多年来,领先的人工智能公司一直坚称,只有拥有庞大计算资源的公司才能推动前沿研究,这强化了这样一种观点:除非你拥有数十亿美元的基础设施投入,否则“不可能赶上”。但 DeepSeek 的成功却讲述了一个不同的故事:新颖的理念可以带来效率上的突破,从而加速人工智能的发展;规模更小但更专注的团队可以挑战行业巨头,甚至创造公平的竞争环境。
我们认为,DeepSeek 的效率突破预示着AI 应用需求的激增。如果 AI 要继续发展,就必须降低总体拥有成本 (TCO) ——通过扩大替代硬件的覆盖范围、最大限度地提高现有系统的效率以及加速软件创新。否则,未来 AI 的效益将面临瓶颈——要么是硬件短缺,要么是开发者难以有效利用现有的各种硬件。
过去 25 年来,我一直致力于为世界释放计算能力。我创立并领导了LLVM的开发,LLVM 是一项编译器技术,它为 CPU 在编译器技术的新应用领域打开了大门。如今,LLVM 已成为 C++、Rust、Swift 等性能导向型编程语言的基础。它支持几乎所有 iOS 和 Android 应用,以及 Google 和 Meta 等主要互联网服务的基础设施。
这项工作为我在苹果领导的几项关键创新铺平了道路,包括创建OpenCL(一个早期的加速器框架,现已被整个行业广泛采用)、使用LLVM重建苹果的CPU和GPU软件堆栈,以及开发Swift编程语言。这些经历强化了我对共享基础设施的力量、软硬件协同设计的重要性,以及直观、开发者友好的工具如何释放先进硬件的全部潜力的信念。
2017 年,我开始着迷于 AI 的潜力,并加入 Google,领导 TPU 平台的软件开发。当时,硬件已经准备就绪,但软件尚未投入使用。在接下来的两年半时间里,通过团队的共同努力,我们在 Google Cloud 上推出了 TPU,并将其扩展到每秒百亿亿次浮点运算 (ExaFLOPS),并构建了一个研究平台,促成了Attention Is All You Need和BERT等突破性成果。
然而,这段旅程也揭示了人工智能软件更深层次的问题。尽管 TPU 取得了成功,但它们仍然仅与 PyTorch 等人工智能框架半兼容——谷歌凭借巨大的经济和研究资源克服了这个问题。一个常见的客户问题是:“TPU 能开箱即用地运行任意人工智能模型吗?”真相是?不能——因为我们没有 CUDA,而 CUDA 是人工智能开发的事实标准。
我并非回避解决行业重大问题的人:我最近的工作是创建下一代技术,以适应硬件和加速器的新时代。这包括 MLIR 编译器框架(目前已被整个行业广泛采用的 AI 编译器),以及我们团队在过去 3 年中构建的一些特别的东西——但我们稍后会在合适的时机分享更多相关信息。
由于我的背景和在业界的人脉,我经常被问及计算的未来。如今,无数团队正在硬件领域进行创新(部分原因是NVIDIA 市值飙升),而许多软件团队正在采用 MLIR 来支持新的架构。与此同时,高层领导们也在质疑,为什么尽管投入了大量资金,AI 软件问题仍然悬而未决。挑战并非缺乏动力或资源。那么,为什么这个行业会感到停滞不前呢?
我不认为我们陷入了困境。但我们确实面临着一些棘手的基础性问题。
为了向前发展,我们需要更好地理解行业底层动态。计算是一个技术含量极高的领域,发展迅速,充斥着各种术语、代号和新闻稿,旨在让每一款新产品都听起来具有革命性。许多人试图拨开迷雾,只见树木不见森林,但要真正理解我们的发展方向,我们需要探究其根源——那些将一切联系在一起的基本构件。
首先,我们将以一种简单易懂的方式回答这些关键问题:
CUDA 到底是什么?
CUDA 为何如此成功
️CUDA 真的好吗?
为什么其他硬件制造商难以提供可比的 AI 软件?
为什么 Triton、OneAPI 或 OpenCL 等现有技术还没有解决这个问题?
作为一个行业,我们该如何向前发展?
我希望本文能够激发有意义的讨论,并提升人们对这些复杂问题的理解。人工智能的快速发展——例如 DeepSeek 最近的突破——提醒我们,软件和算法创新仍然是推动行业发展的动力。对底层硬件的深入理解继续带来 “10 倍” 的突破。
人工智能正以前所未有的速度发展,但仍有诸多潜力有待挖掘。让我们携手突破,挑战固有认知,推动行业发展。让我们一起深入探索!
CUDA究竟是什么
似乎在过去一年里,每个人都开始谈论 CUDA:它是深度学习的支柱,是新型硬件难以与之竞争的原因,也是英伟达护城河与市值飙升的核心。
DeepSeek 的出现让我们有了惊人的发现:它的突破是通过 “绕过” CUDA、直接进入 PTX 层实现的…… 但这究竟意味着什么呢?似乎每个人都想打破这种技术锁定,但在制定计划之前,我们必须先了解自己面临的挑战。
CUDA 在人工智能领域的主导地位不可否认,但大多数人并不完全理解 CUDA 究竟是什么。有人认为它是一种编程语言,有人称它是一个框架。许多人认为它只是 “英伟达用来让 GPU 运行更快的东西”。这些说法并非完全错误,也有很多杰出人士试图解释它,但没有一种能完全涵盖 “CUDA 平台” 的全貌。
CUDA 并非单一事物,它是一个庞大的分层平台,是一系列技术、软件库和底层优化的集合,共同构成了一个大规模的并行计算生态系统。它包括:
一种底层并行编程模型,开发者可以用类似 C++ 的语法利用 GPU 的原始计算能力。
一套复杂的库和框架,这些中间件支持人工智能等关键垂直应用场景(例如用于 PyTorch 和 TensorFlow 的 cuDNN 库 )。
像 TensorRT-LLM 和 Triton 这样的高级解决方案,它们能在不需要开发者深入了解 CUDA 的情况下,支持人工智能工作负载(例如大语言模型服务)。
而这只是冰山一角。
在本章节中,我们将深入剖析 CUDA 平台的关键层级,探究其发展历程,并解释它为何对如今的人工智能计算如此重要。这为我们系列文章的下一部分内容奠定了基础,届时我们将深入探讨 CUDA 如此成功的原因。提示:这与其说是技术本身的原因,不如说和市场激励因素有很大关系。
让我们开始吧!
CUDA 发展之路:从图形处理到通用计算
在 GPU 成为人工智能和科学计算的强大引擎之前,它们只是图形处理器,是专门用于渲染图像的处理器。早期的 GPU 将图像渲染功能硬编码在硅芯片中,这意味着渲染的每个步骤(变换、光照、光栅化)都是固定的。虽然这些芯片在图形处理方面效率很高,但缺乏灵活性,无法用于其他类型的计算。
2001 年,英伟达推出 GeForce3,这一切发生了改变。GeForce3 是第一款带有可编程着色器的 GPU,这在计算领域是一次重大变革:
在此之前:固定功能的 GPU 只能应用预定义的效果。
在此之后:开发者可以编写自己的着色器程序,解锁了可编程图形管线。
这一进步伴随着 Shader Model 1.0 的推出,开发者可以编写在 GPU 上执行的小程序,用于顶点和像素处理。英伟达预见到了未来的发展方向:GPU 不仅可以提升图形性能,还能成为可编程的并行计算引擎。
与此同时,研究人员很快就提出了疑问:“如果 GPU 能运行用于图形处理的小程序,那我们能否将其用于非图形任务呢?”
斯坦福大学的 BrookGPU 项目是早期对此进行的重要尝试之一。Brook 引入了一种编程模型,使 CPU 能够将计算任务卸载到 GPU 上,这一关键理念为 CUDA 的诞生奠定了基础。
这一举措具有战略意义且极具变革性。英伟达没有把计算当作一项附带实验,而是将其列为首要任务,将 CUDA 深度融入其硬件、软件和开发者生态系统中。
CUDA 并行编程模型
2006 年,英伟达推出 CUDA(统一计算设备架构),这是首个面向 GPU 的通用编程平台。CUDA 编程模型由两部分组成:“CUDA 编程语言” 和 “英伟达驱动程序”。
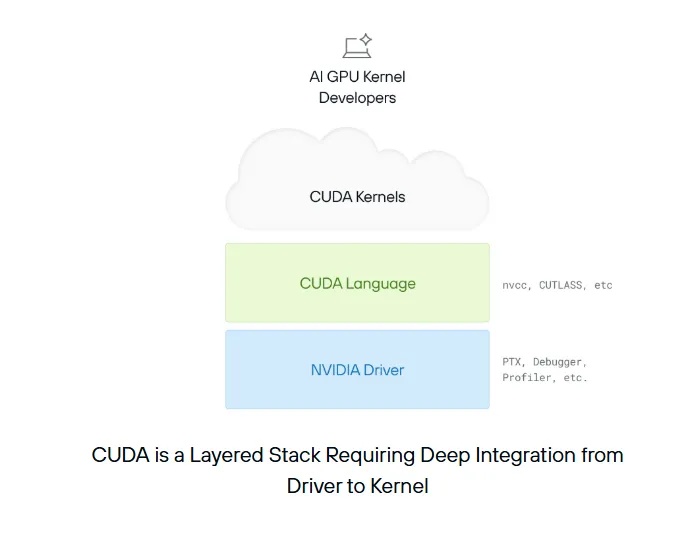
CUDA 是一个分层堆栈,需要从驱动程序到内核的深度集成
CUDA 语言源自 C++,并进行了扩展,以直接暴露 GPU 的底层特性,例如 “GPU 线程” 和内存等概念。程序员可以使用该语言定义 “CUDA 内核”,这是一种在 GPU 上运行的独立计算任务。下面是一个非常简单的示例:

CUDA 内核允许程序员定义自定义计算,这些计算可以访问本地资源(如内存),并将 GPU 用作高速并行计算单元。这种语言会被翻译成 “PTX”,PTX 是一种汇编语言,是英伟达 GPU 支持的最低级接口。
但是程序究竟如何在 GPU 上执行代码呢?这就要用到英伟达驱动程序了。它充当 CPU 和 GPU 之间的桥梁,负责处理内存分配、数据传输和内核执行。以下是一个简单示例:

请注意,这些操作都非常底层,充满了繁杂的细节(如指针和 “幻数(magic numbers)”)。如果出现错误,通常会以难以理解的程序崩溃形式提示。此外,CUDA 还暴露了许多英伟达硬件特有的细节,例如 “warp 中的线程数”(这里暂不深入探讨)。
尽管存在这些挑战,但这些组件让整整一代硬核程序员能够利用 GPU 强大的计算能力来解决数值问题。例如,2012 年 AlexNET 点燃了现代深度学习的火种。它之所以能够实现,得益于用于卷积、激活、池化和归一化等人工智能操作的自定义 CUDA 内核,以及 GPU 提供的强大算力。
虽然大多数人听到 “CUDA” 时,通常想到的是 CUDA 语言和驱动程序,但这远不是 CUDA 的全部,它们只是其中的一部分。随着时间的推移,CUDA 平台不断发展,涵盖的内容越来越多,而最初的首字母缩写词(CUDA)已经无法准确描述其全部意义。
高级 CUDA 库:让 GPU 编程更易上手
CUDA 编程模型为通用 GPU 计算打开了大门,功能强大,但它带来了两个挑战:
CUDA 使用难度较大。
更糟糕的是,CUDA 在性能可移植性方面表现不佳。
为第 N 代 GPU 编写的大多数内核在第 N + 1 代 GPU 上仍能 “继续运行”,但性能往往较差,远达不到第 N + 1 代 GPU 的峰值性能,尽管 GPU 的优势就在于高性能。这使得 CUDA 成为专业工程师的有力工具,但对大多数开发者来说,学习门槛较高。这也意味着每次新一代 GPU 推出时(例如现在新出现的 Blackwell 架构),都需要对代码进行大量重写。
随着英伟达的发展,它希望 GPU 对那些在各自领域是专家,但并非 GPU 专家的人也有用。英伟达解决这一问题的方法是开始构建丰富而复杂的闭源高级库,这些库抽象掉了 CUDA 的底层细节,其中包括:
cuDNN(2014 年推出)—— 加速深度学习(例如卷积、激活函数运算)。
cuBLAS—— 优化的线性代数例程。
cuFFT—— 在 GPU 上进行快速傅里叶变换(FFT)。
以及许多其他库。
有了这些库,开发者无需编写自定义 GPU 代码就能利用 CUDA 的强大功能,英伟达则承担了为每一代硬件重写这些库的工作。这对英伟达来说是一项巨大的投资,但最终取得了成效。
cuDNN 库在这一过程中尤为重要,它为谷歌的 TensorFlow(2015 年推出)和 Meta 的 PyTorch(2016 年推出)铺平了道路,推动了深度学习框架的兴起。虽然此前也有一些人工智能框架,但这些是首批真正实现规模化应用的框架。现代人工智能框架中包含数千个 CUDA 内核,每个内核都极难编写。随着人工智能研究的爆发式增长,英伟达积极扩展这些库,以涵盖重要的新应用场景。

CUDA 上的 PyTorch 建立在多层依赖关系之上
英伟达对这些强大的 GPU 库的投入,使得全球开发者能够专注于构建像 PyTorch 这样的高级人工智能框架,以及像 HuggingFace 这样的开发者生态系统。他们的下一步是打造开箱即用的完整解决方案,让开发者完全无需了解 CUDA 编程模型。
全面的垂直解决方案助力AI和GenAI快速发展
人工智能的热潮远远超出了研究实验室的范畴,如今它无处不在。从图像生成到聊天机器人,从科学发现到代码助手,生成式人工智能(GenAI)在各个行业蓬勃发展,为该领域带来了大量新应用和开发者。
与此同时,出现了一批新的人工智能开发者,他们有着截然不同的需求。在早期,深度学习需要精通 CUDA、高性能计算(HPC)和底层 GPU 编程的专业工程师。如今,一种新型开发者(通常称为人工智能工程师)在构建和部署人工智能模型时,无需接触底层 GPU 代码。
为了满足这一需求,英伟达不仅提供库,还推出了交钥匙解决方案,将底层的一切细节都抽象掉。这些框架无需开发者深入了解 CUDA,就能让人工智能开发者轻松优化和部署模型。
Triton Serving—— 一种高性能的人工智能模型服务系统,使团队能够在多个 GPU 和 CPU 上高效运行推理。
TensorRT—— 一种深度学习推理优化器,可自动调整模型,使其在英伟达硬件上高效运行。
TensorRT-LLM—— 一种更专业的解决方案,专为大规模大语言模型(LLM)推理而构建。
以及许多(众多)其他工具。

NVIDIA 驱动程序和 TensorRT-LLM 之间存在多个层
这些工具完全屏蔽了 CUDA 的底层复杂性,让人工智能工程师能够专注于人工智能模型和应用,而无需关注硬件细节。这些系统提供了强大的支持,推动了人工智能应用的横向扩展。
整体的 “CUDA 平台”
CUDA 常被视为一种编程模型、一组库,甚至仅仅是 “英伟达 GPU 运行人工智能所依赖的东西”。但实际上,CUDA 远不止如此。它是一个统一的品牌,是一个真正庞大的软件集合,也是一个经过高度优化的生态系统,所有这些都与英伟达的硬件深度集成。因此,“CUDA” 这个术语含义模糊,我们更倾向于使用 “CUDA 平台” 这一表述,以明确我们所谈论的更像是 Java 生态系统,甚至是一个操作系统,而不仅仅是一种编程语言和运行时库。

CUDA 的复杂性不断扩大:涵盖驱动程序、语言、库和框架的多层生态系统
从核心来看,CUDA 平台包括:
庞大的代码库:经过数十年优化的 GPU 软件,涵盖从矩阵运算到人工智能推理的所有领域。
广泛的工具和库生态系统:从用于深度学习的 cuDNN 库到用于推理的 TensorRT,CUDA 涵盖了大量的工作负载。
针对硬件优化的性能:每次 CUDA 发布都会针对英伟达最新的 GPU 架构进行深度优化,确保实现顶级效率。
专有且不透明:当开发者与 CUDA 的库 API 交互时,底层发生的很多操作都是闭源的,并且与英伟达的生态系统紧密相连。
CUDA 是一套强大且庞大的技术体系,是整个现代 GPU 计算的软件平台基础,其应用甚至超越了人工智能领域。
CUDA平台的演进史,实为一部软硬件协同进化的史诗——从可编程着色器的萌芽到万亿级AI生态的崛起,英伟达用二十年时间构筑起层层嵌套的技术护城河。这座由数亿行优化代码堆砌的巴别塔,既成就了深度学习革命的算力基石,也暴露出行业深陷路径依赖的隐忧。DeepSeek绕过CUDA直抵PTX层的突破,犹如刺破云层的闪电,揭示了一个关键真相:当硬件创新进入深水区,软件栈的范式革命可能比晶体管密度更具颠覆性。
当前AI竞赛的本质,早已超越单纯算力的军备较量,演变为生态系统重构权的争夺。正如LLVM曾打破编译器的垄断格局,MLIR等新一代基础设施正悄然重塑计算范式。行业的真正瓶颈不在于芯片的物理极限,而在于如何构建开放、可移植的创新土壤——这要求我们以更底层的思维解构CUDA神话,在编译器、中间件与开发者体验的交叉点上寻找突破口。历史的经验反复印证:每一次计算民主化的浪潮,终将由那些敢于跳出既有框架、用算法效率对冲硬件鸿沟的颠覆者引领。此刻,我们正站在算力平权时代的门槛上,答案或许就藏在软件与硬件的缝隙之间。