存儲架構,通過重寫日誌系統、寫入路徑和讀取路徑徹底解耦;引入多數派寫入協議,構建地域級全對等架構,告別木桶效應;原生支持行列混存,同一份數據、同一套日誌、同一份事務一致性——TP/AP不再需要兩套庫兩條鏈路;冷數據再下沉到對象存儲COS,備份快照和無限容量都順手解決。最終帶來的效果是:極致性價比,TCO較同類產品下降200%+;IO零抖動、全鏈路無損變更;數據零丟失,3 AZ金融級強同步、RPO=0。
03
AI in DB,給數據庫裝一隻龍蝦
數據庫領域對於AI的實踐,普遍有兩條路線。其中一條就是上述提到的DB for AI,讓數據庫更好地去滿足Agent的運行需要;另一條則是AI in DB,將Agent引入數據庫的運維和治理流程中,讓Agent幫助研發或者DBA做數據庫巡檢、故障排查以及SQL優化等工作。
這背後,是數據庫的運維正在遭遇一場不對稱的戰爭。
DBA緊缺已經是行業性難題,即便是在大型企業也是如此,而數據庫的分類非常複雜,這也增加了DBA的運維難度。甚至vibe coding的流行,讓很多非研發崗位的人也在大量創建數據庫實例。在如此內外交困的情況下,用Agent來進行數據庫的智能運維就成了剛需。
小紅書就是一個典型案例。業務的高速成長使得小紅書的數據規模迅速膨脹,而支撐業務的所有數據庫產品集群規模都在翻倍擴張,給後台負責運維的人員帶來巨大壓力。「傳統靠人肉、靠SOP、靠加人扛的路子基本上走到盡頭了。」小紅書數據庫DevOps專家許嘉正說。
作為騰訊雲首個數據庫Agent,DatabaseClaw可以做到一句話巡檢,並且生成結構化的巡檢報告,而且不管底下跑的是MySQL、Redis還是MongoDB,AI自動識別引擎,加載對應的診斷策略。它可以逐條解析執行計劃,告訴你哪些需要建索引、哪些需要改寫、哪些其實不用管。

但理想與現實之間依然還存在鴻溝。比如Agent對線上SQL慢查能分析得頭頭是道,但很多業務人員並不敢直接將AI的建議用於真實的生產環境。因為通用的AI沒有上下文,沒有調用內部的工具鏈,也沒有風險邊際和證據鏈的意識,往往只是單純根據SQL文本做了形式化的分析。
與通用智能體不同的是,騰訊雲DatabaseClaw基於過去十幾年服務客戶積累的十幾萬工單,將SOP流程沉澱為Skills,相當於讓Agent在執行各種任務時都有一套最佳用戶實踐。比如當數據庫出現慢SQL的問題,通用Agent往往會給出一個似是而非的建議,而DataBaseClaw會多做一步,先找到慢SQL產生的具體原因,然後對症下藥。
「DataBaseClaw能夠相比較之前一個人乾的活能夠有十幾倍效率的提升。」羅雲說。
除了把專家經驗煉化為可以直接調用的Skills,DataBaseClaw也實現了多引擎的統一納管。不同類型的數據庫有自己的特性和運維工具,比如MySQL要看緩衝池命中率,Redis要盯內存碎片,MongoDB要查慢操作。而DatabaseClaw用單一的Agent實現了MySQL、Redis、MongoDB、TDSQL四大主流引擎的原生覆蓋,DBA通過自然語言就可以查詢數據的狀態、生成報表,降低整體使用門檻。
相比於提高效率和易用性,安全可控是企業敢於將Agent用於真實生產環境的最關鍵一環。
不久前,一位SaaS企業創始人就發帖稱,他在使用智能體執行測試任務時,由於憑據不匹配,Agent竟自主搜索代碼庫找到一個無關的 API Token,把整個生產數據庫給刪除了。現實中,數據庫關係到企業業務的穩定,很多企業不敢將Agent用於真實的生產環境中,一些不合規範的操作可能對系統造成不可逆的損害。
而DataBaseClaw則從三個層面提高Agent的安全防護。一是設立行為護欄,相比於簡單通過Prompt工程對龍蝦進行限制,DataBaseClaw用了規則化或者持續化的方式在上層對龍蝦進行限制,比如只讀權限和分析權限分離,一些變更類的操作需要用戶二次確認。二是讓龍蝦的操作環境白盒化,DataBaseClaw部署在用戶可見的環境上,龍蝦安裝了什麼Skills,配置了什麼策略,用戶完全可知。三是全鏈路進行審計,關鍵的信息脫敏,整個鏈路只保留做什麼了,為什麼要做。
不難發現,DataBaseClaw通過融入人類專家經驗、設立安全護欄等方式,本質上是解決的是通用Agent目前能力邊界有限和安全風險失控的難題,幫助客戶真正敢於將Agent用於數據庫的真實運維環境中。
結 語
Agent帶來了全新的數據使用方式和複雜多元的數據形態,又給底層的數據庫帶來了巨大的機遇和挑戰。數據庫的價值在AI時代沒有被削弱,反而在增強。如何為Agent的高效運行打造一個AI原生數據庫,正在成為數據庫廠商們集體探索的方向。
在這條邁向AI原生數據庫的路上,騰訊雲基於全棧自研的數據庫底座,圍繞DB For AI和AI in DB的雙重佈局,已經構建了從AI應用開發到運維運行的完整鏈路。
模型決定了Agent的下限,而記憶決定了Agent的上限。在模型能力放緩、系統工程備受重視的當下,AI原生數據庫就是騰訊在Agent時代給出的最佳答案。