有媒体援引知情人士透露的消息报道称,“AI芯片超级霸主”英伟达(NVDA.US)的最强劲竞争对手之一——人工智能芯片供应商Cerebras Systems Inc.正在商讨进行一轮大约10亿美元的新融资,以支持这家AI芯片初创公司与英伟达之间的长期竞争态势,并且力争大幅强化该公司AI算力集群相比于英伟达AI GPU集群的性价比与能效比。
这位知情人士表示,这一轮融资将在投资前将这家初创公司的估值定在220亿美元,意味着较去年9月进行融资时的估值大幅扩张170%。因为讨论尚属私下,该人士要求不具名。该知情人士还表示,这家AI芯片初创公司仍计划积极推进在美股的首次公开募股(IPO)。
在首席执行官安德鲁·费尔德曼(Andrew Feldman)的带领之下,Cerebras Systems 正积极寻求挑战英伟达在人工智能芯片领域的高达90%市场份额的绝对市场主导地位,因此这轮融资也势必将为寻求挑战全球最顶级人工智能算力基础设施供应商英伟达主导地位的这家AI芯片公司带来新的一轮资金支持。
向英伟达下战书的Cerebras Systems是何方神圣?
Cerebras Systems 有着无比宏大的“人工智能雄心壮志”。首席执行官安德鲁·费尔德曼称,其公司算力硬件运行人工智能大模型的实际效率是英伟达系统的数倍。除了提供实体算力集群,他领导的这家AI芯片明星初创公司还积极向Facebook母公司Meta Platforms Inc.、有着“蓝色巨人”称号的美国老牌科技公司IBM以及有着“欧洲OpenAI”称号的Mistral AI等大型客户们提供远程人工智能计算服务。
该公司的最新估值较9月的投资轮大幅上升,当时Cerebras Systems 的估值仅仅约为81亿美元。在那之后不久,英伟达与AI芯片初创公司,同时也是Cerebras Systems竞争对手之一的Groq签署了一项重要许可协议,并收购了该AI芯片公司的大部分芯片设计人才,这也大举提振了投资者们对于人工智能芯片领域的看涨热情。
英伟达前不久与AI芯片初创公司Groq达成的200亿美元非独家授权合作协议,将其AI推理技术授权给英伟达,并且在交易完成后Groq创始人及核心研发团队将加入英伟达,可谓共同凸显出随着“全球AI推理大浪潮”全面来袭,叠加谷歌TPU AI算力集群带来的越来越大竞争压力,英伟达力争通过“多架构AI算力+巩固CUDA生态+引进更多AI芯片设计人才”来维持其在AI芯片领域高达90%市场份额的绝对主导权,并且英伟达欲以Groq+以色列AI初创公司AI21 Labs连下关键两子锁住AI全栈话语权。
与被英伟达“拿下”之前的Groq类似,Cerebras Systems 被视为英伟达在AI芯片领域最强劲的竞争对手之一,尤其是在AI推理(inference)这一快速增长的细分蓝海市场。Cerebras 的技术路线与英伟达AI GPU算力体系以及谷歌TPU(AI ASIC技术路线)都截然不同,它采用 “晶圆级引擎”(Wafer‑Scale Engine, WSE) 架构,将整个AI模型放在单个超大芯片上,从而极大提升了推理性能和内存带宽,在单位推理量上实现更高的能效比,并且避免了GPU集群之间的数据拆分和高速通信开销这一重大瓶颈。
不同于英伟达、博通与AMD等芯片巨头聚焦于尺寸较小的高性能芯片,再通过台积电独家的chiplet先进封装进行芯片集成封装整合,Cerebras Systems制造了一个能够覆盖整个硅晶圆的超级大型芯片。Semianalysis等半导体研究机构的分析指出,这样的晶圆级架构在处理大型语言模型推理任务时可以实现比传统AI GPU/AI ASIC更强劲的性能密度和能效比例。
另一家同样有志成为英伟达最强竞争对手之一的初创公司Etched据知人士透露,在一轮新的融资中筹集了大约5亿美元,使得估值来到约50亿美元。
值得注意的是,Cerebras Systems 在很大程度上依赖总部位于阿布扎比的人工智能公司G42的业务,这一深度合作关系已引起美国外国投资委员会(Committee on Foreign Investment in the US)的审查,可能导致IPO进程持续受阻。
AI推理大浪潮全面来袭,Cerebras Systems欲紧抓这股大势
从最近的市场动态来看,Cerebras Systems 确实正在利用 AI 推理这股大浪潮积极布局,并通过融资与推动 IPO 来增强自身竞争力,争取不断蚕食英伟达的高达90%这一无比庞大市场份额。Cerebras 的持续融资进程与IPO推进共同反映出该AI芯片初创公司希望借 AI 推理浪潮扩大市场影响、增强竞争力、挑战英伟达的意图。
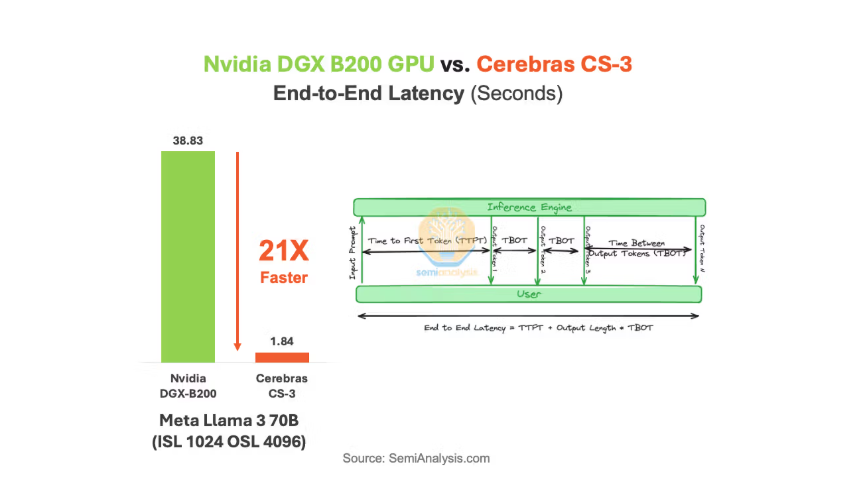
Cerebras 最新的 CS‑3 系统(搭载 WSE‑3 芯片) 在多个公开对比中,被报告在大型语言模型推理场景下可以达到远高于英伟达最新GPU体系——Blackwell架构AI GPU的性能。根据Cerebras自己的对比数据,CS‑3 在运行如 Llama 3 70B 推理任务时比Blackwell架构的 B200 AI GPU 系统快约21倍,同时总体成本和能耗更低(包括硬件与电力消耗成本);第三方分析也指出,一些高参数的推理基准任务中,Cerebras 的输出吞吐量(tokens/sec)多倍于传统GPU,有报道提到在某些模型推理中速度可以达到比GPU快20倍或更多。
在大规模推理领域, 特别是处理大型LLMs时,Cerebras 的WSE‑基架构在性价比(成本/性能比) 与 能效比(能耗/推理输出比) 上可谓全面显示出相较于英伟达 GPU算力集群的显著优势。这些优势主要来源于其晶圆级单片设计、极高带宽和推理吞吐能力。但这种优势更显著于特定推理场景,而非覆盖所有AI计算任务,在通用计算任务部署、AI训练算子以及CUDA生态兼容性方面,英伟达仍具备很大优势。
英伟达AI GPU几乎垄断的AI训练侧需要更加强大的AI算力集群通用性以及整个算力体系的快速迭代能力,而AI推理侧则在前沿AI技术规模化落地后更看重单位token成本、延迟与能效。谷歌明确把Ironwood定位为“为AI推理时代而生”的TPU代际,并强调性能/能效/算力集群性价比与可扩展性。
当AI推理算力体系成为全球科技企业长期现金成本中心,客户们更愿意在云上选择更划算更具性价比的AI ASIC加速器。有媒体曾报道OpenAI通过谷歌云平台Google Cloud大规模租用TPU(谷歌TPU属于AI ASIC技术路线),核心动机之一就是降低AI推理成本——这是来自TPU竞争压力上升的最典型案例。
根据Semianalysis测算数据,谷歌最新的TPU v7 (Ironwood) 展现出了惊人的代际跨越,TPU v7的BF16算力高达4614 TFLOPS,而上一代被广泛使用的TPU v5p仅为459 TFLOPS,这堪称是整整一个数量级的提升。此外,TPU v7显存直接对标英伟达Blackwell架构的 B200,针对特定AI应用场景,架构上更具性价比与能效比优势的AI ASIC可以更容易地吃下主流推理端算力负载,比如TPU甚至能提供比英伟达Blackwell高出1.4倍的每美元性能。
当前超大规模AI推理需求正呈现每六个月翻一番的极速增长趋势,因此在AI推理大浪潮席卷而来以及谷歌TPU带来的愈发强大竞争压力的算力需求背景下,英伟达通过Groq拿到推理芯片思路与顶尖人才、并通过AI21补软件与模型侧能力,属于典型的“硬件技术路线多元化 + AI应用生态端到端绑定”防守/反击。
英伟达与AI芯片初创公司Groq的交易本质是非独占推理类AI芯片技术授权 + 吸纳Groq创始人/CEO Jonathan Ross等高管与部分核心工程团队,一些半导体行业分析师也强调Groq的独家芯片技术专注推理并用片上SRAM等方式降低数据搬运瓶颈,可谓直指推理阶段的成本/延迟痛点。