阿里巴巴近期在AI领域展现出的“日更级”开源节奏和多项大模型技术突破,标志着中国AI产业正在以一种全新的姿态参与全球竞争。这不仅仅是一项技术层面的突破,更是一场关于技术主权、生态重构和全球化竞争的战略博弈。从技术参数到开源策略,从商业逻辑到产业应用,中国企业正在改写全球AI版图。
近一周,中国AI的速度与激情正在上演。
阿里巴巴一口气连发四个开源模型,包括Qwen3系列Qwen3-235B-A22B-Instruct基础模型、Qwen3-Coder、Qwen3-235B-A22B推理模型和通义万相Wan2.2。“开源”、“登顶”等关键词频频出现,“日更级”的节奏更是令世界瞠目结舌。
7月22日,阿里开源Qwen3-235B-A22B-Instruct,性能获得基础模型领域冠军,成为 “全球最智能的非思考基础模型”。
7月23日,阿里开源AI编程模型Qwen3-Coder,代码能力及Agent调用能力超越GPT4.1、Claude4等顶尖闭源模型,登顶全球最大开源社区HuggingFace模型总榜冠军。
7月25日,阿里开源千问3推理模型性能比肩顶级闭源模型Gemini2.5 pro,斩获推理模型的全球开源冠军。
7月28日,阿里开源视频生成模型通义万相Wan2.2,共开源文生视频、图生视频和统一视频生成三款模型。
密集的技术迭代和突破,阿里用实际成果打破了“闭源模型是高性能代名词”的固有认知,重新定义开源模型的天花板。
技能突破:性能与开源的双重飞跃
短短四天时间,阿里三款开源模型Qwen3-235B-A22B-Instruct基础模型、Qwen3-Coder、Qwen3-235B-A22B推理模型,分别在基础模型、编程模型、推理模型等主流领域登上全球开源冠军宝座。
Qwen3-235B非思考模式基础模型的“天花板”突破,仅需4张H20显卡即可部署2350亿参数模型,显存占用仅为同类模型1/3,推理速度提升1.8倍,在GPQA、AIME25、Arena-Hard等任务中更是一举击败Claude4(Non-thinking)等闭源模型,这种“非思考模式”的优化,可能为需要高速推理的场景,如实时对话、自动化处理等提供更高效的解决方案。
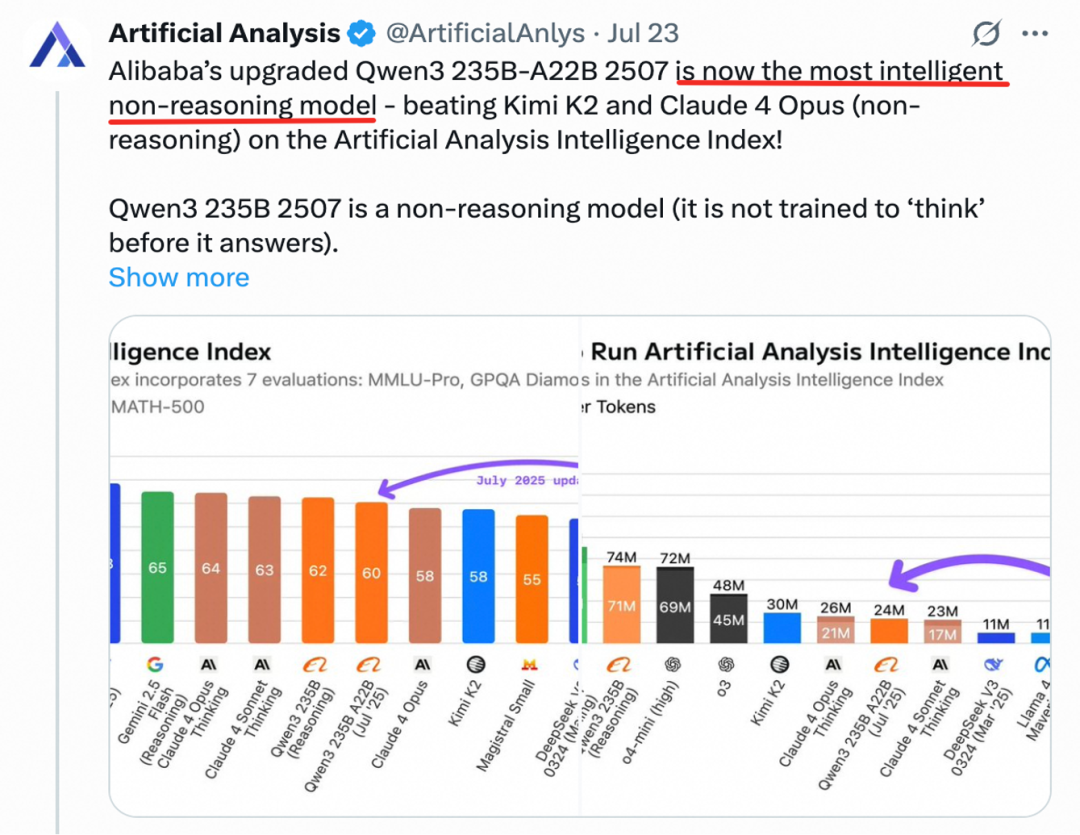
△图:AI研究机构Artificial Analysis:“千问3是全球最智能的非思考基础模型”
同样,推理与视频生成的“全能型”布局,阿里AI正在加速覆盖从文本到多模态的全链路能力。Qwen3-235B-A22B推理模型和通义万相Wan2.2的开源,它可以支持处理256K上下文超长文本,解决复杂推理任务的能力显著提升,在知识、逻辑推理、数学、编程、人类偏好对齐、创意写作、多语言能力等任务中表现可比肩Gemini-2.5 Pro、o4-mini等顶级闭源模型。
通义万相Wan2.2此次共开源文生视频(Wan2.2-T2V-A14B)、图生视频(Wan2.2-I2V-A14B)和统一视频生成(Wan2.2-TI2V-5B)三款模型,其中文生视频模型和图生视频模型均为业界首个使用MoE架构的视频生成模型,总参数量为27B,激活参数14B,均由高噪声专家模型和低噪专家模型组成,分别负责视频的整体布局和细节完善,在同参数规模下,可节省约50%的计算资源消耗,有效解决视频生成处理Token过长导致的计算资源消耗大问题,同时在复杂运动生成、人物交互、美学表达、复杂运动等维度上也取得了显著提升。尤其文生视频、图生视频的开源,有望加速AIGC在影视、广告等行业的落地。
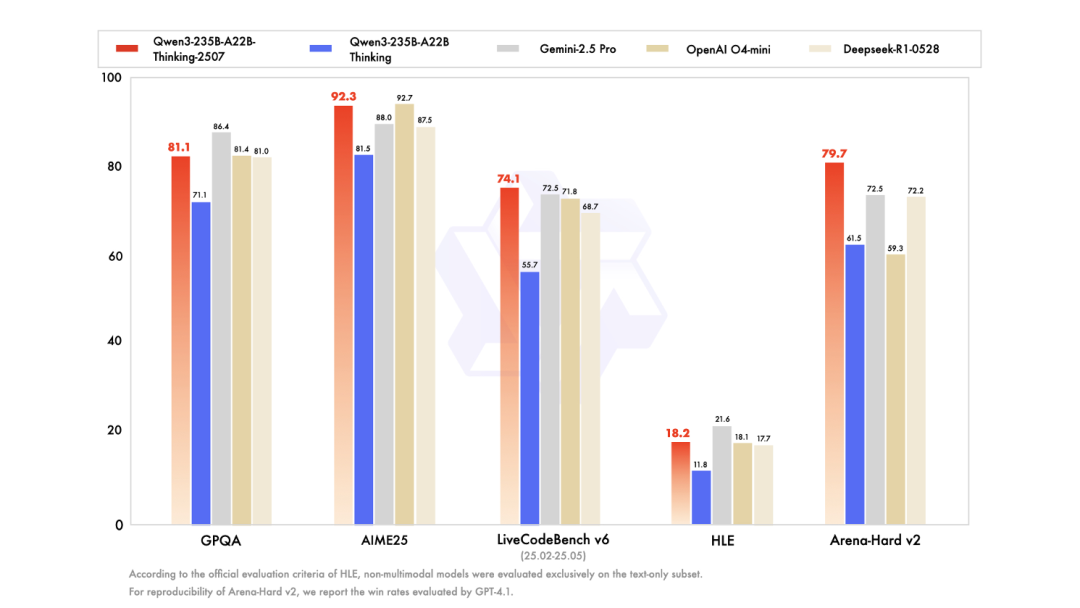

△图:通义万相图
Qwen3-Coder编程模型更是直接带来了AI编程能力的颠覆性竞争,首次将混合专家(MoE)架构引入编程模型,激活参数达35B,支持256K token上下文扩展至1M。在多语言SWE-bench、Mind2Web、Aider-Polyglot等模型Agent能力评估中,Qwen3-Coder超越GPT4.1、Claude4等顶级闭源模型,可帮助程序员实现“一句话生成3D物理模拟代码”、“5分钟搭建品牌官网”,大幅降低编程门槛。这一突破直接冲击了闭源模型与开源模型在编程领域的分工边界,成为全球开发者社区的“爆款”。

Qwen3-Coder编程模型发布之后,迅速登顶全球最大AI开源社区HuggingFace模型总榜冠军,在全球AI圈掀起热潮。推特创始人杰克·多尔西(Jack Dorsey)、爆火Agent应用Perplexity CEO 阿拉温德·斯里尼瓦斯(Aravind Srinivas)、著名风投公司a16z合伙人马克·马斯克罗(Marco Mascorro)等硅谷大咖们纷纷盛赞编程模型Qwen3-Coder,HuggingFace CEO克莱门特·德朗格(Clement Delangue)更是连转带发12条推文,向全球开发者力荐这一最好的编程模型。
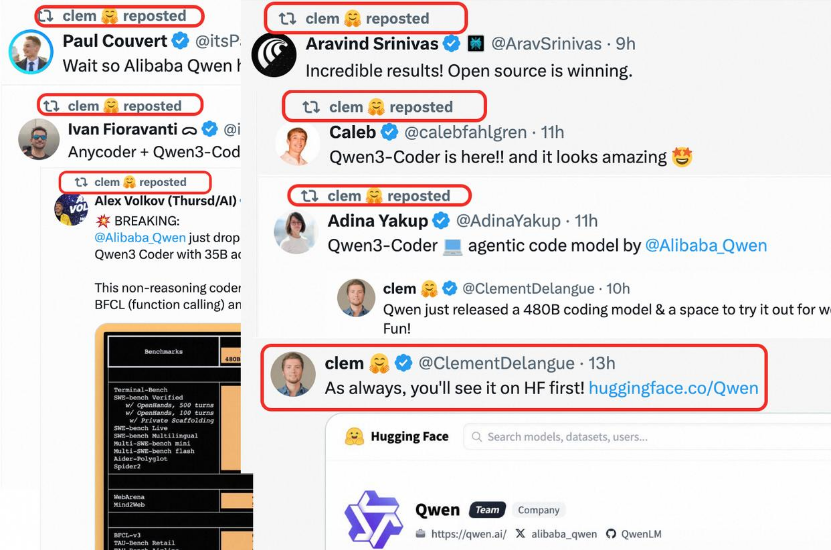
△图:HuggingFace CEO Clement Delangue连发12条推文盛赞Qwen3-Coder
开源生态:从“技术普惠”到“生态锁定”
阿里AI编程模型发布之后,一位硅谷工程师把月付200美元的Claude Code一键卸载,只因为GitHub上“突然出现中国开源的AI编程模型“,不仅性能追平GPT-4,还把上下文拉到100万Token。
模型不仅“性价比高”,而且“还听劝”,Qwen团队也被AI圈誉为开发者们的“有求必应”、“开源懂帝”,“开发者需要什么,千问团队就开源什么。”例如此前Qwen3-235B非思考模型的推出,正式Qwen团队接受了开发者的建议,Qwen团队曾在X平台上写道:“经过与社区沟通和深思熟虑,我们决定停止使用混合思考模式,相反,我们将分别训练Instruct和Thinking模型,以获得最佳质量。 ”
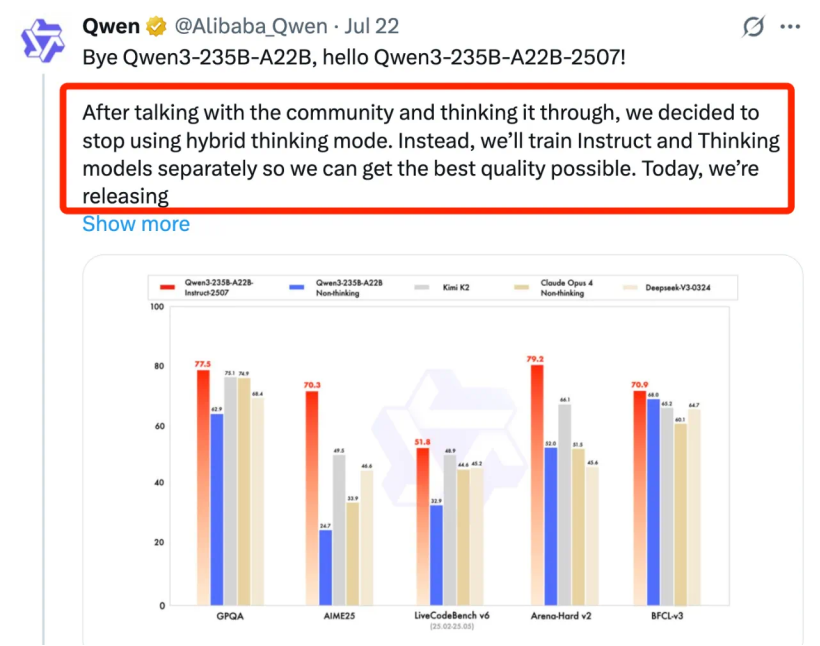
大规模参数模型的开源,降低了开发者和中小企业的使用成本,吸引更多的参与者加入。生态参与者们无需再支付高昂的授权费,即可使用顶级模型。
对于阿里而言,开源不仅仅是“技术共享”,而是通过开源模型构建技术标准,通过云计算及企业服务实现商业化。这种“以开放换生态、以生态锁云端”的策略,既推动技术普惠,又促进了技术商业化价值的转化。
通过魔搭社区、全球开源社区HuggingFace双平台及全链路生态支持,阿里构建起一个跨语言、跨场景、跨行业的全球开发者生态。一方面,全球开源社区可以吸引更多的国际开发者一起贡献代码、优化模型;另一方面魔搭社区提供模型体验、微调、部署服务,促进更多场景化落地,最终形成从模型开源、生态繁荣到技术反哺的良性循环。
同时,开源模型的广泛使用也带来技术的加速迭代。不久前,李飞飞团队曾基于Qwen开源模型训练出s1-32B,性能媲美顶尖推理模型;取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果,甚至在竞赛数学问题上的表现比 o1-preview 高出 27%。同样,在开源红利下,杭州创业团队开发的PolyGlot同传工具,端到端延迟仅420ms,远超传统70B模型。这种“开放协作”模式,正在卷积形成中国AI的全球影响力。
从追赶到定义规则 中国企业重塑全球AI竞争格局
短短一周,阿里AI重新点燃了中国科技公司的AI叙事浪潮,技术迭代的宽度和深度直追当下全球最顶级的AI玩家。
一方面,阿里始终保持敏捷的研发速度,研发的模型覆盖“全尺寸”、“全模态”、“多场景”,顺应AI在不同时期的不同特点,快速迭代,满足开发者和应用企业的需求;另一方面,阿里始终将开源作为AI发展的重要理念,几乎所有模型均是第一时间研发成功,就第一时间对外开源,让全球开发者和企业最快最好地用上最先进的模型,真正践行了“技术民主”的开源本质。

过去十六年,阿里长期坚定地投入云计算和AI技术,发展成为全球少数具备全栈AI能力的企业,成为目前中国唯一同时在基础设施和模型研发上具备全球一流能力的平台。从分布式计算、自研芯片、大模型到行业应用,全栈AI的垂直整合将AI能力快速落地产业链的核心环节,促进技术迭代和生态发展。
这种“开源平权”与“全栈整合”的结合,可能为中国乃至全球AI产业开辟了一条不同于闭源路线的路径。通过多快好省的训练,“性能+成本”的双重碾压,中国的开源模型从本质上动摇了闭源模型的定价权,引发了AI从闭源主导到开源主导的新一轮变革,而中国企业在这一变革中的主动出击,或将重塑全球AI技术的竞争格局。
7月28日消息,全球知名的大模型API三方聚合平台OpenRouter公布了最新一期榜单,来自中国的DeepSeek和阿里通义千问跻身全球前五。其中,来自阿里的通义千问以10.4%的市场份额,超越OpenAI的4.7%,位列第四。
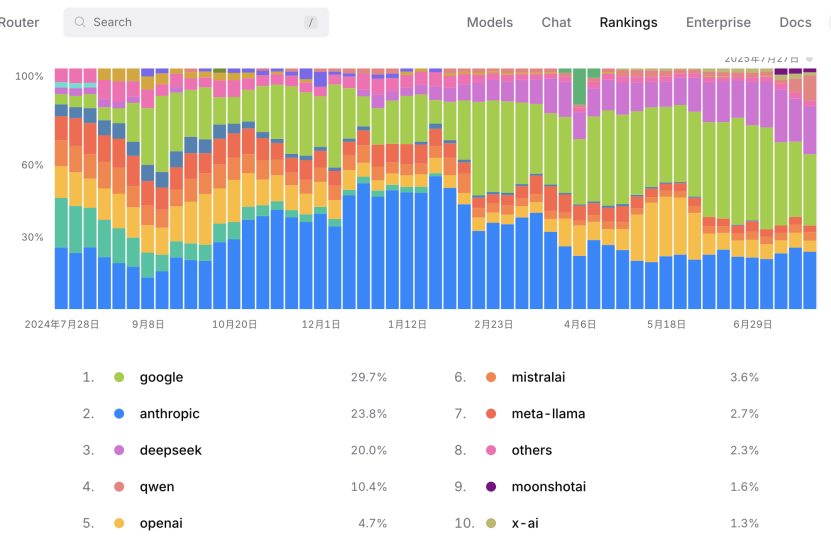
目前,阿里千问在全球主要模型社区的下载量已经突破4亿,衍生模型突破14万个,超越Meta的Llama系列成为全球第一的开源模型家族,千问也是全球开发者和企业使用最广泛的大模型,已有30多万中国企业和机构接入通义大模型,如中国一汽、联想、国家天文台等,覆盖金融、制造、科研等领域。未来三年,阿里将投入3800亿持续云和AI基础设施建设,将开源作为长期战略。
阿里AI加速布局的背后,是一场关于未来的技术战役。随着AI技术从“工具”进化为“基础设施”, 这场战役的胜负,将决定中国在AI时代的全球地位。