
编译 | 程茜 李水青
编辑 | 李水青
智东西5月15日消息,昨日下午,DeepSeek团队发布新论文,以DeepSeek-V3为代表,深入解读DeepSeek在硬件架构和模型设计方面的关键创新,为实现具有成本效益的大规模训练和推理提供思路。
DeepSeek创始人兼CEO梁文锋这次同样出现在了合著名单之中,在作者列表中处于倒数第五的位置。论文署名通讯地址为“中国北京”,可以推测论文研究大概率为DeepSeek北京团队主导。

大语言模型的迅猛扩张正暴露出硬件架构的三大瓶颈:内存容量不足、计算效率低下、互连带宽受限。而DeepSeek-V3却实现了令人瞩目的效率突破——
仅在2048块H800 GPU上进行训练,FP8训练的准确率损失小于0.25%,每token的训练成本250 GFLOPS,而405B密集模型的训练成本为2.45 TFLOPS ,KV缓存低至每个token 70 KB(仅为Llama-3.1缓存的1/7)……
这些突破性数据背后,究竟隐藏着怎样的技术革新?
其中的模型架构和AI基础设施关键创新包括:用于提高内存效率的多头潜在注意力(MLA)、用于优化计算-通信权衡的混合专家(MoE)架构、用于释放硬件功能全部潜力的FP8混合精度训练,以及用于最大限度地减少集群级网络开销的多平面网络拓扑。
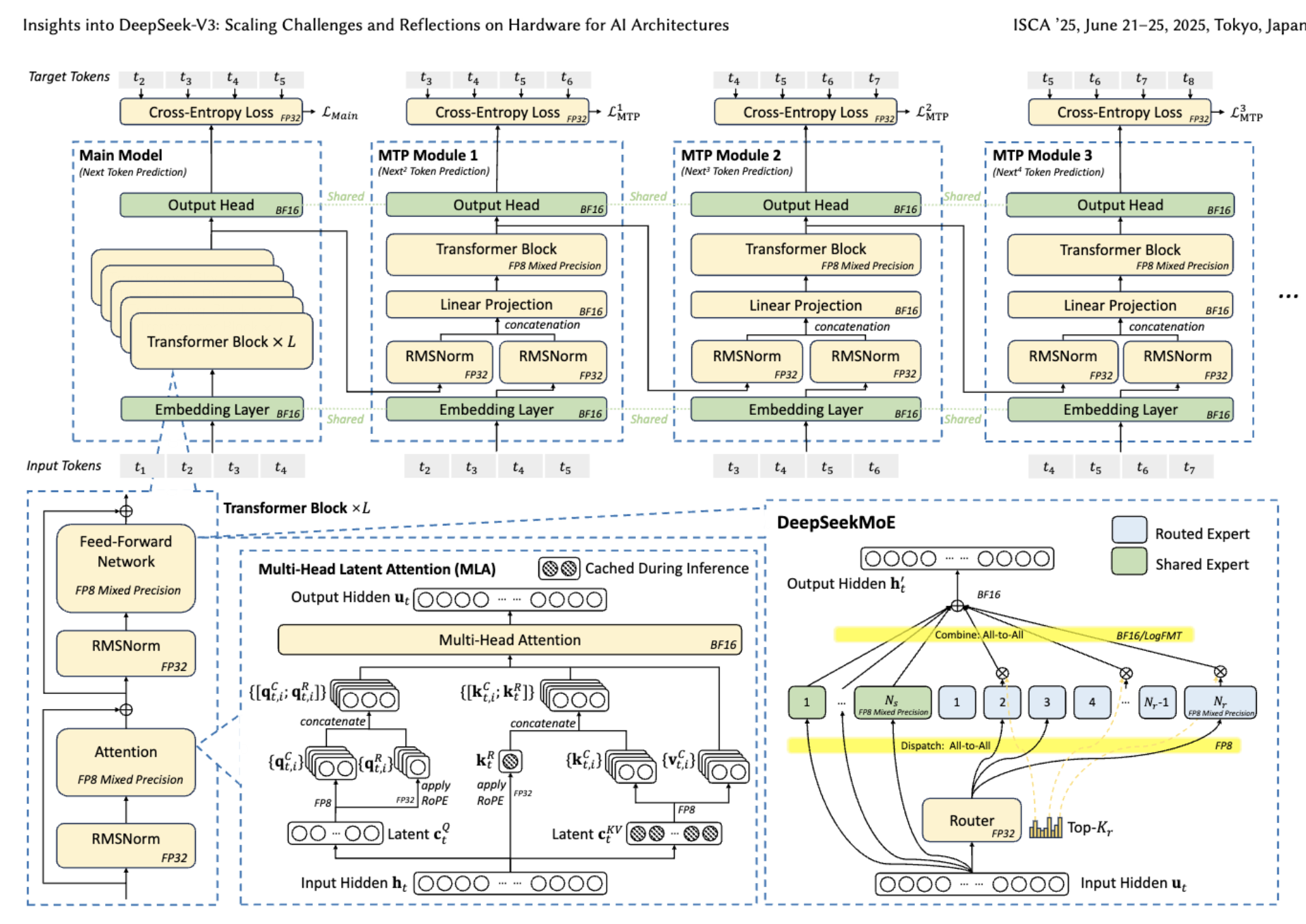
▲DeepSeek-V3基本架构
DeepSeek的论文中验证了,有效的软硬件协同设计可以实现大型模型的成本效益训练,从而为较小的团队提供公平的竞争环境。
也难怪OpenAI联合创始人Andrej Karpathy此前赞叹:“DeepSeek-V3的出现实现了高性能与低成本的平衡……未来或许不需要超大规模的GPU集群了。”
DeepSeek在论文中提到,本文的目的不是重申DeepSeek-V3的详细架构和算法细节,是跨越硬件架构和模型设计采用双重视角来探索它们之间错综复杂的相互作用,以实现具有成本效益的大规模训练和推理。侧重于探讨:
硬件驱动的模型设计:分析FP8低精度计算和纵向扩展/横向扩展网络属性等硬件功能如何影响DeepSeek-V3中的架构选择;
硬件和模型之间的相互依赖关系:深入了解硬件功能如何塑造模型创新,以及大模型不断变化的需求如何推动对下一代硬件的需求;
硬件开发的未来方向:从DeepSeek-V3获得可实现的见解,以指导未来硬件和模型架构的协同设计,为可扩展、经济高效的AI系统铺平道路;
论文地址:https://arxiv.org/abs/2505.09343
一、从源头优化内存效率,MoE模型可降低成本、本地部署
开篇提到的DeepSeek-V3关键创新旨在解决扩展中的三个核心挑战:内存效率、成本效益和推理速度。
1、内存效率:从源头优化内存使用,使用MLA减少KV缓存
从源头优化内存使用仍然是一种关键且有效的策略。与使用BF16进行权重的模型相比,FP8将内存消耗显著降低了一半,有效缓解了AI内存墙挑战。
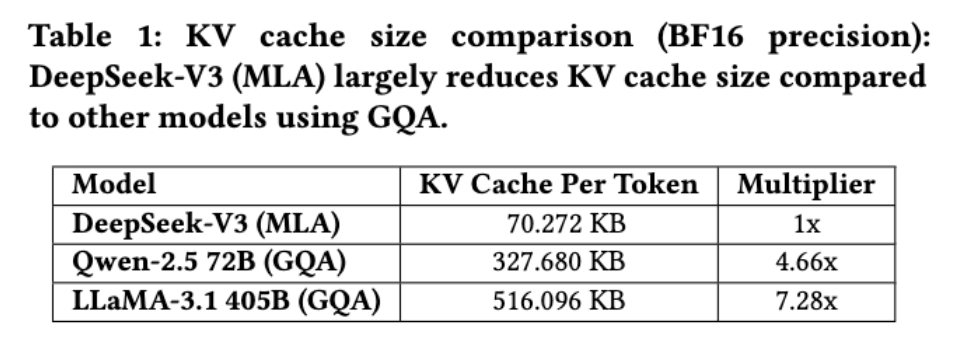
▲KV缓存大小比较(BF16精度)
使用MLA减少KV缓存。对于大模型推理,用户请求通常涉及多轮对话。KV缓存通过缓存先前处理的token的键和值向量来解决这一挑战,无需为后续token重新计算。
在每个推理步骤汇总,模型仅计算当前token的键和值向量,并通过将它们与历史记录中缓存的键值对组合来执行注意力计算。这种增量计算使其在处理长序列或多轮输入时非常高效。但是,它引入了内存受限的瓶颈,因为计算从GEMM转移到GEMV,后者的计算与内存比率要低得多。
为了解决这一挑战,研究人员采用MLA,它使用投影矩阵将所有注意力头的KV表示压缩成一个更小的潜在向量,让该矩阵与模型联合训练。在推理过程中,只需要缓存潜在向量,与存储所有注意力头的KV缓存相比减少了内存消耗。
2、成本效益:MoE可降低训练成本,便于本地部署
DeepSeek开发了DeepSeekMoE,MoE模型的优势有两个方面:
首先可以减少训练的计算要求,降低训练成本。MoE模型允许参数总数急剧增加,同时保持计算要求适中。例如,DeepSeek-V2具有236B参数,但每个token只激活了21B参数。DeepSeek-V3扩展到671B参数,同时能将每个token的激活量保持在仅37B。相比之下,Qwen2.5-72B和LLaMa3.1-405B等稠密模型要求所有参数在训练期间都处于活动状态。
其次,是个人使用和本地部署优势。在个性化Agent蓬勃发展的未来,MoE模型在单请求场景中提供了独特的优势。由于每个请求只激活了一个参数子集,因此内存和计算需求大大减少。例如,DeepSeek-V2(236B参数)在理过程中仅激活21B参数。这使得配备AI芯片的PC能够实现每秒近20个token(TPS),甚至达到该速度的两倍。相比之下,具有相似能力的稠密模型在类似硬件上通常只能达到个位数的TPS。
同时,大语言模型推理优化框架KTransformers允许完整版DeepSeek-V3模型在配备消费类GPU的低成本服务器上运行,成本约为10000美元,实现近20 TPS。这种效率使MoE架构适用于硬件资源有限的本地部署和个人用户。
二、重叠计算和通信、高带宽纵向扩展网络,提高推理速度
第三个挑战是推理速度,DeepSeek通过重叠计算和通信、引入高带宽纵向扩展网络、多token预测框架等来提高模型的推理速度。
1、重叠计算和通信:最大化吞吐量
推理速度包括系统范围的最大吞吐量和单个请求延迟,为了最大限度地提高吞吐量,DeepSeek-V3从一开始就被构建为利用双微批处理重叠,将通信延迟与计算重叠。
DeepSeek将MLA和MoE的计算解耦为两个不同阶段。当一个微批处理执行MLA或MoE计算的一部分时,另一个微批处理同时执行相应的调度通信。相反,在第二个微批处理的计算阶段,第一个微批处理经历组合通信步骤。
这种流水线化方法实现了全对全通信与正在进行的计算的无缝重叠,确保始终能充分利用GPU资源。
此外,在生产中,他们采用预填充-解码分离(prefill-decode disaggregation)架构,将大批量预填充和延迟敏感的解码请求分配给不同的专家并行组。
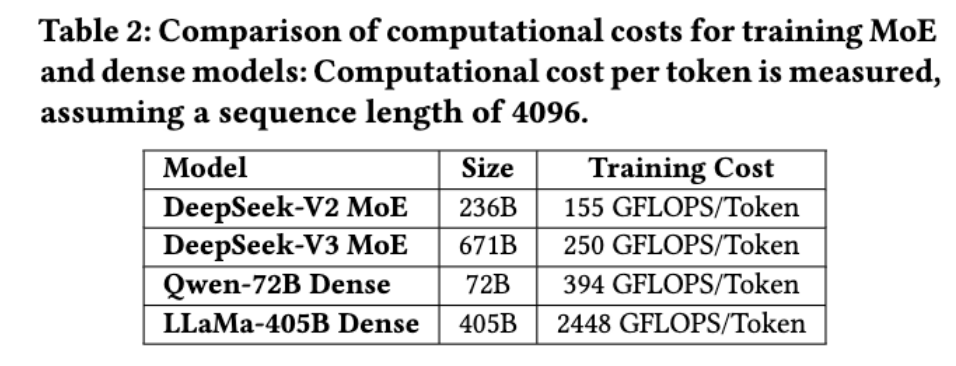
▲训练MoE和稠密模型的计算成本比较:假设序列长度为4096,测量每个token的计算成本
2、推理速度限制:高带宽纵向扩展网络潜力
MoE模型实现高推理速度取决于跨计算设备高效部署专家参数。为了实现尽可能快的推理速度,理想情况下,每个设备都应该为单个专家执行计算或者多个设备应在必要时协作计算单个专家。
但专家并行(EP)需要将token路由到适当的设备,这涉及跨网络的多对多通信。因此,MoE推理速度的上限由互连带宽决定。
考虑这样一个系统:每个设备都保存一个专家的参数,一次处理大约32个token。此token计数在计算内存比率和通信延迟之间取得平衡,此token计数可确保每个设备在专家并行期间处理相等的批量大小,从而计算通信时间。
如果使用像GB200 NVL72(72个GPU上的900GB/s单向带宽)这样的高带宽互连,每个EP步骤的通信时间=(1字节+2字节)×32×9×7K/900GB/s=6.72μs
假设计算时间等于通信时间,这将显著减少总推理时间,从而实现超过0.82毫秒TPOT的理论上限,大约每秒1200个token。
虽然这个数字是理论上得出,尚未经过实证验证,但它说明了高带宽纵向扩展网络在加速大规模模型推理方面的潜力。
3、多token预测(Multi-Token Prediction)
DeepSeek-V3引入了多token预测(MTP)框架,该框架同时增强了模型性能并提高了推理速度。
推理过程中,传统的自回归模型在解码步骤中生成一个token,这会导致序列瓶颈问题。MTP通过使模型能够以较低成本生成额外的候选token并对其进行并行验证,从而缓解了这一问题,这与之前基于自起草的推测性解码方法类似。该框架在不影响准确性的前提下加快了推理速度。
此外,通过预测每步多个token,MTP增加了推理批量大小,这对于提高EP计算强度和硬件利用率至关重要。
4、推理模型的高推理速度与测试时扩展的研究
以OpenAI的o1/o3系列为例,大模型中的测试时缩放通过在推理过程中动态调整计算资源,在数学推理、编程和一般推理方面实现性能提升。后续DeepSeek-R1、Gemini 2.5 Pro、Qwen3都采用了类似的策略。
对于这些推理模型,高token输出速度至关重要。在强化学习(RL)工作流程中,快速生成大量样本的必要性使推理吞吐量成为一个关键的瓶颈。同样,延长的推理序列会增加用户的等待时间,从而降低此类模型的实际可用性。
因此,通过协同硬件和软件创新来优化推理速度对于提高推理模型的效率必不可少。
三、DeepSeek-V3实践:软硬件协同突破效率极限
基于上述核心设计原则,DeepSeek详细描述了低精度训练、互连优化、网络拓扑等具体技术的实现细节。
在低精度技术突破方面,DeepSee通过采用FP8混合精度训练,将模型内存占用直接减少50%,有效缓解“内存墙”难题。DeepSeek还提出LogFMT对数空间量化方案,能在相同比特下实现更高精度。
在互连优化方面,DeepSeek提出了硬件感知并行策略。团队摒弃传统张量并行(TP),转而采用流水线并行(PP)和专家并行(EP),配合自主研发的DeepEP库,实现通信效率的飞跃。
在网络拓扑方面,DeepSeek推出的两层多层胖树(MPFT)网络拓扑,通过8个独立平面实现故障隔离与负载均衡,成本相比传统三层拓扑降低40%以上,且在全到全通信性能上与单层多轨网络旗鼓相当,为集群扩展提供了坚实保障。
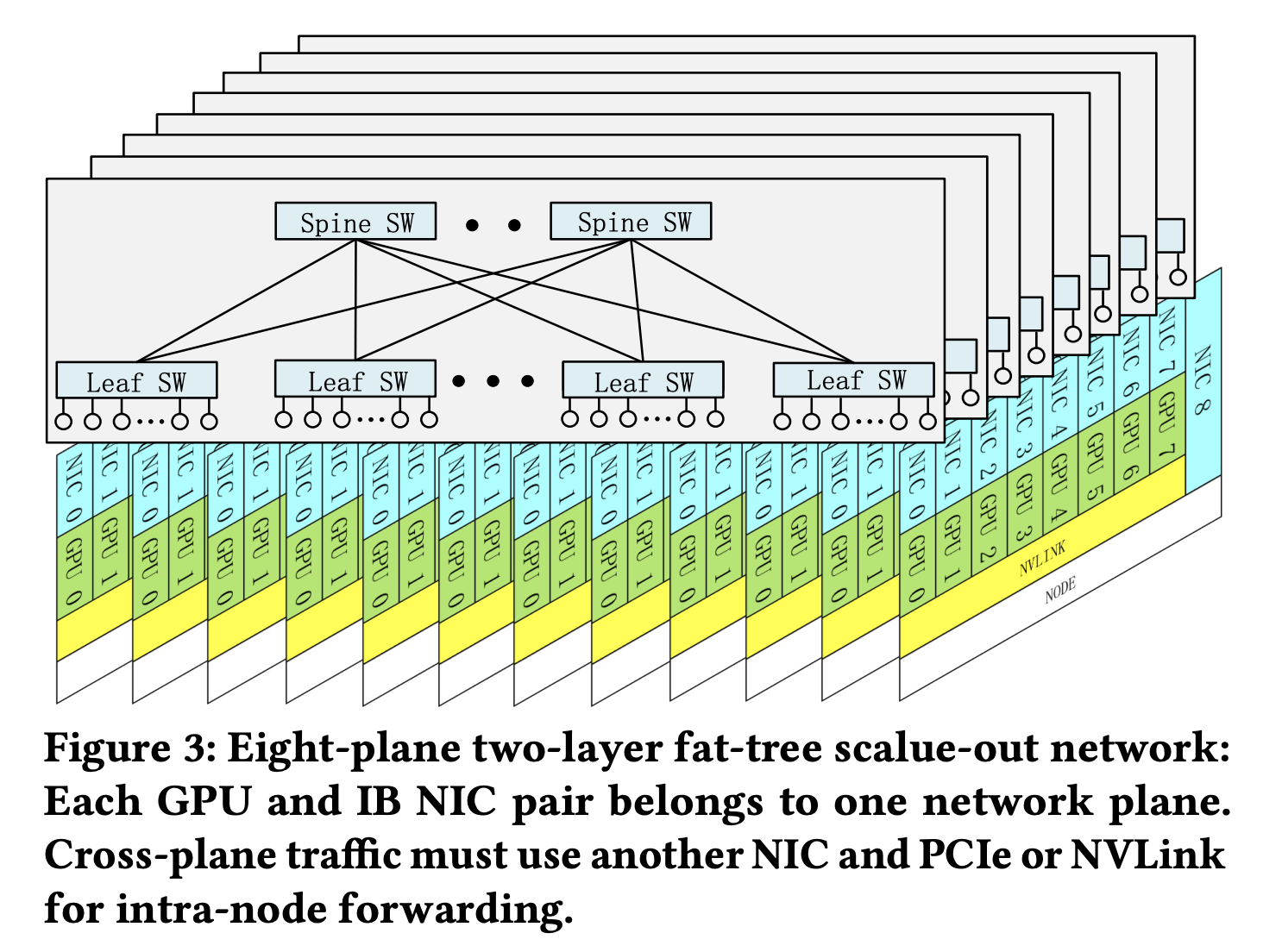
▲八平面两层胖树可扩展网络
四、六大关键,打造下一代AI基础设施
针对当前硬件痛点,DeepSeek提出下一代AI基础设施的核心升级路径。
跳出DeepSeek-V3的具体实现,DeepSeek从硬件架构演进的角度提出六大未来挑战与解决方案,涵盖内存、互连、网络、计算等核心领域。
1、鲁棒性优先:构建不易崩溃的训练系统
现有硬件对GPU故障、内存静默错误等缺乏有效检测,大规模训练中断风险高。
对此,DeepSeek提出硬件必须引入传统ECC之外的高级错误检测机制。基于校验和的验证或硬件加速冗余检查等技术,为大规模部署提供更高可靠性。
此外,硬件供应商应向终端用户提供全面的诊断工具包,使其能够严格验证系统完整性并主动识别潜在的静默数据损坏。
2、颠覆互连架构:CPU-GPU直连消除节点瓶颈
CPU在协调计算、管理I/O和维持系统吞吐量方面仍不可或缺,当前架构面临若干关键瓶颈。
CPU与GPU之间的PCIe接口在大规模参数、梯度或KV缓存传输期间常成为带宽瓶颈。为缓解这一问题,未来系统应采用直接的CPU-GPU互连(如NVLink或Infinity Fabric),或将CPU和GPU集成到扩展域中,从而消除节点内瓶颈。
除PCIe限制外,维持如此高的数据传输速率还需要极高的内存带宽。最后,内核启动和网络处理等延迟敏感任务需要高单核CPU性能,通常需要基频超过4GHz。此外,现代AI工作负载需要每个GPU配备足够的 CPU核心,以避免控制端瓶颈。对于基于小芯片的架构,需要额外核心支持缓存感知的工作负载分区和隔离。
3、智能网络升级:动态路由实现低延迟
为满足延迟敏感型工作负载的需求,未来互连必须同时优先考虑低延迟和智能网络。
共封装光学:集成硅光子学可实现更高带宽扩展性和更强能效,这对大规模分布式系统至关重要。
无损网络:基于信用的流量控制(CBFC)机制可确保无损数据传输,但单纯触发流量控制可能导致严重的队头阻塞。因此,必须部署先进的端点驱动拥塞控制(CC)算法,主动调节注入速率并避免异常拥塞场景。
自适应路由:如5.2.2节所述,未来网络应标准化动态路由方案(如分组喷射和拥塞感知路径选择),持续监控实时网络状况并智能重新分配流量。
高效容错协议:通过部署自愈协议、冗余端口和快速故障转移技术,可显著增强故障鲁棒性。
动态资源管理:为有效处理混合工作负载,未来硬件应支持动态带宽分配和流量优先级。
4、通信顺序“硬件化”:消除软件额外开销
使用加载/存储内存语义的节点间通信高效且便于编程,但当前实现受内存顺序挑战的阻碍。
DeepSeek主张硬件支持为内存语义通信提供内置顺序保证。这种一致性应在编程层(如通过获取/释放语义)和接收方硬件层强制执行,实现有序传递而无额外开销。
5、网络计算融合:硬件加速通信效率
混合专家模型(MoE)的分发与组合阶段存在网络优化空间。论文建议,在网络硬件中集成自动分组复制、硬件级归约功能,并支持LogFMT压缩,降低通信带宽需求。
6、内存架构重构:从“芯片堆叠”到“晶圆集成”
模型规模的指数级增长已超过高带宽内存(HBM)技术的进步,这种差距造成内存瓶颈。
DeepSeek推荐DRAM堆叠加速器,利用先进的3D堆叠技术,DRAM die可垂直集成在逻辑die顶部,从而实现极高的内存带宽、超低延迟和实用内存容量(尽管受堆叠限制)。
DeepSeek还提到了晶圆级系统(SoW),晶圆级集成可最大限度地提高计算密度和内存带宽,满足超大规模模型的需求。
结语:模型进化,倒逼下一代算力革新
AI产业正进入软硬件深度协同时代。通过将硬件特性融入模型设计、反向驱动硬件升级,DeepSeek 开创了软硬件良性迭代闭环。
从硬件到模型,DeepSeek-V3体现了软硬件协同设计在推进大规模AI系统的可扩展性、效率和鲁棒性方面的变革潜力。
从模型回到硬件,DeepSeek则跳出DeepSeek-V3具体模型,来定义未来硬件需为大模型优化的核心方向,从内存、互连、网络、计算等多层面提出了建设性建议,对产业生态具有重要参考意义。