随着美国科技巨擘 谷歌 在上周重磅推出Gemini3 AI应用生态之后,这一最前沿AI应用软件随即风靡全球,推动谷歌AI算力需求瞬间激增。从近期谷歌Gemini AI付费用户反馈以及社交媒体热议来看,无论是B端大企业们还是C端的个人用户们均感叹这是“人类社会迄今最强悍的多模态大模型”,有望指数级革新企业经营效率以及C端用户软件协作效率,因此包括摩根士丹利、瑞穗等华尔街大型投资机构们看涨谷歌股价前景以及所谓的整个“谷歌AI生态链”的声音可谓愈发响亮。
在这些金融大鳄们看来,不仅“谷歌AI生态链”最核心参与者——即谷歌TPU芯片开发主导者 博通 有望全面受益于谷歌AI算力需求史无前例地全面大爆发而迈向新一轮的“超级牛市”,与谷歌主导的“光互联”高性能网络基础设施密切相关联的谷歌AI生态链参与者们以及聚焦于数据中心企业级高性能存储系统的存储领军者们,同样将跟随谷歌AI算力基础设施与AI应用生态野蛮扩张而走向前所未有的“AI繁荣周期”。
在美东时间周二有媒体报道称,Facebook母公司 Meta Platforms, Inc. 正与谷歌方面就斥资数十亿美元采购TPU AI算力集群进行谈判,无疑彻底引爆与谷歌TPU AI算力集群有关的全球投资热潮——推动全球股市与谷歌供应链相关的企业股价暴涨,与此同时AI GPU技术路线的代表——英伟达与AMD等AI GPU类别的AI算力领军者股价则陷入颓势。
有知情人士爆料称,Facebook母公司Meta正考虑2027年斥资数十亿美元购买谷歌TPU AI算力基础设施,包括用于Meta的无比庞大AI数据中心建设,以及赛富时首席执行官马克·贝尼奥夫近日表示,该公司将弃用OpenAI大模型,转而使用谷歌最新发布的人工智能大模型Gemini 3,在这些最新消息加之此前不久有着“OpenAI劲敌”称号的Anthropic计划斥资数百亿美元购置100万块TPU芯片共同强劲催化之下,所谓的“谷歌AI生态链”可谓愈发火热,几乎所有生态链参与者股价近日均实现狂飙式上扬。
根据Semianalysis测算数据,谷歌最新的TPU v7 (Ironwood) 展现出了惊人的代际跨越,TPU v7的BF16算力高达4614 TFLOPS,而上一代被广泛使用的TPU v5p仅为459 TFLOPS,这堪称是整整一个数量级的提升。此外,TPU v7显存直接对标英伟达Blackwell架构的 B200,针对特定应用,架构上更具性价比与能效比优势的AI ASIC可以更容易地吃下主流推理端算力负载,比如谷歌最新TPU集群甚至能提供比英伟达Blackwell高出1.4倍的每美元性能。
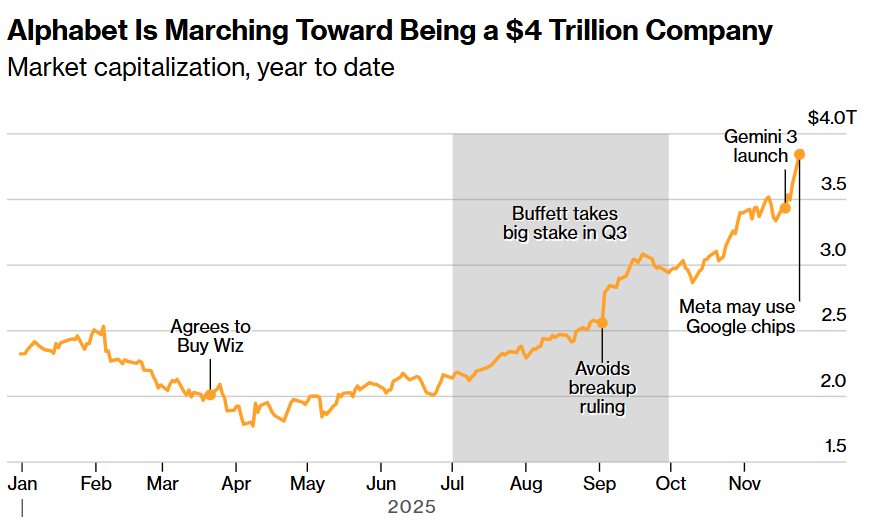
谷歌最新发布的一系列基于Gemini 3的AI产品组合,一经发布即带来无比庞大的AI token处理量,进一步验证了华尔街所高呼的“AI热潮仍然处于算力基础设施供不应求的早期建设阶段”,再叠加“股神”巴菲特一经建仓谷歌母公司Alphabet就位列伯克希尔前十大重仓股,谷歌近期可谓全面强化“AI牛市叙事”,强力驳斥一些投资者所焦虑的“AI泡沫时刻”已经来临。
毫无疑问,在谷歌Gemini3震撼问世,加之英伟达仍然炸裂式增长业绩驱动下,全球投资者们时隔多个月之后,再度感受到AI狂热投资资金的“AI信仰”所带来的巨大震撼,带动与谷歌密切相关联的AI半导体以及全球AI应用软件板块股价大举上攻。
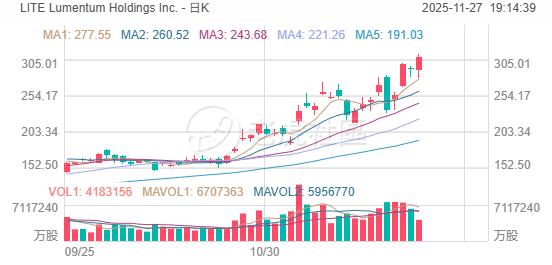
瑞穗点出受益于“谷歌AI需求大爆发”的关键股票名单:博通、Lumentum以及美光科技
华尔街金融巨头瑞穗(Mizuho)近日在一份最新研报中不仅看好全球AI ASIC最强领军者——博通未来股价将迈向新一轮牛市行情(TPU AI算力集群就是一种最典型的AI ASIC技术路线),还将OCS(光电路交换机)与高速光互联器件领军者 Lumentum Holdings Inc. 股票的目标价从290美元大幅上调至325美元。
随着大模型架构逐渐向几种成熟范式收敛,更具性价比与能效比的AI ASIC可以更容易地吃下主流推理端算力负载。并且某些云服务商或行业巨头会深度耦合软件栈,让 ASIC兼容常见的网络算子,并提供优秀的开发者工具,这将加速 ASIC 集群推理在常态化/海量化AI推理场景中的普及。英伟达AI GPU则可能更加聚焦于超大规模前沿探索性的训练、变化极快的多模态或新结构快速试验,以及 HPC、图形渲染、可视分析等通用算力。
瑞穗指出,谷歌独家具备的张量处理器算力集群(Tensor Processing Units,即谷歌TPU AI算力集群)产能爬坡非常有利于Lumentum业绩增长。当前AI基建扩张之势可谓如火如荼,谷歌等超大规模云厂们在构建TPU /AI GPU算力集群之时,正在积极把OCS + 高速光模块作为“高性能网络基础设施底座”全面铺开。
此外,瑞穗分析师团队认为美国存储巨头美光科技也将是谷歌AI算力集群加速扩张的最大受益者之一,毕竟无论是谷歌无比庞大的TPU AI算力集群,抑或是谷歌购置的海量英伟达AI GPU算力集群,均离不开需要全面集成搭载AI芯片的HBM存储系统,以及当前谷歌加速新建或扩建AI数据中心必须大规模购置服务器级别高性能DDR5存储设备以及企业级高性能SSD。而美光正好同时卡在这三块:HBM、服务器DRAM(包括 DDR5/LPDDR5X)、以及高端数据中心SSD,是“AI内存+存储栈”里最直接的受益者之一。
由瑞穗资深分析师Vijay Rakesh领衔的股票分析师团队表示,谷歌TPU在有着“OpenAI劲敌”称号的Anthropic的潜在大规模渗透,以及近期市场上关于Meta和亚马逊旗下云计算巨头Amazon Web Services(AWS)的相关动态消息流,都是对AI ASIC芯片领军者博通的重大利好。
Rakesh等分析师认为,虽然Meta当前庞大的AI算力基础设施大约有95%是建立在英伟达AI GPU基础之上——即基于英伟达以及AMD的大规模AI GPU算力集群,但是转向使用TPU AI算力集群带来的新增TPU订单,无疑对于博通非常有利,哪怕仅仅侵蚀Meta AI算力基础设施中10%的AI GPU算力集群份额,也将对于英伟达以及AMD构成温和挑战,对于博通则是重大利润增量。
不过瑞穗的分析师们表示,虽然TPU AI算力集群正式宣告崛起,他们仍然继续看好英伟达基本面与股价强劲,因为2025-2026年营收规模超过5000亿美元的Blackwell和Rubin架构产品管线“牛市逻辑”依旧完好无损且仍有强劲的估值上行空间。瑞穗的分析师们还表设计,AI芯片巨头英伟达拥有高度多元化的客户群,涵盖云服务提供商、企业客户,以及通过与OpenAI和CoreWeave合作在中东地区达成的全新主权AI合作协议(合作方包括Humain和Neoclouds)。
“整体而言,我们认为,Lumentum是任何程度TPU产能爬坡的关键受益者之一,并且谷歌主导的OCS仍处于早期阶段。”瑞穗分析师们表示。“因此博通仍是我们的首选芯片股标的,与此同时我们将Lumentum的目标价从290美元上调至325美元,因谷歌TPU的爬坡尤其利好于OCS业务。在短期内,分析师同样看好美光盈利的强劲上行潜力——截至2月份的美光季度业绩指引有望受益于DRAM/NAND价格的‘超级顺风’。”瑞穗分析师Rakesh及其团队表示。
Lumentum 之所以是谷歌AI大爆发的最大赢家之一,主要是因为它正好做的是与谷歌TPU AI算力集群深度捆绑的“高性能网络底座系统”中的不可或缺光互连——即OCS(光路交换机)+ 高速光器件,TPU数量每多一层量级,它的出货就跟着往上乘。毋庸置疑的是,包括光模块在内的整个光通信产业链都在受益,因为基于天量级算力的光互连AI大模型训练/推理本质上是“把十万级算力芯片用光纤织成一台机器”,网络带宽和端口数的增速,已经不亚于AI芯片本身,这也是为何近日中国A股市场光模块全面大爆发。
谷歌在Jupiter/AI数据中心网络体系里,已经大规模把 OCS(光路交换机)集群嵌进架构,用来支撑TPU AI系统和大规模训练/推理系统,Lumentum的R300/R64等OCS产品就是专门对准“大型云计算规模 + AI/ML 数据中心网络”:用MEMS光路直接在端点间建立光连接,绕开中间电交换和 OEO 转换,主打高端口数、低时延、低功耗。同时它还是 400G/800G 这类高速数通光模块和光互联芯片的重要供应商,官方已经把这些产品定位为“为AI和超大规模云数据中心提供可扩展互连带宽”的核心器件。
瑞穗看好美光受益于谷歌AI算力大爆发的逻辑则在于AI基建热潮如火如荼之下的存储“超级周期”。在谷歌、微软以及Meta正在主导的建设这类超大规模AI数据中心里,除了通过3D堆叠DRAM所打造的HBM存储系统之外,服务器级别的DDR5也是“刚需级”且必须大规模采购的核心存储资源,两者是互补关系,而不是替代关系。当前支撑天量AI训练/推理算力需求的AI服务器算力集群的DRAM容量通常是传统CPU服务器的4–8倍,很多单机已经超过1TB DRAM,并且明确是向DDR5迁移,主要因为DDR5相比DDR4带宽提升约50%,更适合天量级AI工作负载。
全球两大存储巨头——三星电子与SK海力士,以及西部数据和希捷等存储巨头们近期公布的无比强劲业绩,令摩根士丹利等华尔街大行高呼“存储超级周期”已至,凸显出全球持续井喷式扩张的AI训练/推理算力需求以及端侧AI热潮驱动的消费电子需求复苏周期全面带动DRAM/NAND系列存储产品需求指数级扩张,尤其是美光存储业务中占据最高份额的DRAM细分领域HBM存储与服务器级别高性能DDR5;此外,NAND领域的企业级SSD需求激增。
属于谷歌AI生态链的牛市才刚刚开始?
Gemini3震撼全球,再叠加“股神”巴菲特“最后一舞”建仓谷歌母公司Alphabet即位列伯克希尔前十大重仓股,不仅这家谷歌母公司股价步入暴涨曲线且屡创历史新高——自10月中旬以来大涨超35%且市值开始逼近4万亿美元超级关口,博通、Lumentum、台积电以及MongoDB等谷歌AI生态链的重要参与者们股价均进入屡创新高的狂野暴涨模式。
这位驰骋全球商场与金融市场数十年、年龄高达95岁的“奥马哈先知”将在2025年年末正式卸任伯克希尔首席执行官一职,因此巴菲特所掌舵的伯克希尔·哈撒韦公司最新13F股票持仓,更像是巴菲特在他本人堪称传奇的投资生涯谢幕阶段,把“科技时代核心筹码”从苹果的消费电子生态系统逐渐交棒给“谷歌AI生态链”。
谷歌凭借AI全栈优势构筑起的“AI超级护城河”,挂钩AI资本开支的实际效率以及AI货币化/创收路径相比于Facebook母公司Meta、微软以及亚马逊而言可谓具备显著领先优势且具体路径更加清晰明朗。
全面布局芯片(TPU)-高性能网络基础设施(OCS)-模型(Gemini)-AI应用生态(云计算/搜索引擎/AI+广告营销/主权AI等),尤其是谷歌自研TPU芯片“能效比”与“性价比”相比于单纯的英伟达AI GPU算力集群实现跨越式发展,加之Gemini系列模型能力全球领先,全球资金蜂拥而至,无比重视谷歌AI算力需求的高增长以及TPU算力集群扩张所带来的谷歌AI生态链重大投资机遇。
华尔街分析师们当前集体聚焦的“谷歌TPU AI算力集群”,甚至在不久后的AI算力基础设施市场规模有望占据3-4成,进而冲击当前在该市场占据90%市场份额堪称垄断的英伟达。在华尔街巨头摩根士丹利、花旗、Loop Capital以及Wedbush看来,以AI算力硬件为核心的全球人工智能基础设施投资浪潮远远未完结,现在仅仅处于开端,在前所未有的“AI推理端算力需求风暴”推动之下,持续至2030年的这一轮AI基础设施投资浪潮规模有望高达3万亿至4万亿美元。
摩根士丹利近日发布的一份研报显示,考虑到市场普遍预期英伟达可能将在2027年出货约800万块GPU(假设产能充足),对于谷歌而言,50万至100万块TPU的销售预测可能并非“不合理”。根据摩根士丹利的最新测算,谷歌每对外部销售50万片TPU,将为其云计算业务营收带来大约11%的额外提升,并使其每股收益(EPS)足足增加3%(即EPS+0.37美元)。
大摩表示,未来谷歌TPU AI算力集群将从仅仅满足谷歌内部的AI算力基础设施需求,转变为在全球AI算力持续紧缺背景下满足外部市场需求的“AI战略资产”。大摩强调,谷歌云业务的超预期加速增长及向AI芯片市场的大举扩张,有望使谷歌以及整个“谷歌AI生态链”参与者们的股票获得更高级别的市盈率估值倍数。