编辑:编辑部
【新智元导读】谷歌DeepMind的AI,终于拿下IMO金牌了!六个月前遗憾摘银,如今一举得金,SKEST新算法立大功。这不,它首破解了2009 IMO最难几何题,辅助作图的神来之笔解法让谷歌研究员当场震惊。
时隔6个多月,AlphaGeometry 2直接攻下IMO金牌!
刚刚,谷歌DeepMind一篇28页技术报告,公布了AG2最新突破——
在2000-2024年IMO几何题上,解题率从54%飙升至84%。

论文地址:https://arxiv.org/pdf/2502.03544
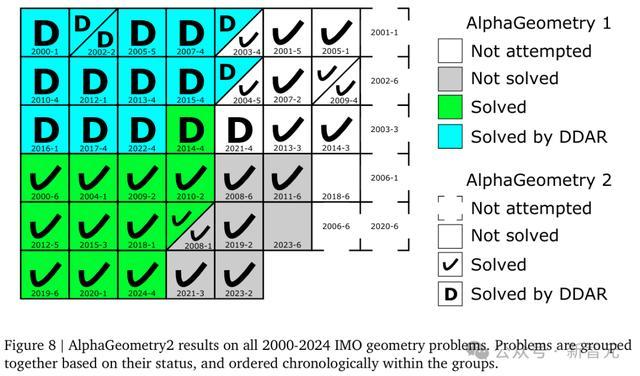
过去近25年IMO几何真题(50道),AG2横扫了42道。要知道,这个成绩已经大幅超于历年IMO金牌得主的平均水平。
去年7月,谷歌曾官宣的两大AI系统AlphaProof和AlphaGeometry 2,距离金牌只有1分之遥。
论文中,团队专为AG2设计了一种全新搜索算法——基于知识共享集成的搜索树(SKEST),允许多个集束搜索(beam search)并行运行并相互帮助。
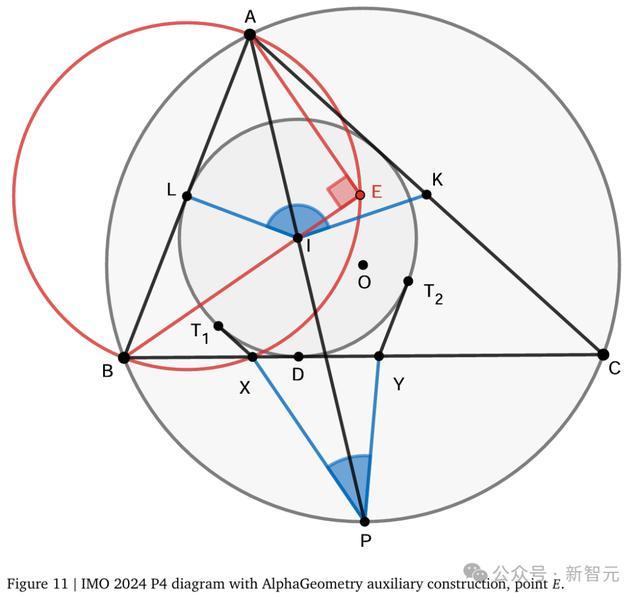
得益于这个算法,AG2能够在19秒内,解决IMO 2024年P4题。
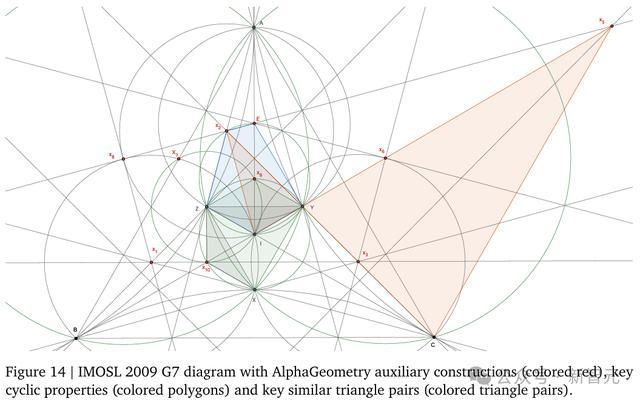
谷歌DeepMind高级研究科学家Thang Luong称,“这是AI首次破解了2009年IMO最难几何题G7(备选题)”。
此前,这道题只有计算性解法(使用复数、三角计算等)。
令人惊讶的是,AG2利用关键的辅助作图(图中的红点),给出了一个只需要“角度”和“比例推导”的优雅解法。
这些点,是由神经符号架构中的“神经网络模型”预测得出的。

有网友表示,“AGI似乎在谷歌内部实现了”。
AG2,一举超越IMO金牌得主
作为全球最具权威的高数竞赛,IMO几何题不仅考验选手对数学概念深刻理解,更需要极强的创造性思维。
而今天,数学这个人类智慧的结晶,正被人工智能以惊人的速度攻克。
第一代AlphaGeometry(AG1)通过将语言模型与符号引擎相结合,在过去25年的IMO几何题中实现了54%解题率。
在当时看来,这个成绩已是相当地惊人。

AG1使用了简单特定域语言,主要由表1列出的九个基本的“谓词”组成
不过,AG1仍在几个关键领域存在局限性,比如特定语言范围、符号引擎效率,以及初始语言模型的能力均会影响其性能。
新一代AlphaGeometry 2,得到了全新升级。
它采用了基于Gemini更强大的语言模型,其在更大更多样化数据集中完成训练,显著提升了理解和推理能力。
同时,谷歌还引入了更快速、更稳健的“符号引擎”,融入了简化规则集、增强双重点处理等优化。
此外,模型领域语言范围也进行了扩展,涵盖了更广泛的几何概念,包括轨迹定理和线性方程。
为了进一步提升性能,团队还开发了一种新型搜索算法,探索更多样的辅助作图策略,并采用知识共享机制,来扩展和加速搜索过程。
AG2最令人瞩目的进展之一是,完全自动化的处理能力。
它可以直接理解自然语言形式的几何问题,借助Gemini团队的技术将问题转化为专用语言,实现了一种全新的“自动图形生成”算法。
得益于以上的改进,AG2在所有IMO几何题上,取得了令人印象深刻的84%解题率。
这意味着,它已经超越了IMO金牌得主的平均水平。
总结来说,AG2带来了几项重大升级:
扩展了领域特定语言(DSL)的覆盖范围,可覆盖88%的IMO几何题目,相比此前的66%有显著提升
改进了符号引擎,使其更加稳健,且速度提升了两个数量级
增强了语言模型,该模型基于Gemini并在更大规模(提升一个数量级)和更多样化的数据集上训练
创新性地提出了一种名为“基于知识共享集成的搜索树”(SKEST)的新算法,能够实现多个搜索树之间的知识共享

更通用的域语言,覆盖88%题目
如上,表1列出的AG1九个基本“谓词”,已经覆盖了2000-2024年IMO几何题目中66%的问题。
但是,AG1的语言无法表达线性方程、点/线/圆的移动,也无法处理“求角度...”这样的常见问题。
由此,谷歌研究人员在AG1的基础上,增加了两个“谓词”,可以解决“查找X”类型的问题:

另外,在某些几何问题中,包括IMO 2024中的一道题目,存在AG1无法表达的几何量(角度、距离)的线性方程。
为了表达这些概念,AG2增加了以下三个谓词:

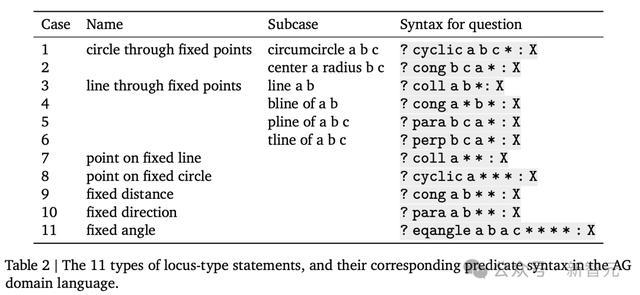
还有一点是,AG1不支持所谓的“轨迹问题”,这类问题涉及点、线和圆等对象的运动,AG2则通过新的谓词语法捕捉这类问题。
表2列出了11种轨迹情况及其对应的谓词和语法。这里使用了一个新的符号*作为固定点的占位符。
除此以外,AG2通过引入一个新的谓词 overlap a b(点A和点B是重合点)来证明点的非独立性,其中涉及A的任何谓词也可以用于B,反之亦然。
在推理闭包(deduction closure)过程中,重合点可以通过作为同一个圆的圆心来定义;
因此,团队引入另一个谓词cyclic_with_center来描述这种情况。因此,cyclic_with_center a1 a2 ... an x表示a_1=a_2=...=a_x是经过点a_x+1...a_n的圆的圆心(当x=0 时,等同于cyclic)。
自动形式化和图形生成
自动形式化
AG1以及其他类似的神经符号系统有一个主要弱点,需要手动将自然语言的输入转换成特定领域的语言。
例如,一个简单的自然语言几何问题“给定三角形ABC,其中两边相等AB=AC,证明角B和角C相等”,在AlphaGeometry的领域特定语言中变成了:“triangle a b c; a b = a c ? eqangle b a b c c b c a”。
在AG2中,团队首先通过人工将几十个几何问题翻译成AG语言。然后,使用这些示例编写少样本提示,要求Gemini将给定的几何问题从自然语言翻译成AG语言。
用这个提示在Gemini中查询五次,然后再调用一次将这些结果合并成一个最终答案。
通过这种方法,AG2能够将IMO 2000-2024中的39个几何问题形式化30个。对于简单的几何问题,这种方法非常有效,几乎没有错误。
自动图形生成
对于无法直接通过几何作图构建的图形(非构造性问题),AG2采用两阶段数值优化方法:
第一阶段使用ADAM梯度下降优化,最小化误差,同时防止点重合和坐标值过大。第二阶段使用Gauss-Newton-Levenberg(高斯-牛顿-勒文伯格)方法,求解非线性方程组,得到精确的图形坐标。
研究团队在44道IMO问题上进行了基准测试,经过上面的优化后,AG2能够为其中41个问题找到图形。
大多数问题在AG2第一次尝试时,甚至几秒钟内就生成了图形。对于剩余的问题,也可以通过更长的运行时间和更多的并行化运算获得图形。
例如,在使用了3333个进程运算了400分钟后,AG2获得了IMO-2011-6(2011年IMO第6题)的图形。
更强大、更快的符号引擎
AlphaGeometry2的核心是“符号引擎”DDAR(演绎数据库与算术推理)。
这是一种用来计算“演绎闭包”的算法。
所谓演绎闭包,就是从一堆最基本的已知事实出发,通过推理能得到的所有事实的集合。
DDAR有一套固定的推理规则,然后它会按照这些规则,一步步地推导出新的事实,把新事实加到集合里,直到没法再推出新的东西为止。
这使它能在两个方面发挥关键作用:一是为语言模型生成训练数据,二是在测试时进行证明搜索,寻找演绎步骤。
在这两种情况下,速度都至关重要。
更快的数据生成意味着可以进行更大规模、更彻底的数据过滤;而更快的证明搜索则意味着可以使得搜索更广泛,从而增加了在给定时间内找到解决方案的可能性。
DDAR的三个主要改进:处理重合点的能力(可以理解为处理更复杂几何图形的能力)、更快的算法和更快的实现。
处理重合点
在AG1中,如果两个点在几何上重合,但名称不同,则系统无法识别它们是同一个点。例如,如果两条线a和b相交于点X,而我们想证明X在某个圆ω上,AG1可能会难以处理这种情况。
AG2通过允许使用具有不同名称但坐标相同的点来解决这个问题。
这种处理重合点的能力非常重要,因为它允许AG2通过“重新表述”来解决问题。在某些情况下,直接证明某个点位于某个圆上可能很困难,但通过引入辅助点并证明该辅助点具有相同的性质,可以简化证明过程。
考虑一个证明两条直线a和b的交点X在圆ω上的例子。
AG2可以通过以下步骤实现:首先,创建一个新的点 X',该点是a和ω的交点;接下来,证明X'位于b上。由于X和X'都位于a和b上,可以得出结论,X和X'是同一点,从而证明X位于ω上。
下图1直观地展示了上述证明过程。
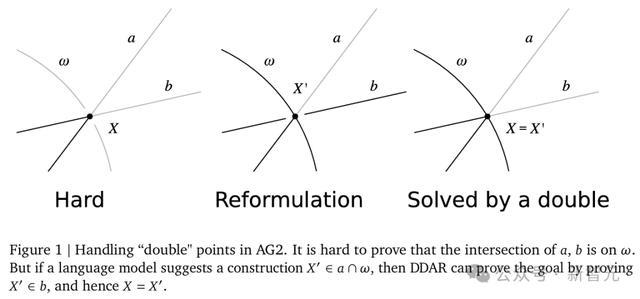
通过这些改进,AG2可以更灵活地处理各种几何问题,并且能够以更接近人类思维的方式解决问题。
更快的算法
AG1的DDAR算法在处理规则列表时,会尝试将每条规则应用于所有可能的点。
为了提高搜索效率,AG2直接硬编码了其应用搜索过程,从而减少了对AR子引擎的查询次数,最多查询三次。
AG2还丢弃了角度和距离的明确规则(例如关于垂直或平行线的规则),这些推导都自动在AR引擎中进行。此外,AG2设计了一种改进的DDAR2算法。
通过这些改进,AG2显著提高了搜索速度和效率,从而加快了证明过程,使得AG2能够更有效地解决复杂的几何问题。
更快的实现
AG2的核心计算部分,特别是高斯消元法,使用C++重新实现。为了与Python环境兼容,AG2使用pybind11将 C++库导出到Python。
通过C++重新实现,AG2的速度比AG1快了300多倍。
这意味着AG2在相同的时间内可以完成更多的计算,从而更有效地解决复杂的几何问题。
更好的合成训练数据
AG2的成功很大程度上归功于其改进的合成训练数据。
AG2使用与AG1相同的程序,但通过扩大资源和改进算法,生成了更大、更多样化、更复杂的数据集,从而显著提升了模型的性能。
AG2首先随机采样几何图形,然后使用符号引擎(DDAR)推导出所有可能的事实。对于每个推导出的事实,使用回溯算法提取相应的前提、辅助点和推导步骤。
AG2严格从随机图开始,这样可以消除数据污染的风险,并探索可能超出人类已知定理分布的定理。
这种方法与TongGeometry等依赖人类专业知识和现有问题图来指导和过滤数据生成的方法形成了鲜明对比。
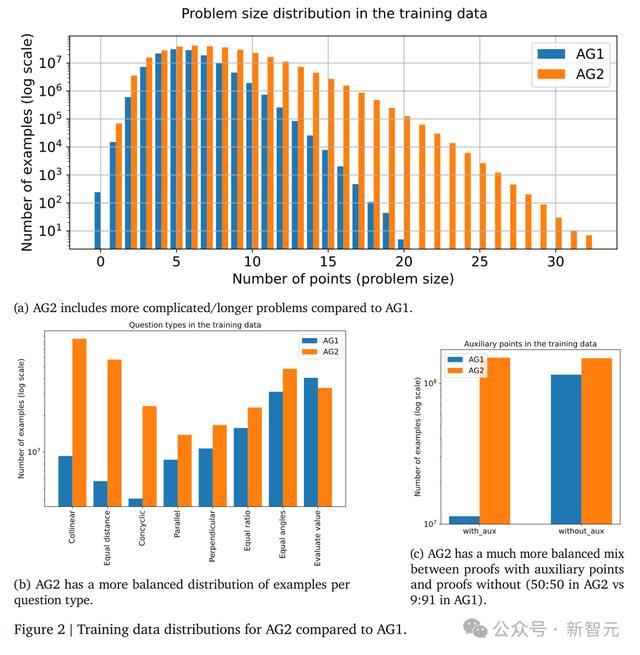
更大、更复杂的图和更好的数据分布
AG2探索的随机图大小是AG1的两倍,从而可以提取更复杂的问题。
生成的定理在复杂性上提高了一倍,包括更多的点和前提。生成的证明步骤最多增加了10倍。
AG2在有和没有辅助点的证明之间有更平衡的数据分布,比例接近50:50,而AG1中有辅助点的证明比例仅为9%。
下图2展示了AG2相比于AG1中包含了更多复杂、更长的问题,在每个问题类型中都有更平衡的分布。
更多类型的定理
除了生成证明经典陈述(如“AB = CD”)的定理外,AG2的数据生成算法还生成“轨迹”类型的问题,例如 “当X在直线/圆Y上移动时,Z在固定直线/圆T上移动”。
AG2通过一个函数P(.)记录每个点在随机图生成过程中的运动依赖性,从而支持轨迹类型问题的生成。
下表3显示了P(.)函数的两个示例,解释了如何确定点的运动源。

更快的数据生成算法
AG1首先在随机图上运行演绎闭包,然后“回溯”以获得最小问题和证明。
为了获得AG1中的最小问题,必须穷举地从问题中移除不同的点集,然后重新运行DDAR来检查可证明性。这对于大量的点来说是不可行的
AG2改用了贪心丢弃算法,该算法只需进行线性次数的检查,就可以判断一组点是否足以证明目标。只要检查是单调的(如果A是B的子集,那么如果A可证明,则B也可证明),贪心算法保证能找到一个关于包含关系的最小点集。
新颖的搜索算法
在AG2中,研究人员设计了一种新颖的搜索算法——基于知识共享集成的搜索树(SKEST)。
在每棵搜索树中,一个节点对应于一次辅助构造尝试以及随后的符号引擎运行。
如果该尝试成功,所有搜索树立即终止。如果尝试失败,该节点会将符号引擎成功证明的事实记录到共享事实数据库中。
经过筛选,这些共享事实不会包含节点自身特有的辅助点,而只保留与原始问题相关的内容,以确保它们对同一搜索树中的其他节点以及不同搜索树中的节点都具有价值。
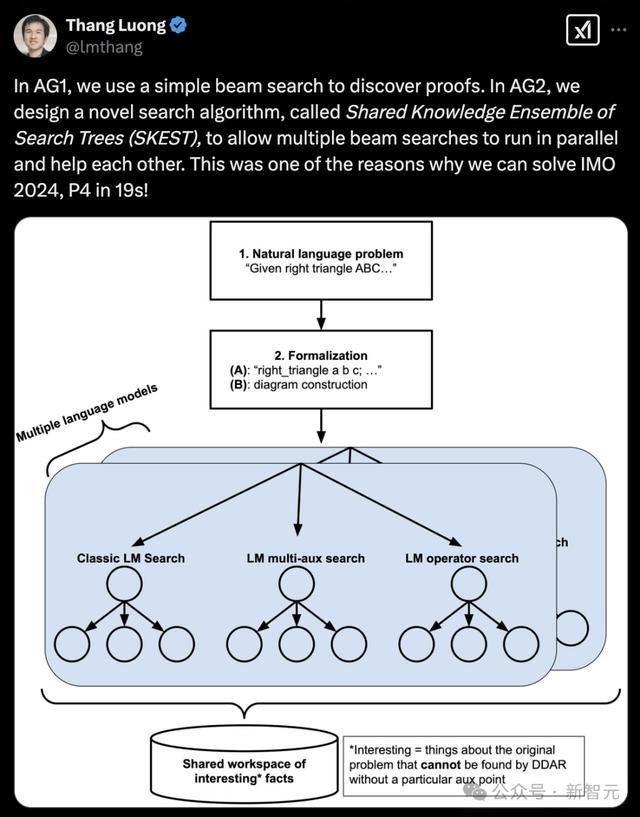
为了确保搜索空间的不同部分都能得到有效探索,研究人员采用了以下几种搜索树:
“经典”搜索树:这种搜索树使用与AG1相同的集束搜索,其中语言模型在每个节点仅生成一个辅助点。
在每个节点预测多个辅助点的搜索树:语言模型被允许在每个树节点生成多个辅助点。
这是可行的,因为语言模型经过训练,可以生成完整的证明,从辅助点开始,并依次推导出推理步骤。
尽管研究人员的目标是让模型在一次查询中生成所有必要的辅助点,但在实践中,他们发现通常需要多次调用模型,以利用先前生成的辅助点。允许模型生成多个辅助点能够加速求解过程,并有效地增加搜索树的深度。
训练设置
AG1语言模型是一个自定义Transformer,在无监督模式下经过两个阶段的训练:首先在包含和不包含辅助构造的题目上训练,然后仅在包含辅助构造的题目上训练。
对于AG2,研究人员采用Gemini训练流水线,并将训练简化为一个阶段,即在所有数据上进行无监督学习。
这个新语言模型是一个基于Gemini构建的MoE模型,并在AG2的数据集上训练。
研究人员训练了多种不同规模的模型,采用三种训练方案:
1. 从零开始训练,使用领域特定语言(DSL)的自定义分词器(与AG1相同)。
2. 微调预训练的数学专用Gemini模型,使用自然语言进行训练。
3. 多模态训练,从零开始并额外引入图像输入,即几何题目的图示。
除了一个包含约3亿条定理的大型合成训练集,研究人员还构建了三个评估集:
1. 合成问题集“eval”:包含带有和不带有辅助点的问题。
2. 合成问题集“eval_aux”:仅包含带有辅助点的问题。
3. IMO评估集“imo_eval”:由2000-2024年IMO中,AlphaGeometry先前成功解决的几何问题组成。
所有这些评估集都包含完整的证明,研究人员在训练过程中计算它们的困惑度损失。
与AG1相同,主要衡量指标是IMO题目的解答率,其中语言模型生成辅助点后,使用DDAR算法结合集束搜索进行求解。
研究人员使用TPUv4进行训练,并采用最大可能的批大小,以充分利用硬件资源。学习率调度策略为线性预热(warm-up)+ 余弦退火(cosine anneal),其中学习率的超参数基于scaling laws设定。
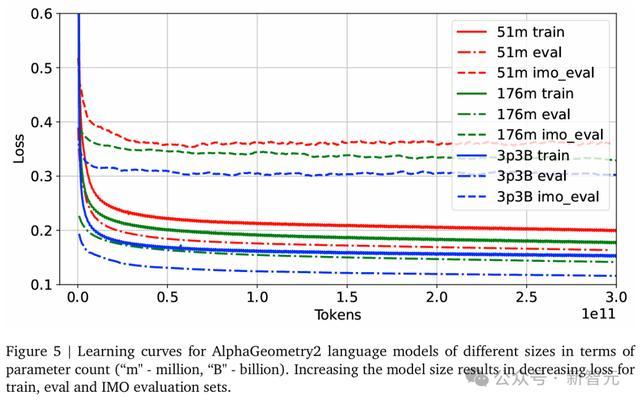
图5展示了不同规模Gemini模型的学习曲线(以参数量为度量)。
如预期所示,模型规模越大,训练集、评估集以及IMO评估集的困惑度损失均会降低。
推理设置
在搜索算法方面,研究人员通过多个搜索树和不同规模的语言模型来解决一个新的问题。
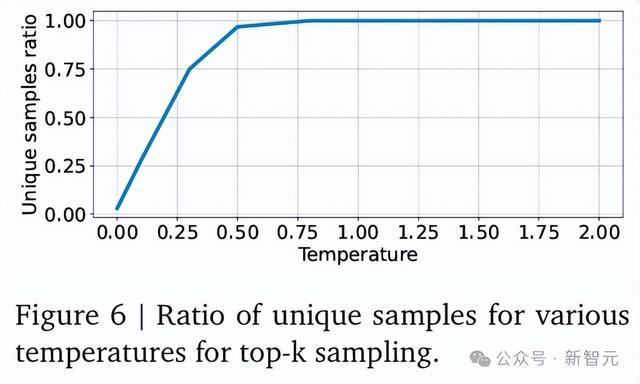
与AG1不同,研究人员使用了温度t=1.0和k=32的top-k采样。需要注意的是,高温度和多个采样对于解决IMO问题至关重要。
在贪心解码模式下(即t=0.0,k=1,且不使用搜索树),模型只能解决26个需要辅助构造的问题中的2个。
而当温度提高到t=1.0并使用k=32个采样(但不使用搜索树)时,语言模型可以解决26个问题中的9个。
如果温度低于t=1.0,则生成的辅助构造不够多样化(见图6);而如果温度过高,则会增加语言模型输出的错误领域语言语法的比例。
这个AI,显示出超凡的创造力
谷歌团队中的几位几何专家和IMO奖牌得主仔细看过AlhpaGeometry的解题过程后,忍不住赞叹道:它展示出了超凡的创造力!
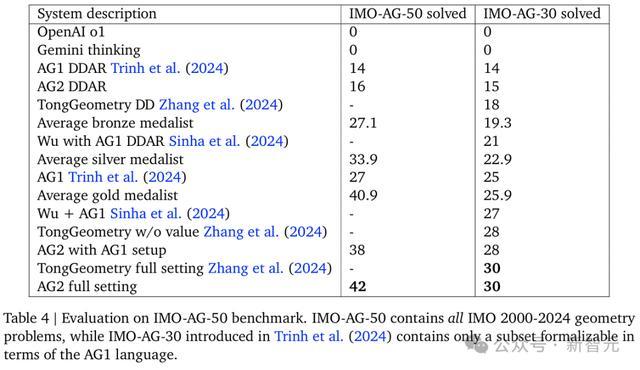
不同配置的AlphaGeometry2,以及其他系统的对比
比如,下面这条题的∠KIL是由中点和内心形成的角度,这两个几何元素通常难以建立关联,且无法直接通过主三角形ABC的角度来计算。
在传统解法中,人类参赛者通常会借助三角函数、复数或其他计算方法来求解。而对于AlphaGeometry而言,其DDAR系统仅依靠基本的角度关系推导和比例关系推导,因此需要引入一些辅助点的构造。
为此,AlphaGeometry在直线BI上巧妙地构造了点E,使得∠AEB = 90°。这一构造优雅地将那些看似无关的几何元素联系起来,形成了两对相似三角形:△ABE与△YBI、△ALE与△IPC。这些相似三角形产生了新的等角关系和等比关系,同时也揭示了点E与线段AB中点L之间的重要联系。
要完成证明,关键在于证明两组三角形的相似性:△AKI ∼ △BPY和△ALI ∼ △CPX,从而得出∠AIK = ∠BYP和∠AIL = ∠CPX。这一过程可以通过运用前述相似三角形所产生的边长比例关系来完成。

正如开篇所述,下面这道题一直以来都只有计算性的解法,例如使用复数、三角计算或通过不等式进行反证法。而AlphaGeometry既不能使用这些计算和推理工具,也不具备高级欧几里得几何知识。
但是,最终的结果却出乎意料——AlphaGeometry通过构建关键的辅助作图,在只用角度和比例追踪的情况下,给出了一个优雅的解决方案。
首先,AlphaGeometry证明了X和Z关于BI对称,根据对称性可知I是三角形XYZ的外心。由此可以证明AB = AC,根据对称性可知三角形ABC是等边三角形。
但是,这个问题的主要挑战在于使用三角形XYZ是等边三角形的条件,即XY=YZ及其循环变体。
为此,AlphaGeometry构造了一系列关键三角形的外心:
D是三角形BXC的外心
E是三角形AYZ的外心
X_1是三角形BIX的外心
X_2是三角形AIY的外心
X_3是三角形CIX的外心
X_4是三角形ABZ的外心
X_5是三角形ACY的外心
X_6是三角形AXZ的外心
X_7是I关于BZ的对称点
X_8是三角形AXY的外心
X_9、X_10是使得三角形IZX_9,三角形IZX_10为等边三角形的点
X_11是Z关于BI的对称点
起初,这些构造看起来非常反直觉,因为大多数人不会构造这些点。考虑到点X,Y,Z的性质,这些点与整个特定配置相关的几何性质并不多,这使得人类很难想出一个综合解法。
尽管如此,这些外心构造有助于形成相等/相似三角形对,这使得AlphaGeometry能够利用三角形XYZ是等边三角形这一事实来解决问题。

从上面的例子中可以看到,AlphaGeometry在构造辅助点方面非常高效,并且能够在不依赖复杂的欧几里得几何知识和工具的情况下,为难题提供非常优雅的解决方案。这使得它能够产生人类通常无法想到的,既富有创意又高效的解法。
那AlphaGeometry有哪些问题是尚未解决的呢?
这样的问题有8个。
其中2个是它已尝试但未解决的,而另外6个则是无法形式化的问题,比如涉及到不等式和可变数量的点,这些目前还不在AlphaGeometry2语言的覆盖范围内。
另外2个则涉及到了一些高级几何解法技巧,如反演、投影几何或根轴等,这些技巧在当前的DDAR中尚未实现。
如果想要做出这些题,就需要更长的推理时间、更长的证明过程,以及更多的辅助构造了,来弥补当前技术的不足了。