过去二十年,数据中心的性能进步主要依赖于计算芯片——CPU、GPU、FPGA 不断演进,但进入生成式 AI 时代后,整个算力体系开始被网络重新定义。在大模型训练中,GPU 间的通信延迟与带宽瓶颈,已经成为训练效率的关键约束。尤其当模型参数突破万亿级,单个GPU已难以承担任务,必须通过数千、数万张 GPU 的并行协同来完成训练。
在这一过程中,网络的重要性愈发凸显,近日,行业内的一则大消息是:Meta/Oracle两大科技巨头选择了NVIDIA Spectrum-X以太网交换机与相关技术。此举被业界视为以太网向AI专用互连迈出的重要一步。

同时也反映出英伟达正在加速向开放以太网生态渗透,绑定云巨头与企业客户。英伟达已经凭借 InfiniBand控制了封闭的高端网络,如今又正在“开放”的以太网生态中设下第二道围墙。
Spectrum-X,以太网AI化
过去几十年,以太网是数据中心采用最为广泛的网络。但在AI为核心的时代,AI 的核心挑战不在单个节点的算力,而在分布式架构下的协同效率。训练一个基础模型(如 GPT、BERT、DALL-E),需要跨节点同步海量梯度参数。整个训练过程的速度,取决于最慢的那一个节点——这正是 “尾延迟(Tail Latency)” 问题的根源。
因此,AI 网络的设计目标不是“平均性能”,而是要确保极端情况下也不拖后腿。这对网络延迟、丢包率、流量调度、拥塞控制乃至缓存架构,都提出了远超传统以太网的要求。为此,英伟达推出了Spectrum-X,首个专为AI优化的以太网解决方案。
那么,Spectrum-X具体做了哪些改进呢?在NVIDIA最新白皮书《Networking for the Era of AI: The Network Defines the Data Center》中,英伟达对此有着详细的介绍。
第一、打造无损以太网。在传统以太网中,丢包与重传被视为“可接受成本”。但在AI训练中,任何丢包都可能导致 GPU空闲、同步失败或能耗激增。
Spectrum-X 通过:RoCE(RDMA over Converged Ethernet)技术实现CPU旁路通信;PFC(Priority Flow Control) + DDP(Direct Data Placement) 确保端到端无损传输;再与Spectrum-X SuperNIC联动,实现硬件级拥塞检测与动态流量调度。
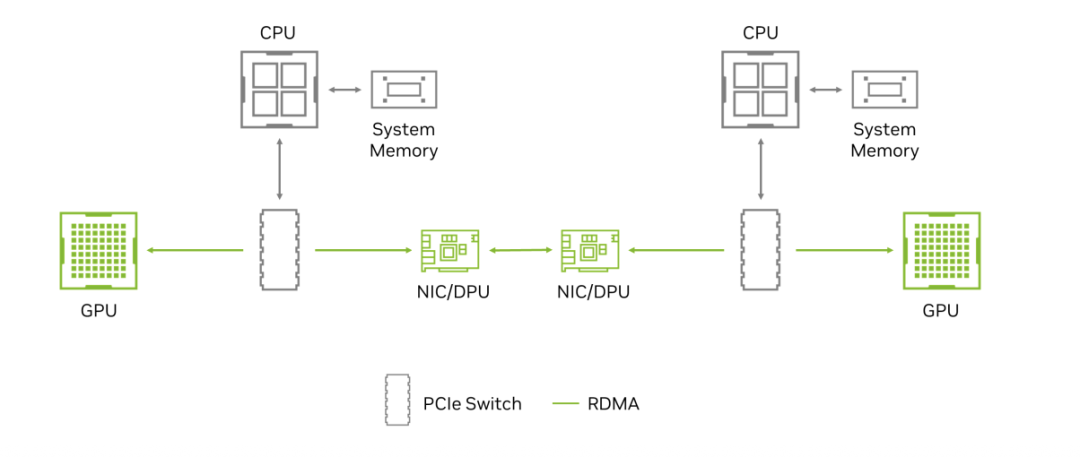
GPU-to-GPU通信的RDMA实现图(来源:英伟达)
这使得以太网第一次具备了接近 InfiniBand的传输确定性。
第二、自适应路由与分包调度。AI 工作负载与传统云计算最大的不同在于,它产生的是少量但极庞大的“象流(Elephant Flows)”。这些流量极易在网络中形成热点,造成严重拥塞。
Spectrum-X采用包级自适应路由(Packet-level Adaptive Routing)与分包喷射(Packet Spraying)技术,通过实时监测链路负载,动态选择最优路径,并在 SuperNIC 层完成乱序重排。这种机制打破了以太网静态哈希路由(ECMP)的局限,使 AI 集群在流量不均时仍能保持线性扩展能力。
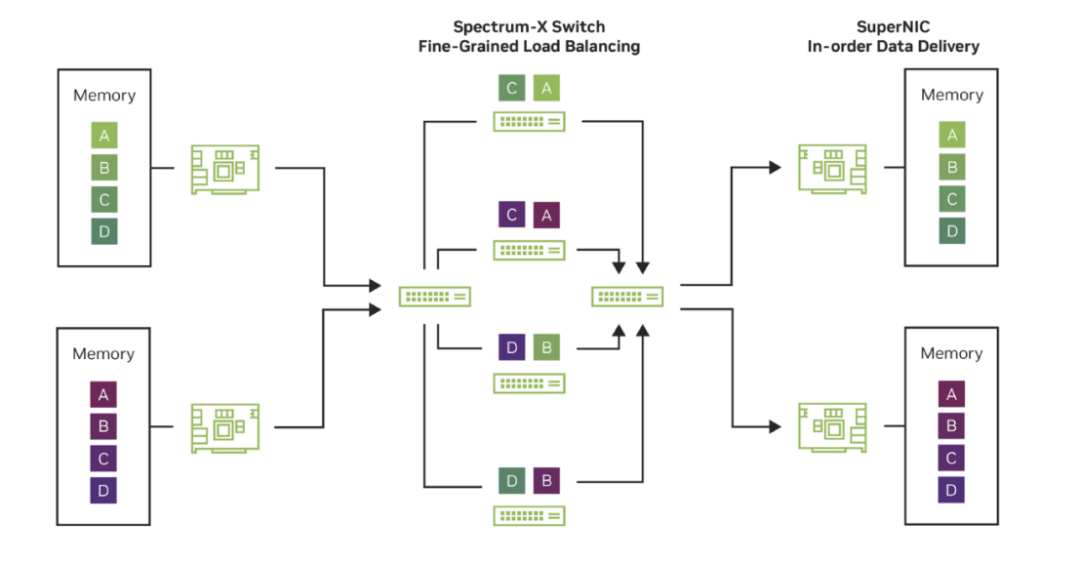
VIDIA Spectrum-X 以太网自适应路由实现图示(来源:英伟达)
第三、解决拥塞控制问题。传统ECN拥塞控制的最大问题是响应延迟太高。当交换机检测到拥塞并发出 ECN 标记时,缓冲区往往已被填满,GPU已出现空转。
Spectrum-X通过硬件级 In-band Telemetry(带内遥测) 实时上报网络状态,SuperNIC 据此立即执行 Flow Metering(流量节流),实现亚微秒级反馈闭环。英伟达声称,其技术已展现出创纪录的效率,其拥塞控制技术实现了 95% 的数据吞吐量,而现成的大规模以太网吞吐量约为 60%。
第四、性能隔离与安全。AI云往往需要在同一基础设施上运行来自不同用户或部门的训练任务。Spectrum-X通过共享缓存架构(Universal Shared Buffer) 确保不同端口公平访问缓存,防止“吵闹邻居”任务影响他人。同时配合 BlueField-3 DPU,在网络与存储层提供:MACsec/IPsec 加密(数据在途安全);AES-XTS 256/512 加密(数据静态安全);Root-of-Trust 与 Secure Boot(硬件安全启动)。这使得AI云具备了类似私有集群的安全隔离能力。
可以说,Spectrum-X让以太网有了“AI 基因”。因此,这也赢得了Meta和Oracle的青睐,不过两家在采用 Spectrum-X上选择了不同的落地策略,各自围绕自身业务诉求做出优化。
Meta的路线更侧重“开放可编排的网络平台”——将 Spectrum 系列与 FBOSS 结合、并在 Minipack3N 这类开源交换机设计上实现落地,体现了Meta在软硬分离、可编程控制面方面的持续投入。对 Meta而言,目标是以开放规范支持其面向数十亿用户的生成式 AI 服务,既要高效也要可控。
Oracle则将 Vera Rubin 作为加速器架构、以 Spectrum-X 做为互联骨干,目标是把分散的数据中心、成千上万的节点聚合为统一的可编排超算平台,从而为企业级客户提供端到端的训练与推理服务。Oracle 管理层将此类部署称为“Giga-Scale AI 工厂”,并将其作为云竞争中的差异化基石。
无论路线如何不同,二者的共同点十分明显:当算力持续呈指数级增长时,网络层决定了这些“理论上的算力”能否转化为“实际可用的吞吐与业务价值”。
Spectrum-X的杀伤力几何?
从产业链竞争格局的角度来分析,NVIDIA Spectrum-X 的推出,确实是一场对以太网网络行业结构的“降维打击”。
首先要理解,Spectrum-X 不是一款单独的交换机产品,而是一种系统战略。它将以下三个组件绑定为一个“软硬一体”生态:
Spectrum-X 交换机 ASIC(实现无损以太网与自适应路由);
Spectrum-X SuperNIC(负责包级重排、拥塞控制与遥测反馈);
BlueField-3 DPU(提供安全隔离与 RoCE 优化)。
也就是说,NVIDIA 把原本属于独立厂商的三层网络生态(交换机、网卡、加速器)一口吞下,让“网络成为 GPU 的延伸模块”,实现了 Compute–Network–Storage 的垂直闭环。因此,这一战略几乎撼动了整个以太网生态。
这意味着过去依靠以太网标准生存的网络公司——无论是卖芯片的、卖交换机的、卖优化软件的——都被迫进入一场新的博弈:要么融入NVIDIA的AI网络体系,要么被边缘化。
直接被波及的企业当中,首当其冲的是数据中心以太网芯片厂商,例如Broadcom(Trident/Tomahawk 系列)、Marvell(Teralynx、Prestera)。Spectrum-X 的 RDMA over Ethernet 能力本质上在挑战所有高端以太网芯片的价值。这些厂商长期垄断“交换芯片+NIC”双生态,以往他们的卖点是“开放 + 性价比”。但当 NVIDIA 把 AI 优化特性(如 DDP、Telemetry、Lossless Routing)内嵌到 GPU/DPU 协同体系中后,这意味着 Spectrum-X 实际上撕开了以太网的“算力黑箱”,势必会一定程度上波及到这些厂商。
再一个可能受到影响是传统网络设备供应商,例如Cisco(思科)、Arista Networks(艾睿思塔)、Juniper Networks(瞻博),这些公司在超大规模云数据中心中一直是“以太网标准派”的代表。他们的高端产品主要卖点是:支持 400/800 GbE;提供丰富的可编程特性;软件定义网络(SDN)管理能力。
但在 Spectrum-X 架构下,英伟达通过“GPU + SuperNIC + Switch + DPU”形成封闭但极致的性能链条,客户无需再依赖 Cisco/Arista 的传统优化方案,尤其在 AI 工厂这种“单租户+极端性能”的环境中,英伟达可以逐渐取代他们的角色。Arista的市值已经有一半来自 AI 网络预期,但 Spectrum-X 若被 Meta、Oracle、AWS 等大客户全面采用,Arista 的增长模型可能会被削弱。
第三个群体是,专注互连的初创芯片企业。如Astera Labs、Cornelis Networks、Liqid、和 Rockport Networks、Lightmatter、Celestial AI等——正在开发具备低延迟、高拓扑可扩展性的定制互连方案。
首先让我们简单分析下这些厂商存在的意义,在英伟达的世界里,互连是垂直整合的:GPU → NVLink → Spectrum-X/InfiniBand → BlueField。但对于其他厂商(AMD、Intel、Google TPU),他们没有控制整个堆栈的能力,因此急需这些 “中立型互连供应商” 提供可替代方案。例如:Astera Labs 的 Leo/Cosmos系列控制器,已经被用在AMD MI300与Intel Gaudi 平台上,用来管理GPU与内存池的互连。Cornelis Networks 则与欧洲超算中心合作,推出 Omni-Path 200G 网络,用以替代 InfiniBand;Liqid 的 Composable Fabric 方案被戴尔和 HPE 集成,用于“AI 基础设施即服务(AI IaaS)”。Lightmatter 与 Celestial AI 则瞄准更远的未来——当光互连取代电互连时,整个 AI 计算集群的架构都将被重写。
一旦大型云厂选择 Spectrum-X 架构,就意味着其整个集群在驱动、遥测、QoS 控制层面都依赖 NVIDIA。初创厂商的开放 Fabric 难以兼容。在短期内,Spectrum-X 的整合速度与客户绑定深度,确实让这些独立创新者的市场空间被明显压缩。
InfiniBand稳坐高性能计算的王座
如果说Spectrum-X是以太网的AI化,那么英伟达Quantum InfiniBand则是AI原生的超级网络。
从一开始,以太网追求的是开放性与普适性——它容忍一定丢包与延迟,以换取成本与兼容性。而InfiniBand的设计哲学恰恰相反:它追求极致的确定性与零损传输(Lossless Determinism)。早在 1999 年,它便作为 HPC(高性能计算)领域的数据互连标准登场,如今已成为全球超级计算中心的事实标准。
凭借三大特性,InfiniBand在过去二十余年间始终稳居性能巅峰:
无损传输(Lossless Networking):确保训练过程中无一字节数据丢失;
超低延迟(Ultra-Low Latency):通信时延以微秒计,远低于传统以太网;
原生 RDMA 与网络内计算(In-Network Computing):在网络层执行计算聚合,释放主机负载。
这些能力让 InfiniBand 成为 AI 训练时代的“通信主干”,尤其是在大模型动辄上万 GPU 节点的架构下,它依然能维持线性扩展与稳定的同步性能。
英伟达在2019年以近70亿美元收购Mellanox后,掌握了InfiniBand的全栈生态。最新的Quantum-2是英伟达InfiniBand架构的第七代产品,被业界视为当前最具代表性的高性能网络平台。它为每个端口提供高达 400 Gb/s 的带宽,是前代产品的两倍;其交换芯片的端口密度更是提升了 三倍,可在三跳 Dragonfly+ 拓扑 内连接超过 一百万个节点。
更重要的是,Quantum-2 引入了第三代 NVIDIA SHARP(Scalable Hierarchical Aggregation and Reduction Protocol) 技术——这是一种将计算能力“嵌入网络”的聚合机制,使网络本身成为“协处理器”。在这一架构下,AI 模型训练的加速能力较上一代提升 32 倍,并支持多个租户与并行应用共享同一基础设施而不牺牲性能,真正实现了“网络级虚拟化”的算力资源池化。
然而,InfiniBand的辉煌背后,也潜藏着结构性的挑战。一方面,它由 NVIDIA 主导并保持着较强的生态封闭性——这种“垂直一体化”的架构虽然带来性能优势,但也引发了云服务商与 OEM 厂商的担忧:成本高、生态受限、兼容性有限、议价空间有限。
正因如此,以太网阵营正在加速反击。包括 Meta、Oracle、Broadcom、AMD 在内的多家企业,正通过 Ultra Ethernet Consortium(超以太网联盟) 推动新一代开放标准,希望在开放以太网架构下重建 InfiniBand 级的确定性与性能。这也是为何英伟达为何选择推出Spectrum-X的一个原因,主动把自家优势算法、遥测和拥塞控制机制“嫁接”到以太网标准体系中,以便在以太网生态中保持网络层的话语权。

超以太网联盟的指导成员
结语
从 InfiniBand 到 Spectrum-X,英伟达正在完成一场看似开放、实则更深层次的“垄断重构”。它在封闭与开放之间搭建双轨系统——一条面向 HPC 与超算(InfiniBand),一条面向云与企业 AI(Spectrum-X)。最后,就用英伟达白皮书中的一句话结束吧:“The network defines the data center.”——AI时代的算力,不再在芯片之间,而在连接之中。