
编辑:桃子 KingHZ
大自然的分形之美,蕴藏着宇宙的设计规则。刚刚,何恺明团队祭出“分形生成模型”,首次实现高分辨率逐像素建模,让计算效率飙升4000倍,开辟AI图像生成新范式。
图像生成建模全新范式来了。
你是否曾凝视过雪花的精致对称,或惊叹于树枝的无穷分支?
这些都是大自然中的“分形”。早在1983年,数学家Mandelbrot就揭示了这一现象。
而如今,何恺明团队将这一概念注入AI,重磅提出“分形生成模型”(fractal generative models),将GenAI模型的模块化层次提升到全新的高度。

论文链接:https://arxiv.org/abs/2502.17437
类似于数学中的分形,它采用了“递归结构”,递归调用原子生成模块,构建了新型的生成模型,形成了自相似的分形架构。
具体来说,每个生成模块内部包含了更小的生成模块,而这些小模块内又嵌套着更小的模块。
这也并非凭空想象,科学研究早已证明,大脑的神经网络正是分形的杰作。人类大脑同样是通过模块化递归,将微型神经网络组合成更大的网络。
在像素级图像生成上,研究团队验证了新方法的强大——
“分形生成模型”首次将逐像素建模的精细分辨率的计算效率,提升了4000倍。

分形生成模不仅是一种新模型,更是生成建模领域的全新范式。
它将AI设计与自然界奥秘合二为一,或许通往真正智能道路,就是更深入理解、模拟自然界已有的设计模式。
这篇神作一出世,便有网友表示,何恺明的ResNet 2?

还有大佬称,“分形生成模型代表了AI领域一个激动人心的新前沿。自回归模型的递归特性,就是在学习模仿大自然的模式。
这不仅仅是理论,而是一条通往更丰富、更具适应性AI系统的道路”。

自然界终极设计模式,“分形”无处不在
计算机科学的核心概念之一是模块化。
现代生成模型(如扩散模型和自回归模型)是由基本的“生成步骤”组成的,而每个步骤本身都是由深度神经网络实现的。
将复杂的功能抽象成基本模块,通过组合这些模块来构建更复杂的系统。这就是模块化方法。
基于这一理念,研究团队提出将生成模型本身作为一个模块,从而开发更高级的生成模型。
新方法受到了生物神经网络和自然数据中观察到的分形特性的启发。
与自然分形结构类似,设计的关键组件是定义递归生成规则的“生成器”。
例如,生成器可以是一个自回归模型,如图1所示。在这种实例化中,每个自回归模型由本身也是自回归模型的模块组成。具体来说,每个父自回归模块生成多个子自回归模块,而每个子模块进一步生成更多的自回归模块。
最终的架构在不同层次上展现出类似分形的自相似模式,如图1所示。
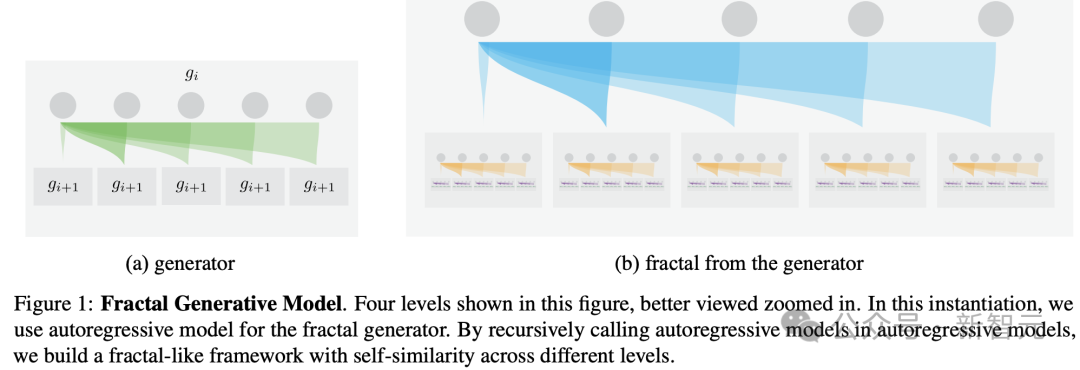
图1:分形生成模型
在这个实例中,使用自回归模型作为分形生成器。在自回归模型中,递归调用自回归模型,构建了一个具有不同层级之间自相似性的类似分形的框架。
动机和直觉
从简单的递归规则中,分形可以产生复杂的模式。
这也是分形生成模型的核心思想:利用现有的原子生成模块,递归地构建成更高级的生成模型。
在分形几何中,这些规则通常被称为“生成器”。
通过不同的生成器,分形方法可以构建许多自然模式,如云、山脉、雪花和树枝,并且和更复杂的系统有关,如生物神经网络的结构、非线性动力学和混沌系统。

Mathworld中不同的分形模式
形式上,分形生成器g_i,指定了如何基于上一级生成器的输出xi,生成下一级生成器的新数据集
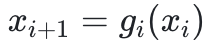
例如,如图1所示,生成器可以通过在每个灰色框内递归调用类似的生成器来构建分形。
由于每个生成器层级可以从单个输入生成多个输出,在仅需要线性递归层级的情况下,分形框架可以实现生成输出的指数级增长。
这特别适合用相对较少的生成器层级,来建模高维数据。
“分形生成模型”核心架构
分而治之
在理论上,生成模型就是建模多个高维随机变量的联合分布,但直接用单一的自回归模型建模,在计算上是不可行的。
为了解决这个问题,采用了分而治之的策略。
关键模块化是将自回归模型抽象为一个模块化单元,用于建模概率分布p(x∣c)。
通过这种模块化,可以在多个下一级自回归模型的基础上构建一个更强大的自回归模型。
假设每个自回归模型中的序列长度是一个可管理的常数k,并且总随机变量数N=k^n,其中n=log_k(N)表示框架中的递归层级数。
分形框架的第一层自回归模型将联合分布划分为k个子集,每个子集包含k^{n−1}个变量。形式上,我们将联合分布分解为:
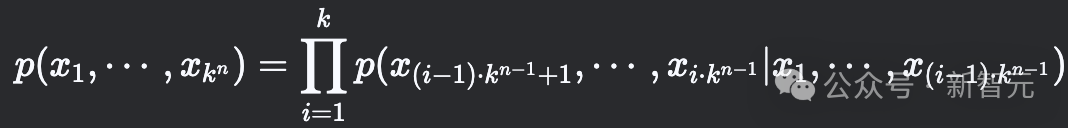
每个包含k^{n−1}个变量的条件分布p(⋯∣⋯ ),由第二层递归的自回归模型建模,以此类推。
通过递归调用这种分而治之的过程,分形框架可以使用n层自回归模型,高效地处理k^n个变量的联合分布。
架构实例
如图3所示,每个自回归模型将上一层生成器的输出作为输入,并为下一层生成器生成多个输出。
它还接受一张图像(可以是原始图像的一部分),将其切分成多个patch,并将这些patch嵌入以形成Transformer模型的输入序列。这些patch也会被传递给相应的下一层生成器。
然后,Transformer将上一层生成器的输出作为一个独立的token,放置在图像token之前。
基于合并的序列,Transformer生成多个输出,供下一层生成器使用。
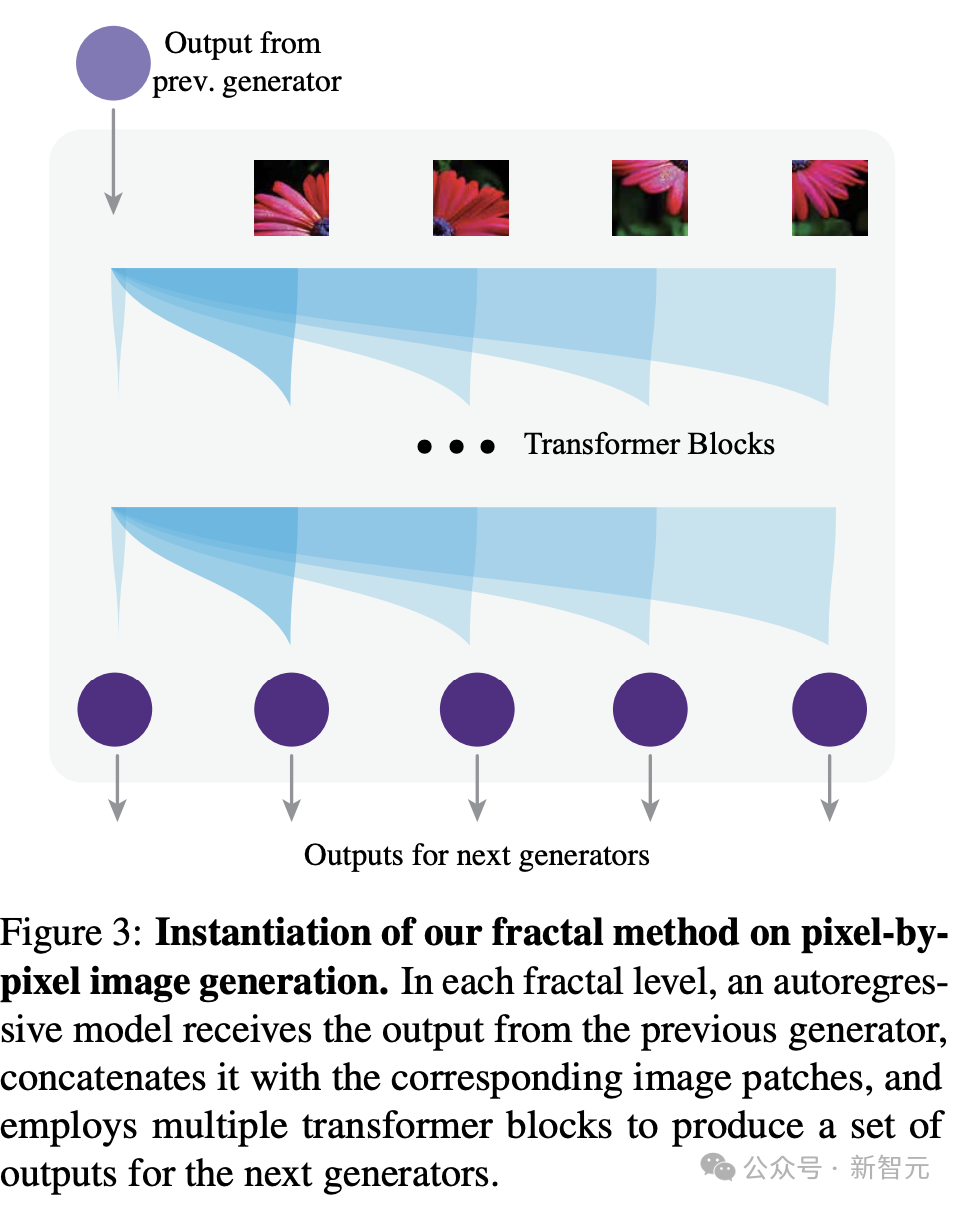
遵循领域内模型中的常见做法,将第一个生成器g_0的序列长度设置为256,将原始图像划分为16×16的patch。
然后,第二层生成器对每个patch进行建模,并进一步将这些patch细分为更小的patch,递归地继续这一过程。
为了管理计算成本,逐渐减少较小patch的Transformer宽度和Transformer块的数量,因为对较小的patch建模,通常比较大的patch更容易。
在最后一级,使用非常轻量的Transformer,以自回归方式建模每个像素的RGB通道,并对预测应用256路交叉熵损失。
值得注意的是,分形设计建模256×256图像的计算,成本仅为建模64×64图像的两倍。
实现
采用宽度优先的方式,端到端训练原始图像像素。
在训练过程中,每个自回归模型从上一层的自回归模型接收输入,并为下一层自回归模型生成一组输出作为输入。这个过程一直持续到最终层级,在那里图像被表示为像素序列。
最后的模型使用每个像素的输出,以自回归的方式预测RGB通道。
对预测的logits计算交叉熵损失(将RGB值视为从0到255的离散整数),并通过所有层级的自回归模型,进行反向传播,从而端到端地训练整个分形框架。
分形模型以逐像素的方式生成图像,按照深度优先的顺序遍历分形架构,如图2所示。
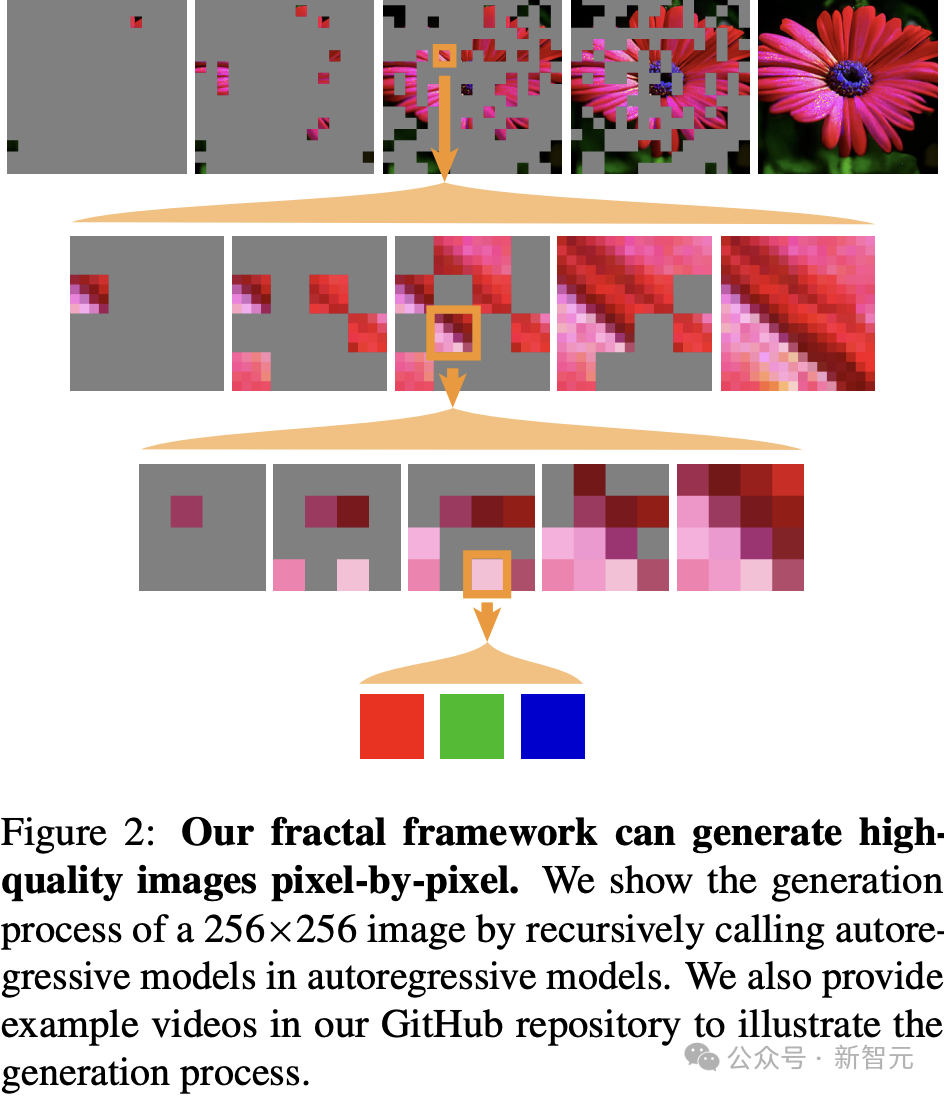
这里,以下文中的MAR的随机顺生成方案为例。

论文链接:https://arxiv.org/abs/2406.11838
第一层:自回归模型捕捉16×16图像patch之间的相互依赖关系,并在每一步根据已知的图像patch生成下一层的输出。
第二层:模型利用这些输出,对每个16×16图像patch内4×4图像patch之间的相互依赖关系建模。
类似地,第三层自回归模型建模每个4×4图像patch内的像素之间的相互依赖关系。
最后,从自回归预测的RGB logits中,最顶层的自回归模型采样出实际的RGB值。
与尺度空间自回归模型的关系
尺度空间自回归模型(Scale-space Autoregressive Models),与分形方法之间的一个主要区别在于:它们使用单一的自回归模型,按尺度逐步预测token。
相较之下,分形框架采用了分而治之的策略,通过生成子模块递归地建模原始像素。
另一个关键区别在于计算复杂度:尺度空间自回归模型在生成下一个尺度的token时,需要对整个序列执行全注意力操作,这导致计算复杂度显著更高。
举个栗子,当生成256×256分辨率的图像时,在最后一个尺度下,尺度空间自回归模型中每个注意力patch的注意力矩阵大小为(256 × 256)² = 4,294,967,296。

而新方法在建模像素间依赖关系时,对非常小的图patch(4×4)进行注意力操作,其中每个图patch的注意力矩阵仅为(4 × 4)² = 256,从而使得总的注意力矩阵大小为(64 × 64) × (4 × 4)² = 1,048,576次操作。
这种缩减使得分形方法在最精细的分辨率下,比传统方法计算效率提高了4000倍,从而首次实现了像素逐像素建模高分辨率图像。
与长序列建模的关系
大多数关于逐像素生成的前期研究,将问题表述为长序列建模,并利用语言建模中的方法来解决这个问题。
然而,许多数据类型的内在结构,包括但不限于图像,超出了单一维度的序列。
与这些方法不同,研究团队将这类数据视为由多个元素组成的集合(而非序列),并采用分治策略递归地对包含较少元素的子集进行建模。
这一方法的动机来源于对这些数据的观察——大量数据展现出近似分形结构:
图像由子图像组成,
分子由子分子组成,
生物神经网络由子网络组成。
因此,旨在处理这类数据的生成模型应当由子模块组成,而这些子模块本身也是生成模型。
实验结果
研究人员在ImageNet数据集上,对“分形生成模型”进行了广泛的实验,分别使用64×64和256×256的分辨率。
评估包括无条件和类别条件图像生成,涵盖了模型的多个方面,如似然估计、保真度、多样性和生成质量。
似然估计
研究人员首先在ImageNet 64×64无条件生成任务上展开评估,以检验其似然估计的能力。
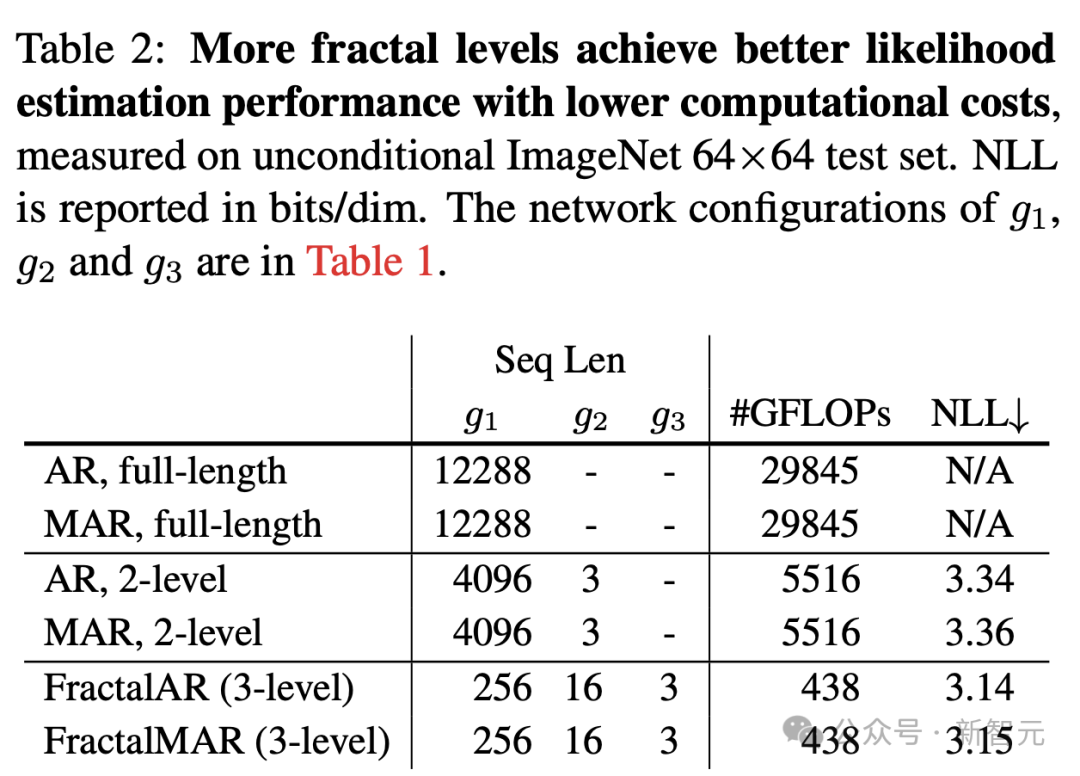
为了考察分形框架的有效性,他们比较了不同分形层级数量下框架的似然估计性能,如下表2所示。
使用单个自回归模型,对整个64×64×3=12,288像素序列建模会产生过高的计算成本,让训练变得不可行。
此外,先对整个像素序列然后对RGB通道建模的两级分形框架,需要的计算量是三级分形模型的十多倍。
在表5中,进一步将分形框架与其他基于似然的模型进行了比较。
分形生成模型,同时使用因果自回归和掩码自回归分形生成器实现,取得了强大的似然性能。
特别是,它实现了每维3.14比特的负对数似然,显著优于此前最佳的自回归模型(每维3.40比特),并且与SOTA模型相比有着强大得竞争力。
这些发现证明了,分形框架在具有挑战性的逐像素图像生成任务上的有效性,突显了其在建模高维非序列数据分布方面的潜力。

生成质量
此外,研究人员还使用“四级分形结构”评估了FractalMAR在256×256分辨率下,在具有挑战性的类别条件图像生成任务上的表现。
如下表4中,FractalMAR-H实现了6.15的FID,以及348.9的IS。
在单个Nvidia H100 PCIe GPU上以1024的批大小评估时,平均每张图像的生成时间为1.29秒。

值得注意的是,新方法在IS和精确率上,具备了显著优势,表明其能够生成具有高保真度和精细细节的图像,这一点在图4中也得到了展示。
然而,其FID、召回率相对较弱,与其他方法相比,生成的样本多样性较低。
研究人员推测,这是由于以逐像素方式对近200,000个像素进行建模的巨大挑战所致。

此外,研究人员进一步观察到一个有前景的Scaling趋势:
将模型规模从1.86亿参数增加到8.48亿参数,显著改善了FID(从11.80降至6.15)和召回率(从0.29提升至0.46)。
他们预期,进一步增加参数规模,可能会进一步缩小FID和召回率的差距。
条件逐像素预测
进一步地,作者通过图像编辑的常规任务,检验了分形方法的条件逐像素预测性能。
如下图5中的几个示例,包括修复(inpainting)、外延(outpainting)、基于掩码外延(uncropping)和类别条件编辑。
结果显示,分享方法能够基于未掩码区域,准确预测被掩码的像素。
此外,它能够有效地从类别标签中捕捉高层语义信息,并反映在预测的像素中。
这一点在类别条件编辑示例中得到了展示,其中模型通过条件化狗的类别标签,将猫的脸替换成了狗的脸。这些结果证明了,新方法在给定已知条件下预测未知数据的有效性。

更广泛地说,通过逐像素生成数据,新方法提供了一个相比扩散模型或在潜空间运作的生成模型,更易于人类理解的生成过程。
这种可解释的生成过程不仅让我们能够更好地理解数据是如何生成的,还提供了一种控制和交互生成的方式。
未来,这些能力在视觉内容创作、建筑设计和药物发现等应用中,尤为重要。
作者介绍
Tianhong Li(黎天鸿)

黎天鸿目前是MIT CSAIL(麻省理工学院计算机科学与人工智能实验室)的博士后研究员,师从何恺明教授。
在此之前,他获得了MIT博士、硕士学位,导师是Dina Katabi教授。他本科毕业于清华大学姚班计算机科学专业。
黎天鸿的研究兴趣主要集中在表示学习、生成模型,以及这两者之间的协同效应。他的目标是构建能够理解和建模,超越人类感知的智能视觉系统。
他也非常喜欢烹饪,这种热爱程度几乎和做研究一样。
有趣的是,在个人主页里,他列出了一些自己最喜欢的菜谱。

Qinyi Sun

Qinyi Sun目前是麻省理工学院(MIT)电气工程与计算机科学系(EECS)本科生,师从何恺明教授。
Lijie Fan

Lijie Fan目前是谷歌DeepMind研究科学家。
他于2024年获得了MIT计算机科学专业博士学位,于2018年获得了清华大学计算机科学学士学位。
他的个人研究重点在生成模型和合成数据。
何恺明

何恺明目前是麻省理工学院(MIT)电气工程与计算机科学系(EECS)的副教授,于2024年2月加入。
他本人的研究重点是,构建能够从复杂世界中学习表示并发展智能的计算机模型,研究的长期目标是用更强大的AI来增强人类智能。
何恺明最为人熟知的研究是深度残差网络(ResNets)。ResNets的影响力不仅限于计算机视觉领域,它的设计思想被广泛应用于现代深度学习模型中。
无论是自然语言处理中的Transformer(如GPT、ChatGPT),还是强化学习中的AlphaGo Zero,甚至是蛋白质结构预测的AlphaFold,残差连接都成为了这些模型的核心组件之一。
除了ResNets,何恺明在计算机视觉领域的贡献同样令人瞩目。他提出的Faster R-CNN和Mask R-CNN,极大地推动了目标检测和图像分割技术的发展。
在加入MIT之前,他于2016年-2024年在Facebook AI研究院(FAIR)担任研究科学家,2011年-2016年在微软亚洲研究院(MSRA)担任研究员。
此前,他于2011年在香港中文大学获得博士学位,2007年在清华大学获得学士学位。