作者丨青橙财经 青风
DeepSeek爆火之后如何与之相处?这是摆在每个大模型厂商面前无法回避的问题。
腾讯、百度等选择了快速拥抱,在其旗舰AI产品中相继接入满血版DeepSeek-R1,借势收获了不少新用户;字节豆包、阿里通义、月之暗面Kimi、智谱清言等选择正面对抗,在自研大模型中增加“深度思考”模式;零一万物更为果断,在大模型“六小龙”中首家宣布放弃超大参数预训练,未来全面转向ToB业务。
3月31日,百度给出了一个新的答案。在昨日举行的新一期百度AI DAY上,文小言宣布完成品牌焕新与功能升级。升级的核心点是,在此前接入DeepSeek-R1的基础上,新版文小言进一步开放,将百度自研的文心X1、文心4.5等最新模型与DeepSeek-R1、可灵等第三方模型进行深度融合,并支持自动识别用户需求、自动选择最适合的模型完成任务,还升级了语音大模型、图片问答、AI生图生视频等多模态能力。

*图源互联网
这意味着什么呢?之前,为了写一段小红书的种草文案,新媒体运营人员要用DeepSeek-R1;创作一张海报,要用国外的Midjourney或者国内的百度文心;制作一段宫崎骏风格的动画,要用快手旗下的可灵AI或者OpenAI旗下的Sora;声音克隆可能要用海螺AI;求解一道高等数学题,幼儿园小朋友十万个为什么的语音聊天,可能还是“鸽了好久”的GPT-4o更可用……
大模型技术越来越先进,但也越来越细分。人们处理日常问题,可能就需要下载和使用不同的大模型产品及众多的细分版本,需要分别花钱充值,更麻烦的是国外产品使用起来极其不便,中文适配也差。
新版文小言的策略是,一个应用就可以完成众多不同类型的任务。它既可以做深度思考,完整展示思维链,也可以进行连续任务执行,还因为升级了多模态能力,能与用户进行更自然、更高效的交互。而且,它还从“手动档”升级为“自动档”,将任务扔进来即可,不需要用户操心具体该使用哪个专精模型。
使用简单,交互方式自然,性能强大,功能丰富,这不就是人们所期待的AI助手的发展方向吗?对百度这个AI老兵来说,至少意味着找到了一条与新生力量的开放相处之道:优势互补,相互协作。
01“补齐DeepSeek的多模态短板”
人们到底需要什么样的AI大模型?还是史蒂夫·乔布斯的话最有道理,“用户根本不知道想要什么,直到你展示给他看。”
在2023年大模型出现的早期阶段,众厂商比拼的是长文本处理能力,月之暗面、百川智能、零一万物等厂商轮番竞技,最长上下文输入长度从20万攀升至30万、40万字;2024年初,Sora横空出世,5月份GPT-4o正式发布,让人们惊呼科幻走进现实,AI生图、AI视频等多模态能力的发展贯穿全年始终;2025年初,DeepSeek-R1凭借强大的推理能力和极致性价比,搅动整个科技行业,将人们的关注重新拉回文字形态的通用大模型。
但在DeepSeek全面普及之后,人们发现,在图片与拍照、视频与摄像、语音输入与输出等与AI更自然的交互方面,仍然没有得到很好地满足。最近,GPT-4o升级,上线了“用嘴P图”功能,“吉卜力风”图片刷爆AI圈,让千千万万设计师们人人自危。再次证明,多模态能力一直留存在人们潜意识的需求菜单里,且需求巨大。
DeepSeek固然强大,但在多模态方面存在明显的短板,仅限于在图片和拍照中识别里面的文字。可以说,DeepSeek的输入输出全部都是文字的。腾讯元宝接入了DeepSeek-R1,但只是解决了DeepSeek官方应用“服务器繁忙”的问题,也没有带来多模态的增益价值。

*图源文小言
而新版文小言将百度两大新模型文心大模型X1和4.5与DeepSeek-R1满血版,进行了多模型融合调度。用户可以随意切换使用,或者更省事地选择“自动模式”。百度这两个新模型在推理和多模态方面各有侧重。
文心X1与DeepSeek-R1类似,都是深度思考模型,但文心X1是宣称“首个”能自主调用比如绘图等各种工具的,可以完成⼀些连续任务。它利用递进式强化学习训练方法、基于思维链和行动链的端到端训练、多元统一的奖励系统等技术,推理输出直接可以图文混合呈现。
文心大模型4.5是百度自主研发的新一代原生多模态基础大模型,在多模态交互、理解方面更强,原生模型联合预训练能实现更深层次的模态融合。拍图解题,文生图,让图片动起来,AI语音聊天,都可以很好地实现。
其语音大模型此次也进行了全新升级,使用起来颇有亮点,比如它支持方言对话、复杂知识问答及随时打断等场景,用户可进行语音知识问答或趣味角色扮演。
百度语音首席架构师贾磊透露,该模型是百度在业界首个推出、基于全新互相关注意力(Cross-Attention)的端到端语音语言大模型。在语音场景满足一定交互指标下,大模型调用成本比行业平均降低50%-90%,推理响应速度极快,将语音交互等待时间压缩至1秒左右,极大提升了交互流畅性。
02“更多场景更多玩法”
借助多模型融合和多模态理解,新版文小言带来更多的用户真实存在的AI使用场景和更大的想象空间。
像上面提到的,动画爱好者如果想制作一段视频,往往要先用DeepSeek生成提示词,再用Midjourney文生图,再拿到可灵AI中做图生视频。现在文小言可以一条龙解决了。比如让爱因斯坦弹吉他,边弹边跳。

*图源文小言,爱因斯坦弹吉他AI视频(GIF)
还有个非常常见的场景,家里客厅装修,有一整扇落地窗,想参考几个不同的风格设计。用白话给文小言输入提示词后,文心X1会进行深度思考,然后调用搜索、画图等多种工具,最后生成多张效果图,每张都附有该风格的设计说明,图文混排输出,清晰明了。
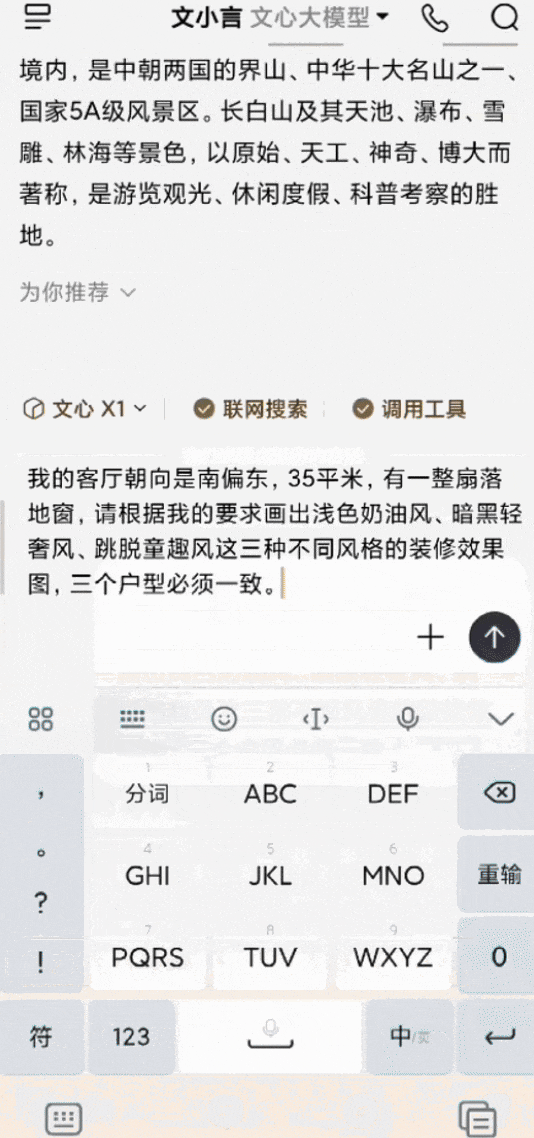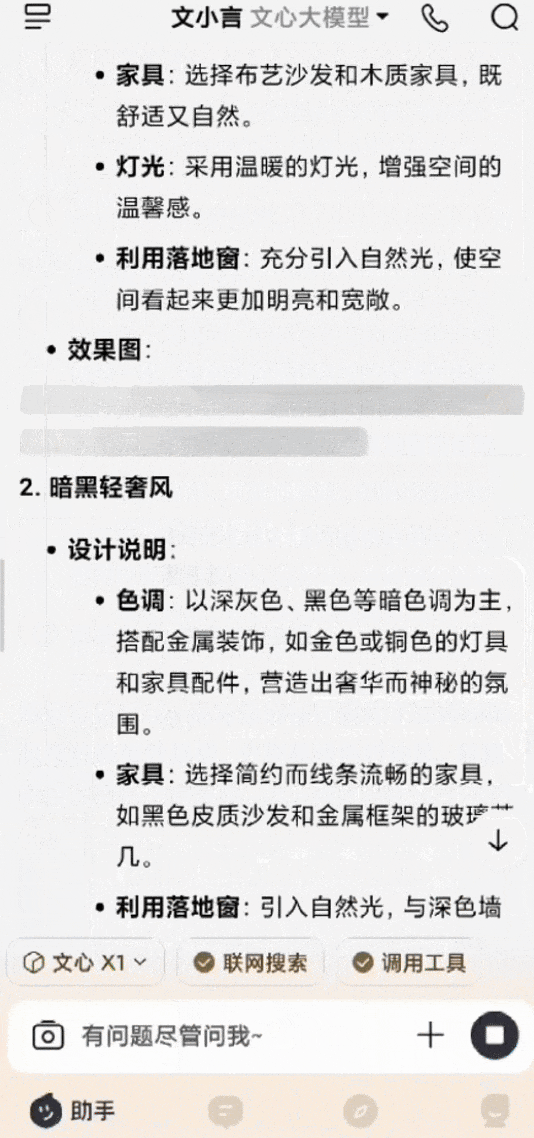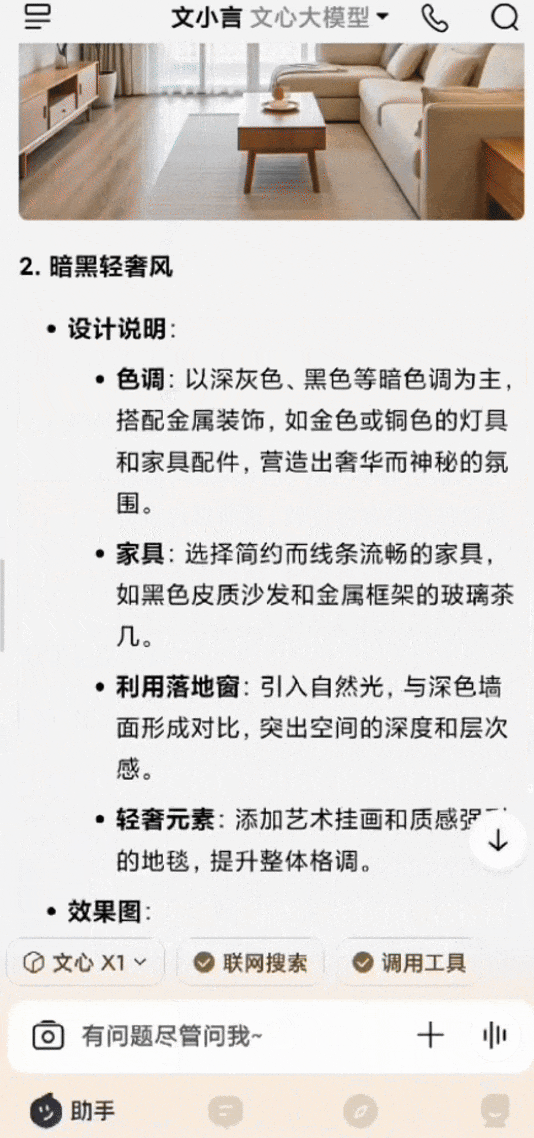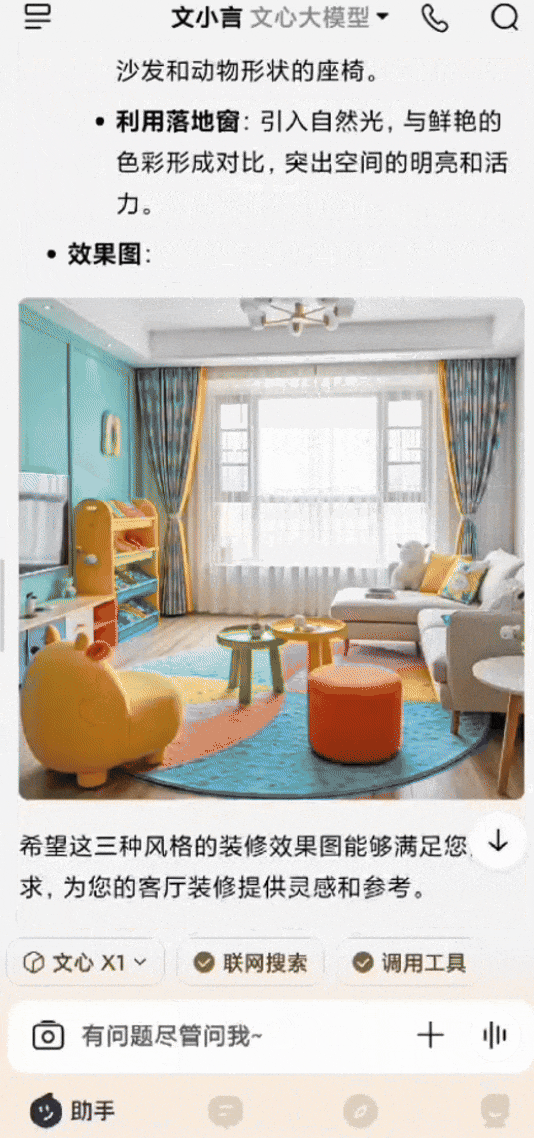
*图源文小言,装修设计示例(GIF)
再比如辅导孩子功课,让很多家长头疼,因为很多题目可能自己也不会做。新版文小言中新增了一个“解题老师”,直接对题目拍照,它就可以生成解答。神奇的是,它还有老师讲解的视频,不只给出答案,还给出详细的做题思路和步骤,用语音和视频展示娓娓道来。就像个一对一的家教,而且是免费的。这种多模态解题功能的难得之处在于,它不是简单地给孩子提供答案,而是指导了做题方法,传统大模型仅通过文字很难达到这种效果。
*图源百度
文小言新的端到端语音模型能够识别儿童的含糊发音,理解能力更符合儿童的习惯包括快速打断与响应。比如要求它给孩子讲个故事,如果不爱听,孩子直接打断要求换一个,文小言能丝滑衔接,不会再出现之前智能语音那种“你说你的,我讲我的”的尴尬局面。它还能切换蜡笔小新、孙悟空、熊大熊二等百变音色,更学会了重庆话、河南话、广西话等多种方言。
03“写在最后”
⼤模型马拉松竞赛进⼊“深⽔区”,因为用户真实需求的多样性,导致未来的竞争不可能再是单⼀模型的能⼒,⽽是如何让AI能⼒更⾼效、更便捷地触达⽤户。
百度在AI大模型领域深耕多年,在AI搜索、检索增强的文生图技术(iRAG)、无代码工具、智能体生态构建等方面积累了很多经验,尤其是拥有海量的中文语料库,这比一众国外产品具备明显的本地化优势。
在增强自身能力之外,百度近期也愈发体现出开放升级的姿态。将DeepSeek两款大模型上架至千帆ModelBuilder平台;宣布搜索引擎和智能体平台接入DeepSeek;文心一言全面免费;宣布文心大模型系列开源;如今,文小言新版App又将最新模型与DeepSeek深度融合,多模态能力大幅提高。
文小言采用“模型矩阵+自动调度+生态开放”的策略,试图构建一条具有持续竞争力的产品护城河。这一趋势或许将成为未来AI演进的主线。而在这个过程中,用户体验得以不断提升,将是最大的受益者。