提到 AI 時代的最大贏家,差友們的第一反應,肯定是英偉達吧?
畢竟老黃這兩年靠着給 AI 廠商"賣鏟子",營收和市值都"遙遙領先"。而這一切,都得益於 20 年前老黃力排衆議,堅持 CUDA 生態——這一把,真讓他賭對了。
但你可能想不到,還有一家公司,左手拿着性能幹不過英偉達的顯卡,右手攥着 "過時" 的 4nm 工藝,居然也在 AI 競爭裏賺得盆滿鉢滿。
而它就是——A M D!
等會,這是怎麼做到的?
前段時間,託尼受邀參加了AMD的AI開發者大會,回來後,我對這個問題有了一些答案。

不過這事兒嘛。。。得從十多年前蘇媽靠銳龍翻身那會兒說起。
銳龍誕生之前,AMD 的處理器一直活在 "i3 默秒全" 的陰影裏。

直到 Zen 架構橫空出世——在 "硅仙人" 吉姆·凱勒的帶領下,初代銳龍 IPC 性能實打實提升了 52%,8 核 16 線程的規格,更是在那個 4 核稱王的年代震撼全場,也拉開了芯片廠之間 "核戰爭" 的序幕。

到了 2020 年的 Zen 3系列,AMD 終於一雪前恥:單核、多核性能雙雙幹翻了英特爾同期旗艦。
而 AMD 的這場勝利,也逐漸從消費市場蔓延到數據中心 B 端。說到數據中心,很多人現在的第一反應,應該是老黃和他的 GPU 的天下。
但其實,從早期虛擬機、雲服務,到如今的 AI,都離不開 CPU 的協調調度。
所謂數據中心,其實就是一個超級物流中心,本質是百萬級的 "小快遞" 同時配送。

即使單核 CPU 再快,面對百萬小件,那也是分身乏術;而多核 CPU,就像僱了一支龐大的「司機車隊」同時出發,還能通過「拼車」(虛擬化)服務更多客戶,把效率拉滿。
也就是說,到了數據中心這邊,別管這那的,我就要那個核多的超大杯。
尤其是現在 AI 智能體興起,工具調用、任務編排,還得靠 CPU 來幹活。以至於前段時間的 GTC ( GPU 技術大會 )上,老黃也掏出屬於英偉達的 CPU 來。

可這事兒呢,反倒是 AMD 的老本行了。在銳龍處理器證明了 Zen 架構的實力之後,AMD 的下一步,便是劍指數據中心。
十年前,數據中心的 x86 處理器,還是英特爾的一言堂:2016 年至強 Broadwell 最高 24 核,2017 年至強 Skylake-SP 最高 28 核。
可就在同年,AMD 開始爆種,掏出了 32 核的初代 EPYC 處理器。
而在接下來的十年裏,AMD 把 EPYC 的核心數一路堆到了 256 核 512 線程!英特爾也被迫跟進,做出了 128 個大核、288 個小核的產品……
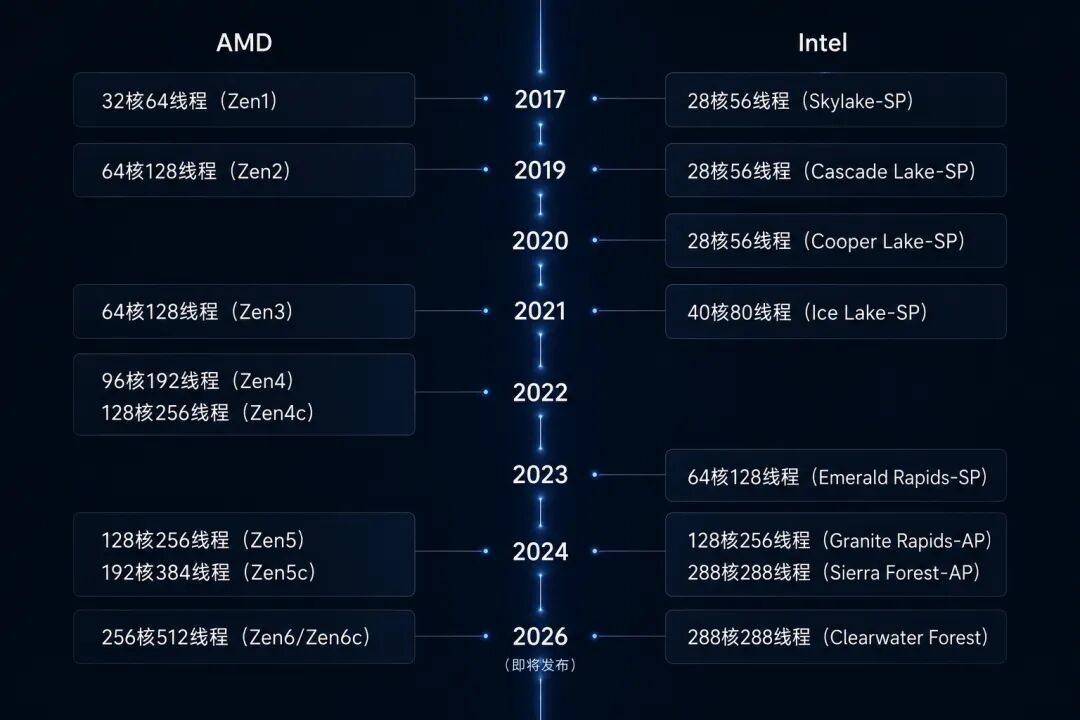
誰說英特爾不會堆核心?這不是挺會的嘛。
所以朋友們,不是英特爾突然有了良心,只是因為蘇媽來過。。。
當然,光靠"便宜大碗"給家人們謀福利還不夠,AMD 還祭出了殺手鐧——
3D V-Cache。
所謂 3D V-Cache,指的是在CPU上加一塊大容量緩存。像是最早的 5800X3D,把 L3 緩存加到了 96M,對比普通版翻了 3 倍。
緩存大,對於打遊戲來說,意味着幀數更高、更穩定。

但緩存大可不只對遊戲有用,在數據中心同樣能大殺四方。無論是需要超低延遲的金融交易,還是仿真計算、有限元分析這類重計算任務,都能靠 3D V-Cache 獲得誇張的性能提升。
就拿 EPYC 9684X 來說,96 核心塞了足足 1152MB 三級緩存,相比競品(至強 8490H)的優勢幾乎達到了 3 倍。
這些功能特性方面的投入,讓 AMD 在今年徹底收到了回報。事到如今,哪個數據中心會不喜歡 AMD 的 EPYC 處理器呢?
這種喜歡,在市場份額上就體現得非常真實:2019 年之前,Intel 在數據中心的份額一度高達 97%;可隨着 EPYC 的崛起,這個數字在 2025 年降到了 70% 左右。
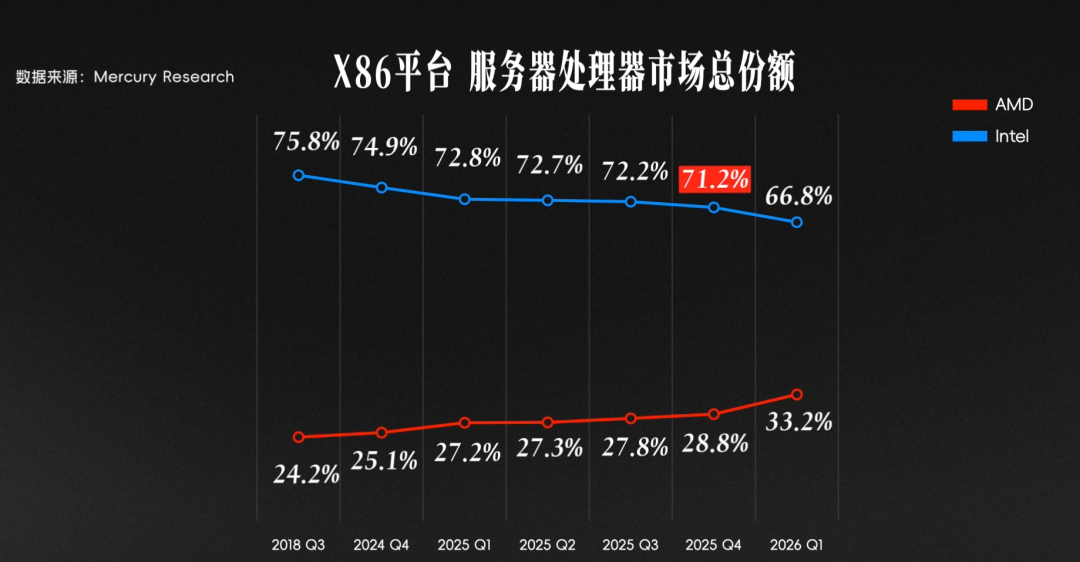
換句話說,AMD 只用了短短 6 年,就從零拿下了 30% 的市場份額。
看來真香定律,在數據中心這也是能成立的。。。

靠着向數據中心賣 CPU,AMD 再也不會像曾經一樣風雨飄搖,大廈將傾了。
當然了,大家也都知道,AMD 除了 CPU,也做顯卡生意的,然而 AMD 的顯卡 —— 也就是 GPU 業務,這兩年過的則是。。。

其實在 2018 年之前,AMD 還是能跟英偉達掰掰手腕的。2006 年收購的 ATi(也就是如今 AMD 的圖形部門),市場表現一直透着一股 "神鬼二相性":神的時候王牌對王牌,旗艦卡甚至能小勝英偉達;鬼的時候呢,旗艦卡只能勉強和老黃的中端卡過過招。
可轉折點,在於老黃的神之一手:2018年,老黃開始在消費級 GPU 當中集成 RT Core 和 Tensor Core,並且同步推出了光線追蹤和 DLSS 超分技術,如今這兩項技術,每個臭打遊戲的差友,應該都不會陌生。

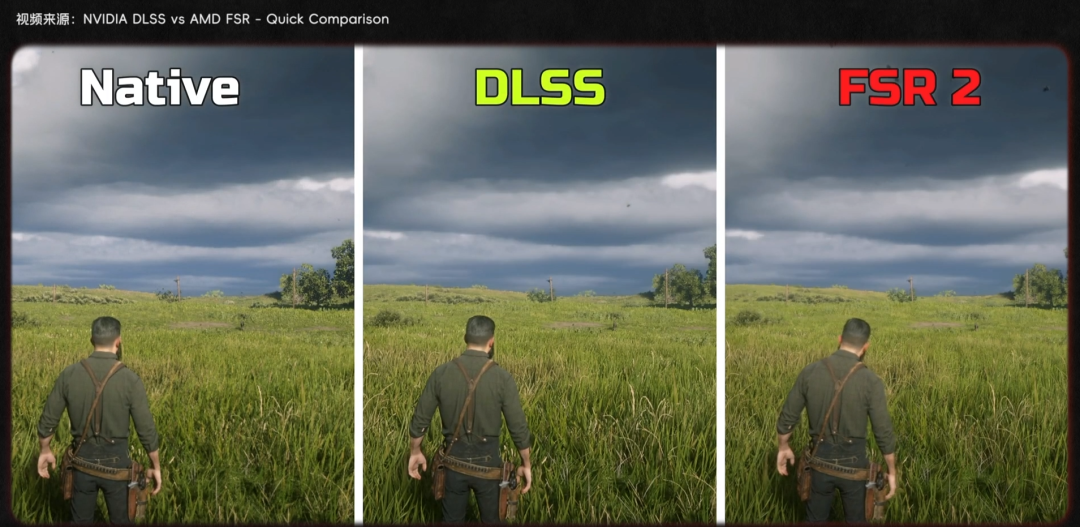
可正是這兩項顛覆傳統光柵化渲染的技術,讓 AMD 一下子陷入了被動:在這之後,兩年後的 6000 系、四年後的 7000 系顯卡,都沒能拿出像樣的光追和超分支持。
直到 2025 年 9000 系顯卡的發布,AMD 纔算有了不錯的光追表現。而 A 卡的超分超幀技術——FSR,早期更是用傳統算法糊弄。FSR 能用,但效果跟 N 卡的 DLSS 差着一截。同樣,直到隨着 9000 系一同推出的 FSR4,纔是真正基於 AI 的超分技術,能和 DLSS 在畫面表現上掰掰手腕了。

換句話說,AMD 在圖形技術方面,花了 7 年時間才追上老黃的佈局。
到了服務器端,劇情就更是大家熟悉的味道了:對 AI 支持最好、坐擁 CUDA 生態的 N 卡直接賣爆。AMD 這邊確實沒老黃那麼有前瞻性,對標 CUDA 的 ROCm 直到 2016 年纔出現,各類算法的支持和優化功底,也沒 CUDA 那麼深厚。
總結下來就是:無論是光追、超分超幀,還是大模型時代的軟硬件支持,又或者是硬件性能,AMD 的 GPU 確實不是英偉達的對手。
也正因如此,很長一段時間裏,AMD 的 GPU 都是靠"性價比"這一招,喫着老黃看不上的訂單。
而 AMD 維持性價比優勢的方法其實挺簡單:又不是什麼芯片都得用 2nm 先進製程,更便宜的 4nm,甚至 5nm 工藝其實也夠用了嘛。
成本更低,賣的自然也可以更便宜。
而倒有點「無心插柳」的感覺:隨着智能體引爆了市場對 CPU 和 GPU 的混合需求,AMD 正好是左口袋 CPU、右口袋 GPU,都能掏出東西來。

既然兩邊都能自研,那就可以整點不一樣的花活了。於是,AMD 嘗試偷師蘋果,把更大規模的 CPU 和 GPU 都塞進同一塊芯片,再把內存也整合進去。
AI Max+ 395 應運而生。這顆 U 在一顆芯片裏,塞入了 16 核 CPU 和 40CU 的 「核顯」,性能堪比獨顯的同時,又可以共享系統內存,用超大內存直接跑大模型。

曾經這個活只有蘋果能幹,可一台大內存的 Mac Studio 動輒三五萬,而一台 395 的小主機只要一萬多。雖然依舊不便宜,但對於那些重度使用大模型、同時又有隱私顧慮的小夥伴來說,這個價錢其實……挺划算的。
當然了,AMD 如今的問題也不少。
就拿 AI Max+ 395來說,生態短板依舊明顯。託尼有同事一直用它跑本地大模型:面對主流的 LLM 模型,AMD 的兼容性沒啥問題;可一旦想試試圖片或者視頻生成模型,又或者想進行模型微調,就不好說了。
面對生態劣勢,一方面 AMD 把 ROCm 開源,想要借社區的力量來實現對 CUDA 的"彎道超車"。
另一方面,在這次 AMD AI 開發者大會上,蘇媽給出了一個更適合 AMD 的答案——圍繞性價比,構建一套屬於自己的 AI 生態。

具體來說就是:開發者可以在 AI Max+ 395 這類終端上快速實現想法,再用 AMD 顯卡的工作站做微調測試,最後在數據中心用 AMD GPU 完成生產部署。整套流程都跑在 AMD 的軟件生態裏,遷移起來自然順暢得多。

理論歸理論,實際用起來怎麼樣?
大會上給出了答案:單台 AI Max+ 395 最大支持 128GB 統一內存,能把 Qwen 122B 模型跑在本地;

4 台 395 互聯,還能搞定更大更復雜的任務。同時,AMD 還宣佈了與魔搭社區的合作,每人有 100 小時的雲端算力體驗時間——好不好用,自己試試就知道。

不論是拿下"過時"產能,在硬件上堅持性價比;還是上個月結束的 AI 開發者大會,如今 AMD 的種種動作,也是在嘗試打造屬於自己的軟硬件生態。
今年 AMD AI 開發者大會,選在了對 AI 開源貢獻最大的中國,足以見得 AMD 對生態的重視。

當補齊生態這塊最短的板之後,即使 AMD 頂着"落後"工藝,性能也比不過的雙重 Debuff,恐怕也能在市場殺出屬於自己的一片天。
撰文:洛洛 & 米羅
編輯:米羅
美編:素描
圖片、資料來源:
AMD官網
2026 AMD AI開發者大會
2026 GTC
How Chip Giant AMD Finally Caught Intel
Mercuy Research