作者 | ZeR0
编辑 | 漠影
智东西4月30日报道,今日,小米开源其首个推理大模型Xiaomi MiMo。其中经强化学习训练形成的MiMo-7B-RL,在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)公开测评集上,仅用7B参数量,得分超过了OpenAI的闭源推理模型o1-mini和阿里Qwen开源推理模型QwQ-32B-Preview。
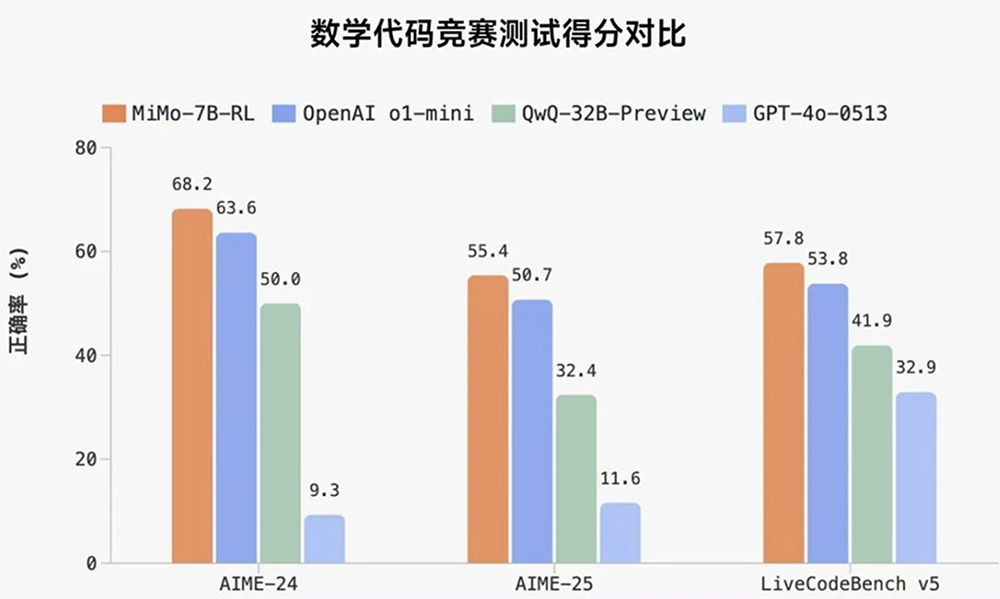
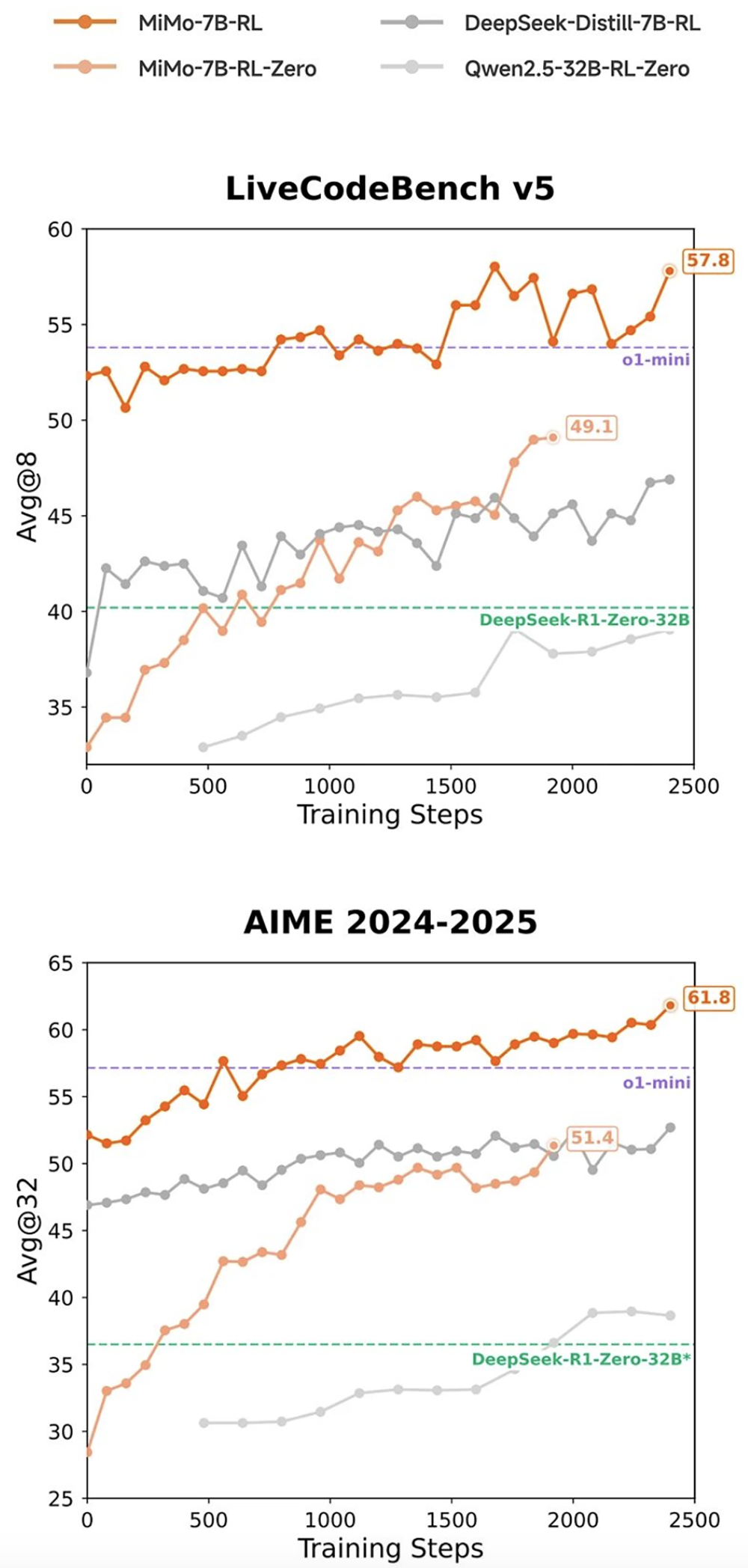
在相同强化学习训练数据情况下,MiMo-7B-RL在数学和代码推理任务上均表现出色,分数超过DeepSeek-R1-Distill-7B和Qwen2.5-32B。
MiMo是新成立不久的小米大模型Core团队的初步尝试,4款MiMo-7B模型(基础模型、SFT模型、基于基础模型训练的强化学习模型、基于SFT模型训练的强化学习模型)均开源至Hugging Face。代码库采用Apache2.0许可证授权。

开源地址:https://huggingface.co/XiaomiMiMo
小米大模型Core团队已公开MiMo的26页技术报告。

技术报告地址:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
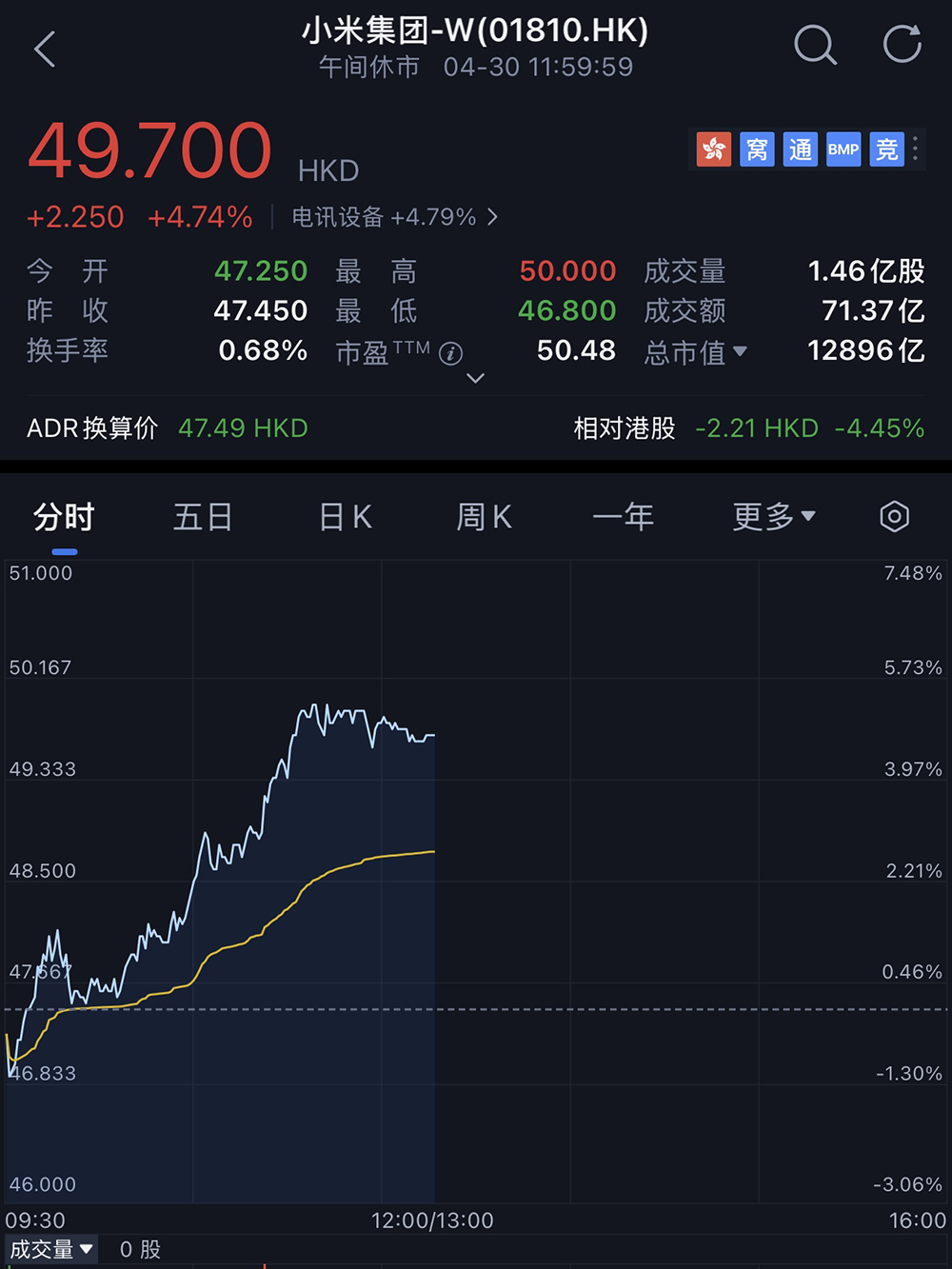
受此消息提振,截至午间休市,小米集团今日股价上涨4.74%,总市值1.29万亿港元(约合人民币1.21万亿元)。
一、预训练+后训练,联动提升推理能力
MiMo系列模型从零开始训练,其推理能力的提升由预训练和后训练阶段中数据和算法等多层面的创新联合驱动,包括:
预训练:核心是让模型见过更多推理模式
数据:着重挖掘富推理语料,并合成约200B tokens推理数据。

训练:采用三阶段数据混合策略,逐步提升训练难度,MiMo-7B-Base在约25T tokens上进行预训练;受DeepSeek-V3启发,将多token预测作为额外的训练目标,以增强模型性能并加速推理。
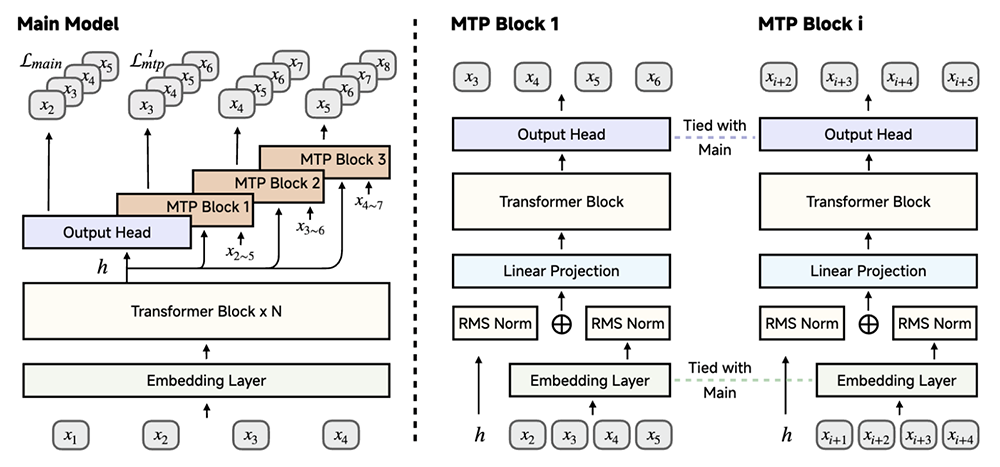
▲使用MiMo-7B实现多token预测:在预训练期间使用单个MTP层,推理阶段可使用多个MTP层以获得额外的加速
后训练:核心是高效稳定的强化学习算法和框架
算法:提出Test Difficulty Driven Reward来缓解困难算法问题中的奖励稀疏问题,并引入Easy Data Re-Sampling 策略,以稳定强化学习训练。
数据:精选了13万道数学和代码题作为强化学习训练数据,可供基于规则的验证器进行验证。每道题都经过仔细的清理和难度评估,以确保质量。仅采用基于规则的准确率奖励机制,以避免潜在的奖励黑客攻击。
框架:设计了Seamless Rollout系统,集成了连续部署、异步奖励计算和提前终止功能,以最大限度地减少GPU空闲时间,使得强化学习训练加速2.29倍,验证加速1.96倍。
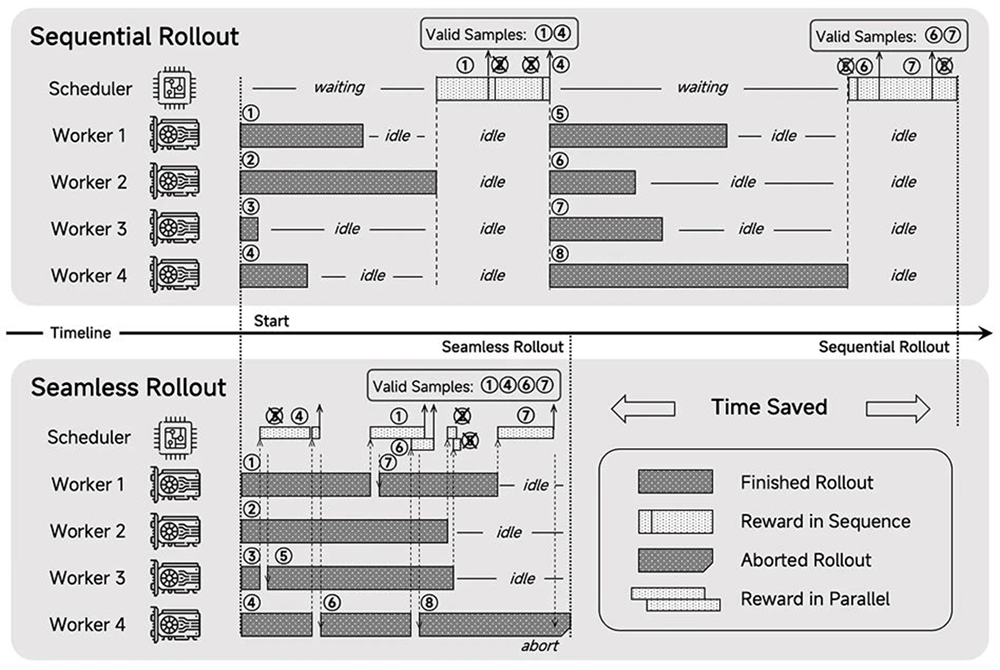
▲MiMo-7B-RL Seamless Rollout引擎概览
二、7B强化学习模型,性能超过阿里32B模型和OpenAI o1-mini
小米大模型Core团队将MiMo-7B-Base与Llama-3.1-8B、Gemma-2-9B、Qwen2.5-7B等规模相当的开源基础模型进行了比较,所有模型评估都共享相同的评估设置。
结果如图所示,MiMo-7B-Base在所有基准和评估的k值取得了高于其他对比模型的pass@k分数。随着k增加,MiMo-7B-Base与其他模型的分数差距稳步拉大,特别是在LiveCodeBench上。
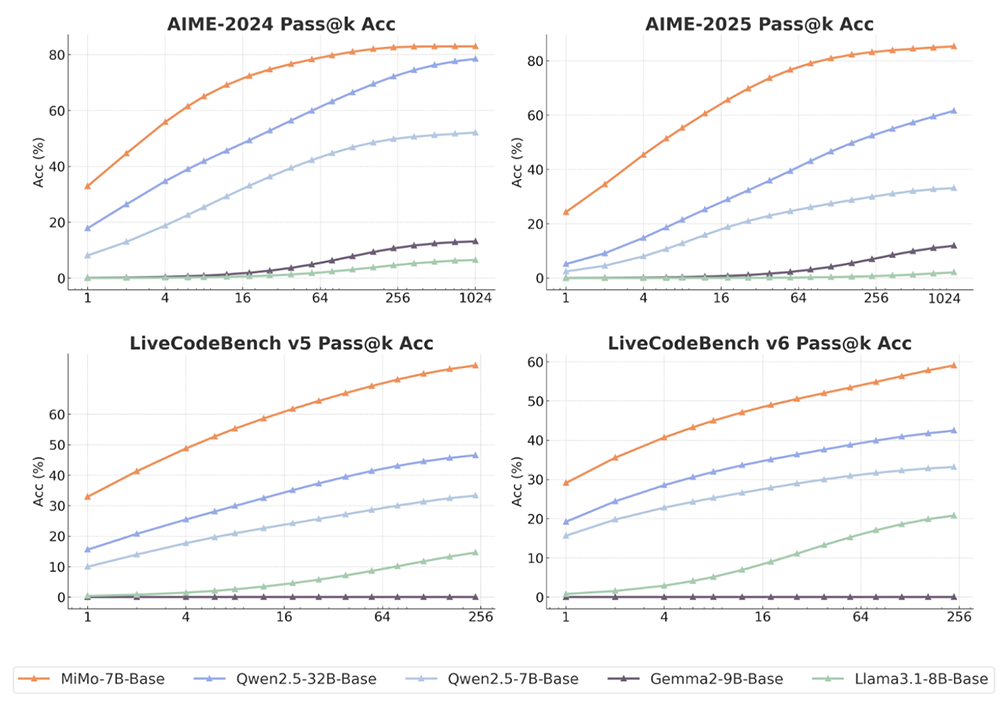
在评估语言推理模型的BBH基准测试上,MiMo-7B-Base的分数为75.2分,比Qwen2.5-7B高出近5分。SuperGPQA基准测试结果展示出MiMo-7B-Base在解决研究生水平问题方面的出色表现。在阅读理解基准测试DROP上,该模型的表现优于其他对比模型。
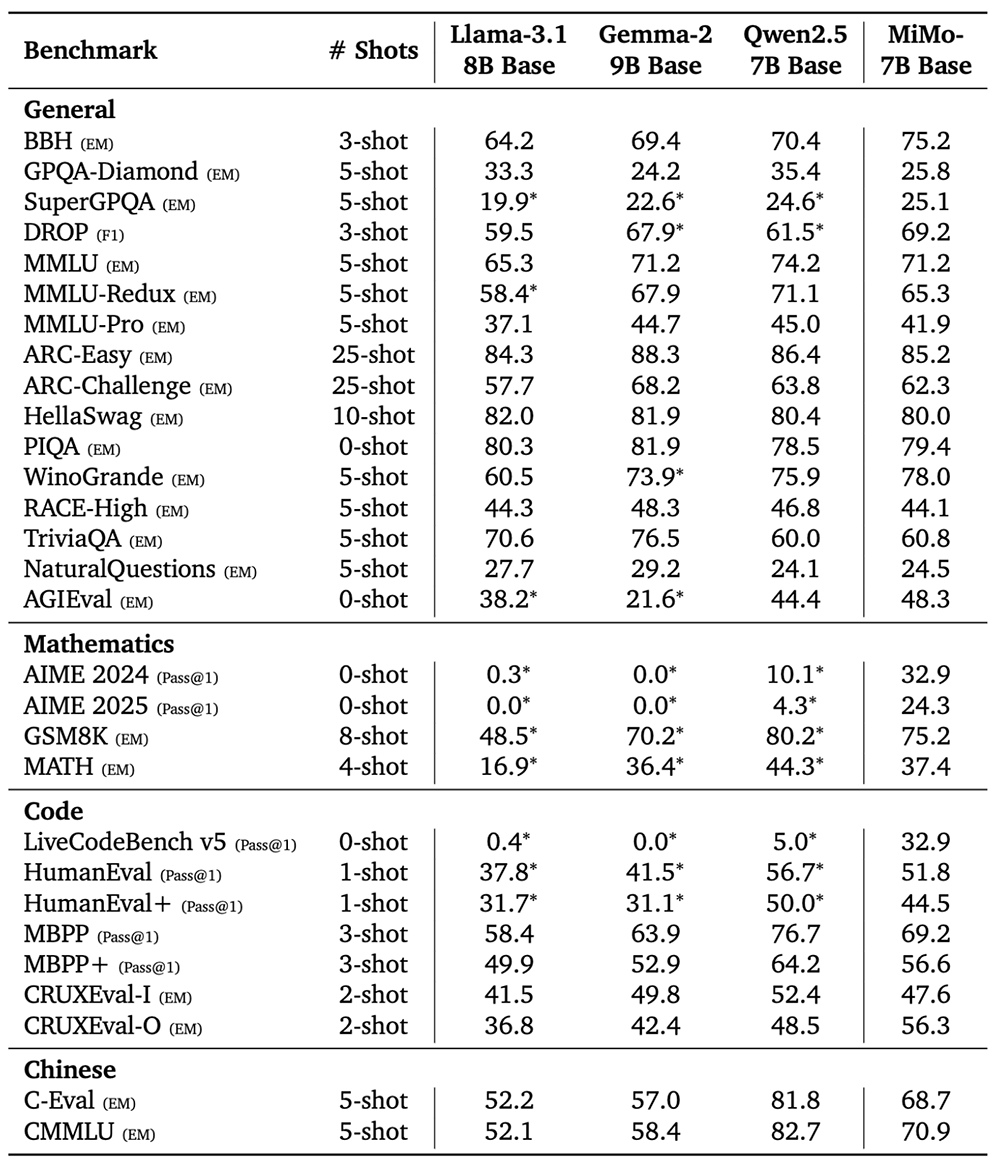
在代码和数学推理任务中,MiMo-7B-Base的多项分数超过Llama-3.1-8B、Gemma-2-9B。
MiMo-7B-Base在支持的32K上下文长度内实现了近乎完美的NIAH检索性能,并在需要长上下文推理的任务中表现出色,多数情况下分数都超过了Qwen2.5-7B。这些结果验证了其在预训练期间将多样化数据与高质量推理模式相结合的策略的有效性。
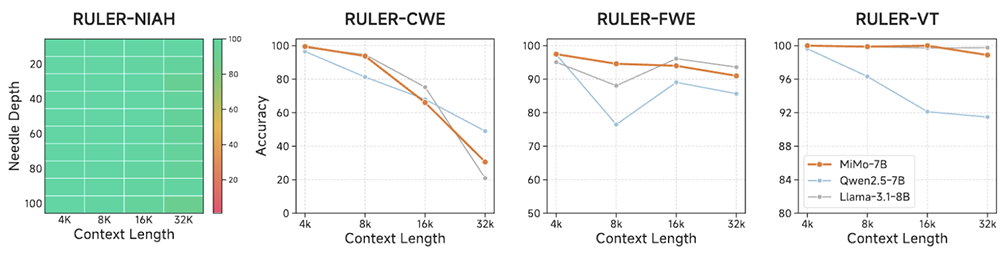
▲RULER上的长上下文理解结果
MiMo-7B-RL在多项通用基准测试接近或超过拥有32B参数规模的QwQ-32B Preview模型,数学和代码性能更是全面领先。
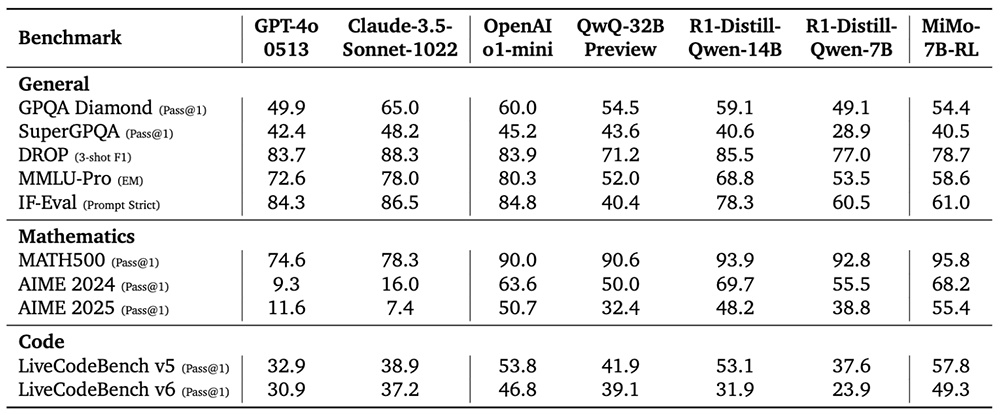
在数学基准测试AIME 2025测试、代码基准测试LiveCodeBench v6中,MiMo-7B-RL的得分均超过OpenAI o1-mini。
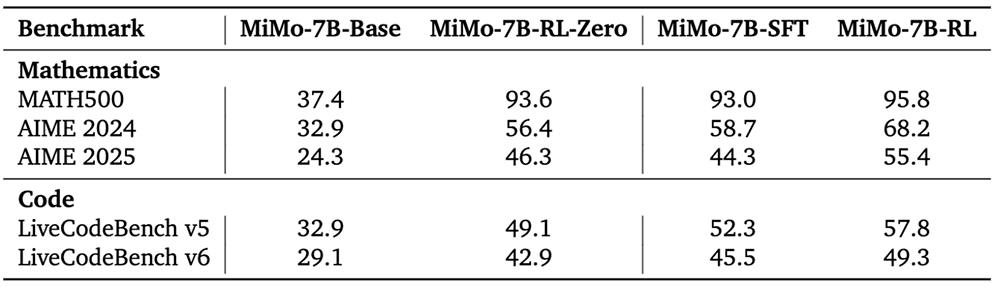
MiMo-7B系列4款大模型的多项数学和代码测试对比如下:
结语:今年大模型的三大热点,MiMo一举覆盖
今年,在DeepSeek爆红后,开源和推理迅速成为大模型领域的热门风向。如今低调许久的小米也正式加入这一战局。
作为国产手机头部企业之一,小米这次开源的四款模型参数规模只有7B,小到可以满足在端侧设备上本地运行的需求,贴合了大模型的另一大趋势——从卷参数规模转向追求经济高效。
通过在预训练和后训练过程中的多项创新联动,MiMo-7B-Base在数学、代码和通用任务上都展现了出色的推理能力。这项研究可以为开发更强大的推理模型提供参考。