智東西
作者 | 程茜
編輯 | 心緣
智東西6月24日消息,啱啱,阿里千問大模型上新,發布首個原生語言世界模型(LWM)Qwen-AgentWorld,該模型有35B-A3B與397B-A17B兩種參數規模。
該模型專門為各類AI智能體研發與訓練而生。在博客中,研究人員提到,該語言世界模型的核心目的不是降成本、替代智能體的真實交互環境,而是為了增強通用智能體的能力。其可以讓智能體在做動作前,先在內部模擬環境反饋再決策。
Qwen-AgentWorld兩大核心亮點為:
從預訓練階段就將環境建模作為訓練目標,貫穿CPT→SFT→RL全流程。此前完整訓練通用基礎大模型,往往會在訓練結束後,纔開始教AI理解環境、預判操作結果。
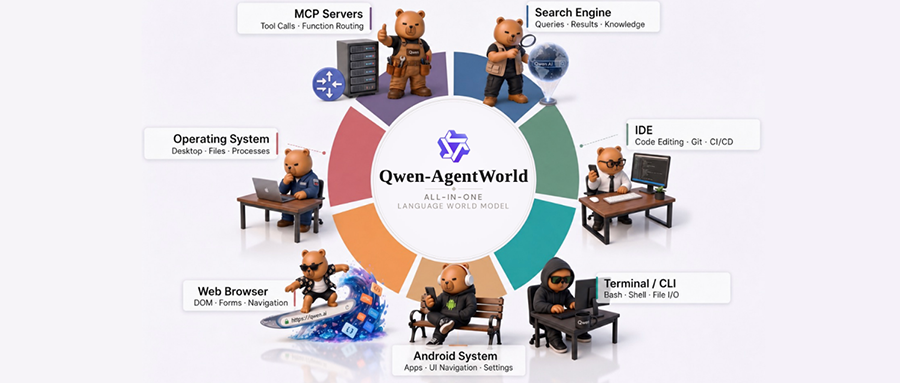
單一模型同時覆蓋7類環境,包括文本類環境(MCP、Search、Terminal、SWE)與GUI類環境(Web、OS、Android),實現跨領域知識遷移。
例如下圖,Qwen-AgentWorld可以模擬手機系統,左側為手機界面的初始狀態,右側為讓Agent點擊工具欄中的刪除圖標的操作預測。
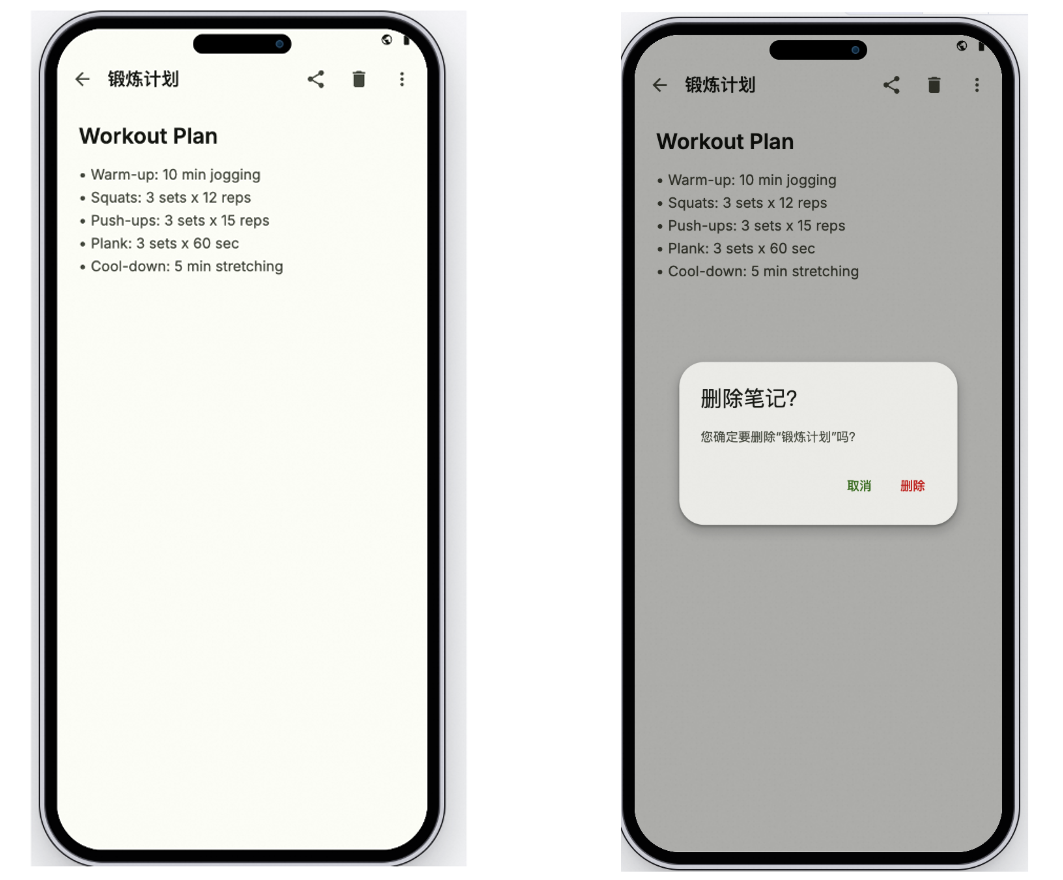
研究人員在博客中提到,LWM並不是為了取代真實環境,真實環境交互始終是確保智能體行為可靠性的黃金標準,LWM提供的是一條互補路徑,其具備超越真實環境的可擴展性與可控性,還有內化的世界預測能力。
此外,阿里還發布了配套的覆蓋七大領域的語言世界模型評測基準AgentWorldBench。
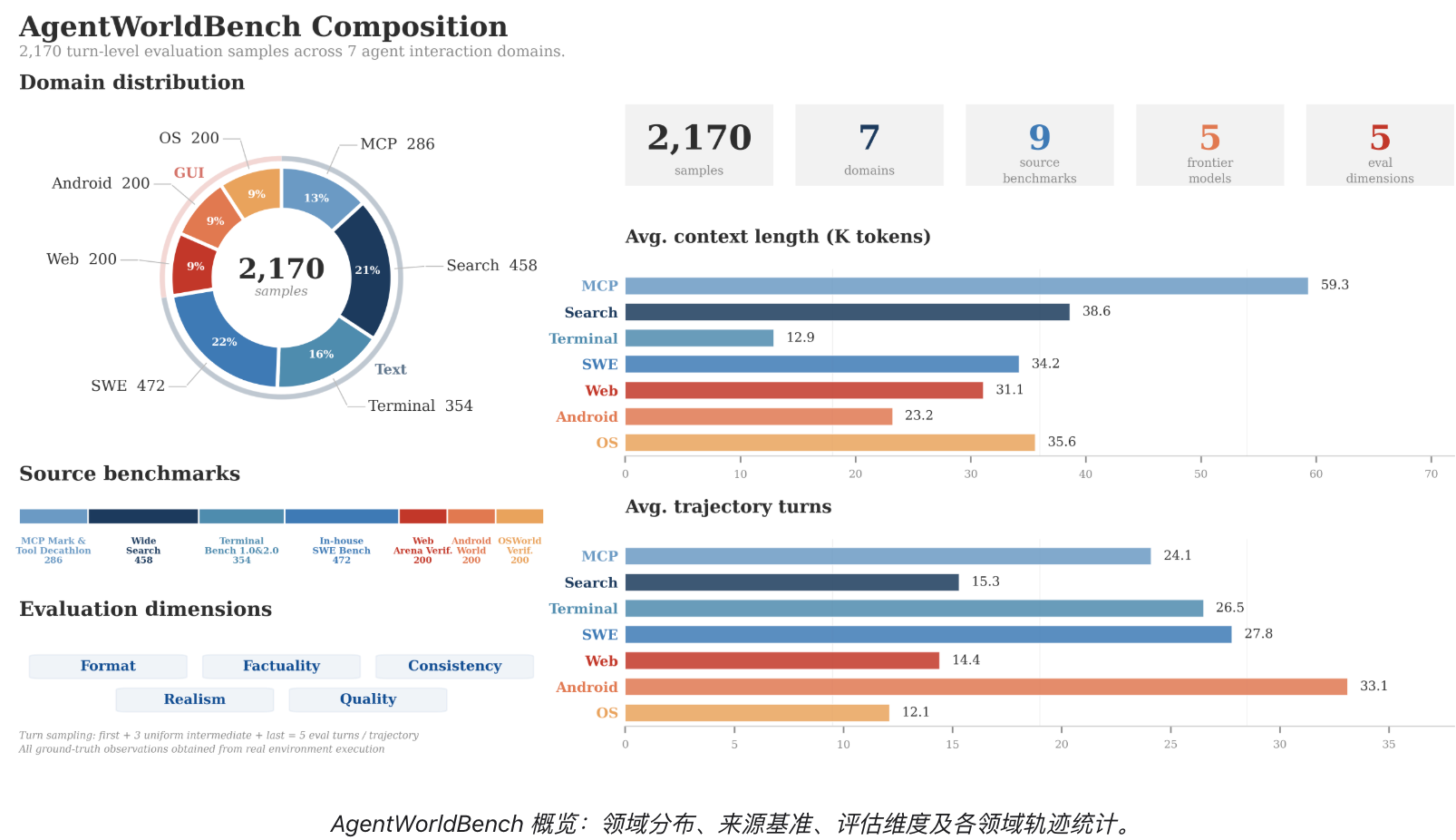
▲AgentWorldBench概覽
阿里開源了Qwen-AgentWorld-35B-A3B(模型權重)和AgentWorldBench(評估基準)。
▲AgentWorld開源主頁
GitHub開源地址:https://github.com/QwenLM/Qwen-AgentWorld
ModelScope開源地址:https://modelscope.cn/collections/Qwen/qwen-agentworld
Hugging Face:https://huggingface.co/collections/Qwen/qwen-agentworld
一、覆蓋7類環境,支持跨領域知識遷移
Qwen-AgentWorld單一模型同時覆蓋7類環境,包括文本類環境(MCP、Search、Terminal、SWE)與GUI類環境(Web、OS、Android),能實現跨領域知識遷移。
對於三個GUI領域,環境觀測以可渲染代碼(無障礙樹XML、HTML、UI層級標記)而非像素幀的形式呈現,使得僅憑純文本世界建模即可覆蓋視覺環境。
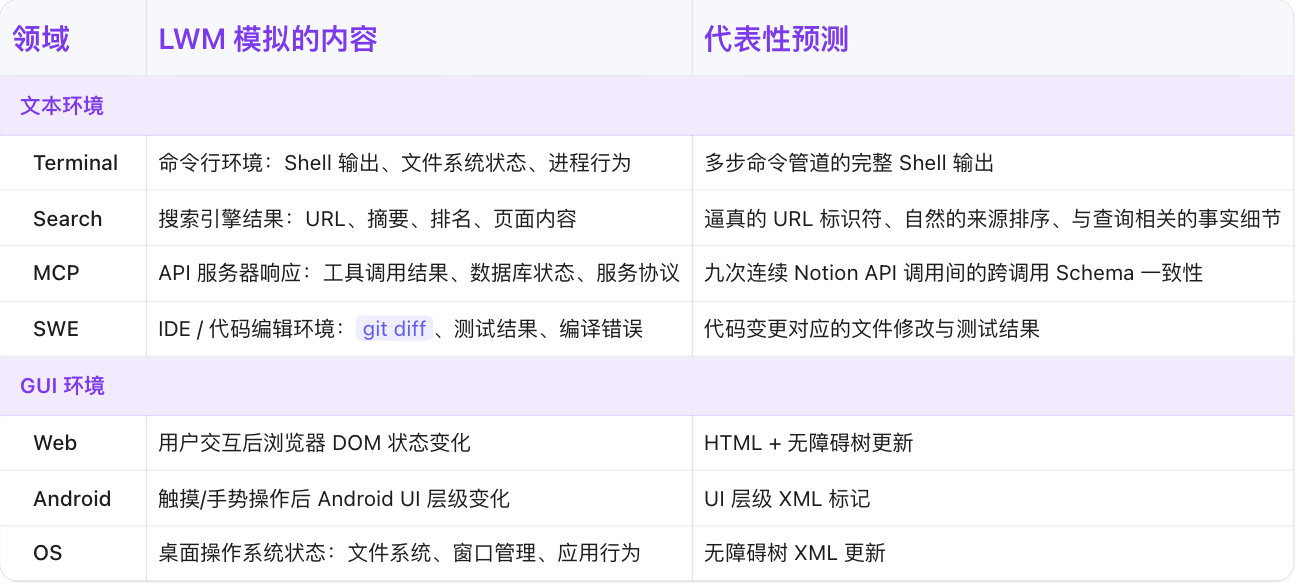
▲Qwen-AgentWorld可模擬的7類交互環境
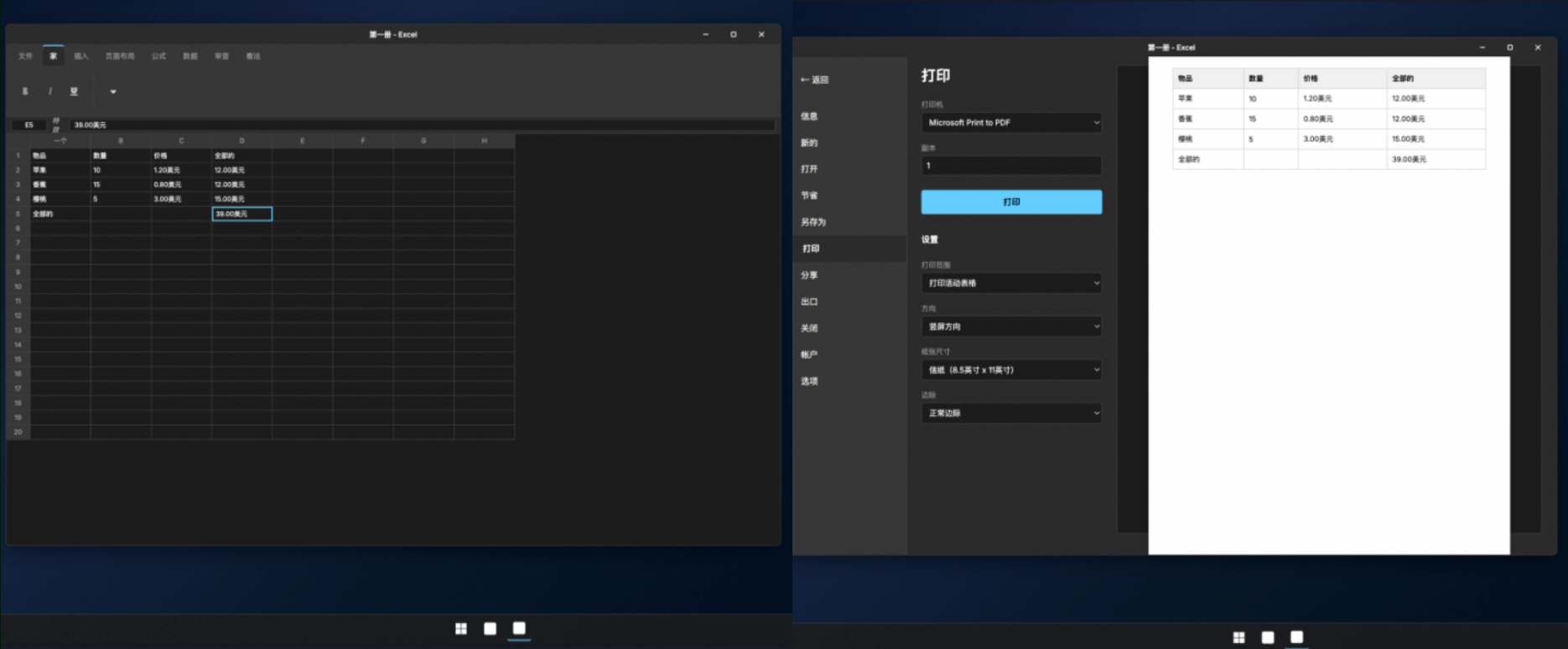
Qwen-AgentWorld可以模擬電腦系統,例如下面左側就是電腦初始界面,右側為Agent從菜單欄中單擊「文件」>「打印」的操作預測。
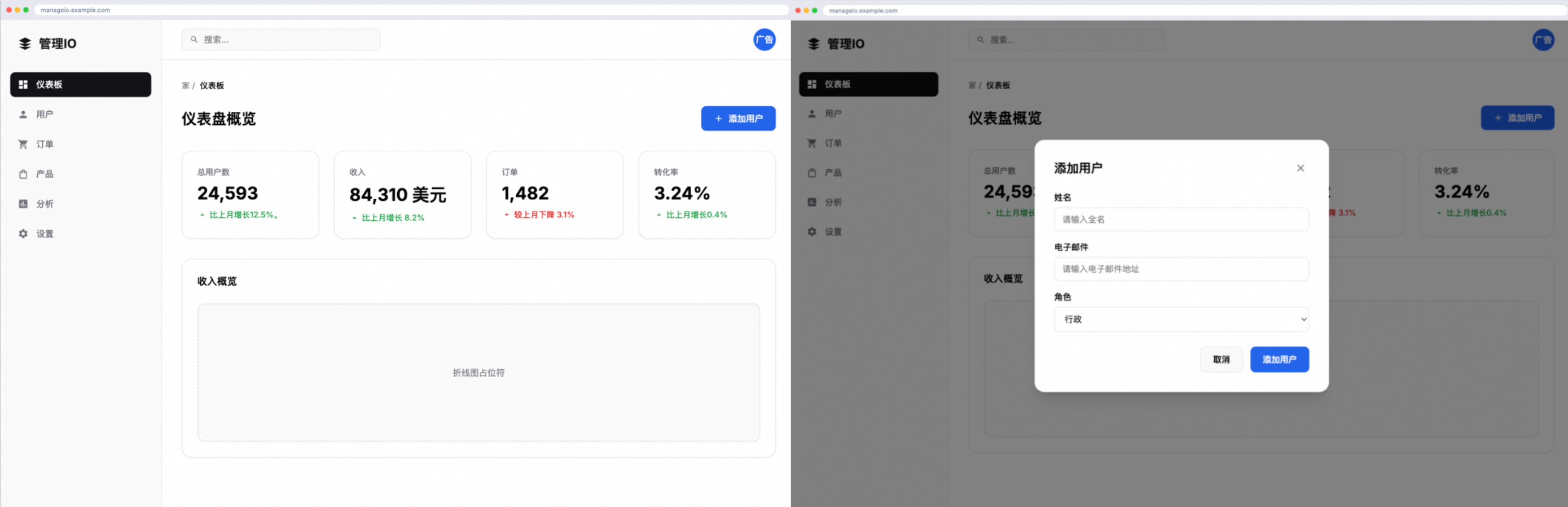
該模型還能模擬網站交互,下圖左側就是某網站的儀表盤界面,右側為Agent點擊「添加用戶」按鈕的操作預測。
在博客中,阿里研究人員提到,他們希望探索基於語言模型的世界建模,能否進一步拓展通用智能體能力的邊界。
第一個方向是構建智能體環境模擬的基礎模型:Qwen-AgentWorld是首個在單一模型中覆蓋七大智能體交互領域的語言世界模型,基於超過1000萬條真實環境交互軌跡,經由CPT→SFT→RL三階段訓練而成。

▲三階段訓練流程
第二個方向是探討世界建模在智能體訓練中的作用,並通過兩種互補範式加以驗證:作為解耦的環境模擬器,它為智能體強化學習提供了更優的可擴展性與可控性,可控的模擬RL能夠以真實環境無法實現的方式塑造智能體行為,且顯著優於僅在真實環境中訓練的RL。
作為統一的智能體基礎模型,LWM的預訓練可有效遷移至涵蓋七個基準(其中三個完全未出現在訓練集中)的多輪智能體任務,且無需針對智能體任務進行任何RL微調,初步驗證了語言世界模型能夠作為構建更強智能體模型的基礎。
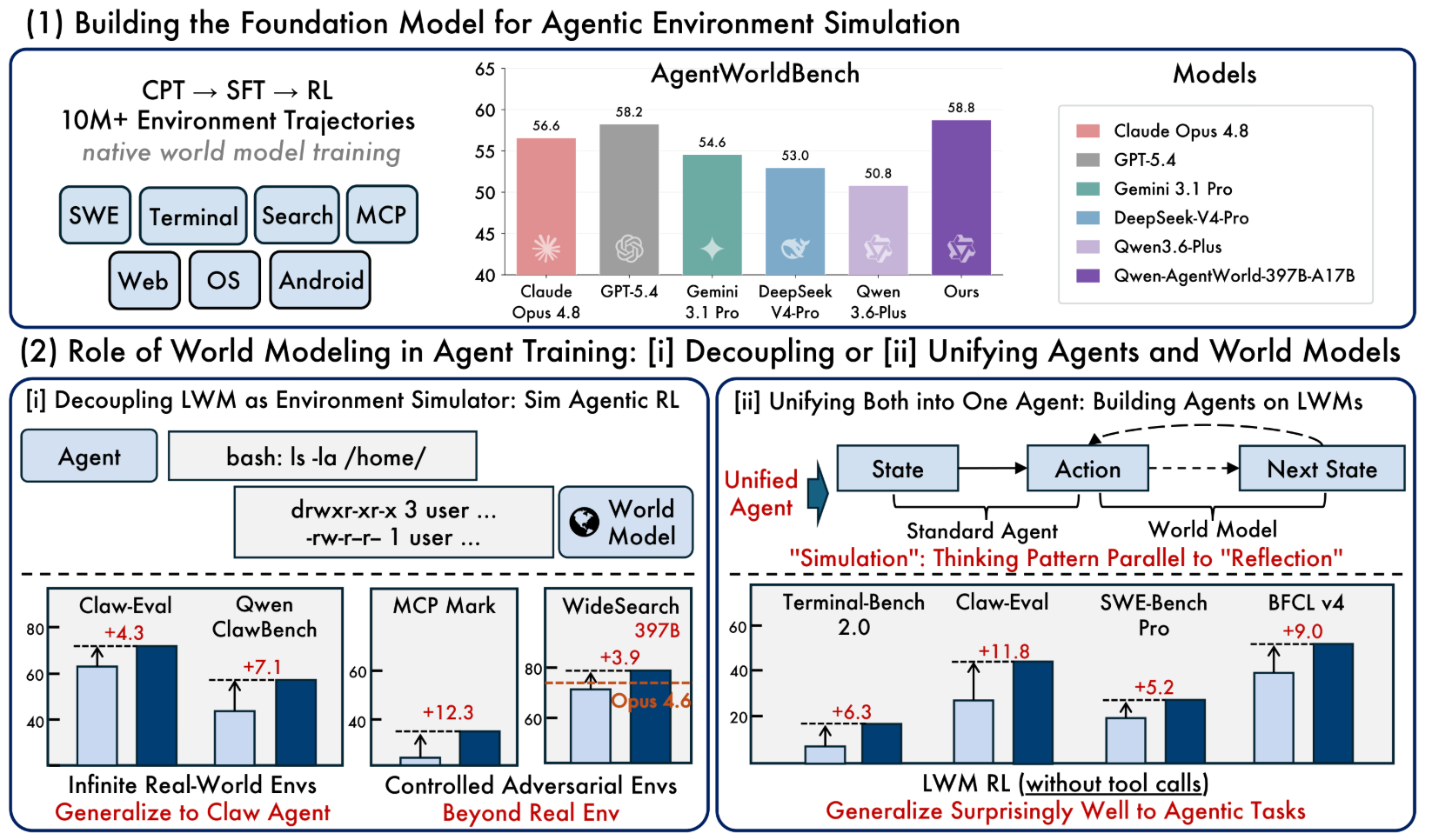
▲Qwen-AgentWorld架構圖
二、整體模擬質量超Claude Opus 4.8、Gemini 3.1 Pro
為系統評估語言世界模型,研究人員推出綜合性評測基準AgentWorldBench。
該基準基於5個前沿模型在9個成熟評測集上的真實環境交互觀測構建而成。AgentWorldBench採用開放式評分準則(rubric),從格式、事實性、一致性、真實性和質量五個維度全面評估世界建模能力,深入考察模型的推理能力、領域知識以及長上下文處理水平。
在AgentWorldBench評測中,Qwen-AgentWorld-397B-A17B的整體模擬質量超越GPT-5.4、Claude Opus 4.8與Gemini 3.1 Pro。
Qwen-AgentWorld-397B-A17B在AgentWorldBench上取得最高的整體均分(58.71),超越GPT-5.4(58.25)及所有其他前沿模型。這一優勢在Terminal和SWE兩個領域最為顯著,研究人員認為這是因為這兩個領域的預測需要準確模擬代碼執行狀態和工具API行為。
在35B-A3B規模上,三階段訓練流水線將整體均分提升了8.66分,使Qwen-AgentWorld-35B-A3B的表現超過Claude Sonnet 4.6。這一提升在文本類和GUI類領域中均保持一致。
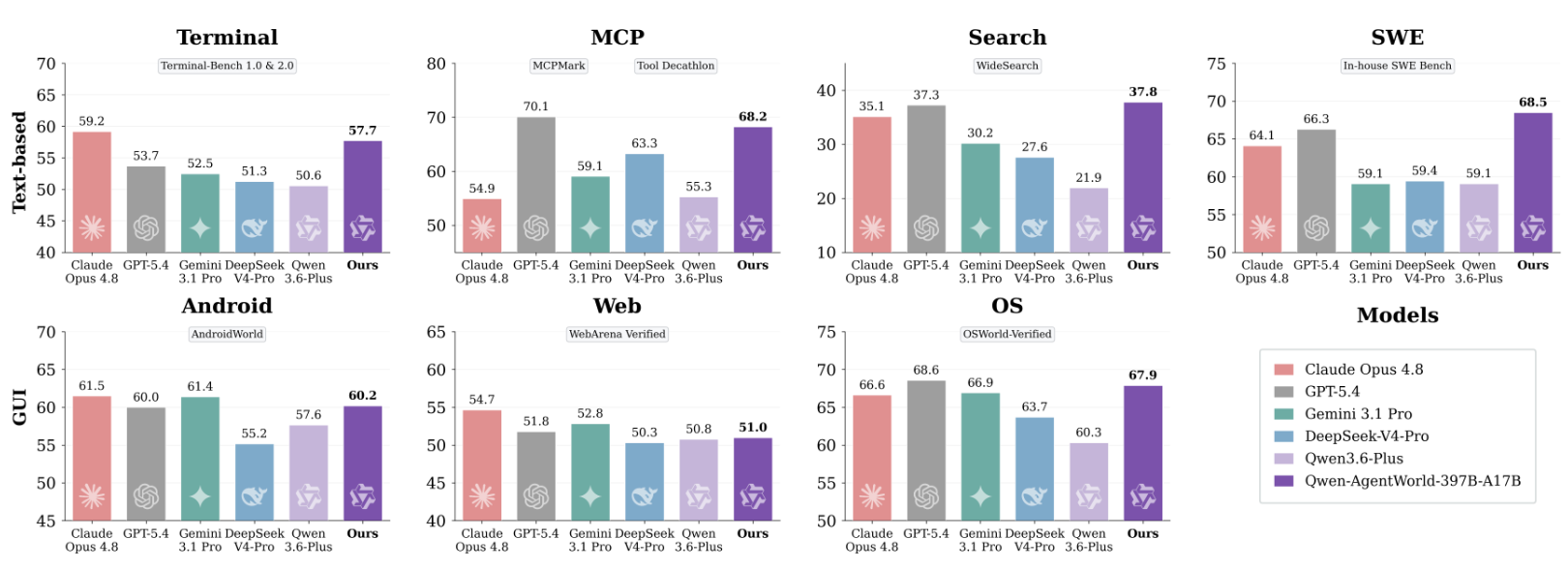
▲AgentWorldBench評測結果
三、湧現3種推理模式:自糾錯、防信息泄露、多步因果推理
在整體分數的分析之外,研究人員還分析了4個文本類領域的129條思維鏈,發現3種湧現的推理模式。
自我修正:模型使用「Wait!」作為自我糾錯的觸發信號,以修正中間預測。在129個輪次中有1347次此類中斷(平均每turn 10.4次),包括事實錯誤、知識邊界或視角轉換等情況。
信息泄漏防護:在搜索領域,模型已知智能體正在搜索的參考答案,當查詢與答案無關時,模型通過確保摘要不會意外透露目標來防止泄漏。
多步因果推理:預測curl -s localhost:3000 | python3 -m json.tool的輸出需要一條6步推理鏈:Node.js缺失→服務器未啓動→端口3000無監聽→curl靜默失敗→空管道→json.tool拋出JSONDecodeError。
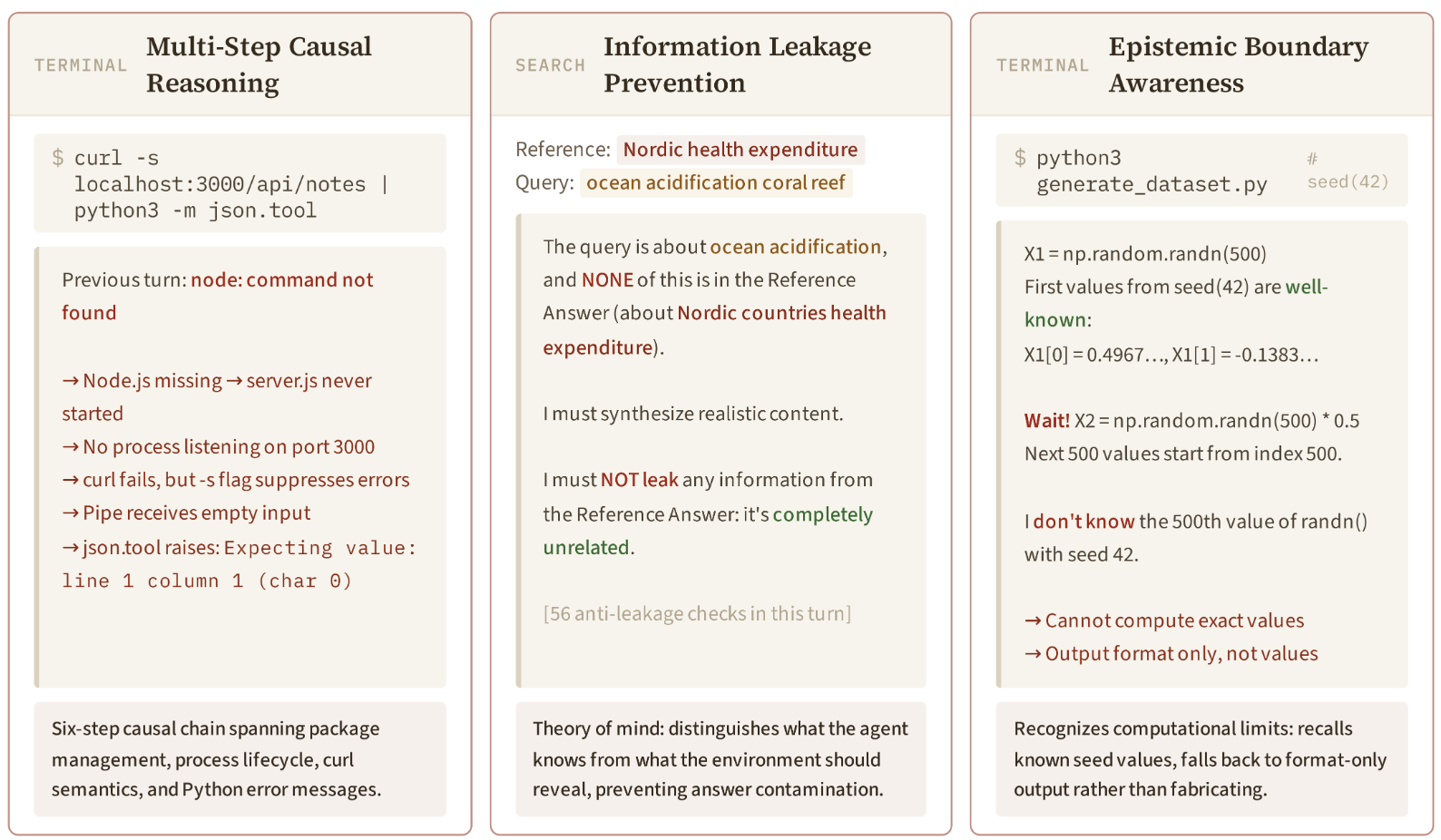
▲Qwen-AgentWorld的推理模式
結語:單一模型統一七大交互環境,語言世界建模或打開通用智能體新路徑
Qwen-AgentWorld是一個原生語言世界模型,在單一模型中覆蓋七大智能體交互領域,基於此研究人員探索了世界模型加強通用智能體的兩種互補範式。
作為統一智能體基礎模型,語言世界模型(LWM)的預訓練可遷移至涵蓋七個基準的多輪智能體任務,初步驗證了語言世界模型能夠作為構建更強智能體模型的基礎。語言世界建模或開闢了一條互補的擴展路徑,推動通用智能體超越真實環境交互的能力上限。