文|光锥智能 魏琳华
从年初曝出与雷军接触、离职,到上个月官宣加入小米,再到本月出席小米“人车家全生态大会”,被冠以“天才少女”名号的罗福莉,站在台前拿出了新模型MiMo-V2-Flash。
刚刚在这个领域开始起跑的小米,交出了一份看起来不错的成绩单。
作为一个参数309B、激活参数15B的“大”模型(罗福莉本人也提到,这个尺寸小到不愿意称之为大模型),在小米团队的构想中,这个模型是为了给Agent当基座来训练的。
为此,这个模型的优化更加侧重一些特定的方向,核心是高性价比、快速:
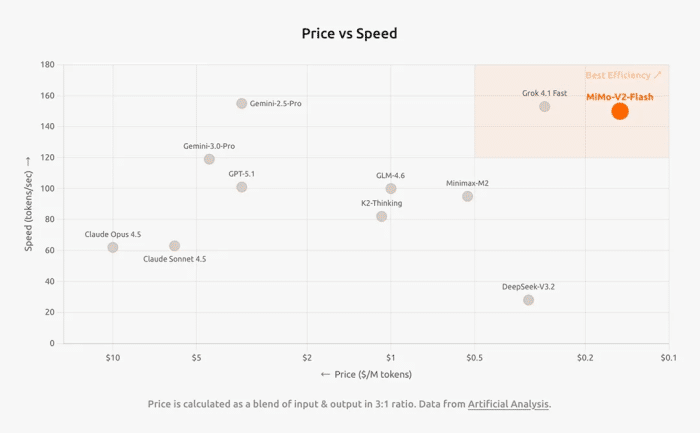
比如能够达到每秒150 tokens的生成速度、极低的成本,在保持高性价比的同时,它还保证了模型的性能。
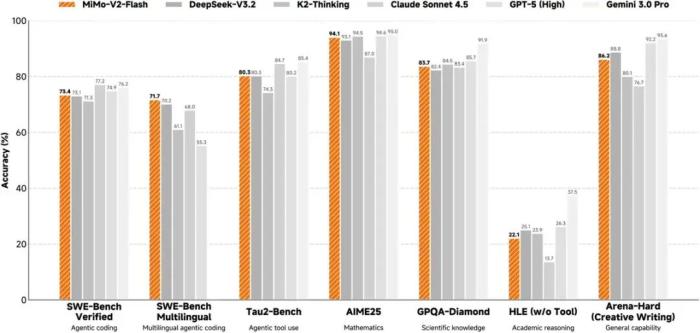
“它的代码能力和 Agent 能力在世界级公开公正的评估榜单上,已经进入了全球开源模型 Top 1-2 的行列。”罗福莉说,“大部分评估基准已经超过或者和DeepSeek-V3、Kimi K2- Thinking、Qwen等模型相当,但它的参数是后者们的1/2-1/3。”
发布的小米模型,也面临了两极分化的口碑,有人盛赞模型代码能力领先,有人则认为这是一个“刷分”之作。
无论如何,小米需要AI。
选在12月18日的人车家全生态大会,更说明了AI之于小米的重要性。
放到智能终端,摆在小米眼前的两个任务是:第一,做轻量化模型,靠端侧部署,升级“超级小爱”和澎湃OS,把AI接入智能终端;第二,智驾方面,小米则更需要大模型做基座,靠模型给智驾能力提升空间。
做AI上,小米用行动表示,自己“动真格”了。
01 压成本、提速,小米押注Agent
从一开始,小米做AI的目标,或许早在2023年雷军的年度演讲上就提到了——“轻量化+端侧部署”。
罗福莉在演讲中直言,当下模型学习的方向与生物智能的进化方向存在背离,单纯的“大力出奇迹”已难以涌现更高阶的智能。
当Scaling Law能够带来的提升越来越少,小米选择了一条更契合自身的路:做一个参数小、性能好且够便宜的模型。
“Scaling的范式已经逐步从预训练(Pre-train)转向后训练(Post-train),”罗福莉解释道,“我们如何激发后训练的潜能?这就需要一个稳定的范式,以便在强化学习(RL)上投入更多的算力。”
为此,作为一个给Agent打底的模型,MiMo-V2-Flash的优化逻辑指向了三个关键问题:
高效沟通:强化代码能力和工具调用,这是智能体交互的基础。
加速带宽:通过极高的推理效率,解决智能体之间信息传递的瓶颈。
发力后训练:通过稳定范式,激发强化学习的潜能。

由此,小米做了个309B的大模型MiMo-V2-Flash,从指标上来看,它最突出的地方在于代码能力。
在官方给出的数据中,可以看到,在SWE-Bench Multilingual(软件工程基准测试中的多语言版本)中,该模型甚至超过了包括GPT-5在内的一众闭源大模型。
虽然在其他指标上,该模型和DeepSeek V3.2、kimi k2 Thinging等开源模型还有些许差距,但作为一个尺寸较小的模型,表现已经很亮眼。
更核心的其实是这个模型在推理速度和价格上的优化:
用Claude Sonnet 4.5作为对比指标,小米新模型的推理价格仅为其2.5%,生成速度却是其2倍。
MiMo-V2-Flash的API定价为,输入0.7元/百万tokens,输出2.1元/百万tokens。和国内模型相比,这也是一个非常具备竞争力的价格。
为了优化成本,提升推理速度,小米披露了其背后的技术架构选择——混合注意力机制。
从混合注意力机制上下手,月之暗面、MiniMax等独角兽也曾在类似方向上探索。
小米的选择是,采用了5:1的滑动窗口注意力(Sliding Window Attention, SWA)与全局注意力(Global Attention, GA)的混合结构。
官方实验表明,SWA在长文和推理能力上优于主流的线性注意力机制,且固定大小的KV Cache极易适配现有的基础设施(Infra)。
不过,对于小米来说,如果要达到在会上宣讲的效果,把模型接入到车、手机等设备中,300B还是一个不小的规模,距离端侧落地仍有距离。
最耐人寻味的,或许是罗福莉在演讲时的结语:
“AI进化的下一个起点,一定要有一个可以跟真实环境交互的物理模型,”罗福莉说道,“我们要打造的本质上不是一个程序,而是一个具备物理一致性、时空连贯性的虚拟宇宙。”
从今年小米的模型发布动态上,我们猜测,小米未来的优化将被拆解为两条线:一是死磕端侧,为智能终端加码;二是攻克物理模型,补足在智驾方面的模型能力。
02 做端侧、做智驾AI给小米全家桶打底
无论外界对参数和架构的讨论如何热烈,对小米而言,AI的价值最终必须回归到业务。
选在12月18日的人车家全生态大会发布模型,本身就说明了AI之于小米的战略意义:
在智能终端侧,通过升级“超级小爱”和澎湃OS,让它们从指令执行者变为真正的助理;在智能驾驶侧,则急需大模型作为基座,拓展智驾的上限。
回顾2025年,小米在MiMo系列上的发力呈现出一种急行军的态势,不同于两年前模型发布后的安静,今年的小米高调了起来。
4月:开源MiMo-7B系列,覆盖基础、指令微调及强化学习版。
5月:发布MiMo-VL-7B,突破多模态视觉理解。
11月:推出MiMo-Embodied具身智能大模型,整合自动驾驶与机器人技术。
12月:MiMo-V2-Flash压轴登场,主打极致效率与Agent能力。
这一连串动作的背后,是巨额的真金白银。小米集团总裁卢伟冰在财报电话会上明确表示,AI是核心研发方向。2025年,小米研发投入预计超过300亿元,其中四分之一(约75亿元)将直接砸向AI领域,并计划在未来五年投入超过2000亿元。
“在端侧,我们要追求轻量算力、低功耗和周期成本,这样才能普及端侧AI,”卢伟冰说道,“这一定是小米未来的大方向,也是小米的优势所在。”
组织层面的动作,同样印证了小米的决心:从2024年开始,小米搭建了自己的AI Infra平台,去年年底,界面新闻爆出,小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。据悉,其团队在成立时已有6500张GPU资源。
为了支撑这一战略,小米的人才拼图也在2025年逐步完整。
除了负责基础大模型的罗福莉,小米还挖来了陈龙服务于智驾团队。这种“双核”配置在技术路线上已经初见成效——陈龙团队提出并开源了全球首个打通自驾与具身操作的跨具身(X-Embodied)基座模型MiMo-Embodied。

这一模型试图解决自动驾驶与机器人之间的知识迁移难题,意味着小米正在尝试用一套通用的AI逻辑,去驱动其庞大的硬件生态——从手中的手机,到智能家居,再到智驾。
雷军曾提到,小米的AI战略是“轻量化+本地部署”。可以看到,小米是一定会利用在全球连接超过10亿台设备的巨大存量优势,靠AI做业务。
对于小米来说,MiMo-V2-Flash的发布不仅仅是为了在排行榜上占据一席之地。它是小米试图向资本市场和用户讲述的一个新故事:
一家硬件公司,正在通过掌握最高效的“大脑”(AI模型)和最广泛的“身体”(人车家生态),试图在智能时代完成一次彻底的进化。
至于这个故事能否讲通,不仅取决于模型做得好不好,更取决于这些技术能否真正跑通每一台小米设备,转化为用户感知得到的体验。