中国联通公众号发文,日前,DeepSeek团队宣布将在“2月27日至3月3日”陆续开源5个代码库,这与中国联通一直秉持的,开源普惠理念不谋而合。
DeepSeek官宣开源周,继中国联通于1月开源,元景“自适应慢思考”思维链大模型后,又针对DeepSeek系列模型进行了,“自适应慢思考”优化升级,平均可节省约30%的推理计算量,现已开源。
这也是目前业界首个对DeepSeek系列思维链模型做“自适应慢思考”优化升级的工作。
“以我为主,为我所用”的开放创新
元景思维链大模型具备多学科、多场景通用推理能力,且能在确保慢思考能力不打折的情况下,做到针对不同任务和难度的自适应慢思考,大幅降低了资源消耗,实现了大模型“慢思考”能力高性价比落地应用。
元景思维链大模型接入DeepSeek-R1并非简单的“拿来主义”,而是“从其善,优其不善”,对DeepSeek-R1版本进行了调整,最大程度规避了其面对简单问题“过度思考”的现象,使模型具备了“自适应”能力。
即在面向难度较高问题时使用慢思考模式生成长思维链,面向简单问题时则倾向于生成简洁的思维链,迅速准确的输出相关答案。这样避免了答案的冗余、资源的浪费以及减少用户等待时间,提升用户体验。
调整步骤完整分享
难度自适应微调:为实现模型推理的难度自适应,中国联通利用DeepSeek-R1满血版模型采样生成数据,通过复杂度量化模块构造长度偏好数据集,对于简单问题从采样答案中挑选长度较短的答案,对困难问题挑选长度较长的答案,使得答案长度与当前问题复杂度相匹配。
在此基础上对DeepSeek-R1进行微调,使得微调后的模型具备对不同难度题目的自适应慢思考能力。具体改造流程如下图所示。
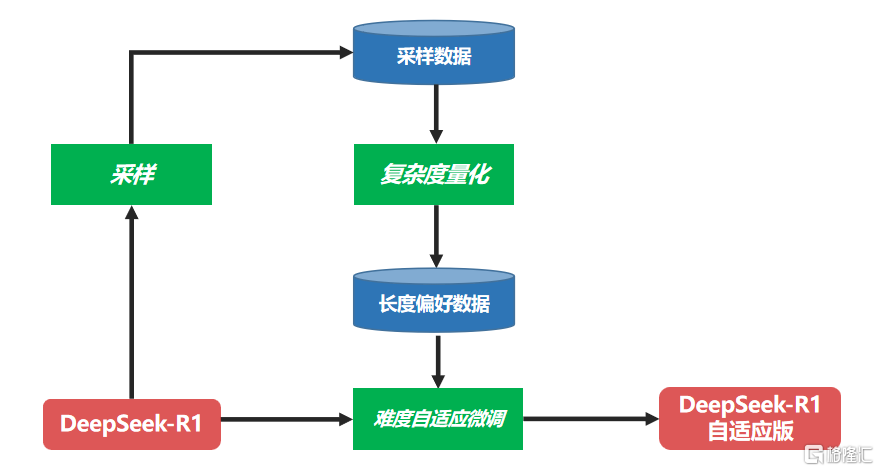
自适应慢思考的DeepSeek-R1满血版模型训练流程图
二次蒸馏:针对DeepSeek-R1的系列蒸馏模型,由于其使用的蒸馏数据来自训练满血版R1时使用的训练数据,而非由性能更好的R1满血版自身生成的数据,这会导致得到的蒸馏模型未能充分学习R1满血版的能力,蒸馏效果大打折扣。
为解决这个问题,中国联通使用了二次蒸馏的策略,即利用DeepSeek-R1满血版将已积累的高质量数据转化为包括深度思考过程的长思维链格式数据,在DeepSeek-R1蒸馏系列模型基础上再进行一次微调,使模型具备更强的推理能力。
难度自适应强化学习:在对模型进行二次蒸馏后,中国联通进一步借鉴DeepSeek-R1的构建思路,在GRPO算法基础上提出了一种难度自适应强化学习算法DA-GRPO(Difficulty Adaptive GRPO),对二次蒸馏模型进行难度自适应的强化学习训练,进一步提升其推理效果。除了使用传统的基于规则的正确性奖励、格式奖励、语言一致性奖励外,DA-GRPO还基于每个问题的复杂程度和生成答案的长度对奖励得分进行校准。
具体而言,如果模型对一个简单问题输出较长的答案,则对奖励分数进行相应的惩罚。同时,若模型对困难的问题输出较长的答案,则给予其更高的奖励分数,以鼓励其进行更充分的思考。
这样,通过提高样本答案奖励得分的区分度,使模型具备根据问题难度输出相应长度答案的能力,在保证推理准确率的前提下显著减少了答案冗余和资源消耗,从而实现对不同难度问题的自适应慢思考。
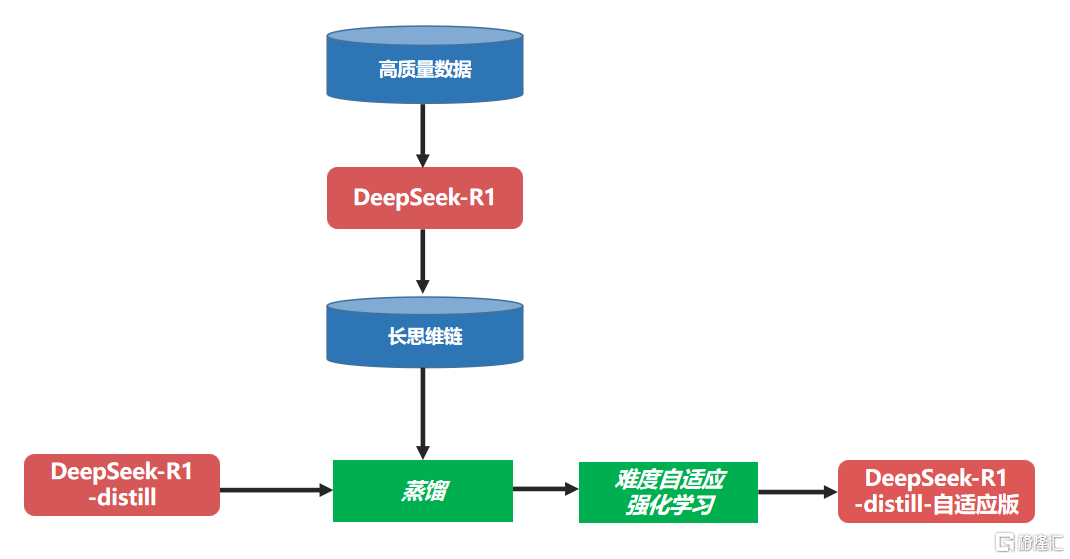
自适应慢思考的DeepSeek-R1蒸馏版模型训练流程图
推理计算量节省约30%
中国联通以DeepSeek-R1-distill-32B模型为例,对上述方法的效果进行了验证。
通过在数学任务测评集(MATH500)上对比以及具体实验可以看到,经过难度自适应改造后的模型在不同难度等级问题上生成的回答长度较原版均明显下降,并且对于最高难度(Level 5)输出的回答长度降幅最大,体现了模型对不同难度等级问题具备自适应慢思考能力。
经过测评,这种创新的自适应慢思考方法,平均可节省约30%的推理计算量,冗余输出大幅减少,用户体验得到有效提升。
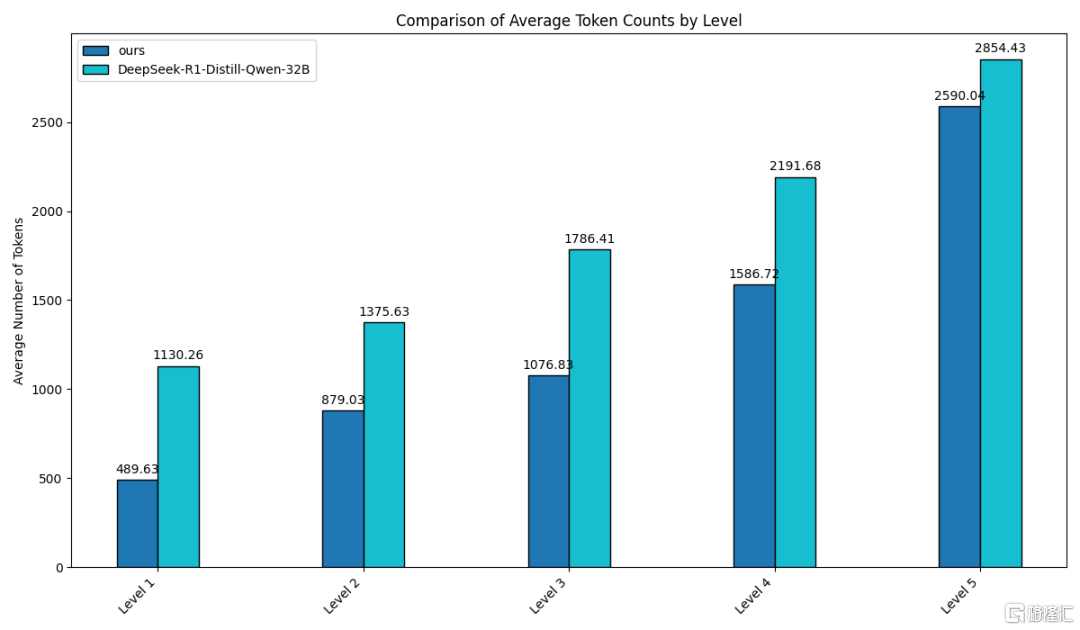
回答长度对比:原版DeepSeek-R1-distill-32B(浅蓝)vs自适应版(深蓝)

除了通过对DeepSeek-R1模型进行自适应慢思考优化升级外,中国联通还在紧锣密鼓推进对DeepSeek-R1系列模型的能力边界量化和安全价值观增强等相关工作的探索。
未来,中国联通将持续与以DeepSeek为代表的先进开源模型深度融合,不断升级元景基础模型能力和MaaS平台功能,贯彻开源普惠理念,推进算力普惠、模型普惠、应用普惠,以先进数智水平赋能社会千行百业。
目前,自适应慢思考版的DeepSeek-R1-distill-32B已在GitHub、魔搭、始智等社区全面开源,地址如下:
GitHub:https://github.com/UnicomAI/Unichat-DeepSeek-R1-distill-32B
魔搭:https://www.modelscope.cn/UnicomAI/Unichat-DeepSeek-R1-distill-32B
始智:https://wisemodel.cn/models/UnicomAI/Unichat-DeepSeek-R1-distill-32B