来源:源达
投资要点
全球首款通用性AI Agent——Manus
中国创业公司Monica于2025年3月6日发布全球第一款通用型AI Agent——Manus,其在GAIA 的基准测试中取得了新的SOTA表现, 超越Open AI同级产品。Manus采用Multiple Agent架构, 可将复杂任务拆分为规划、执行、验证等子模块,运行在独立的虚拟机中。目前,Manus已提供多种处理现实世界任务的案例,包括个性化旅行规划、深度股票分析、保险政策比较、供应商采购、财务报告分析、专业数据整理、教育内容创建等。该产品体现国内 Al Agent 产品强大的通用性和复杂任务执行能力。此外,官方计划在今年开源Manus的推理部分,国内厂商有望内化Manus的通用任务执行能力,从而进一步推动AI应用的落地。
DeepSeek算法创新催动AI平权
DeepSeek R1版本模型在训练方法上的核心创新点在于通过极简的规则化奖励设计(准确性奖励和格式奖励)来替代复杂的传统的微调(SFT以及RLHF),从而实现高效的推理能力优化,以及节约大量的算力成本。该方法在后续产品的迭代中得到了延续,3月25日,DeepSeek 宣布V3 模型已完成小版本升级,该版本借鉴了DeepSeek-R1 模型训练过程中所使用的强化学习技术,在推理类任务上的表现水平大幅提高,在数学、代码类相关评测集上取得了超过 GPT-4.5 的得分成绩。DeepSeek-R1的算法创新使得模型在极少标注数据条件下显著地提升模型推理能力,AI 产业链价值链分配或向中小厂商倾斜。此外,在医疗、金融合规等垂直领域,仅需少量领域规则即可微调模型,无需海量标注数据,相关应用侧公司有望受益。
投资建议
建议关注AI应用侧的投资机会:1) AI语音: 科大讯飞;2) 金融IT:恒生电子;3)医疗IT:卫宁健康;4)AI视频/图像创作:万兴科技。
风险提示
AI 技术发展不及预期;AI应用渗透不及预期;竞争格局恶化。
一、国内创业公司发布全球首款通用型AI Agent
1.全球首款通用型AI Agent——Manus
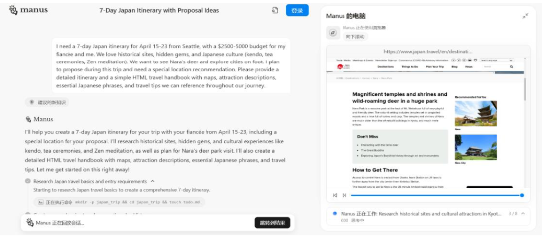
中国的创业公司Monica于2025 年 3 月 6 日发布全球第一款通用型AI Agent , 据团队介绍,“Manus是全球第一款通用Agent产品,可以解决各类复杂多变的任务。无论用户需要深入的市场调研、繁琐的文件批量处理、个性化的旅行规划还是专业的数据分析,Manus都能通过独立思考和系统规划,在自己的虚拟环境中灵活调用各类工具——编写并执行代码、智能浏览网页、操作各类网页应用——为用户直接交付完整的任务成果,而非仅仅提供建议或答案。”
|
图1:Manus 初始运行界面 |
图2:Manus执行结果界面 |
 |
 |
|
资料来源:Manus官网,源达信息证券研究所 |
资料来源:Manus官网,源达信息证券研究所 |
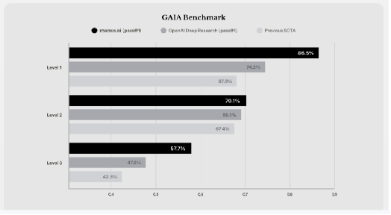
根据官网资料,Manus在GAIA(General Artificial Intelligence Assistant benchmark)的基准测试中, 在所有三个难度级别上都取得了新的SOTA(state of the art)表现, 超越Open AI同级产品。
图3:Manus GAIA基准测试
资料来源:Manus官网,源达信息证券研究所
GAIA为FAIR、Meta、HuggingFace等于2023年发布的通用人工智能助手基准测试,提出了系列需要推理、多模态处理、网页浏览和工具使用等基本能力的现实世界问题。对于人类来说,这些问题在概念上很简单,但对大多数先进的人工智能来说却具有挑战性:测试中人类受访者正确率达92%,而配备插件的GPT-4仅获得15%。GAIA可以根据解决问题所需的步骤数量和所需的不同工具数量分为三个难度级别:
1)Level 1:问题通常不需要工具,或最多使用一个工具,不超过5步;
2)Level 2:问题通常涉及更多步骤,大约在5到 10步之间,且需要结合不同的工具;
3)Level 3:问题是为接近完美的通用助手设计的,需要执行任意长度的操作序列,使用任意数量的工具,并访问一般世界。
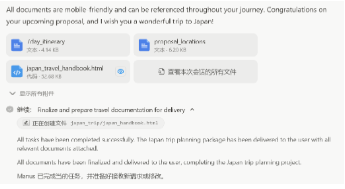
此外,Manus 支持文本、文档、压缩包等多种类型的输入。在指令发出后,Manus 能够在虚拟机内自行配置和使用终端、编辑器、浏览器等工具,完全自主地实现复杂任务的拆解、规划与异步执行。在执行期间,页面左侧显示有系统当前的运行状态,右侧则显示正在访问的页面或整体进度。由于 Manus 是在云中异步工作的,一方面用户可以同时运行多个 Manus 会话,并行执行不同任务;同时用户也可以在任务执行过程中关闭计算机,Manus 将在后台继续运行,并且会在任务完成后发送通知。此外,Manus 也支持任务执行过程中的实时交互。
图4:Manus 系统运行情况
资料来源:Manus官网,源达信息证券研究所
在实际使用当中,目前Manus已提供多种处理现实世界任务的案例,包括个性化旅行规划(整合旅行信息、为用户创建定制旅行手册)、深度股票分析(全面股票洞察)、保险政策比较(创建保险政策比较表)、供应商采购(找到最适合用户需求的供应商)、财务报告分析(研究和数据分析捕捉市场对特定公司的情绪变化)、专业数据整理(创业公司列表整理)、教育内容创建(为中学教师创建视频演示材料)等。
目前,该产品还在内测之中,用户可在登录后申请加入内测。
图5:Manus 涵盖的应用场景
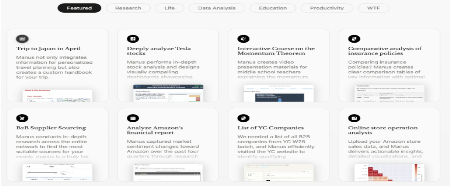
资料来源:Manus官网,源达信息证券研究所
- Manus 性能对比领先于Operator
Manus目前采用Multiple Agent架构,将复杂任务拆分为规划、执行、验证等子模块,运行在独立的虚拟机中,通过规划代理、执行代理、验证代理的分工协作机制来大幅提升对复杂任务的处理效率,并通过并行计算缩短响应时间。
在Multiple Agent的架构中,每个代理可能基于独立的语言模型或强化学习模型,彼此通过API或消息队列通信。同时每个任务也都在沙盒中运行,避免干扰其他任务,支持云端扩展。每个独立模型都能模仿人类处理任务的流程,比如先思考和规划,理解复杂指令并拆解为可执行的步骤,再调用合适的工具。
与Manus 有相似功能的Agent 是Open AI 于25年1月份发布的Operator, 该产品是一款由 Open AI 推出的 AI 浏览器智能体,由计算机使用代理(Computer-Using Agent,)驱动,结合了 GPT-4o 的视觉能力以及强化学习下的高级推理,能够识别网页并自动实现与网页的交互,且具备一定的推理能力,可以在遇到问题时自我纠正,可以在无法解决时将控制权交换给用户。
|
图6:Operator运行界面 |
图7: Operator 应用场景 |
 |
 |
|
资料来源:Open AI官网,源达信息证券研究所 |
资料来源:Open AI官网,源达信息证券研究所 |
在性能测试中,Manus 与Operator均可以构建出虚拟环境和资源进行CUA一些列动作执行。
Manus能够在云端独立完成任务,无需人工干预,直接交付完整的任务成果,同时由多种模型支持,具备强大的工具调用能力,可灵活编写代码、智能浏览网页和操作各类应用,不仅仅局限于单一任务,而是能够跨领域、跨任务地提供解决方案。
而Operator主要运行在浏览器中, 无法调用终端、文件系统等资源交付最终结果。
表1:Manus 与Operator 性能对比
|
Manus |
Operator |
|
|
技术架构 |
Multiple Agent |
Computer-Using Agent |
|
是否能创建云上虚拟机 |
是 |
是 |
|
是否支持浏览器外的操作 |
是 |
否 |
|
推理能力 |
强 |
较弱 |
|
鲁棒性 |
强 |
较弱 |
资料来源:Manus,Open AI, 国金证券研究所,源达信息证券研究所
3.Manus计划开源模型推理部分,进一步推动AI 应用落地
3月11日,Manus平台宣布将与阿里通义千问团队正式达成战略合作。双方将基于通义千问系列开源模型,在国产模型和算力平台上实现Manus的全部功能。目前两家技术团队已展开紧密协作,致力于为中国用户打造更具创造力的通用智能体产品,Manus产品使用了不同的基于阿里千问大模型(Qwen)的微调模型。
此外,官方将计划在今年开源Manus中的部分模型,特别是Manus的推理部分。国内厂商有望内化Manus的通用任务执行能力,推出在多个领域具有泛化应用效果的模型,有望进一步推动AI应用的落地。
二、Deepseek 通过算法优化实现 AI 平权
1.Deepseek R1 版本实现重要算法创新
AI 传统的训练方法包括预训练(Pre-Training)以及微调(Fine-Tuning),主要过程可以简化为:随机模型 → 预训练(爬取数据)→ 预训练模型 → 微调(领域数据)→ 微调模型 → 提示/上下文学习 → 实际应用。
具体来看,从一个随机初始化的大语言模型(Random Model)开始,模型参数未经训练,接着使用大规模、多样化的爬取数据进行无监督学习。这些数据通常包含网页文本、书籍、代码等。通过预测下一个词或掩码词等任务,学习通用语言表示,得到一个预训练模型,具备通用语言理解能力。接着通过在监督微调(SFT)加入大量的思维链(COT)范例,用例证和复杂的如过程奖励模型(PRM)之类的复杂神经网络奖励模型,来让模型学会用思维链思考,使其适应具体任务。
图8:AI模型的训练方法
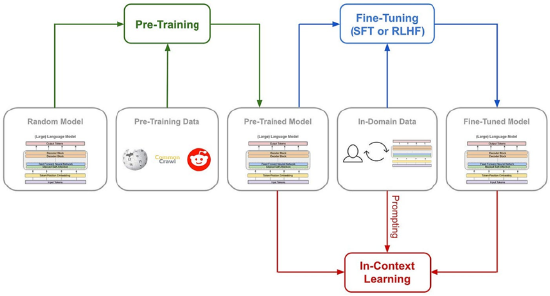
资料来源:腾讯科技公众号,源达信息证券研究所
图9:SFT微调示例

资料来源:源达信息证券研究所
图10:RLHF微调示例
资料来源:源达信息证券研究所
DeepSeek-R1-Zero训练方法降低计算资源消耗。DeepSeek-R1-Zero在训练方法上的核心创新点在于通过极简的规则化奖励设计(准确性奖励和格式奖励)来替代复杂的传统的微调(SFT以及RLHF),从而实现高效的推理能力优化。
规则化奖励设计具体包括:
- 准确性奖励:准确性奖励模型评估响应是否正确。对了就加分,错了扣分。评价方法也很简单:例如,在具有确定性结果的数学问题中,模型需要以指定格式(如<answer>和</answer>间)提供最终答案;对于编程问题,可以使用编译器根据预定义的测试用例生成反馈。
- 格式奖励:格式奖励模型强制要求模型将其思考过程置于<think>和</think>标签(该标签为思考的开闭过程)之间。没这么做就扣分,做了就加分。
同时让模型在GRPO(Group Relative Policy Optimization)的规则下自我采样+比较,自我提升。即通过组内样本的排序(如“组1 > 组2”)比较来计算策略梯度,有效降低了训练的不稳定性,同时提高了学习效率。该训练方法首先可以使训练效率的提升,所需训练时间更短,其次是省去了SFT和复杂的奖惩模型,从而降低计算资源消耗。
表2:不同训练路径对比
|
方法 |
奖励来源 |
数据需求 |
|
传统RLHF |
人类偏好模型 |
大量人工标注 |
|
监督微调SFT |
标注输入-输出对 |
高质量标注 |
|
R1-Zero |
规则(答案/格式校验) |
无人工标注 |
资料来源:DeepSeek, 源达信息证券研究所
表3: DeepSeek-R1-Zero算力节省原因
|
环节 |
传统RLHF |
DeepSeek-R1-Zero |
算力节省原因 |
|
奖励计算 |
训练RM(需GPU计算) |
规则匹配(CPU正则表达式) |
省去神经网络前向传播和反向传播 |
|
RL算法 |
PPO(多步优化,高方差) |
单步策略梯度(如REINFORCE) |
简化策略更新,减少交互次数 |
|
数据需求 |
大规模人类标注数据 |
自动生成+规则验证 |
零标注成本,数据生成算力可忽略 |
|
调试成本 |
需调参RM和PPO超参数 |
规则逻辑透明,调试简单 |
减少实验迭代次数 |
资料来源:DeepSeek, 源达信息证券研究所
此外,DeepSeek-R1-Zero训练方法可以快速提高模型的推理能力。根据DeepSeek的研究论文,大模型在训练学习的过程中,响应长度会出现突然的显著增长后又回落,这些“跳跃点”可能暗示模型推理解题策略的质变,即模型推理能力的显著提升。
如下图所示:
图11: DeepSeek-R1-Zero 在训练过程中出现跳跃点
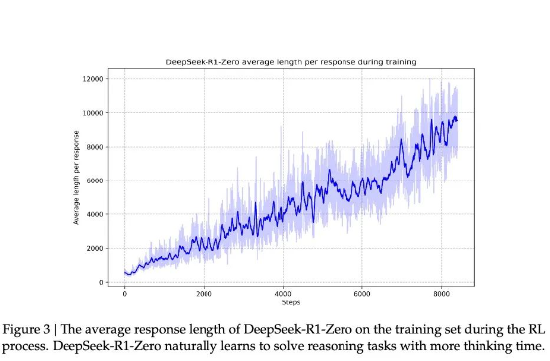
资料来源:Deepseek,源达信息证券研究所
Deepseek R1-Zero在数学界享有盛誉的AIME竞赛中从最初的15.6%正确率一路攀升至71.0%的准确率。AIME的题目需要深度的数学直觉和创造性思维,而不是机械性的公式应用。
图12: DeepSeek-R1-Zero 在AIME的表现
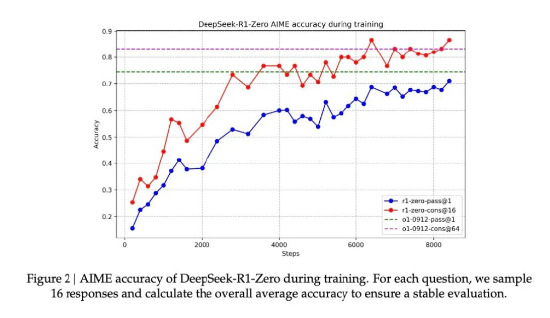
资料来源:Deepseek,源达信息证券研究所
- 创新强化学习技术助力Deepseek V3完成小版本升级
3月25日,DeepSeek 宣布V3 模型已完成小版本升级,目前版本号 DeepSeek-V3-0324,根据官方公众号描述,DeepSeek-V3-0324 与之前的 DeepSeek-V3 使用同样的 base 模型,仅借鉴了DeepSeek-R1 版本模型训练过程中所使用的强化学习技术,便大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过 GPT-4.5 的得分成绩。
图13: DeepSeek-V3-0324 相对于其他模型的表现
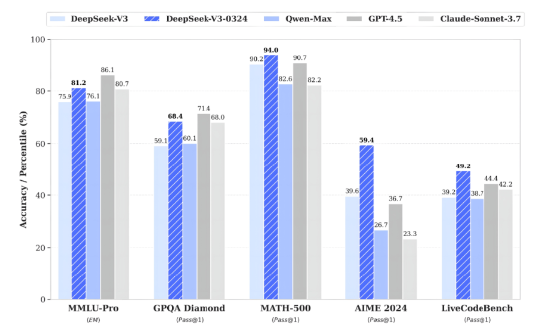
资料来源:Deepseek,源达信息证券研究所
综上, DeepSeek-R1版本模型的算法创新使得模型在极少标注数据条件下显著地提升模型推理能力,在数学、代码、自然语言推理等任务上性能对齐海外模型。过往大模型遵循Scalling Law准则,头部厂商能够凭借先发以及投入优势吸引资源聚集构建自身护城河,Deepseek R1 则打破了在算力和芯片上“大力出奇迹”的既定格局,极大冲击头部模型厂商壁垒,AI 产业链价值链分配或向中小厂商倾斜。
三、投资建议
1.建议关注
Manus计划在今年开源其推理部分的模型,国内厂商有望内化Manus的通用任务执行能力,推出在多个领域具有泛化应用效果的模型,有望进一步推动AI应用的落地。
以Deepseek-R1引领的 AI 技术平权使得中小厂商广泛受益,算力资源有限的机构也可高效地训练高性能模型。此外,在医疗、金融合规等垂直领域,仅需少量领域规则即可微调模型,无需海量标注数据,相关应用侧公司有望受益。
建议关注AI应用侧的投资机会:1) AI语音: 科大讯飞;2) 金融IT:恒生电子;3)医疗IT:卫宁健康;4)AI视频/图像创作:万兴科技。
2.行业重点公司一致盈利预测
表4:万得一致盈利预测
|
公司 |
代码 |
归母净利润(亿元) |
PE |
总市值(亿元) |
||||
|
2024E |
2025E |
2026E |
2024E |
2025E |
2026E |
|||
|
科大讯飞 |
002230.SZ |
5.7 |
9.0 |
12.3 |
194.1 |
122.9 |
90.3 |
1115.4 |
|
恒生电子 |
600570.SH |
10.4 |
16.0 |
18.5 |
50.5 |
32.8 |
28.2 |
526.9 |
|
万兴科技 |
300624.SZ |
0.3 |
0.8 |
1.2 |
362.1 |
140.7 |
103.1 |
120.6 |
|
卫宁健康 |
300253.SZ |
4.4 |
5.7 |
7.3 |
54.3 |
41.7 |
32.7 |
239.5 |
资料来源:Wind一致预期(2025/4/2),源达信息证券研究所
四、风险提示
AI 技术发展不及预期;
AI应用渗透不及预期;
竞争格局恶化。
责任编辑:刘万里 SF014