投资人Brad Gerstner认为英伟达会是第一个市值超过十万亿美元的公司。
近期,英伟达(NVDA.US)投资“出手”频繁,先是宣布50亿美元投资英特尔,随后斥资至多1000亿美元投资OpenAI,而受此前OpenAI与甲骨文的合作,市场均在股价层面给予了积极反馈。
但市场也出现了质疑声音——称英伟达、OpenAI与甲骨文存在“收入循环”,财务数字“操作”大于实际营收。
9月25日,在播客BG2最新一期节目中,BG2主播、Altimeter Capital创始人Brad Gerstner,Altimeter Capital合伙人Clark Tang与英伟达CEO黄仁勋展开了一次对话。黄仁勋在对话中回应了当下市场的关心的问题。
黄仁勋认为,投资OpenAI实际上是一个很好的机会,并认为OpenAI将是下一家数万亿美元级别的Hyperscaler。
此外,黄仁勋也特别解释了为什么ASIC芯片并不完全和英伟达GPU是竞争关系——因为英伟达是AI基础设施提供商,其提供的能力范围已经不仅仅是硬件和软件层面,也包括其不断迭代的速度、规模优势带来的可靠性,以及整体能源效率等综合因素。
因此,黄仁勋认为英伟达目前的护城河比三年前“更宽“,而Brad Gerstner甚至认为,英伟达将是史上第一家达到十万亿美元的公司。
以下为「明亮公司」编译的访谈正文(有删节):

Brad Gerstner:Jensen,再次欢迎你。你的红色眼镜很好看,真的很适合你。距离上次上播客,已过去一年多。你们如今超过40%的收入来自推理(inference),而且推理正因为chain of reasoning链式推理而要起飞了。
黄仁勋:大多数人还没真正内化这一点,这其实就是一场工业革命。
投资OpenAI不是合作的前提,是因为有机会能投
Brad Gerstner:说真的,从那次之后,感觉你我每天都像在验证那期播客。在AI的时间尺度上,这一年像过了一百年。我最近重看了那期,很多观点让我印象深刻。
最打动我的是你当时拍着桌子说——当时大家觉得预训练进入低潮(pre-training),很多人说预训练要完蛋了,硬件建设过度。那是大约一年半前。你说推理不会只是一百倍、一千倍。会是十亿倍。这把我们带到今天。你刚宣布了一项巨大合作,我们应该从这里聊起。
黄仁勋:我想正式说下,我认为我们现在有三条Scaling Law。第一是预训练的Scaling Law。第二是后训练(post-training)的Scaling Law。后训练基本上就是让AI练习一种技能,直到做对,它会尝试很多不同方法。要做到这一点,就必须进行推理(inference)。所以训练与推理如今以强化学习的方式整合在一起,非常复杂,这就是后训练。
第三是推理(inference)。过去的推理是“一次出手”,而我们现在理解的新推理,是“先思考再作答”。先想,再回答,想得越久,答案质量越高。思考过程中你会检索、查证事实、学到东西,再继续思考、继续学习,最后输出答案,而不是上来就生成。所以思考、后训练、预训练,如今我们有三条Scaling Law,而不是一条。
Brad Gerstner:这些你去年就提过,但你今年说推理会提升十亿倍,并由此带来更高水平智能”的信心更高吗?
黄仁勋:我今年更有把握。原因是看看如今的智能体系统。AI不再是单一语言模型,而是由多个语言模型组成的系统,它们并发运行。有的在用工具,有的在做检索,事情非常多,而且是多模态。看看生成的视频,简直令人难以置信。
Brad Gerstner:这也引到本周的关键时刻,大家都在谈你们与OpenAI的重磅合作Stargate。你们将成为首选合作伙伴,并在一段时间内向公司投资1000亿美元。他们会建10个“gig“(Gigawatt,吉瓦)。如果这10个“gig”都用英伟达,那对你们的收入贡献可能高达4000亿美元。帮我们理解一下这个合作,对你意味着什么?以及为何这项投资是合理的?
黄仁勋:我先回答后一个问题,再回到我的叙述。我认为OpenAI很可能成为下一家数万亿美元级的hyperscale公司。
就像Meta是hyperscale,Google也是,他们会同时拥有C端与企业服务。他们非常可能成为下一家多数万亿美元级的hyperscale公司。如果是这样,能在他们达到那个规模之前投资进去,是我们能想象到的最聪明的投资之一。你必须投资你熟悉的东西,恰好我们熟悉这个领域。所以这笔钱的回报会非常出色。
我们很乐意投资,但不是必须的,也不是合作的前提;是他们给了投资机会,这太好了。
我们与OpenAI在多个项目上合作。第一,Microsoft Azure的建设,我们会持续推进,这个合作进展非常顺利,未来还有数年的建设;第二,OCI(Oracle Cloud Infrastructure)的建设,我想大概有5-7个GW要建。我们与OCI、OpenAI、软银一道推进。这些项目都已签约,正在实施,工作量很大。第三是CoreWeave。所有与CoreWeave相关的……我还在讲OpenAI,对,一切都在OpenAI语境里。
所以问题是,这个新伙伴关系是什么?它是帮助OpenAI首次自建AI基础设施。也就是我们直接与OpenAI在芯片、软件、系统、AI工厂层面协作,帮助他们成为一家完全自运营的hyperscale公司。这会持续相当一段时间,是对他们现有建设的补充。
他们正经历两个指数曲线:第一个指数是客户数量在指数级增长,因为AI在变好、用例在变好,几乎每个应用现在都连到OpenAI,所以他们正经历使用指数;
第二个指数是计算量的指数增长。每个使用场景的算力在暴涨。过去是一键式推理,现在要先思考再回答。这两个指数叠加,大幅抬升了计算需求。我们会推进所有这些建设。因而这个新合作是对既有所有合作的“增量”,去支撑这股惊人的指数增长。
Brad Gerstner:你刚说到一个很有意思的点,你认为他们极大概率会成为数万亿美元公司,是很好的投资;同时你们还在帮助他们自建数据中心。过去他们把数据中心外包给微软,现在他们要自建“全栈工厂”,就像Elon和X那样,对吧?
Brad Gerstner:想想Colossus的优势,他们构建全栈,就是hyperscaler,即便自己用不完容量,也能卖给别人。同样的,Stargate在建设海量容量,他们觉得会用掉大部分,但也能售卖出去。这听起来很像AWS、GCP(谷歌云)或Azure,是这意思吗?
黄仁勋:我认为他们很可能自己用掉,就像X大多会自用。但他们希望与我们建立直接关系——直接工程协作和直接采购关系。就像Zuck、Meta与我们之间的直接关系。我们与Sundar和Google的直接关系,我们与Satya和Azure的直接伙伴关系。他们规模足够大了,认为该建立这些直接关系了。我很乐意支持,而且Satya(微软CEO)知道,Larry(谷歌联合创始人)知道,大家都知道。
华尔街与英伟达之间预期背离:如何理解AI的需求规模
Brad Gerstner:这儿有件事我觉得颇为神秘。你刚提到Oracle 3000亿、Colossus的建设,我们知道一些主权国家在建(AI基础设施),hyperscaler也在建。Sam正以万亿美元的口吻来谈这一切。可覆盖你们股票的华尔街25位卖方分析师的共识却显示,你们从2027年开始增长放缓,预2027-2030年年化增速8%。这些人的唯一工作就是给英伟达做增长预测。显然……
黄仁勋:我们对此很坦然。看,我们经常能轻松超预期。
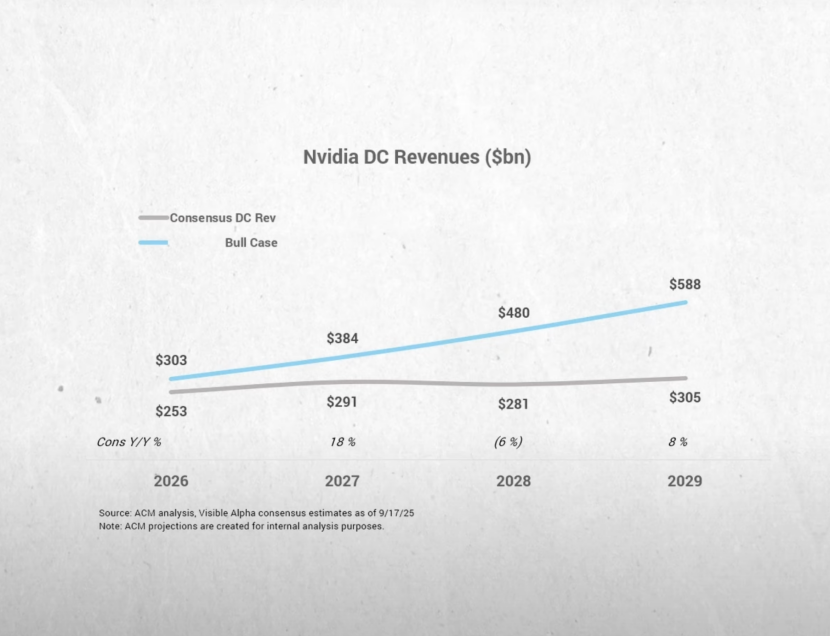
英伟达数据中心营收的增长预期(来源:BG2)
Brad Gerstner:我明白。但这仍是个有趣的“背离”。我每天都在CNBC、彭博上听到。很多人担心短缺会转向过剩,他们不相信持续高增长。他们说,行,我们给姑且信你们的2026年,但2027年可能供给过剩、不再需要那么多。但共识预测其实显示这不会发生。我们也做了自己的预测,纳入了所有这些数字。
结果是,即便进入“AI时代”两年半,各方的信念仍然分歧巨大,Sam Altman、你、Sundar、Satya的看法,与华尔街仍然相信的相去甚远。对此,你依旧感到从容吗?
黄仁勋:我也不认为这不一致。首先,我们这些“建设者”应该为“机会”而建。我们是建设者。让我给你三个思考点,有助于你对英伟达的未来更放心。
第一点,是物理定律层面的、最关键的一点,通用计算已到尽头,未来属于加速计算与AI计算。这是第一点。
你可以这样想:全球有多少万亿美元的计算基础设施要被更新换代。所以首先你得认识到通用计算的终结。没人反对这一点。摩尔定律已死,人们常这么说。那么这意味着什么?通用计算会转向加速计算。我们与Intel的合作就是在承认通用计算需要与加速计算融合,为他们创造新机会。通用计算正迁移到加速计算与AI。
第二点,AI的首要用例其实已无处不在——在搜索、在推荐引擎等等。基础的hyperscale计算基础设施过去由CPU执行推荐,如今要由GPU执行AI。你把传统计算换成加速计算与AI;你把hyperscale计算从CPU换到加速计算与AI。这是第二点。仅仅满足Meta、Google、字节跳动、Amazon,把它们传统的hyperscale方式搬到AI,就是数千亿美元的市场。
所以,哪怕先不谈AI创造新机会,仅仅是AI改变了旧做法到新做法。然后再谈未来。是的,到目前为止我其实只谈了“平凡”的事。旧方式不对了。你不会再用煤油灯,而要用电。这就够了。
然后是更不可思议的,当你走向AI、走向加速计算,会出现什么新应用?就是我们在谈的所有AI相关,机会巨大。怎么理解?简单想想,过去电机替代了体力劳动;现在我们有AI——我称之为AI超级计算机、AI工厂——它们会生成tokens来增强人类智能。而人类智能占全球GDP的55%-65%……我们就算50万亿美元吧,这50万亿将被某种东西增强。
回到个人层面,假如我雇一位工资10万美元的员工,再给TA配一个1万美元的AI,如果这个AI让那位员工产能翻倍、三倍?我会不会做。一定会做。我现在就在给公司里每个人配,没错,每位协作智能体(co-agents)、每位软件工程师、每位芯片设计师都已有AI与其协作智能体,覆盖率100%。
结果是我们做的芯片更好,数量在增长,推进速度更快。公司因此增长更快、招聘更多、生产率更高、营收更高。利润更高。现在把英伟达的故事套到全球GDP上,很可能发生的是,这50万亿会被……我们取个数,10万亿美元所增强。而这10万亿需要跑在一台机器上。
AI与过去IT的不同在于,过去软件是事先写好,跑在CPU上,不怎么自己“动”。未来,AI要生成tokens,而机器要生成这些tokens、它“在思考”,所以软件一直在运行;过去是一次性编写,现在是持续编写、持续思考。要让AI思考,就需要工厂。假设这10万亿token的毛利率是50%,其中5万亿需要工厂、需要AI基础设施。
所以如果你告诉我全球每年的资本开支大概是5万亿美元,我会说这个数看起来说得通。这大概就是未来的轮廓——从通用计算到加速计算;把所有hyperscale都换成AI;然后用AI去增强人类智能,覆盖全球经济。
Clark Tang:以今天而言,我们估算年市场规模大约4000亿美元,所以TAM从现在到目标是四到五倍的提升。
黄仁勋:没错。昨晚(北京时间9月24日)阿里巴巴的吴泳铭(Eddie Wu)说,从现在到20年代末,他们要把数据中心电力(消耗)提升十倍。对吧?你刚才说四倍?这就对上了。他们要把电力提升十倍,而我们的收入与电力几乎是正相关。(注:吴泳铭表示,对比2022年GenAI元年,到2032年阿里云全球数据中心能耗规模将提升10倍)他还说token生成量每几个月就翻倍。
这意味着什么?单位能耗性能(perf per watt)必须指数级提升。这就是为什么英伟达要疯狂推进单位能耗性能提升,而单位能耗收入(revenue per watt)基本就是收入。
Brad Gerstner:在这个未来里,有个假设从历史角度看我觉得很迷人。两千年里,全球GDP基本不增长。然后工业革命来了,GDP加速;接着数字革命,GDP又加速。你现在的意思和Scott Bessent(美国现任财长)说的一样——他认为明年全球GDP增长会到4%。你其实是在说全球GDP增速将加快,因为我们正在给世界提供“数十亿同事”来为我们工作。而如果GDP是在既定劳动与资本下的产出,那么它必须……
黄仁勋:一定会增长。看看AI正在发生的事,AI的技术形态、可用性,诸如大语言模型与AI智能体,都在推动一个新的“智能体行业”。这点毫无疑问。OpenAI就是历史上收入增长最快的公司,他们在指数级增长。所以AI本身是个高速增长的行业,因为AI需要背后的工厂与基础设施,这个行业在增长,我的行业也在增长;而因为我的行业在增长,在我们之下的行业也在增长——能源在增长、电力与厂房在增长。这简直是能源产业的复兴。核能、燃气轮机……看看我们生态之下的那些基础设施公司,他们做得很棒,大家都在增长。
Brad Gerstne:这些数字让大家都在谈是否会“供给过剩”或“泡沫”。Zuckerberg上周在一个播客说了,可能会有短期的“气阱”(Airpocket),Meta可能会多花个100亿美元之类的。但他说,这不重要。对他业务的未来而言太关键了,这是必须承担的风险。但从博弈角度看,这有点像“囚徒困境”。
黄仁勋:开心的囚徒。
Brad Gerstner:再捋一遍。今天我们估算到2026年,会有1000亿美元的AI收入,不含Meta,也不含跑推荐引擎的GPU还有搜索等其他工作负载,我们就先算1000亿。
黄仁勋:但hyperscale行业本身到底有多大?这个行业现在的基数是多少?
Brad Gerstner:以万亿美元计。
黄仁勋:对。这个行业会先部署AI,不是从零起步,你得从这里开始。
Brad Gerstner:不过怀疑者会说,我们必须从2026年的1000亿,长到2030年至少1万亿的AI收入。你刚才还谈到5万亿。从全球GDP的自下而上推演看,你能看到从1000亿到1万亿在未来五年实现吗?
黄仁勋:能,而且我会说我们其实已经到了。因为Hyperscalers已经把CPU迁到AI,他们的整个收入基座如今都由AI驱动。
Brad Gerstner:是的。
黄仁勋:没有AI就没有TikTok,对吧?没有AI就没有YouTube Shorts。Meta做的为你定制、个性化的内容,没有AI就做不到。以前那些事情,靠人类事先创作、提供几个选项,再由推荐引擎挑选。现在是AI生成无限多的选项。
Brad Gerstner:这些转变已经发生:我们从CPU迁到GPU,主要是为了那些推荐引擎。
黄仁勋:对。Zuck会告诉你,我在SIGGRAPH时他也说过,他们其实到得有点晚。Meta用GPU也就一年半、两年的事。搜索上用GPU更是崭新的、刚刚开始的。
Brad Gerstner:所以论证是,到2030年我们有1万亿AI收入的概率几乎确定,因为我们几乎已经达到了。
接着我们只谈“增量”。不管你做自下而上还是自上而下,我刚听了你按全球GDP占比的自上而下的分析。那你觉得,未来三到五年内,出现“供给过剩(glut)”的概率有多大?
黄仁勋:在我们把所有通用计算彻底转换为加速计算与AI之前,我认为出现过剩的概率极低。
Brad Gerstner:会花几年?
黄仁勋:直到所有推荐引擎都基于AI,直到所有内容生成都基于AI。因为面向消费者的内容生成很大程度就是推荐系统之上的,所以所有这些都会转向AI生成。直到传统意义上的hyperscale全部迁到AI,从购物到电商等一切都迁过去。
Brad Gerstner:但所有这些新建项目,我们谈的是“万亿级”,总是提前投资。那如果你们看到了放缓或过剩,是不是还“不得不”把钱投进去?还是说,一旦看到放缓迹象,再随时收缩?
黄仁勋:实际上正相反,因为我们在供给链的末端,我们按需响应。现在,所有VC都会告诉你——你们也知道——全球短缺的是“计算”,不是GPU的数量短缺。只要给我订单,我就造。过去两年我们把整个供应链都打通了,从晶圆启动、到封装、到HBM内存等等,我们都加足了马力。需要翻倍,我们就翻倍,供应链已备好。我们现在等的是需求信号。当云服务商、hyperscaler和客户做年度计划给我们预测时,我们就响应,并按那个预测去建。
问题是,他们每次给我们的预测都会错,因为预测都偏低。于是我们总处于“紧急追赶”模式,已经持续了好几年,每一轮预测都比上一年显著上调。
Brad Gerstner:但还不够。比如去年,Satya看起来稍微收敛了一点,有人说他像房间里那个“更稳重的成年人”,压一压预期。但几周前他又说,我们今年也建了两个“gig”,未来还会加速。你是否看到那些传统hyperscalers——相较于Core Weave或Elon的X,或者相较于StarGate——此前略慢一些的,现在都在加倍投入,而且……
黄仁勋:因为第二条指数来了。我们已经有一条指数在增长,AI的应用和渗透率指数级增长。第二条指数是“推理与思考”,这就是我们一年前讨论的。我当时说,一旦你把AI从“一次性出手、记忆并泛化”推进到“推理、检索与用工具”,AI就在思考,它会用更多算力。
Clark Tang:回到你刚才的点,hyperscale客户无论如何都需要把内部工作负载从通用计算迁到加速计算,他们会穿越周期持续建设。我想部分hyperscalers的负载结构不同,不确定消化速度,现在大家都认定自己严重低配了。
黄仁勋:我最喜欢的应用之一就是传统的数据处理,即结构化与非结构化数据处理。很快我们会宣布一个关于“加速数据处理”的重大计划。
数据处理占据了当今世界绝大多数CPU,它仍然完全跑在CPU上。去Databricks,大多是CPU;去Snowflake,大多是CPU;Oracle的SQL处理,大多是CPU。
大家都在用CPU做SQL/结构化数据。未来,这一切都会迁到AI数据。这是一个极其庞大的市场,我们会推进过去。但你需要英伟达的全部能力——加速层与领域专用的“配方”。数据处理层的“配方”需要我们去构建,但它要来了。
「循环营收」质疑:投资机会不绑定任何条件
Brad Gerstner:还有一个质疑点。昨天我打开CNBC,他们说的是“过剩、泡沫”。换到彭博,是“循环交易与循环营收(round-tripping、circular revenues)”。给在家观看的观众解释下,这指公司之间缔结看似交易、实则缺乏真实经济实质的安排,人为抬高营收。
换言之,增长不是来自真实的客户需求,而是财务数字上。所以当你们、微软或亚马逊投资那些同时也是你们大客户的公司时,比如你们投资OpenAI,而OpenAI又购买数百亿美元的芯片。
请提醒我们、也提醒大家:当彭博等媒体分析师拿“循环营收”大做文章时,他们到底误解了什么?
黄仁勋:建10GW的(数据中心)规模大概就是4000亿美元左右吧。那4000亿要主要由他们的offtake(消纳能力/下游需求)来支撑,它在指数增长。
(支出)这得由他们自有资本、股权融资和可获得的债务来支持,这是三种工具。能融到多少股权与债务,取决于他们对未来收入的把握程度。精明的投资人与授信人会综合权衡这些因素。这是他们公司的事,不是我的。
我们当然要和他们紧密合作,以确保我们的建设能支持他们持续增长,但收入端与投资端无关。投资机会不是绑定任何条件的,是一个纯投资机会。正如前面说的,这家公司很可能成为下一家多万亿美元级的hyperscale公司。谁不想持有它的股权?我唯一的遗憾是,他们早年就邀请我们投资,当时我们太“穷”了,投得不够,真该把所有钱都投进去。
Brad Gerstner:而现实是,如果你们不把本职工作做到位,比如Vera Rubin最终不成好芯片,他们也可以去买别家的。对吧?他们没有义务必须用你们的芯片。正如你说的,你们看待这件事是机会性的股权投资。
黄仁勋:我们投了xAI、投了CoreWeave,这都是很棒的投资。
Brad Gerstne:回到“循环营收”的讨论,还有一个根本点是,你们把一切都摆在台面上,告诉大家你们在做什么。而其背后的经济实质是什么?并不是双方互相倒腾营收。我们看到有用户每月为ChatGPT付费,有15亿月活在用这个产品。你刚说世界上每家企业要么拥抱这一切,要么被淘汰。每个主权国家都把这视为其国防与经济安全的“生死攸关”,就像核能一样。
黄仁勋:问问看,有哪一个人、公司、国家会说“智能”对我们是可选项?没有。这就是基础。关键在于“智能的自动化”。
摩尔定律已死,现在需要极致的软硬件协同设计
Brad Gerstner:需求问题我问得够多了,我们聊系统设计。我接下来会把话题递给Clark。2024年你们切换到了年度发布节奏,对吧?
Hopper之后,2025年的Grace Blackwell是一次巨大升级,需要数据中心进行重大改造。26年下半年会有Vera Rubin,27年有Rubin Ultra,28年有Feynman。年度发布节奏进行得如何?为什么要改为年度发布?英伟达内部的AI是否让你们能落实年度发布?
黄仁勋:是的,答案是肯定的。没有它,英伟达的速度、节奏和规模都会受限。现在没有AI,根本不可能建出我们如今的产品。为什么这么做?记得Eddie(吴泳铭)在财报或大会上说过、Satya说过、Sam也说过……token生成速率在指数级上升,用户使用在指数级上升。我记得OpenAI说周活跃用户有8亿左右,对吧?从ChatGPT推出才两年。
Brad Gerstner:而且这些用户的每次使用都在生成更多token,因为他们在使用“推理时思考”(inference-time reasoning)。
黄仁勋:没错。所以第一点是:在两个指数叠加的情况下,除非我们以不可思议的速度提升性能,否则token生成成本会持续上升。
因为摩尔定律已死,晶体管的单位成本每年几乎不变,电力也大致不变。在这两条“定律”约束下,除非我们发明新技术降成本,否则即便给对方打个几个百分点的折扣,也无法抵消两个指数增长的压力。因此我们必须每年以跟上这个指数的节奏去提升性能。
比如从Kepler(注:2012年4月发布)一路到Hopper(注:2022年3月发布),大概实现了100000的提升。那是英伟达 AI旅程的开端,十年十万倍。Hopper到Blackwell,因为NVLink等,我们在一年内实现了30×的系统级提升;接下来Rubin还会再来一波“x”(数倍),Feynman再一波“×”……
之所以能做到,是因为晶体管本身帮不上太多忙了。摩尔定律基本只剩密度在涨,性能没有相应提升。所以我们必须把问题在系统层面完全拆开,所有芯片同步升级,软件栈与系统同步升级,这是极致的“协同设计(co-design)”。
以前没人做到这个层级。我们同时改变CPU、重塑CPU,与GPU、网络芯片、NVLink纵向扩展、Spectrum-X横向扩展。当然还要去构建更大的系统,在多个AI工厂之间做跨域互联。并且以年度节奏推进。所以我们自身也在技术上形成了“指数叠指数”。这让客户能持续拉低token成本,同时通过预训练、后训练与“思考”让token更聪明。AI变聪明,使用就更多,使用更多就指数增长。
Brad Gerstner:极致的协同设计是什么?
黄仁勋:极致协同设计,意味着你要同时优化模型、算法、系统与芯片。
当摩尔定律还能推动时,只要让CPU更快,一切都会更快。那是在“盒子里”创新,只需把那颗芯片做快。但如果芯片不再变快,你怎么办?就要跳出原有框架来创新。
英伟达改变了行业,因为我们做了两件事——发明了CUDA、发明了GPU,并把大规模协同设计的理念落地。
这就是为什么我们覆盖这么多行业。我们在构建大量库与协同设计。第一,全栈的极致不仅在软件与GPU,还延伸到数据中心层面的交换与网络,以及它们内部的所有软件:交换机、网络接口、纵向扩展与横向扩展,跨全部层面优化。其结果就是Blackwell对Hopper的30×提升。摩尔定律根本做不到,这是极致协同设计的成果。
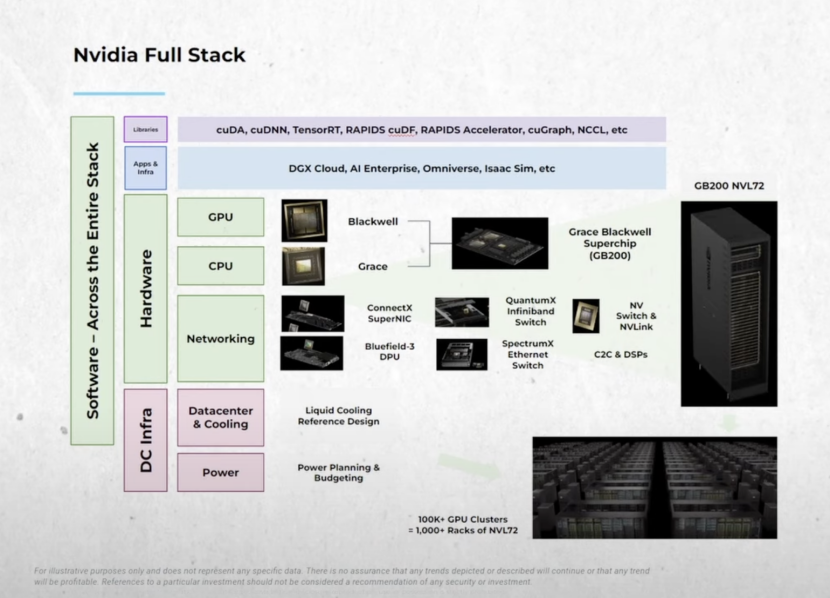
英伟达全部技术栈(来源:BG2)
Brad Gerstner:这些都源自极致协同设计。
黄仁勋:是的,这就是为什么我们要做网络、做交换、做纵向/横向/跨域扩展,做CPU、做GPU、做NIC。也是为什么英伟达的软件如此丰富。我们在开源软件上的贡献提交量,全球能比的没几家。而且这还只是AI领域。别忘了我们在计算机图形、数字生物学、自动驾驶等。我们产出的软件规模极其可观,这让我们能做深度且极致的协同设计。
Brad Gerstner:我从你一位竞争对手那里听说,你们这么做能降低token生成成本。但与此同时,你们的年度发布节奏让竞争者几乎很难跟上。因为你们给供应链三年的可见性,供应链锁定更深,心里有底该供到什么规模。
黄仁勋:你不妨这样想:要让我们一年做几千亿美元级的AI基础设施建设想想我们在一年前就必须提前预备多少产能。我们说的是数千亿美元级的晶圆启动量、DRAM采购量。这个规模,几乎没有公司能承接。
英伟达的护城河为什么更宽了:如何看ASIC的竞争力
Brad Gerstner:你们今天的护城河比三年前更宽了吗?
黄仁勋:是的。
首先,竞争者比以往更多,但难度也比以往更大。因为晶圆成本在上升。除非你在极致规模上做协同设计,否则你交不出那个“数倍”级的增长,这是第一点。所以,除非你一年同时做6-8颗芯片,否则不行。重点不是做一颗ASIC,而是构建一座AI工厂系统。这座系统里有很多芯片,它们都协同设计。它们共同交付我们几乎固定节奏能拿到的那个“10×”。
所以第一,协同设计必须极致。第二,规模必须极致。当你的客户部署1个GW,那就是四五十万颗GPU,要让50万颗GPU协同工作,这就是个奇迹。
所以客户是在承担巨大的风险来购买这些。你得想,有哪个客户会在一个架构上下500亿美元的采购订单?一个全新的、未经大规模验证的架构?
你再兴奋、大家再为你喝彩,当你刚刚展示第一个硅片的时候,会有谁给你500亿美元的订单?你又为何敢在一颗刚刚流片的芯片上启动500亿美元的晶圆?但对英伟达来说,我们敢,因为我们的架构高度成熟与积累的信用。其二,我们客户的规模极其惊人。再者,我们供应链的规模也极其惊人。谁会替一家企业去提前启动这些、预构建这么多,除非他们确信英伟达能把它交付到底?对吧?他们相信我们能交付到全球所有客户手里,愿意一次性启动数千亿美元的供应。
这就是“规模”的故事。
Clark Tang:顺着这个点,全球一个最大的争论是“GPU vs ASIC”,比如Google的TPU、Amazon的Trainium。Arm到OpenAI、Anthropic在传出自研……你去年说过我们构建的是“系统”,不是“芯片”,而你们在堆栈的每一层都驱动性能提升。你还说过这些项目里很多可能永远到不了生产规模,事实上…大多数都到不了。在TPU看似成功的前提下,你今天如何看这片正在演进的版图?
黄仁勋:Google的优势在“前瞻”。
记得他们在一切开始之前就做了TPU v1。这跟创业没区别。你应当在市场尚未做大之前去创业,而不是等市场涨到万亿级再来。所有VC都懂一个谬误:市场很大,只要拿到几个百分点就能做成大公司。这是错的。你该在一个很小的领域拿到“几乎全部份额”,这就是英伟达当年做的,也是TPU当年做的。
所以今天那些做ASIC的人的挑战在于:市场看起来很“肥”,但别忘了,这个“肥市场”已经从一颗叫GPU的芯片,演化为我刚描述的“AI工厂”。
你们刚看到我宣布了CPX(注:Rubin CPX GPU,英伟达专为长语境推理设计的芯片),这是一颗用于“上下文处理与扩散式视频生成”的芯片,是很专门但很重要的数据中心负载。我刚才也暗示,也许会有“AI数据处理”处理器。因为你需要“长期记忆”和“短期记忆”。KVCache的处理非常重,AI记忆是大事。你希望你的AI有好记忆。围绕整个系统处理KVCache非常复杂,也许它也需要一颗专属处理器。
你可以看到,英伟达今天的视角,是俯瞰全体AI基础设施——这些了不起的公司要如何让多元且变动的工作负载流经系统?看看Transformers,这个架构在快速演化。若非CUDA如此好用、易于迭代,他们要如何进行如此海量的实验,来决定采用哪种Transformer变体、哪类注意力算法?如何去做“解耦/重构(disaggregate)”?CUDA之所以能帮你做这一切,是因为它“高度可编程”。
所以看我们的业务,你得回到三五年前那些ASIC项目启动之时,那会儿的行业“可爱而简单”,只有GPU。一两年后,它已巨大且复杂;再过两年,它的规模会非常之大。所以,作为后来者要杀入一个巨量市场,这仗很难打。
Clark Tang:即便那些客户在ASIC上成功了,他们的算力机队里也应该有个“优化配比”,对吧?我觉得投资人喜欢非黑即白,但其实即便ASIC成功了,也要有个平衡。会有很多不同的芯片或部件加入英伟达的加速计算生态,以适配新生的负载。
Brad Gerstner:换句话说,Google也是你们的大客户。
黄仁勋:Google是我们的大GPU客户。Google很特殊,我们必须给予尊重。TPU已经迭代到v7了,对吧?这对他们也是极大挑战。他们做的事情极难。
所以我想先理顺一下芯片的分类。一类是“架构型”芯片:x86CPU、ArmCPU、英伟达GPU,属于架构级,有丰富的IP与生态,技术很复杂,由架构的拥有者构建。
另一个是ASIC,我曾就职于发明ASIC概念的公司LSI Logic。你也知道,LSI早已不在。原因在于,当市场规模不太大时,ASIC很棒,找一家代工/设计服务公司帮你封装整合并代工生产,他们会收你50-60个点的毛利。
但当ASIC面向的市场变大后,会出现一种新方式叫COT(Customer-Owned Tooling,客户自有工具),谁会这么做?比如Apple的手机芯片,量级太大,他们绝不会去付给别人50-60%的毛利做ASIC,他们会自己掌握工具。
所以,当TPU变为一门大生意时,它也会走向COT,这毫无疑问。话说回来,ASIC有它的位置——视频转码器的市场永远不会太大;智能网卡(Smart NIC)的市场也不会太大。
所以当你看到一家ASIC公司有十来个甚至十五个ASIC项目时,我并不惊讶,因为可能其中五个是Smart NIC、四个是转码器。它们都是AI芯片吗?当然不是。如果有人做一颗为某个特定推荐系统定制的处理器,做成ASIC,当然也可以。但你会用ASIC来做那颗“基础计算引擎”吗?要知道AI的工作负载变化极快。有低延迟负载,有高吞吐负载;有聊天token生成,有“思考”负载,有AI视频生成负载,现在你在谈的是……
Clark Tang:算力机群的 “主力骨干”。
黄仁勋:这才是英伟达的定位。
Brad Gerstner:再通俗点讲,就像“象棋vs跳棋”。那些今天做ASIC的人,不管是Trainium还是别的某些加速器,本质是在造一颗“更大机器中的一个部件”。
而你们造的是一个“非常复杂的系统、平台、工厂”,现在你们又开始做一定程度上的“开放”。你提到了CPX GPU,在某种意义上,你们在把工作负载“拆分”到最适合它的硬件切片上。
黄仁勋:没错。我们发布了一个叫“Dynamo”的东西——解耦后AI负载编排(disaggregated orchestration),而且开源了它,因为未来的AI工厂就是解耦的。
Brad Gerstner:你们还发布了NVLink Fusion,甚至对竞争对手开放,包括你们刚刚投资的Intel,这就是让他们也能接入你们正在建的工厂——没人疯狂到要独自建完整工厂。但如果他们有足够好的产品、足够有吸引力,终端客户说我们想用这个替代某个Arm GPU,或者替代你们的某个推理加速器等,他们就可以插进来。
黄仁勋:我们非常乐意把这些接上。NV Fusion是个很棒的主意,我们也很高兴与Intel合作——它把Intel的生态带进来,全球大多数企业工作负载仍跑在Intel上。它融合了Intel生态与英伟达的AI生态与加速计算。我们也会与Arm做同样的融合。之后还会与更多人做。这为双方都打开了机会,是双赢、非常大的双赢。我会成为他们的大客户,他们也会把我们带到更大的市场机会前。
Brad Gerstner:与此紧密相关的,是你提出一个让人震惊的观点:就算竞争者造的ASIC芯片今天已经更便宜,甚至就算他们把价格降到零,也依然会买英伟达的系统。因为一个系统的总运营成本——电力、数据中心、土地等——以及“智能产出”,选择你们仍然更划算,即使对方的芯片白送。
黄仁勋:因为单是土地、电力、厂房等设施就要150亿美元。
Brad Gerstner:我们试着做过这背后的数学题。对很多不熟悉的人来说,这听起来不合逻辑,你把竞品芯片定价为零,考虑到你们芯片并不便宜,怎么可能还是更划算?
黄仁勋:有两种看法。一是从营收角度。大家都受“电力”约束。假设你拿到了新增2GW的电力,那你希望2GW能被转化为营收。如果你的“token单位能耗(token per watt)”是别人的两倍,因为你做了深度且极致的协同设计,你的单位能耗性能更好,那你的客户就能从他们的数据中心产出两倍营收。谁不想要两倍营收?而就算有人给他们15%的折扣——比如我们75%的毛利,别人50%-65%的毛利——这点差距也绝不可能弥补Blackwell与Hopper之间30×的差距。

过去10年大模型单位能效提升了10万倍(来源:BG2)
就算我们把Hopper和别人的ASIC看作同级,Blackwell也有30×的空间。所以在同一个GW上,你要放弃30×的营收。这代价太大了。就算对方白送芯片,你也只有2GW的电力可用,你的机会成本高得离谱——你永远会选择“单位能耗”最强的那套系统。
Brad Gerstner:我从一家hyperscaler的CFO那里听说过,鉴于你们芯片带来的性能提升,特别是以单位能耗(token/gigawatt)和“电力供给”为硬约束,他们不得不升级到新的周期。展望Rubin、Rubin Ultra、Feynman,这条曲线会延续吗?
黄仁勋:我们现在一年做六七颗芯片,每一颗都是系统的一部分。系统软件无处不在。要实现Blackwell的30×,需要跨这六七颗芯片的联调与优化。想象一下,我每年都这么做,砰、砰、砰地连发。如果你在这锅“芯片大杂烩”里只做一颗ASIC,而我们却在整锅里到处优化,这就是个很难的问题。
Brad Gerstner:这让我回到开头的护城河问题。我们做投资许久了,在整个生态投资,也投了你的竞争对手,比如Google、博通。
但当我从第一性原理出发,你们改为以年为单位的发布节奏、跟供应链共研、规模远超所有人预期,这对资产负债表与研发有双重规模要求,你们通过收购与自研推进了NVFusion、CPX等。因此,你们的护城河在拓宽,至少在“构建工厂或打造系统”这件事上是如此。
但有趣的是,你们的估值倍数比那些人都低。我认为部分源自“大数定律”——一家4.5万亿美元的公司不可能再变更大了。但一年半前我也问过你,如果市场会把AI负载提升10×或5×,我们也知道Capex的走势。在你看来,结合刚才谈到的优势下,营收“不大幅更高”的概率有多大?
黄仁勋:我这样回答,我们的机会远大于市场共识。
Brad Gerstner:我认为英伟达很可能成为第一家10万亿美元的公司。我在这行待得够久了。十年前,大家还说世上不可能有1万亿美元公司。现在我们有十家。今天的世界更大了,对吧?
黄仁勋:世界变大了。而且人们误解我们在做什么。大家记得我们是“芯片公司”——没错,我们造芯片,造的是全球最惊人的芯片。但英伟达实际上是一家AI基础设施公司。
我们是你的“AI基础设施合作伙伴”。我们与OpenAI的伙伴关系就是最好证明。我们是他们的AI基础设施伙伴。我们以很多方式与客户合作。我们不要求任何人买我们的一切。我们不要求你买整机柜,你可以买一颗芯片、一个部件、我们的网络,或仅仅买我们的CPU。也有人只买我们的GPU,配别家的CPU和网络。我们基本上是按你喜欢的方式卖。我的唯一请求是,买点儿我们的东西就行。
Brad Gerstner:你说过,不只是更好的模型,还要有“世界级建造者”。你说,也许全国最强的建设者是Elon Musk。我们聊过Colossus One,他在那里把二十几万颗H100/H200组成一个“相干”的大集群。现在他在做Colossus Two,可能是50万颗GPU、相当于几百万H100的“等效”相干集群。
黄仁勋:如果他先于所有人做到1GW,我不惊讶。
Brad Gerstner:既能做软件与模型,又懂如何打造这些集群的“建造者”有什么优势?
黄仁勋:这些AI超级计算机极其复杂。技术复杂,采购复杂(融资),拿地、拿电力与厂房复杂,建设复杂、点亮复杂。这恐怕是人类史上最复杂的系统工程之一。Elon的优势在于:在他脑子里,这些系统是一体协同的,所有相互依赖关系都在他一个人脑中,包括融资。是的,而且……
Brad Gerstner:他自己就是个“大GPT”、一台“大超算”。
黄仁勋:对,终极“GPU”。他有很强的紧迫感,他非常想把它建出来。当“意志”与“能力”相遇时,不可思议的事会发生。
主权AI:AI正在成为每个国家的基础设施
Brad Gerstner:你深度参与的另一块是主权AI……回看30年前,你大概难以想象如今你经常出入白宫。总统说你与英伟达对美国国家安全至关重要。面对这些,先给我个背景——若不是各国把这件事视为“生死攸关”,至少不亚于我们在1940年代看待“核”,你也不会出现在那些地方。如今如果没有一个由政府出资的“曼哈顿计划”,那它也由英伟达、OpenAI、Meta、Google来出资。
黄仁勋:没有人需要原子弹,但人人都需要AI。这就是巨大的不同。AI是现代软件。这是我一开始就说的:从通用计算到加速计算,从人写代码到AI写代码,这个根基不能忘,我们已经重塑了计算。它需要被普及,这就是所有国家都意识到必须进入AI世界的原因,因为每个国家都必须在计算中保持现代化。不会有人说:你知道吗,我昨天还用计算机,明天我就靠木棍和火种了。所以每个人都得继续向前,只是计算被现代化了而已。
第二,为了参与AI,你必须把自己的历史、文化、价值观写进AI。随着AI越来越聪明,核心AI学这些的速度很快,不必从零开始。所以我认为每个国家都需要一定的主权能力。我建议大家都用OpenAI、用Gemini、用Grok、用Anthropic……用各类开放模型。但他们也应该投入资源去学习如何“构建”AI,这不仅是为了语言模型,也是为了工业模型、制造模型、国家安全模型。他们要培养一整套“自己的智能”。因此,每个国家都应具备主权能力。
Brad Gerstner:这是否也是你在全球听到与看到的?
黄仁勋:是的。他们都会成为OpenAI、Anthropic、Grok、Gemini的客户,但同时也需要建设自己的基础设施。这就是英伟达在做的大想法——我们在构建“基础设施”。就像每个国家需要能源基础设施、通信与互联网基础设施,现在每个国家都需要AI基础设施。