(本文作者為 AI唱反調,鈦媒體經授權發布)
文 | AI唱反調
阿里、 Momenta、英偉達最近都在講"世界模型"。阿里那個能讓 AI 幫你操作電腦,Momenta 那個能讓車預判路人下一步,英偉達那個能生成逼真的暴雨視頻。如果不太關注技術細節,大概率會以為這是同一個方向的三次突破,像同一個班裏的三個學霸同時考了滿分。
真相很直接:這三樣東西除了名字一樣,幾乎沒有任何關係。把它們統稱為"世界模型",就像把"世界地圖""世界時鐘"和"世界觀"當成同一類東西。字面上都有"世界",實際各說各話。
阿里做的是讓AI 在電腦裏先試錯的"數字沙盤",Momenta 做的是讓自動駕駛預判路況的"老司機直覺",英偉達做的是給 AI 造訓練素材的"虛擬片場"。三個"世界",三條平行線,誰也不挨着誰。
同名不同命
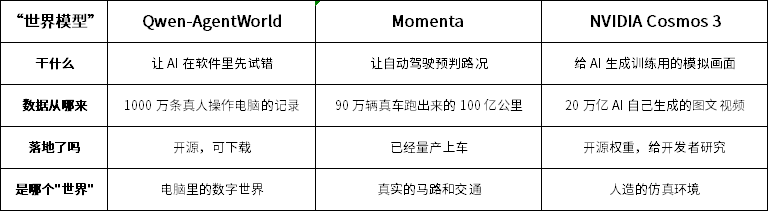
第一個是阿里Qwen-AgentWorld,本質上是一個給 AI 用的"數字沙盤"。
它把瀏覽器、電腦桌面、手機界面、代碼編輯器這些環境打包成一個虛擬遊樂場,讓AI 在裏面先試錯、再行動。比如操作某個軟件會不會點錯按鈕,先在沙盤裏預演一遍,成功了再去操作真實的電腦。這基於超過 1000 萬條真人操作電腦的記錄訓練。AI 看了上千萬次真人怎麼寫代碼、怎麼搜索、怎麼填表格,學會了"點這裏之後通常會發生什麼"。
它的"世界"是電腦裏的數字空間:網頁、App、代碼倉庫。和真實的馬路、真實的機器人沒有直接關係。
第二個是Momenta,那套已經量產上車的系統,它是自動駕駛的"預判本能"。
自動駕駛最大的難點已經變了。現在的問題不再是"看清前面有什麼",變成猜出下一秒會發生什麼。前車突然減速,是要靠邊停車還是臨時踩了一腳?路邊行人是要過馬路還是等公交?Momenta 就是讓 AI 提前在腦子裏過一遍未來幾秒的交通畫面,然後選最安全的動作。這背後不只是直覺,還涉及感知、預測、規劃多個模塊的協同。
關鍵是,這東西已經量產了。Momenta 有 90 萬輛車在跑,積累了 100 億公里的真實駕駛數據。這些視頻不只是"看着玩",裏面包含"當時做了什麼、車怎麼反應、結果對不對"的完整因果鏈條。它的"世界"是真實的物理世界:馬路、車輛、行人、雨雪天氣。
第三個是NVIDIA Cosmos 3,它是給 AI 造訓練素材的"虛擬片場"。
它的核心能力是生成逼真的視頻畫面,但這些視頻不是拿來刷的,是給機器人和自動駕駛當練習題用的。比如想讓AI 學會"暴雨天路面反光看不清車道線"怎麼處理,現實中不可能天天等暴雨,Cosmos 3 就生成一段暴雨開車的視頻,讓 AI 在虛擬畫面裏反覆練。
它開源了權重,能處理文字、圖片、視頻、聲音、動作指令五種信息,20 萬億 token(token 是 AI 處理信息的最小單元,文字、圖像、視頻、聲音都會被切成這種"小塊"喂進去)說明它看過、生成過巨量素材。但關鍵是,這些畫面屬於"合成數據",AI 自己造的,不是真實拍攝的。好處是成本低、場景全;壞處是"仿真"和"真實"之間永遠有差距。
它的"世界"是人造出來的仿真環境,本身不直接開車,也不直接操作電腦,只給其他 AI 提供練習題。
世界模型:一個被掏空的標籤
其實"世界模型"定義混亂這件事,學界自己也頭疼。今年 6 月初,李飛飛團隊在 MIT Technology Review 發文,標題就叫《當視頻生成、機器人和 NVIDIA 都自稱世界模型》。文章裏提到,Sora 被叫世界模擬器,Genie 被叫世界模型,現在連做自動駕駛的、做機器人的都在用同一個詞。
6 月中旬的智源大會上,智源研究院院長王仲遠乾脆把世界模型分成了四大類:以語言為中心的、以像素為中心的、以三維結構為中心的、以視覺表徵為軸心的。看,連頂尖研究者都沒法統一口徑。
那三者的共性到底是什麼?它們都在做"預測"或"模擬"。預測點一下鼠標會發生什麼,預測前車減速後下一秒的路況,預測暴雨天的路面長什麼樣。但預測的對象完全不同:一個在預測數字環境裏的操作後果,一個在預測物理世界裏的交通演變,一個在預測仿真畫面裏的場景參數。
這就好比"預測"這個詞,可以預測股票、預測天氣、預測孩子考多少分,都是預測,但乾的事完全不同。世界模型現在就是這個狀態:同一個詞,被用來描述三種完全不同的能力。
閉環定生死
這三個"世界模型"不會合併成同一個東西,未來會沿着三條線走。

第一條是數字世界模型,解決"AI 怎麼操作軟件、怎麼寫代碼"的問題。由 Qwen、OpenAI、Claude 這類公司主導。特點是迭代快、數據成本低,因為電腦裏的操作記錄很容易獲取。和我們關係最近:以後用的 AI 助手,可能先在後台沙盤推演一遍,再幫忙訂機票、填表格。
第二條是物理世界模型,解決"自動駕駛怎麼安全開車、機器人怎麼搬東西"的問題。由 Momenta、Tesla、華為這類公司主導。特點是數據成本極高,需要真車去跑,但一旦形成閉環,壁壘極深。和我們關係:以後坐的車、看到的無人配送車,背後都是這類模型。
第三條是基礎設施線,NVIDIA 的角色更像一個"賣鏟子的"。Cosmos 3 提供合成數據,讓上面兩條線的開發者都能用,但它自己不直接開車,也不直接操作電腦。它賺的是"造影視基地"的錢,不是"拍戲"的錢。
判斷誰更領先,別隻看參數大不大、開源不開源。真正重要的指標是閉環,AI 在真實環境裏用了之後,能不能把結果反饋回來,讓自己變得更聰明。
Momenta 的閉環最紮實。90 萬輛車每天在路上跑,AI 預測錯了,數據就會回來告訴它"下次別這麼猜"。這種真實世界反饋是合成數據替代不了的。
Qwen 的閉環在數字世界。1000 萬條真人操作的成功和失敗經驗被記錄下來,成了 AI 的教材。在"讓 AI 操作軟件"這個賽道上,這是稀缺資產。
Cosmos 3 的閉環在仿真基地內部其實很高。它生成視頻、測試、反饋、再生成的循環在虛擬環境裏跑得很快。但要把這些畫面餵給真實世界的汽車或機器人,還要跨一道"從仿真到現實"的鴻溝。這一步目前還沒完全打通。
三者的區別很明顯:Momenta 是在真刀實槍開車中進化,Qwen 是在真人操作電腦中進化,NVIDIA 是在人造影視基地裏進化。沒有高下之分,只是戰場不同。
下次看到"世界模型"四個字,先問一句:說的是電腦裏的、馬路上的,還是人造影視基地裏的?答案不同,選擇完全不同。現在喊"世界模型"的,一半是真在做,一半是借這個詞給自己貼金。分得清前者後者,纔不會被 PR 稿帶跑偏。