3月26日,在博鳌亚洲论坛2025年年会上,百度集团执行副总裁、百度智能云事业群总裁沈抖透露,百度智能云即将上线三万卡自研国产芯片昆仑芯集群,同时还在继续迭代模型。去年,百度已点亮了万卡的自研芯片昆仑芯P800。这标志着中国企业在人工智能算力领域,取得了新的重大突破。
而国产三万卡集群的启动和投入生产,为今年初以来,大模型应用的爆发和技术的进一步训练,提供了重要的算力保障。
与此同时,在当天的论坛上,沈抖呼吁,要把人工智能真正用起来。现在已有六成以上的央国企和百度合作,基于大模型做行业创新,但更多的企业并没有把大模型用起来。沈抖认为,中国最大优势就在于拥有丰富的应用场景,应该抓住这些应用场景,加速大模型的迭代和发展,真正让中国、让亚洲、让更多的人能用上领先的大模型。
01
大模型应用爆发,算力保障成关键
数智前线获悉,百度智能云即将投产的昆仑芯3万卡集群,一方面通过稳定的算力资源供应,避免因外部因素导致的断供风险,支撑了企业研发和生产的连续性;另一方面,也实现了更低的采购和维护成本,使更多企业,能够以更低的成本获得高性能计算资源。
三万卡大型集群的出现,也避免了计算资源闲置问题。利用云厂商的优势,通过大型集群,为众多企业提供服务,根据不同企业的需求,动态分配计算资源,实现多元算力支撑,企业即开即用。这不仅提高了资源利用率,也降低了企业使用云服务的成本。
这在当下尤为关键。去年以来,人工智能在深度推理、多模态等方面取得明显突破。业内的共识是,AI已成为全球产业变革的核心引擎,今年开年后,正在加速进入千家万户和千行百业,推动AI迈入全民普惠时代。AI推理迎来爆发式增长。
在这种情况下,大模型的应用落地和技术演进,都对可持续的算力保障提出更迫切的需求。
例如,今年开年后,政务在AI上动作极快。深圳福田提出“数智员工”,首批上线70名“数智员工”,“AI招商助手”将企业筛选分析时间缩至分钟级;福建漳州计划陆续推出30个“AI公务员”,聚焦教育、医疗、应急、环保、文旅等领域;北京市监局通过百度智能云千帆接
入DeepSeek,为企业登记注册提供全天候“咨询”。
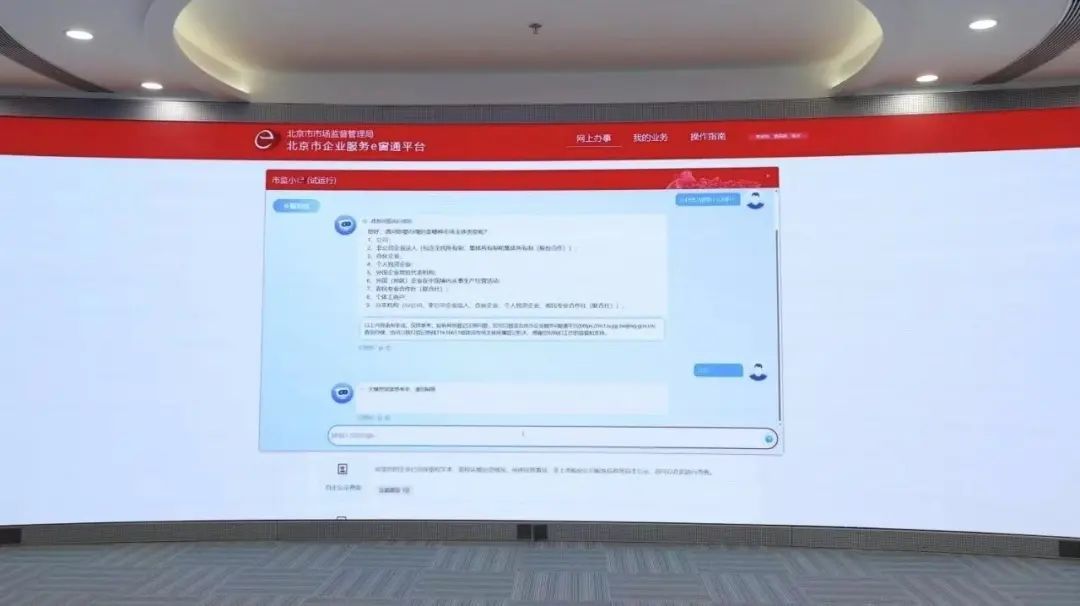
业内人士告诉数智前线,更多城市看到AI对北京、杭州等地的产业带动后,在统筹政务系统建设中,将AI作为抓手。未来两三个月,不少城市的“一网通办”,将提供更多AI服务。
“在这一过程中,算力面临挑战。虽然DeepSeek等模型,对训练的算力要求降低了,但对推理的需求却增加了,因为满血模型的参数量不小,而且深度推理的‘自言自语’过程,相较于只给出一个答案,会消耗更多token。”资深人士告诉数智前线,“尤其是过去算力建设以训练为主,今年将转向推理为主,政务领域算力将面临一波升级。”
在教育领域,去年秋季以来,高校已成为智算采购大户。在AI for science领域,人工智能在提高科研的质量和产出,像上海交大与百度合作推进AI for science,在新材料发现等上有很大促进作用。
今年以来,不少高校快速接入DeepSeek,在尝鲜后,又将学校里的业务系统对接大模型,结果用户量迅速攀升,并发越来越大。一些高校在教学的实操环节,甚至提出“要为每一间教室分配一些算力”。同时,长尾需求也在暴增,一些双非院校或职校,包括学校的院系甚至教研组,都提出算力需求。
除了大语言模型落地带来的算力激增,今年各行业对多模态的需求,也在拉动算力基础设施的建设。
如宁德时代持续引入多种人工智能技术,展开数智化建设,通过AI技术,保证产线的良率与效率。国家电网联合百度等公司,推出千亿级多模态行业大模型,深入电网安全、新能源消纳及供电服务等核心场景。百度不久前推出的原生多模态大模型文心4.5,已迅速被引入各行业,它支撑的视频捕捉与智能分析,正在帮助连锁行业优化服务和食安管理。这都对算力提出大量多元化要求。
伴随大模型的应用深入,智能体也呈现爆发势头。今年Manus让大家看到了多智能体调用,个人和企业都展现出极大热情。百度近日全量上线国内首个对话式应用开发平台百度秒哒,上线24小时就吸引了超过2万用户体验,创建应用数量突破3万个,相当于每3秒就诞生1个应用。
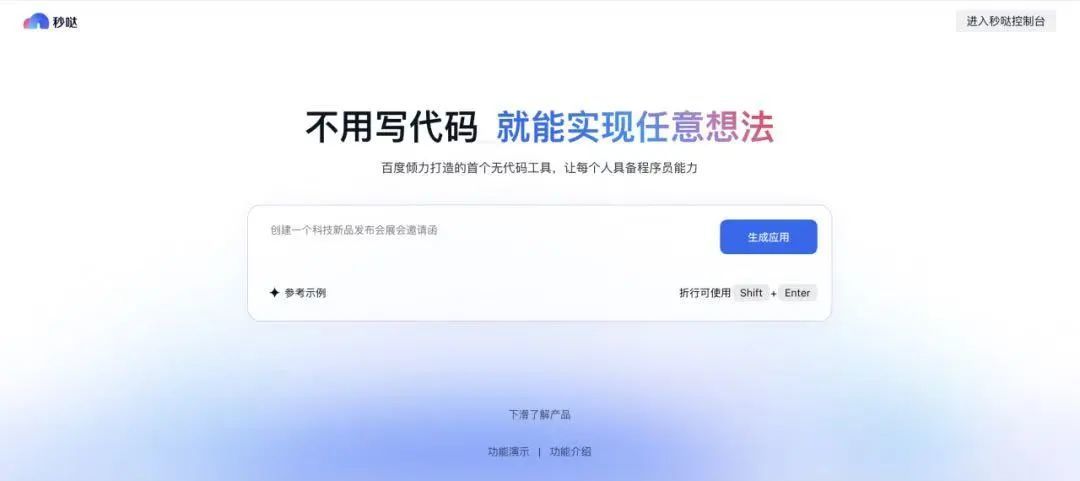
一些业界人士预言,2025年不仅是智能体“元年”,或许也是智能体的爆发之年。智能体的普及,也正在推升算力需求。
但与激增的算力需求相比,当下国内AI算力供应紧缺。在中国市场,由于美国禁令,国外芯片的供应受到限制,并且由于全球人工智能需求旺盛,芯片交货缓慢、价格上涨。美国还在不断推出新政,进一步限制中国获取先进芯片技术。在这种情况下,中国亟需可持续供应的自主AI算力。
这也促使国产算力的脚步越走越快。在百度智能云三万卡集群月底点亮之外,昆仑芯服务器近日中标招商银行项目,将围绕多个核心业务场景,全面支持招商银行落地大模型应用。而这些多元化算力,将为互联网、金融、能源、工业、教育等众多领域,加速智能化转型,提供坚实的算力保障和支撑。
02
构建三万卡集群的拦路虎,如何击破?
三万卡集群建设,从硬件到软件,技术挑战是全方位的。结合昆仑芯以及百舸4.0的创新技术,在集群点亮过程中,解决了当下人工智能大规模集群面临的关键问题。
例如,包括DeepSeek在内的不少模型,采用了MoE(混合专家模型)架构,通过多专家并行和集群互联技术,降低了对高算力单卡的依赖,并在有限的算力和训练Token资源下,开发能耗更低、推理和训练效果更优的大模型。
根据介绍,昆仑芯P800基于新一代自研架构XPU-P,显存规格比同类主流GPU高出20%-50%,这对MoE架构更加友好。同时,支持了8bit推理、MLA(多头潜在注意力机制)、多专家并行等特性,这些特性实现更大的吞吐、更低时延,进一步降低集群训练及推理成本。
与此同时,百度百舸AI异构计算平台4.0,在3万卡集群建设中,围绕落地大模型全旅程的算力需求,发挥了至关重要的作用。
为了解决大模型训练时高通信带宽的需求,百舸4.0已构建了超大规模HPN高性能网络,将带宽有效性提升到90%以上。
3万卡集群能耗极高,常规的散热方案能耗可达十兆瓦或更高。为此,百舸采用了创新性散热方案,可以有效降低能耗,为企业的模型训练,进一步降低成本。
为了提升GPU 的有效利用率(通常用MFU来表示GPU的有效利用率),百舸不断优化并完善模型的分布式训练策略,将训练主流开源模型的集群MFU提升至58%。
大规模集群执行训练任务的稳定性非常关键。百舸可快速自动侦测到导致训练任务异常的节点故障。同时,通过百度自研的BCCL(百度集合通信库),能快速定位故障并自动化重新调度任务到健康节点,继续完成训练,目前已将故障恢复时间从小时级降低到分钟级,保障集群有效训练率达到98%。
这些技术最终确保了昆仑芯集群的“多、快、稳、省”。
在2025年两会期间,人工智能成为核心议题之一,政府工作报告明确提出“持续推进‘人工智能+’行动”,强调将数字技术与制造业实体经济深度融合,支持大模型广泛应用。这表明,以场景为核心,落地产业,已成为实现人工智能价值的关键路径。
不过,业界认为,大模型落地行业,还有很长的路要走。不少行业和企业在探索场景、治理数据,尝试多元的算力支撑,探讨AI落地价值,并进行人才储备。
在这样的形势下,大模型业界及生态,也在从底层算力、模型、工具链和应用,逐步构建起可持续、全方位的方案。而此次百度即将点亮的三万卡集群,为产业注入了强大动力,将进一步助推企业迎接新一轮科技和产业变革。